 电子发烧友App
电子发烧友App


随着信息技术的飞速发展,利用日趋强大的信息化手段对交通系统进行管理也成为了一种发展趋势,上世纪八十年代开始,智能交通系统(Intelligent Trans-portation System,简称 ITS)得到了快速的发展。面对现代化交通对信息需求的日益增长,ITS 不但可以在交通管理层面利用计算机强大的计算能力进行更加科学高效的交通规划和管理,并可以通过先进的自动化设备获得更丰富的交通信息。
本文实现了一个基于视频的交通检测系统,研究的范围包括视频帧的获取,图像处理,车辆的检测与跟踪,以及交通宏观信息的获取。详细探讨了车辆的检测与跟踪的技术方法,主要工作体现在如下几个方面:
(1) 采用 Directshow 技术对视频图像帧进行获取。
(2) 采用 OpenCV 库进行相关的图像处理并对感兴趣区域进行提取。
(3) 分析和探讨了基于连续图像帧之间的运动物体检测技术,比较和权衡了各种算法,在已经取得的研究成果的基础上,提出了基于检测线的车辆发现方法。
2 开发环境介绍
视频处理一般是基于视频中一帧一帧的数据,所以首要的任务就是将视频中一帧一帧的图像获得到。在这个过程中我们采用了基于COM 组件技术的DirectShow 开发包。DirectShow 通过对过滤器的拼接来完成视频播放和处理任务,使得开发者不必关注视频的解码方式,从而将更多的精力放在图像处理的部分。
而在图像处理过程中,我们需要一套强大而高效的 API,使我们不需要关注最底层的图像处理过程,从而将精力都放在上层的算法的研究中。而在这里我们选择了 Intel 公司的 OpenCV 图像处理函数库,下面就针对 OpenCV 和 DirectShow 开发包进行介绍。
2.1 OpenCV 的介绍
OpenCV 是 Intel 公司的一个开源的图像处理函数库。它包括 300 多个 C/C++函数的跨平台的中、高层API,它不依赖于其它的外部库。
OpenCV 包含了计算机视觉和图像处理方面的许多通用算法,它包括以下功能:对图像数据的操作、对图像和视频的输入和输出、对矩阵和向量的操作、具有线性代数的算法程序、对各种动态数据结构进行操作、基本的数字图像处理能力、对各种结构进行分析、对摄像机定标、对运动进行分析、对目标进行识别,另外 OpenCV 还具有具有基本的 GUI 功能,还可对图像进行标注等。
在 OpenCV 库中,最常用也是最基本的一个数据结构是 Ip1Image,它在 OpenCV 中用来存储位图的数据结构,使用频率是非常高的,所以在这里有必要介绍一下它。Ip1Image 在 OpenCV 中的定义如程序1所示:
Typedef struct_Ip1Image{
int nSize; int ID; int nChannels; int depth; int dataOrder; int origin; int width; int height; struct _Ip1Image *maskROI;
struct _Ip1ROI *roi; void *imageId; struct_Ip1TileInfo *tileInfo;
int imageSize; char *imageData;
int widthStep; char *imageDataOrigin; }Ip1Image; (程序 1) Ip1Image 结构是来源于 Intel Image Precssiong
Libray,使用函数 cvCreateImage 来初始化 Ip1Image结构,函数的定义如程序 2 所示,这个函数只是单纯分配一块没有存放内容的内存。当为其中的参数 depth 赋值为 IPL_DEPTH_8U 时,初始化的是一个单通道无符号整形图像,而赋值为 IPL_DEPTH_32F 时,初始化的是一个三通道浮点图像。
Ip1Image*cvCreateImage(CvSize size, int depth, int channels); (程序 2)
有关OpenCV 实现其它功能的函数,文章中会贯穿的介绍。
2.2 DirectShow 的介绍
DirectShow 是微软在 Active Movie 和 Video for Windows 的基础上,推出的新一代的基于 COM 组件
技术的流媒体处理的开发工具包。它为需要自定义解决方案的应用程序提供了对底层流控制结构的访问。从网络应用的角度看,DirectShow 可用于视频点播、视频会议和视频监控等领域。
当播放媒体文件时,Filter Graph Manager 首先建立一个 Filter Graph。在 Filter Graph 中,源过滤器负责读取原始的媒体数据流,变换过滤器完成对这些数据流的解码,最后由提交过滤器将解码的结果显示出来。此时的媒体数据已经转换为一帧一帧的图像,就可以方便的将它们一张张的捕捉下来了。
3车辆检测模块的设计和实现
3.1 车辆检测模块的算法流程
使用 DirectShow,我们可以从交通视频中取得一帧一帧连续的图像,车辆的检测和发现操作就是
基于对这些连续图像帧的处理和分析的。按照一般的运动检测方法和目标跟踪手段,我们将取到的原始真彩色图像帧首先做灰度化处理,然后进行平滑操作,并基于背景差分法和帧间差分法进行感兴趣区域的提取,最后得到二值化的感兴趣区域图像。根据连续帧的二值图像检测出新进入画面的车辆,之后进行基于自适应边框的精确车辆定位,从而完成车辆的检测。本章的后面部分将对其中各个步骤进行详细的介绍。
3.2 视频图像帧的预处理
3.2.1 图像灰度化处理
一般的图像处理运算都是在灰度图像上面进行的,灰度图是只保留了图像的亮度信息的图像,因为灰度图像可以在保留足够的内容信息的同时,有效的降低运算量。所以,我们首先要将原始的视频帧图像进行灰度化处理,即将真彩色图像中的每个像素点都转换成 8bit 长度的亮度值,使所有像素的灰度值都在[0,255]范围之内。
程序 3 是 OpenCV 中对图像进行颜色模型转换的函数,而图像的灰度化也属于一种颜色模型的转换:
void cvCvtColor(const CvArr* src, CvArr*dst, int code); (程序 3)
此函数将 RGB 颜色空间表示的真彩色图像进行灰度化的内部算法如公式(1)所示:
Y=0.212671*R+0.715160*G+0.072169*B(1)
我们平时比较常用的将 RGB 真彩色图像灰度化的算法如公式(2)所示:
Y=0.299*R+0.587*G+0.114*B(2)
这两个公式都是依据在 R、G、B 三个颜色通道中亮度值的贡献比例而得到的。
3.2.2 图像平滑处理
视频图像在采集的过程中会不可避免的引入噪声,噪声的来源主要有电磁转换和光电转换引入的噪声、获取图像时存在的不确定因素以及自然起伏性的噪声。
为了去除视频图像中的噪声,从而使图像中的有用信息更加清晰,我们就需要对已经进行了灰度化的图像进行平滑操作。运算要求能够有效的减少各种类型的噪声的同时,也要能够很好的保留原图像中的轮廓信息。
void cvSmooth(const CvArr* src, CvArr* dst,
int smoothtype=CV_GAUSSIAN, int param1=3,
int param2=0, double param3=0,
double param4=0); (程序 4) OpenCV 中提供的图像的平滑处理的函数为
cvSmooth,它的声明如程序 4 所示,这个函数提供了很多种平滑算法供选择,包括简单不带尺度变换的模糊、简单滤波、高斯滤波、中值滤波和双向滤波等。在这里,我们采用了中值滤波来对经过了灰度化的图像进行滤波。
中值滤波的计算原理为:对于一幅图像,选取 N*N 像素大小的窗口,其中 N 为奇数,对于图像中的每一个能够放置这个窗口的位置,取出这个窗口中的所有像素点,将所有像素点的灰度值排序。由于 N 为奇数,那么在所有的 N*N 个像素点中必有一个中值,然后用此中值代替原窗口中心像素点的像素值。
3.3 背景差分法和帧间差分法的结合
在交通检测系统中,由于车辆颜色各异,有一些
车辆的灰度范围与道路背景的灰度范围比较接近,在这种情况下,使用背景差分法往往很难得到清晰完整的车辆运动区域,往往会出现区域不联通和边界不清
const CvArr* src2,
CvArr* dst); (程序 5)
在 OpenCV 中实现两帧差分运算的函数为cvAbsDiff,如程序 5 所示,它的功能就是将两幅灰度图像做差再取绝对值,它得到的结果也是灰度图像。
图 1 展现的是交通视频中的某一帧图像经过一系列处理而得到的灰度图与此时动态生成的虚拟背景做差分之后的二值化图像。此时,车辆和行人已经能够分辨出来了。
类似的方法,通过函数 cvAbsDiff 将当前帧的灰度图像与上一帧的灰度图像做差分,车辆的边缘信息得到了比较好的保留,但帧间差分法也导致了车辆区域内部形成了一定程度的空洞,这是由于车辆内部的颜色比较一致而导致的。而这个缺点就可以通过融合背景差分法而得到弥补。
背景差分法与帧间差分法相结合,就是先分别通过这两种方法所得到灰度图像,并分别对它们进行二值化处理,最后对这两幅二值图像进行按对应像素或运算而得到的。在 OpenCV 中,两幅图像的对应像素进行或运算的函数如程序6 所示,其中参数src1 和src2 是两幅输入图像的指针,而参数dst 是存放结果的图像指针,mask 参数仍然表示一个蒙板,只有当mask 中与输入图像对应像素的元素值为1 时,才对输入图像中的对应像素进行运算,从而使两幅图片的或运算能够更加灵活的实现。而在本系统所使用的方法中,两幅图像直接无蒙板做或运算即可。图3显示了图2与图1进行或运算之后得到的结果。可以看出,相比图1和2,图3的车辆内部更加饱满,边缘也更加清晰,每一辆车的白色块相对更加的完整,用肉眼也可以比较容易分辨出一辆一辆的车,这样能够为后续的车辆的识别运算提供保障。
void cvOr(const CvArr* src1, const CvArr* src2, CvArr* dst,
const CvArr* mask=NULL); (程序 6)
3.4 车辆的发现
在得到二值化的感兴趣区域之后,我们就开始使用得到的二值图像进行车辆的发现,本系统采用了一种基于检测线的方法进行车辆的发现。该方法的基本流程如下:

1)通过视频与真实世界的空间透视关系,能够估计出车辆的长宽的大致范围。在车辆可能进入的垂直方向设置检测线,检测线的宽度大概在估计出的车辆长度的一半。如图4 所示,车辆可能进入的位就在视频图像的下部与上部两个地方,于是我们就设置两条宽度不同的检测线。
2) 将检测线纵向切割成宽度为两个像素的小矩形条。根据每个小矩形中的感兴趣区域的多少来决定 它是否是一个合格的区域,计算方法如公式(3)所示:
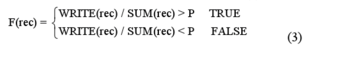
其中,F(rec)表示参数rec合格的区域,WRITE(rec)表示该小矩形内感兴趣像素点的个数,而SUM(rec)表示该小矩形内像素点的总数,P表示一个阈值,在本系统中取P=0.7。
3) 算法从检测线上左边第一个小矩形开始判断,遇到第一个F(rec)的结果为TRUE 的小矩形,记录它的位置,然后维续向右判断,直到遇到第一个F(rec) 结果为FALSE 的小矩形时,就结束这个感兴趣区块的扩TRUE的充。此时,从记录的第一个F(rec)的结果为小矩形到最后一个F(rec)的结果为TRUE 的小矩形就产生了一块连续的“合格”小矩形区间。
4) 判断这个区间的宽度是不是大于预设的一个阈值W,如果大于W,那么认为从第一个“合格”小矩形到最后一个“合格”小矩形所构成的大矩形就是一个候选的新的车辆位置,否则就认为它是噪声。
5) 重复步骤3-4,直到判断到检测线中最后的一个小矩形为止。
6) 对于新产生的候选车辆位置,进行重复性判断,如果这个矩形与任何标示现存车辆的矩形的重合度小于一个阈值P,那么就认为这个候选区域是一个新发现的车辆,建立这个车辆的对象,否则,则认为它是现有车辆的一部分。其中。P=D(AB) D(A)+D(B).D(AB 表示区域A与区域B重合的区域的大小,而D(A)与D(B)分别表示区域A与区域B的面积。
















 工商网监
工商网监
评论