语音芯片LD3320 芯片是一款基于非特定人语音识别技术的声控芯片, 可以实现语音识别及MP3 播放功能。为了能使芯片正常工作,共有42 个引脚需要配置,而单独使用AT89S52 单片机无法直接完成对该芯片的配置。
2014-12-18 10:54:41 3070
3070 
为进一步提高模拟训练的训练效果,利用智能语音芯片设计开发了某模拟训练器的示教与回放系统。该系统综合运用语音识别、声强检测、语音合成、数据记录等手段,完成对操作过程的实时记录与回放,取得了良好的训练
2014-03-28 10:40:192260 非特定人语音识别技术研究的最终目的是让计算机等设备能够“听懂”人类语音,提取出语音中所包含的特定信息,成为人机通信和交互最便捷的手段。
2014-10-21 10:08:221559 
本汉语语音识别系统是一个非特定人的、孤立音语音识别系统。其中孤立音至少包括汉语的400多个调音节(不考虑声调)以及一些常用的词组。##测度估计技术可以采用动态时间弯折DTW、隐马尔可夫模型HMM
2014-12-16 13:44:373123 
随着高新技术在军事领域的广泛运用,武器装备逐步向高、精、尖方向发展。传统的军事训练由于训练时间长、训练费用高、训练空间窄,常常不能达到预期的训练效果,已不能满足现代军事训练的需要。为解决上述问题,模拟训练应运而生。
2015-07-27 11:13:072357 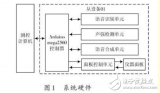
本系统采用的主控MCU为Atmel公司的ATMEGA128,语音识别功能则采用ICRoute公司的单芯片LD3320。LD3320内部集成优化过的语音识别算法,无需外部FLASH,RAM资源,可以很好地完成非特定人的语音识别任务。
2020-02-17 15:07:442366 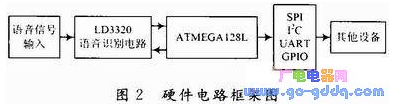
特定人语音识别的方法有哪些?特定人语音识别技术在汽车控制上的应用是什么?
2021-05-14 06:34:04
,设置寄存器传入LD332X / LD3320 芯片,就可以完成语音识别功能。直接将芯片设计加入系统中即可以增加非特定人语音识别功能。# #
目前已有的语音识别芯片,一般基于特定人语音识别技术
2009-12-16 12:00:28
各位大神,我想完成用SPCE061A来实现非特定人的语音识别技术,并能够使得发出的命令能在LCD上显示,不知有没有能够指导一下的,大概的框架和模块,拜托各位了。。。
2015-01-06 22:47:31
语音识别系统在智能家庭系统中的应用是什么?
2021-05-31 06:54:34
本帖最后由 linchenfeng 于 2014-8-10 21:33 编辑
非特定人声识别单元,初步测试已经完成,可以识别和合成语音。但是对于噪声干扰和识别的距离以及准确性还需要进一步优化
2014-08-07 13:31:03
² 非特定人语音识别² 语音支持 35 种语言, 如中文、英语、日语等² BC009 支持二种连接方式:一、25MM 间距端子线连接二、直接将模块焊接到主板上 2.应用范围智能家电:智能语音灯具语音播报
2018-10-26 14:49:00
FPGA和Nios_软核的语音识别系统的研究引言语音识别的过程是一个模式匹配的过程 在这个过程中,首先根据说话人的语音特点建立语音模型,对输入的语音信号进行分析,并提取所需的语音特征,在此基础上建立
2012-08-11 11:47:15
`产品特征:1、单芯片语音识别解决方案(非特定人识别)2、ISD9160自带145kflash,可以做20条左右指令,另外可以外加SPI-FLASH扩展指令数量。3、采用***先进语音识别算法
2017-04-08 15:08:51
LD3320语音识别模块+MP3-TF-16P模块实现语音交互功能利用LD3320语音识别模块可以实现非特定人声语音控制单片机io口动作,而加入MP3-TF-16P语音播放模块,可以让语音识别富有
2022-02-15 06:35:24
LD3320是非特定人(不用针对指定人)语音识别芯片,即语音声控芯片。最多可以识别50条预先内置的指令。工作模式:LD3320(LDV7)语音模块可以工作在以下三种模式:普通模式:直接说话,模块直接
2022-02-18 06:32:52
一、概述1.芯片介绍LD3320 是一颗基于非特定人语音识(SI-ASR:Speaker-Independent Automatic Speech Recognition)技术的语音识/声控芯片
2021-07-26 06:54:04
为了提高广大单片机爱好者学习单片机的兴趣,凌阳科技大学计划教育推广中心推出了应用SPCE061A作为主控制器,外加电机驱动电路制作的语音识别机器人。该机器人采用特定人语音识别对机器人进行控制,可以
2011-03-08 17:09:02
这是说话人语音识别的相关资料,大神们来看看啊,顺便帮小弟做一个用电脑麦克风识别说话人的程序,谢啦
2012-05-31 15:17:36
使用的是STC单片机,LD3320LD3320 是一颗基于非特定人语音识别(SI-ASR:Speaker-IndependentAutomatic Speech Recognition)技术的语音识别/声控芯片。提供了真正的单芯片语音识别解决方案。
2016-06-29 10:44:29
的项目,当初开始研究LD3320芯片,无意中发现了ISD9160。ISD9160在BOM上可以直接驱动,特别适合语音控制方案。另外额外的还有语音识别的功能,我要做的是非特定人语音识别智能家具设计。如图
2016-12-23 09:19:55
应用。通过软件支持,ISD9160可以实现特定人和非特定人语音识别。其中非特定人语音识别支持九种语音,方便客户开发国际化的产品。客户在开发的时候,使用Nuvoton提供的ASR Tool工具,只需
2020-08-13 12:16:03
集成电路技术和微机械加工制造技术的进步,微型智能射频卡得到了发展,在低功耗IC技术方面的突破,为发展小型、低功耗主动射频卡创造了条件。 本文以新型射频芯片nRF905为例,设计了一个工作在微波频段的主动式射频识别系统,给出了系统中关键的通信模块设计方案。
2019-07-26 07:21:50
开发并测试了安装在汽车内、使用简单离散字的特定发音人语音识别系统。
2019-11-04 07:23:41
非特定语音识别有杂音干扰,如何用外围电路解决这个问题?
2018-01-31 10:08:46
非特定人的语音识别任务。1 整体方案设计1.1 语音识别原理在计算机系统中,语音信号本身的不确定性、动态性和连续性是语音识别的难点。主流的语音识别技术是基于统计模式识别的基本理论,原理如图1所示
2014-03-17 13:31:40
识别系统设计的可行性,并给出了设计方案。通过多次测试结果表明,本系统具有电路运行稳定,语音识别率高,成本低等优点。同时借助于LD3320的MP3播放功能,该系统具有一定的交互性和娱乐性。移植性方面,系统
2021-01-13 15:54:14
基于DSP的汉字语音识别系统如何实现
2021-03-12 06:33:15
基于HMM的语音识别系统是怎么训练的?有哪些步骤?
2021-12-23 06:16:50
基于LabVIEW的语音识别系统
2020-03-07 16:41:15
请大家帮帮忙,基于LabVIEW的语音识别系统,要求先录几个人的声音做样板,然后再让其中一个人说话,能辨别出是谁说的
2013-05-16 11:16:15
语音识别是机器通过识别和理解过程把人类的语音信号转变为相应文本或命令的技术,其根本目的是研究出一种具有听觉功能的机器。本设计研究孤立词语音识别系统及其在STM32嵌入式平台上的实现。识别流程是:预
2021-08-06 08:32:00
设计的台灯采用的主控芯片是性能较高的STM32F103C8T6单片机芯片,采用中断方式对台灯进行按键控制,并通过基于LD332O语音识别模块,利用非特定人语音识别技术对台灯的工作状态进行语音控制,同时实现了...
2022-01-19 06:04:27
特定人语音识别的方法有哪些?特定人语音识别系统是由哪些部分组成的?如何去实现一种特定人语音识别系统?
2021-05-19 06:44:14
现在社会发展的这么快,什么高科技都涌现出来,什么智能机器人啦,智能手机等,有很多在这里就不一一列举了,在这里我们要说的就是语音识别系统了,现在嵌入式产品如此的多,就像一些智能空调啦,我们可以对着他说
2021-12-20 07:52:03
嵌入式语音识别系统是什么?嵌入式语音识别系统在生活中的应用有哪些呢?
2021-12-23 08:27:03
导读:微软今天宣布,其会话语音识别系统的误率达到了5.1%,是目前为止最低的。
[img][/img]
这一数据超过了微软人工智能和研究团队去年5.9%的误差率,并将其准确性与专业的人
2017-08-23 09:18:35
随着计算机技术和信息技术的迅速发展,语音口令识别已经成为了人机交互的一个重要方式之一。语音口令识别系统将根据人发出的声音、音节或短语给出响应,如通过语音口令控制一些执行机构、控制家用电器的运行或做出
2019-09-03 08:27:23
(GMM+HMM+NGRAM)概述)。一段时间后老板就布置了具体任务:在我们公司自己的ARM芯片上基于kaldi搭建一个在线语音识别系统,三个人花三个月左右的时间完成。由于我们都是语音识别领域的小白,要求...
2021-07-29 08:59:19
怎样去搭建一个基于kaldi的嵌入式语音识别系统呢?
2021-12-23 09:30:05
怎样去搭建一个基于kaldi的嵌入式在线语音识别系统?分为哪几个阶段呢?
2021-10-28 08:37:01
设备说明:本设备使用具有两个usart串口的stc12c5a60s2作为MCU主控,SNR3512作为语音识别模块,JQC80作为语音模块,esp8266作为联网模块。本设备可以实现非特定人声的语音
2021-12-06 08:16:18
语音与“家电沟通”,控制其开启和关断。基本思路:作品融合单片机技术、基于非特定人的语音识别技术、无线信息发传输技术为一体。首先采集人的语音命令,通过语音识别技术识别出命令,由单片机将命令处理成对家用电器...
2021-09-15 06:50:56
该设计运用三星公司的S3C2440,结合ICRoute公司的高性能语音识别芯片LD3320,进行了语音识别系统的硬件和软件设计。在嵌入式Linux操作系统下,运用多进程机制完成了对语音识别芯片
2021-11-04 09:03:09
语音识别是什么?怎样去设计并制作出基于STM32的孤立词语音识别系统呢?
2021-11-08 07:04:19
求matlab特定人语音识别的程序,或者思路也行
2012-03-31 15:03:58
音乐语音识别系统的硬件电路该如何去设计?音乐语音识别系统的软件该如何去实现?
2021-12-23 08:50:56
一种基于FPGA技术的多按键状态识别系统的设计方案
2021-05-06 08:44:59
SVM多类分类方法是什么?嵌入式系统开发环境怎么搭建?基于SVM的0MAP5912非特定人嵌入式语音识别系统的实现方法
2021-06-01 06:47:44
本系统是基于数字通信原理、利用集成单芯片窄带超高频收发器构建的无线识别系统。阐述了该无线射频识别系统基本工作原理和硬件设计思路,并给出了 程序设计方案的流程图。从低功耗、高效识别和实用角度设计适用于
2019-08-14 06:49:06
完成语音识别功能。直接将芯片设计加入系统中即可以增加非特定人语音识别功能。
#
目前已有的语音识别芯片,一般基于特定人语音识别技术,芯片在出厂后无法修改识别的条目只能识别出厂前预制的识别内容
2009-12-16 11:59:08
: 1、识别率高达95%,无需联网,只需一颗芯片即可搞定, 2、非特定人声的语音识别,即只要是说同样的指令,谁说都可以,不论男女老少都可以识别。3、识别的指令只需满足3-8个字,具体是什么词,由客户自定义
2018-06-13 10:50:02
谁能告诉我 ,设计一个语音电子锁,要能够用特定人的声音开锁,用什么语音识别芯片可以做到呢?
2012-11-15 20:46:01
详细介绍了一种非特定人的数码语音识别算法:连续距离密度分段概率模型,同时给出了基于ADSP2181 DSP芯片的语音识别模块的实现方案。
2009-04-22 15:30:00 30
30 详细介绍了一种非特定人的数码语音识别算法:连续距离密度分段概率模型,同时给出了基于ADSP2171DSP芯片的语音识别模块的实现方案.
2009-04-27 16:33:2344 系统采用凌阳SPCE061A 单片机作为语音识别系统的主控芯片。通过硬件电路设计和软件代码部分成功的设计并实现了一种具有语音识别功能、语音提示(语音合成)及语音回放(语音编
2009-05-26 10:54:0845 语音识别技术是近年来十分活跃的研究领域,语音识别系统的实用化研究是语音识别研究的一个主要方向。近年来,消费类电子产品对低成本、高稳健性的语音识别功能的需求快速
2009-08-22 08:25:18115 语音识别技术是语音处理领域的一个关键技术。在研究了语音识别技术原理的基础上,本文提出了一种基于ARM 处理器的孤立词语音识别系统的设计方案,包括系统硬件设计、软件
2009-09-03 10:52:4977 本文介绍了一种基于TMS320C6711 DSP的非特定人、孤立词语音识别系统。本文首先介绍了语音识别技术的基本原理,然后对不同的识别算法在多种嵌入式系统平台上进行性能分析和比较
2010-07-27 17:49:1324 随着语音识别和语音合成技术的不断更新与发展,将语音识别技术应用于嵌入式产品中已得到广泛应用。SVM(支持向量机)作为统汁概率模型已经被证明是一种很好的识别模型。
2010-08-19 09:50:141089 
提出了一种特定人群 指纹验证 系统的A S IC 实现方案。实现了指纹数据量少(针对特定人群)、采集环境相对固定的指纹验证系统脱机工作。简要介绍了该系统采用的指纹验证算法, 重点介
2011-06-24 11:15:1037 语音控制的基础就是语音识别技术,可以是特定人或者非特定人的。非特定人的应用更为广泛,对于用户而言不用训练,因此也更加方便。语音识别可以分为孤立词识别,连接词识别,
2011-07-22 10:08:4812043 
详细介绍了一种非特定人的数码语音识别算法:连续距离密度分段概率模型(CDD-SPM),同时给出了基于ADSP2181 DSP芯片的语音识别模块的实现方案。
2011-10-12 15:59:32120 设计了一个嵌入式语音识别系统,该系统硬件平台以ADSP-BF531为核心,采用离散隐马尔可夫模型(DHMM)检测和识别算法完成了对非特定人的孤立词语音识别。试验结果表明,该系统对非特定
2012-07-12 14:02:320 本文首次提出了一种以专用语音处理芯片UniSpeech-SDA80D51为核心组成的非特定人车载音响语音控制系统的设计方案,并实现了系统样机的研制。
2012-10-23 10:04:402900 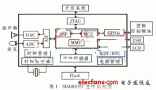
本文介绍了一种基于ARM的光学指纹识别系统的设计方案。##系统软件设计部分针对畸变纠正采用了四点转正算法。
2014-02-24 10:38:192020 基于STM32的语音识别系统的设计与实现
2015-11-09 18:03:0046 基于ARM的纸币号码识别系统,有需要的下来看看
2016-08-29 15:31:415 基于语音特征聚类的HMM语音识别系统研究_姚敏锋
2017-03-15 08:00:002 该设计运用三星公司的S3C2440,结合ICRoute公司的高性能语音识别芯片LD3320,进行了语音识别系统的硬件和软件设计。在嵌入式Linux操作系统下,运用多进程机制完成了对语音识别芯片
2017-10-15 10:53:426 本文介绍了一种基于ARM的光学指纹识别系统的设计方案。本方案采用ARM处理器作为控制核心,构建指纹识别算法的嵌入式系统的设计方法及过程。该系统采用光学指纹传感器(内建格科微电子有限公司的光学
2017-10-16 16:22:275 的模式识别系统,包括指纹图像获取、处理、特征提取和比对等模块。)设计方案,同时对该指纹识别系统的硬件架构进行了说明。该方案具有结构简单、可扩展性和移植性强等诸多优点。 图 1 所示是本嵌入式指纹识别系统的硬件框图。从图 1 中可以看到, 本系统主要
2017-10-17 16:19:1510 针对复杂状况下传统表情识别方法存在的问题,提出一种新的非特定人表情识别方法。该算法首先提取每张表情图像的HOG特征和Haar小波特征,然后将两种不同的特征串行融合得到整幅图像的特征,最后通过SVM
2017-11-22 17:22:250 语音控制在智能家居的应用为人民生活带来极大便利,但常规的非特定人语音控制会产生语音的误触发。本文在非特定语音识别的基础上,通过改进相应算法设计了一种特定人语音识别家居控制系统。系统采用MFCC算法
2017-11-27 14:10:584 随着计算机技术和信息技术的迅速发展,语音口令识别已经成为了人机交互的一个重要方式之一。语音口令识别系统将根据人发出的声音、音节或短语给出响应,如通过语音口令控制一些执行机构、控制家用电器的运行或做出
2019-04-23 15:52:53863 
LD3320是一颗基于非特定人语音识别(SI-ASR:Speaker-Independent Automatic Speech Recognition)技术的语音识别/声控芯片。提供了真正的单芯片语音识别解决方案。
2019-06-12 10:31:213021 嵌入式语音识别系统分为封闭域识别和开放域识别,封闭域识别范围围绕指定的字/词语集合,也就是说在开发系统的时候会设定好应识别的字或词语,对范围外的词语语音系统不会识别。
2019-06-12 11:38:092859 对比语音识别技术的两个发展方向,由于基于不同的运算平台,因此具有不同的特点。大词汇量连续语音识别系统一般都是基于PC机平台,而语音识别专用芯片的中心运算处理器则只是一片低功耗、低价位的智能芯片
2019-10-01 09:21:005253 
ASR Board 是一款基于Arduino的开源语音识别控制板,该模块只需要通过上位机软件发送指令即可设定要识别的关键词,不需要用户事先训练和录音,是一款高效的非特定人语音识别控制模块。更重要的是,它不仅能够“识别”语音,而且还能够播放语音,和用户进行互动。
2019-11-28 11:36:032765 
本文首先介绍了语音识别设置的删除,其次阐述了语音识别系统工作流程,最后介绍了语音识别系统的实现。
2020-04-01 09:47:403749 本文介绍了一种采用ARM处理器作为控制核心的非特定人语音识别系统的设计方案。
2020-04-11 11:17:371180 
斯坦福大学的一项研究显示,亚马逊、苹果、谷歌、IBM和微软的语音识别系统存在种族差异,对白人和黑人语音的识别率有高有低。
2020-05-18 09:37:31579 深圳唯创知音研发了一款,本地语音识别芯片,是低成本语音交互解决方案,单芯片可定制60条不同的识别命令词,并且符合蓝牙 V5.1 + BR + EDR + BLE 规范,是一款低成本、高可靠性的非特定人声识别方案;
2022-07-25 17:50:25996 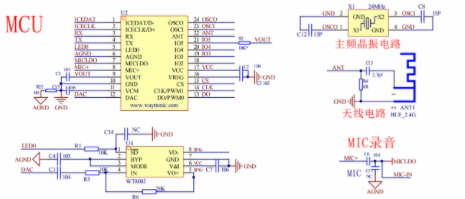
WTK6900H系列语音识别芯片,是深圳唯创知音研发的一款,低成本非特定人声语音识别芯片,支持语音对话、语音控制两种方式进行人机交互;3米内语音识别度可达90%以上;
2022-10-26 08:38:521317 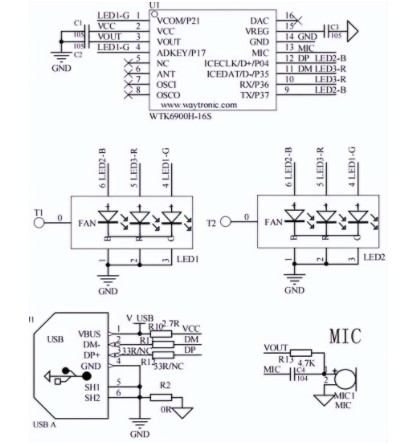
电子发烧友网站提供《基于OMAP5912的嵌入式非特定人连续语音识别系统.pdf》资料免费下载
2023-10-09 15:21:410 电子发烧友网站提供《基于DSP的车载语音识别系统方案设计.pdf》资料免费下载
2023-11-08 09:14:380
正在加载...
 电子发烧友App
电子发烧友App


















 工商网监
工商网监
评论