 电子发烧友App
电子发烧友App


基于矢量量化编码的数据压缩算法的研究与实现
As the rapid development of communications and information technology, data compression technology has become a powerful tool for people to work or do the scientific research on this information age. As a study of important issues on information research, data compression technology has been pay much attention to. Vector Quantization Technology, as an important branch in the field of data compression, with its excellent characteristics: high compression, encoding speed, clear and simple algorithm, has become powerful tools and methodologies in the area of image compression.
Aimed to the application with the way to Vector Quantization in the Static image of research goals, this thesis show you the detailed explanation of the basic Vector Quantization principle, related concepts and development status, the discussion the three technology key of Vector Quantization — code book design algorithm, code searching and code distribution. In detail elaborated LBG algorithm and most greatly drops which we can called MD algorithm in the code book design algorithm, based on inequality quick code-search in quick code-search and BAS algorithm and Prohibition search symbol index distribution algorithm in symbol index distribution. Finally, I analyzed the existing typical algorithm and improving algorithm, come up with my own realization based on the method of Vector Quantization and achieve good results.
KEYWORDS:data compression Vector Quantization LBG
目 录
摘 要 I
ABSTRACT II
第一章 绪论 1
1.1 课题的研究背景及意义 1
1.2课题研究现状 2
1.3 课题研究内容 3
第二章 矢量量化技术简介 4
2.1 数据压缩技术 4
2.2 矢量量化的定义及理论基础 8
2.3 矢量量化的相关概念 10
2.4 矢量量化的关键技术及技术指标 13
第三章 矢量量化的算法研究 16
3.1 矢量量化码书设计算法的研究 16
3.1.1 经典的LBG算法 16
3.1.2 MD算法 18
3.1.3 码书设计算法比较 19
3.2 码字搜索算法 20
3.2.1 基于不等式的快速码字搜索算法 20
3.2.2 等均值等方差最近邻搜索算法 21
3.3 码字索引分配算法 23
3.3.1 BSA算法 23
3.3.2 禁止搜索码字索引算法 25
第四章 矢量量化算法的实现 26
4.1 需求分析与整体设计 26
4.1.1需求分析 26
4.1.2 整体设计 26
4.2 矢量量化算法的实现过程及说明 27
4.2.1 初始码书的生成 27
4.2.2 LBG矢量量化 28
4.2.3 矢量量化码字索引与恢复 31
4.3 实验结果及评价 31
第五章 结论与展望 34
参考文献 35
致 谢 36
附录 37
摘 要
伴随着通讯与信息科技的迅猛发展,数据压缩技术己经成为信息时代人们工作与科研的有力工具。数据压缩技术,作为信息论研究中的一个重要课题,一直受到人们的广泛关注。矢量量化技术作为数据压缩领域里的一个重要分支,以它压缩比高、编码速度快、算法简单清晰等良好的特性,在图像压缩等领域都已成为有力的手段和方法。
本文以矢量量化在静止图像方面的应用为研究目标,介绍了矢量量化的定义,基本理论、相关概念及发展现状,重点讨论研究了矢量量化的三大关键技术–码书生成和码字搜索和码字索引分配。详细阐述了码书设计算法中的LBG算法和最大下降MD算法;快速码字搜索中的基于不等式快速码字搜所和码字索引分配中的BAS算法和禁止搜索码字索引算法等。
最后总结分析了现有典型的算法和改进算法并提出了自己的基于矢量量化算法的实现方法,编程实现了一个完整的数据压缩软件,取得了较好的效果。
关键词: 数据压缩,矢量量化,LBG
ABSTRACT
第一章 绪论
1.1 课题的研究背景及意义
1.1.1 研究背景
随着计算机和大规模集成电路的飞速发展,数字信号分析和处理技术得到很大发展,并已经广泛应用于通信、雷达和自动化等领域。数字信号的突出优点是便于传输、存储、交换、加密和处理等。一个模拟信号f(t),只要它的频带有限并允许一定的失真,往往可以经过采样变成时间离散但幅值连续的采样信号f(n)。对于数字系统来说,f(n)还需经过量化变成时间和幅值均离散的数字信号x(n)。
通信系统有两大类:一类是传输模拟信号f(t)的模拟通信系统;另一类是传输数字信号x(n)的数字通信系统。在任何数据传输系统中,人们总希望只传输所需要的信息并以最小失真或者零失真来接收这些信息。人们常用有效性(传输效率)和可靠性(抗干扰能力)来描述传输系统的性能。与模拟通信系统相比,数字通信系统具有抗干扰能力强,保密性好,可靠性高,便于传输、存储、交换和处理等优点。在数字通信中,码速率高不仅影响传输效率,而且增加了存储和处理的负担。
上个世纪八、九十年代,计算机技术和网络技术取得了飞速的发展,人类社会进入到了前所未有的信息化时代。随着信息时代的来临人们对通信业务的要求不断增长,在日常生活中,大量的信息数据需要传输、存储和处理。科学实验表明,人类从外界获取的知识之中,有80%以上都是通过视觉感知获取的【1】。眼睛获取的是图像信息,和语音、文字等信息相比,图像包含的信息量更大、更直观、更确切,因而具有更高的使用效率和更广泛的适应性,一幅图胜过千言万语, 图像信息是人类认识世界、自身的重要源泉。所以在信息数据中,绝大部分数据都是图像数据,而图像数据的传输常常要占用很大的带宽,需要很大的存储空间,因而怎样对图像数据进行行之有效地传输是一个极具挑战性的课题。
数字图像中包含的数据量十分巨大,例如,800 x 600分辩率的真彩色图像,其数据量为800 x 600 x 3=1440000字节,约1.4MB;而一分钟CD音质的音频文件一般需要l OMB左右的存储空间。在视频传输中PAL制式(25帧/秒)下,画面分辨率为640 x 480下,真彩色(24位)的图像序列,播放1秒钟的视频画面数据量为:640 x 480 x 3 x 25 = 23,040,000字节,相当于存贮一千多万个汉字所占用的空间。如此庞大的数据量,给图像的传输、存贮、传输线的传输率(带宽)以及计算机的处理速度等增加巨大的压力。由此可见,对降低传输成本,增加数据传输的可靠性,不断满足人们对信息传输的需求,图像压缩都具有十分重要的作用。为了解决好这个问题,我们就必须对图像进行编码压缩,在保证一定图像质量的前提下,有效地减少传输时所需的数据量和占用的频带。
1.1.2 研究意义
图像压缩就是在没有明显失真的前提下,将图像的位图信息转变成另外一种能将数据量缩减的表达形式,即去处冗余信息。首先,尽管图像中数据量很大,但其行、列以及帧间都具有极强的相关性或冗余信息。即一个象素的灰度值,总是和它周围的象素的灰度值有着某种关系,可以由它们推算表示出来,应用某种方法提取或减少它们之间的这种相关性,即可实现图像压缩。其次,大部分图像视频信号的最终接收者都是人眼,而人类的视觉系统是一种高度复杂的系统,它能从极为杂乱的图像中抽象出有意义的信息,并以非常精练的形式反映给大脑。人眼对图像中的不同部分的敏感程度是不同的,如果去除图像中对人眼不敏感或意义不大的部分,对图像的主观质量是不会有很大影响的,也实现了图像压缩。正由于图像压缩的必要性和可能性,图像压缩编码研究成为一个越来越活跃的领域。在诸如基于Internet的多媒体通信、可视电话、数字电视,多媒体计算机等领域得到了广泛的应用。
1.2课题研究现状
矢量量化的基本理论早在二十世纪六七十年代已有人关注,而在二十世纪八十年代开始逐步完善起来。矢量量化是分组量化的一种,受到广泛注意和使用的分组量化方法是由黄和舒尔泰斯于1963年首先提出来的【2】,他们指出分组量化的实现方法:首先与正交矩阵相乘将相关的采样变换为不相关的采样,然后再在每组固定的总比特数限制下,将不同的量化比特数目分配给每个不相关的采样值。1979年,格尔肖在他的论文【3】中详细阐述了分组量化的一般性理论,它将贝内特早年关于均方误差准则的量化模型推广到分组量化中。
将矢量量化技术推向研究高潮和推广应用应归功于1980年由Linde. Buzo和Gray提出来的一种有效的LBG矢量量化码书设计方法【4】,该文献己经成为矢量量化的经典文献,是矢量量化技术发展的基石。
在20多年历程中,学者们在以下五个方面对矢量量化技术展开研究:
1. 针对基本矢量量化器复杂度大和比特率固定的缺点,开发其它类型的矢量量化器;
2. 针对基本矢量量化器的LBG码书设计算法容易陷入局部极小、初始码书影响优化结果和计算量大的缺点,学者们引入了神经网络、优化理论、模糊集合等技术,提出了各种各样的码书设计算法;
3.在矢量量化编码场合中,针对基本矢量量化器的穷尽搜索编码算法的计算量大和比特率固定的缺点,提出各种各样的快速码字搜索算法和变比特率码字搜索算法;
4. 矢量量化技术的应用;
5. 考虑到信道噪声将会在矢量量化解码端引入额外失真,学者们开始研究码字索引分配算法以减少由于信道噪声引起的失真。
1.3 课题研究内容
1. 研究内容
1)对数据压缩的基本理论、技术标准、评价方法进行研究和分析
2)对基于矢量量化的数据压缩算法及其衍生算法进行逻辑上的分析和比较
3)选择矢量量化算法中的一种算法进行实现,完成一个完整的数据压缩软件
2. 本文结构安排
第一章为绪论,主要介绍了课题的研究背景,简要地阐述课题的研究意义最后,总结了本论文的研究内容。
第二章中,首先对数据压缩作了简要的综述;然后介绍了矢量量化数据压缩算法的起源,发展和相关的数学模型及理论基础;最后写了矢量量化的关键技术和矢量量化技术指标。
第三章是对矢量量化算法的研究,首先分别论述了矢量量化的三大关键技术的算法,介绍了码书设计中的LBG算法和最大下降算法;码字搜索算法中的基于不等式的快速码字搜索算法和等均值等方差最近邻搜索算法;码字索引分配算法中的BSA算法和禁止搜索码字索引算法。
第四章是矢量量化算法的实现。详细介绍了矢量量化算法的实现过程,并对实验结果进行了分析和评价。
第二章 矢量量化技术简介
2.1 数据压缩技术
2.1.1数据压缩技术的发展
数据压缩的研究过程一直有两个发展方向【5】:一个是许多数学家所致力于的建立信源和数据压缩的数学模型,并从中找出衡量数据压缩质量的技术指标及最优压缩性能指标;另一个则是众多的工程技术人员所进行的工作,他们的研究重点为建立一个能实现数据压缩功能的系统,以服务于工程应用,或者对这些数据压缩系统进行分析或模拟,以确定它们的性能指标。
不论是理论研究还是工程实践,1977年以前,数据压缩作为信息论研究中的一项内容,主要是有关信息嫡,数据压缩比和各种编码方法的研究,即按某种方法对源数据流进行编码,使得经过编码的数据流比原数据流占用较少的空间。其中基于符号频率统计的霍夫曼编码具有良好的压缩性能,一直占据重要的地位,不断有基于霍夫曼编码的改进算法提出。
随着计算机技术的飞速发展,数据压缩作为解决海量信息存储和传输的支撑技术受到人们的极大关注。1977年,两位以色列科学家Jacob Ziv和Abraham Lempel发表了论文”A universal algorithm for sequential data compression”,提出了不同于以往的基于字典的压缩算法LZ77【5】。1978年,又推出了改进算法LZ78。他们的研究把无失真压缩的研究推向了一个全新的阶段。
随着信号处理研究的不断的发展,数字图像信号、语音信号等都被大量的引入到有关的领域中。由于图像信息占用较多的存储空间,而图像通信又是目前非话业务的主流,因此数据压缩技术在图像通信中得到了最广泛的应用。
在图像编码中,最早研究的是预测编码,曾作为经典理论而登载于各种专著,并得到广泛的应用。近年来,随着神经网络理论的兴起,有人采用BP网进行非线性预测的尝试,并取得了较好的效果。
1969年,在美国举行首届”图形编码会议”,表明图像编码以独立的学科挤身于学术界。而变换编码在五年左右的时间内成为研究热点。变换编码中的DCT编码由于编码效果较好,运算复杂度适中等优点,已经发展成为目前国际图像编码标准的核心算法。
80年代中后期,众多研究者相继提出了在多个分辨率下表示图像的方案,主要的方法有:子代编码,金字塔编码,小波变换编码等。基于小波变换的方法具有较高的压缩性能,己发展为JPEG 2000的核心算法。在近年来的甚低码率的编码研究中,有一种称之为模型基的编码方法颇引人注意,这种方法压缩比高,但适用于场景比较简单的特定场合。
在1988年左右,有人提出了一种分形图像编码的压缩方案。这种方案思路新颖、压缩潜力大、并具有解码分辨率无关性等优点,是一种很有潜力的编码方法。
尽管用软件压缩方法可以较好地实现数据压缩的目的,但由于压缩算法的运算量较大,需要很高的运算速度和存储空间,这对现有系统来说是很大的负担。为了解决这个问题,人们在继续探索数据压缩技术的同时,着手研制生产高性能的芯片和系统。一般在对时间要求不高的场合采用软件压缩,而对运行速度有特殊要求的情况下,可使用硬件压缩。不过,目前硬件压缩的开销远远大于软件压缩的开销。
2.1.2 数据压缩技术的分类
数据压缩的研究已有几十年的历史,其间,人们提出了各种各样的压缩算法。在分类上,也存在几种不同的方法,有人按编码失真程度或者说按压缩过程的可逆性将数据压缩编码分为两种类型:无失真压缩编码 (Noiseless Coding)与有失真压缩编码 (Noise Coding);有人按编码基建模的不同将数据压缩分成模型基编码和波形基编码;又有人将它分为第一代压缩编码和第二代压缩编码;还可按压缩技术所使用的方法进行分类,可分为预测编码(Predictive Coding)、变换编码(Transform Coding)和统计编码(Statistical Coding)三大类。目前,较为认可的是第一种分类方法【6】。
1.无失真压缩
无失真压缩也可称之为冗余度压缩(Redundancy Compression),在数字图象压缩中,有3种基本的数据冗余:编码冗余、像素间冗余以及心理视觉冗余。而无失真压缩就是利用数据的统计冗余进行压缩,除去或尽量除去数据中重复和冗余部分,而不丢失其中的任何信息,可完全恢复原始数据而不引入任何失真,但压缩率受到数据统计冗余度的理论限制,一般为2:1到5: 1这类方法广泛用于文本数据、程序和特殊应用场合的图像数据(如医学图像等)的压缩.由于压缩比的限制,仅使用无损压缩方法不可能解决图像和数字视频的存储和传输问题。
常用的无失真压缩技术有:哈夫曼编码,算术编码,游程编码,LZ编码等。
1)行程长度编码(RLE)
行程长度编码(run-length encoding)是压缩一个文件最简单的方法之一。它的做法就是把一系列的重复值(例如图象像素的灰度值)用一个单独的值再加上一个计数值来取代。比如有这样一个字母序列aabbbccccccccdddddd它的行程长度编码就是2a3b8c6d。这种方法实现起来很容易,而且对于具有长重复值的串的压缩编码很有效。例如对于有大面积的连续阴影或者颜色相同的图象,使用这种方法压缩效果很好。很多位图文件格式都用行程长度编码,例如TIFF,PCX,GEM等。
2)LZW编码
这是三个发明人名字的缩写(Lempel,Ziv,Welch),其原理是将每一个字节的值都要与下一个字节的值配成一个字符对,并为每个字符对设定一个代码。当同样的一个字符对再度出现时,就用代号代替这一字符对,然后再以这个代号与下个字符配对。LZW编码原理的一个重要特征是,代码不仅仅能取代一串同值的数据,也能够代替一串不同值的数据。在图像数据中若有某些不同值的数据经常重复出现,也能找到一个代号来取代这些数据串。在此方面,LZW压缩原理是优于RLE的。
3)霍夫曼编码
霍夫曼编码(Huffman encoding)是通过用不固定长度的编码代替原始数据来实现的。霍夫曼编码最初是为了对文本文件进行压缩而建立的,迄今已经有很多变体。它的基本思路是出现频率越高的值,其对应的编码长度越短,反之出现频率越低的值,其对应的编码长度越长。
2.有失真压缩
有失真压缩也可称为嫡压缩(Entropy Compression),这是一种不可逆压缩。他利用了人类视觉对图像中的某些频率成分不敏感的特性,在压缩过程中会损失掉一部分信息,这样,其原始数据不能由压缩数据完全恢复出来。他是以丢失部分信息为代价而获得较高的压缩率。当然,为了确保恢复后的数据能基本保持原数据的特征,这种失真应该限制在某个规定的范围之内。无失真压缩主要有两大类型:特征抽取和量化方法,特征抽取的典型例子如指纹、汉字的模式识别,一旦抽取出足以有效表征与区分不同模式的特征参数,便可用它取代原始的图像数据,这一类方法一般是用于特定的环境。量化则是更为通用的熵压缩技术,除了直接对无记忆信源的单个样本做所谓的零记忆量化外,还可以对有记忆信源的多个相关样本映射到不同的空间,去除了原始数据中相关性后再做量化处理,由此又引出了预测编码和变换编码。
1)矢量量化编码
矢量量化编码利用相邻图象数据间的高度相关性,将输入图象数据序列分组,每一组m个数据构成一个m维矢量,一起进行编码,即一次量化多个点。根据仙农率失真理论,对于无记忆信源,矢量量化编码总是优于标量量化编码。
2)预测及内插编码
一般在图象中局部区域的象素是高度相关的,因此可以用先前的象素的有关灰度知识来对当前象素的灰度进行预计,这就是预测。而所谓内插就是根据先前的和后来的象素的灰度知识来推断当前象素的灰度情况。如果预测和内插是正确的,则不必对每一个象素的灰度都进行压缩,而是把预测值与实际象素值之间的差值经过熵编码后发送到接收端。在接收端通过预测值加差值信号来重建原象素。
3)变换编码
变换编码就是将图象光强矩阵(时域信号)变换到系数空间(频域信号)上进行处理的方法。在空间上具有强相关的信号,反映在频域上是某些特定的区域内能量常常被集中在一起,或者是系数矩阵的分布具有某些规律。我们可以利用这些规律在频域上减少量化比特数,达到压缩的目的。由于正交变换的变换矩阵是可逆的且逆矩阵与转置矩阵相等,这就使解码运算是有解的且运算方便,因此运算矩阵总是选用正交变换来做。
图2.1 数据压缩技术的分类
2.1.3 数据压缩算法的度量标准
对于一种数据压缩算法的性能,有一定的衡量标准,为了后面几章描述的方便,也为不至于产生歧义,对这些标准作以简单的介绍【7】。
1.算法性能评价
1)压缩比(CR:Compression Ratio):
压缩比定义为原始数据量与压缩后量的比值,即
压缩比 = 原始数据量/压缩后量
2)计算复杂度:
计算复杂度可以用算法处理一定量数据所需的基本运算次数来度量。如处理一帧有确定的分辨率和颜色数的图像所需的加法次数和乘法次数。
压缩算法分为编码部分和解码部分,如果两者的计算复杂度大至相当,则算法称为对称的,反之称为非对称的。
2.图像质量评价
1)均方误差(MSE)
对于模拟信号,设原始数据为x(t),编码、解码后的数据为y(t),二者之差为e(t),即e(t) = x(t) - y(t)。则e(t)的方差如公式2.1所示:
(2.1)
通常误差均值μe=0, 又称为均方误差(Mean Squared Error)。
2)信噪比(SNR):
对于离散信号,设原始数据为 ,编码、解码后的数据为 ,它们的差值为 的均方误差为 ,信噪比(Signal to Noise Ratio)定义为原始数据方差 与重建数据误差方差 的比值如公式2.2所示:
(2.2)
3)峰值信噪比(PSNR):
对于离散图像数据,在信噪比的计算中常用图像数据中的最大值xmax来代替均方根值бx,得到峰值信噪比如公式2.3所示
(2.3)
2.2 矢量量化的定义及理论基础
2.2.1 矢量量化的起源及发展
矢量量化基本理论早在20世纪六七十年代己有人关注,八十年代开始逐步发展完善起来。1956年,Steinhaus第一次系统阐述了最佳矢量量化问题【8】;1978年,Buzo第一个提出实际的矢量量化器。1980年,Linde, Buzo和Gray将Loyd-Max算法推广,提出了一种有效的矢量量化码书设计算法一一LBG【4】算法,将矢量量化技术的研究和推广应用推向了高潮,成为矢量量化技术发展的里程碑。
在20多年的发展历程中,人们全面研究了矢量量化的理论和应用,开发了多种类型的矢量量化器。虽然矢量量化技术研究已经日趋成熟,但仍存在很多有待解决的问题,如矢量量化码书标准与编码对象密切相关,不同应用场合下码书结构、尺寸以及矢量维数都不相同。矢量量化的压缩标准也一直没有提出。目前的研究大多停留在理论方面,各种优化的矢量量化器的硬件实现还有待于进一步的研究。因此,有关矢量量化技术的研究还有很多工作要做。
矢量量化在20多年的发展历程中,主要是从以下几方面得到了发展:
(1) 矢量量化器的研究,对基本矢量量化器复杂度大和比特率固定的缺点,开发其它类型的矢量量化器;
(2) 矢量量化码书设计算法研究:针对基本矢量量化器的LBG码书设计算法 容易陷入局部极小、初始码书影响优化结果和计算量大的缺点,学者们引入神经 网络、优化理论、模糊集合等技术,提出了各种各样的码书设计算法;
(3) 矢量量化码字搜索算法研究:在矢量量化编码场合中,针对基木矢量量 化器的穷尽搜索编码算法的计算量大和比特率固定的缺点提出各种各样的快速 码字搜索算法和变化特率码字搜索算法;
(4) 矢量量化码字索引分配算法研究:考虑到信道噪声将会在矢量量化解码端引入额外失真,学者们开始研究码字索引分配算法以减少信道引起的失真。
2.2.2 矢量量化的定义及理论基础
1. 定义
一个维数为k,尺寸为N的矢量量化器可以定义为从k维欧儿里得空间 到一个包含N个输出(重构)点的有限集合C的映射Q【9】,表示为公式(2.4):
(2.4)
其中, 。
C是重构码字矢量集合,称为码书,其尺寸(大小)为N。码书的N个元素Yi称为码字或者码矢量,它们均为k维欧几里得空间 中的矢量。输入矢量空间 通过尺寸为N的矢量量化器Q后,被分割成N个互不重叠的区域又称为胞腔,这个过程称为输入矢量空间的划分。对 胞腔 定义为公式(2.5):
(2.5)
2. 理论基础
矢量量化的理论基础是香农的率失真理论。1948年,香农定义了信道容量,并证明只要编码速率不超过信道容量,符号就能以任意小的差错概率在该信道中传输。1959年,香农定义了率失真函数R(D),并证明只要R(D)不超过信道容量就能保证接收端的失真不超过给定阈值D。在数学上,R (D)定义为在给定失真D的条件下,系统所能够达到的最小码速率。对于幅值离散的信源, R(D)定义如下公式(2.6)所示:
(2.6)
其中, ,平均失真满足公式2.7:
(2.7)
式中d(X,Y)是失真测度,它表示输出采样值Y再现原始采样值X所引入的失真, P(Y/X)表示在己发送X的情况下接收到Y的概率。R(D)的单位为比特/采样。同样,也可以定义失真率函数D(R),它是率失真函数的逆函数,其含义为在定速率不超过R的条件下,系统所能够达到的最小失真,它是在维数k趋向无穷大时Dk(R)的极限,即 。
香农理论表明在速率受限的条件下或在平均失真受限的情况下,通信系统所能达到的最优性能。率失真函数通常又被作为理论最优值,如果一个系统的性能低于理论最优值,则一定可用更好的编码技术获得系统性能的改善;如果一个系统的性能接近理论最优值,则此系统已接近最优,无法再做太多改善;一个系统的性能不可能优于理论最优值。由香农理沦可知,理论上,矢量量化技术只要不断的增加矢量的维数k,编码的性能就可任意接近率失真函数,使系统性能达到最优。因此,香农的率失真理论指出了矢量量化技术的优越性,是矢量量化技术的理论基础。
2.3 矢量量化的相关概念
2.3.1 数学模型
设有一个信源采样数据序列,我们把每K个数据分成一组,每组数据都记录成矢量形式 (i =1,2 ,…,N ),称x为输入矢量。设 为一个K维输入矢量的集合。
再把T划分成M(
通常,我们把这M个子空间称为Voronoi胞腔(Cells),或者简称胞腔,有时也把它称为一个分类或分区。在每个胞腔R,中我们再找到一个代表元Yi,我们称所有这些代表元组成的集合C=( )为码书(Codebook)。这些代表元也称为码字(Codeword)集合1= (1,2,…, M}称为码字的索引集合。一个矢量量化器包括编码器和解码器两部分。编码器主要包括一个码书和一个量化器。
量化器Q(X)定义如式(2.9):
Q: T C;
当X 时,Q (X)= Yi (i=1 ,2,…,M). (2.9)
其中,Q(X)是一个多对一的函数,因此它是不可逆的。解码器主要包括一个与编码器相同的码书和一个码字检索器 (i)。
码字检索器 (i)定义如式(2.10):
: I C;
(i) = Yi,i=1,2,…,M. (2.10)
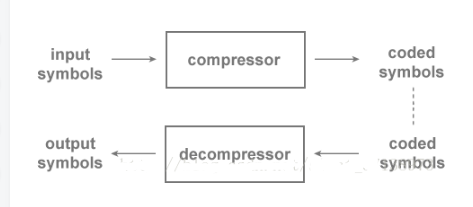
矢量量化的模型如下图2.2所示:
编码时:对任意一个输入的K维矢量X,计算Q(X)的值Yi,通过传输信道发送码字Yi的索引i到解码器端。
解码时:对输入的一个索引号i,查找码书中对应的码字Yi,输出Yi作为整个系统对矢量X的压缩恢复值。
图2.2矢量量化器结构示意图
2.3.2 量化器Q(x)相关问题
我们可以看出矢量量化可以等价于一个聚类问题。但如何聚类却有很多种方法。在上文我们说当 时,Q(X)= Yi;(i=1 ,2,…,M)。这是用胞腔来定义Q(X)。反过来,也可以用Q(X)和码字Yi来定义胞腔Ri,如式(2.11)所示:
(2.11)
当然,最初必须有一个明确的Q{X〕的定义。
如何判断 昵?通常定义一个失真测度函数 (实数域),d (X,Yi)表示用Yi来代表X时产生的误差。我们用它来判断一个矢量X到底属于那个胞腔:
当d (X,Y
因此,在这里量化器的主要工作就是利用失真测度函数d进行最近邻码字收索。有时候我们也把d(X,Yi)称作X与Yi之NJ的距离。
2.3.3 失真测度函数
我们要求失真测度函数满足以下两个条件:
(1)正定性: 当且仅当 X=Y时d( X,Y)=0;
(2)对称性: ;
有时候我们也加上第三个条件:
(3)三角不等式: ;
失真测度函数通常选择线性赋范空间中的范数,根据范数的定义,它们都满足上面三个条件。在本文中若无特殊声明,我们的d(X,Y)就取最常用的2范数的平方,即K维欧几里德空间中的距离的平方: ,我们把这个测度又称为平方误差测度。它虽然不满足三角不等式但是 却是满足全部这三个条件的。
事实上,判断一个矢量X属于哪个胞腔可以有很多种标准,在本文中,我们仅仅依据最近邻(NN: Nearest Neighbor)准则为判断标准。利用矢量失真函数d,我们再定义一个胞腔失真函数:
D: Voronoi Cells R (实数域);
X为处理矢量。
因为我们通常处理的数据量都是有限的,所以有限个实数之和也是有限的,从而D(Ri)是有限的。那么我们系统的总失真就如式(2.12)所示:
(2.12)
有时为方便起见,我们也把Er记为Er(C),C为码书,把D(Ri)记为D(Ri, Yi), Yi为Ri的代表元。显而易见的,Er是越小越好。
2.4 矢量量化的关键技术及技术指标
2.4.1 矢量量化的关键技术
矢量量化的三大关键技术是【8】:码书设计、码字搜索和码字索引分配。其中前两项最关键。
1. 码书设计
矢量量化的首要问题是设计出性能好的码书。如果没有码书,那么编码将成为无米之炊。假设采用平方误差测度作为失真测度,训练矢量数为M,目的是生成含N (N< M)个码字的码书,则码书设计过程就是寻求把M个训练矢量分成N类的一种最佳方案(如:使得均方误差最小),而把各类的质心矢量作为码书的码字。可以证明在这种条件下各种可能的码书个数为Num C,Num C满足公式2.13:
(2.13) 其中C为组合数。通过测试所有码书的性能可以得到全局最优码书。
然而,在N和M比较大的情况下,搜索全部码书是根本不可能的。为了克服这个困难,文献中各种码书设计方法都采取搜索部分码书的方法得到局部最优或接近全局最优的码书。所以研究码书设计算法的目的就是寻求有效的算法尽可能找到全局最优或接近全局最优的码书以提高码书的性能,并且尽可能减少计算复杂度。
2. 码字搜索
矢量量化码字搜索算法是指在码书已经存在的情况下,对于给定的输入矢量,在码书中搜索与输入矢量之间失真最小的码字。给定大小为N的码书C,如果矢量x与码字A之间的失真测度为d(x,y),则码字搜索算法的目的就是找到码字Y,使得失真测度满足公式2.14:
(2.14)
如果采用平方误差测度,对于k维矢量,每次失真计算需要k次乘法,2k一1次加法,从而为了对矢量x进行穷尽搜索编码需要Nk次乘法,N(2k -1)次加法和N-1次比较。可以看出,计算复杂度由码书尺寸和矢量维数决定。对于大尺寸码书和高维矢量,计算复杂程度将很大。研究码字搜索算法的主要目的就是寻求快速有效的算法以减少计算复杂程度,并且尽量使得算法易于用硬件实现。
3. 码字索引分配
在图示的矢量量化编码和解码系统中,如果信道有噪声,则信道左端的索引i经过信道传输可能输出索引J而不是索引i,从而将在解码端引入额外失真。为了减少这种失真,可以对码字的索引进行重新分配。如果书大小为N,则码字索引分配方案一共有N!种。码字索引分配算法就是在N!种码字索引分配方案中寻求一种最佳的码字索引分配使由信道噪声引起的失真最小。然而,当N较大时,测试N!种码字索引分配方案是不可能的。为了克服这个困难,各种码字索引分配方法都采用局部搜索算法,往往只能得到局部最优解。所以研究码字索引分配算法的目的就是寻求有效的算法尽可能找到全局最优或接近全局最优的码字索引分配方案以减少由信道噪声引起的失真,并尽可能减少计算复杂度和搜索时间。
2.4.2 矢量量化技术指标
1. 矢量量化压缩率
从矢量量化器的工作原理我们看出,码书确定之后,传输或者存储的压缩数据只是一系列码字的索引,这些索引本身并不包含原始数据的任何信息。因此矢量量化的压缩率很大,其比特率 bit/采样,也就是说压缩倍数为 B为原始采样数据所用比特(bit)数。
举例来说,当E=8, M= 256, K=64时,压缩率r=0.015625 bits/采样。压缩倍数为64。这样的压缩倍数显然很可观了从压 缩 率 与压缩倍数的计算公式我们看出,M一般是2的幂次。再例如,码书大小为150,码字索引要用8bits码书大小为256,码字索引也要用8bits.两种码书大小得到的数据压缩率相同,但后者压缩性能显然更好,所以一般我们用256而非150个码字,大小为2a的码书又称为q比特码书。
2. 信号恢复性能指标
通常信号质量有均方误差(MSE),信噪比(SNR),峰值信噪比(PSNR) 【11】等。在本文的讨论中,我们主要是灰度图像作为测试数据来源。我们的矢量量化技术的应用也主要是针对灰度图像的,因此以L级灰度图像为例,我们给出个指标的定义:设一副L级灰度图像有WXH个像亲,Xij为原始图像像素值,Yij为恢复图像像素值,那么
结过如下公式所示:
(2.15)
(2.16)
(2.17)
第三章 矢量量化的算法研究
3.1 矢量量化码书设计算法的研究
3.1.1 经典的LBG算法
如前所述,在矢量量化器的构造过程中,码本设计是最初的也是最重要的部分,根据各种码本设计算法的思想和迭代过程,我们可以将码本设计问题归结为Lloyd算法的两条基本准则【12】:
1. 最佳划分准则(Optimal Partition)
对于给定的码本 利用最近邻条件对训练矢量集进行重新划分。将每个训练矢量映射到与它之间失真最小的码字,最后形成一组以现有码本中的码字为中心的最佳划分。设训练矢量集为:
则训练矢量集的最佳分类 满足公式(3.1):
式中,i,j= 1,2,…,N (3.1)
如果存在D(x,yi )= D (x,yj ), 则将训练矢量归入码字yi的集合。
通常把这种最佳划分称为Voronoi划分,对应的子集凡称为Voronoi胞腔。设训练矢量x为k维的 ,如果用平方误差测度用来表征训练矢量x和码字yi之间的失真,即:
(3.2)
2. 质心条件 (CentroidC ondition)
利用由上面步骤得到的训练矢量划分集 重新计算它们各自的质心,得到新的码本:
(3.3)
(3.4)
式中, 代表子集Si中训练矢量的个数。
各种矢量量化码本设计算法基本都是上面两个步骤的交替迭代的基础上得到最后的码本。不难看出,码本生成过程中的计算量是随着码本矢量的维数k和码本尺寸N的增大而急剧增长的,对于需要高维大码本的矢量量化器来说,测试所有可能的码本来寻求全局最优码本将是十分困难的。为了克服这个困难,Linde . Buzo和Gray提出了经典的LBG算法。
1980年Linde,Buzo和Gray将Lloyd算法推广到矢量空间【8】, 算法的步骤简单描述如下:
Step 1 :给定初始码本 ,令迭代次数m=0,平均失真初始值为 ,给定失真下降阈值 ;
Step 2:用码本 中的码字作为质心,根据最佳划分原则将训练矢量集x划分为对应于每个码字的N个聚类,
满足: ;
Step 3:计算本次迭代的平均失真 判断相对误差是否满足 ,若满足,则停止算法,码本C(m)就是所求的码本;
否则,转Step 4;
Step 4:根据质心条件,计算各聚类的质心,即公式(3.5):
(3.5)
产生新码本 并置m=m+1,转Step 2
END:算法结束。
对于 LBG算法来说,初始码本选择的好坏将直接影响到后面的迭代计算结果,一个不好的初始码本会降低算法的收敛速度和最终码本的性能。因此在LBG算法中要对初始码本的选择作一定的处理。如果初始码本随机产生,即直接从训练序列中随机选择N个训练矢量作为初始码字,构成初始码本,可能会选到一些非典型的训练矢量作码字,因而该胞腔可能含有少数几个矢量甚至只有1个。另外,有可能把某些空间分得过疏。这可能会导致码本中的有些码字得不到充分利用,设计出来的码本性能就可能较差。
3.1.2 MD算法
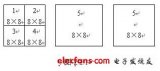
最大下降(MD)【13】码本设计算法与经典的LBG算法不同,它是一种分裂算法,而没有初始码本。在MD算法中,首先将训练矢量集 作为一个原始包腔,然后该包腔被它的最优分割超平面分成两个子包腔。依此类推,每次分裂产生一个包腔,直到生成最后的N个包腔,计算它们的质心,就可以得到设计的码本C={y}i=1,2,…,N)。与LBG算法相比,MD算法的计算量少并且所产生的码本性能好。另一方面,MD算法倾向于分割元素较多的胞腔,而不会去分割只有一个元素的胞腔,避免了非典型码字的形成,提高了码本的整体性能。在MD算法中,从L个包腔向(L+ l )个包腔扩展时,先要找出每个现有包腔的最优分割超平面,并计算它们各自带来的失真下降幅度,然后依据失真下降最大准则来选择究竟对哪一个包腔进行分裂。这在k维空间里是比较困难的事,需要大量的计算和比较。图3.2所示为MD算法的分裂过程示意图,图中每一步骤中有阴影的包腔 是当前符合失真下降最大准则的包腔,它被最优分割超平面分成下面的两个子包腔 和 。从L个包腔生成(L+ 1)个包腔的具体实现描述如下:
设超平面 将某胞腔 分成两个非空胞腔如式(3.6)所示:
(3.6)
式中 , , , T表示转置。
当 中的矢量被质心 量化时,胞腔的失真D(Si)定义为公式(3.7): (3.7)
则由分割超平面H,划分胞腔S,所引起的失真下降可表示为式(3.8):
(3.8)
若采用平方误差测度,则式(3.8)可以化简为式(3.9):
或 (3.9)
式中, 分别为 的元素个数, 。分别为 的质心。
从式(3.9)中可以看出,若胞腔 、 非空,则失真下降函数满足 。
我们将胞腔Si的最优分割超平面 定义为使胞腔 具有最大失真下降 的超平面。MD算法先计算出所有胞腔的最大失真下降值 , ,然后找出最大的最大失真下降值 ,即 ,最后将胞腔Sp分割成两个新胞腔。所以,L+l个胞腔是通过划分L个胞腔中具有最大失真下降的胞腔并保持其余胞腔不变而得到的。值得注意的是,每次分裂包腔时,并不需要重新计算所有包腔的失真函数,而只需找到新增加的两个包腔的最优分割超平面,计算它们各自的失真函数,再与其它包腔的失真函数值进行比较即可找出新的满足失真下降最大准则的包腔。产生最后的N个胞腔,一共需计算(2N-3)次最大失真下降函数。
3.1.3 码书设计算法比较
LBG算法是一种迭代算法,其迭代操作是标量量化劳埃德迭代操作的直接推广。LBG算法他具有如下的优点:
1. 不用初始化计算,可大大减少计算时间
2. 初始码字选自训练序列,无空胞腔问题
LBG算法在具有如上的优点的同时也有一些缺点和不足:
1. 在每次迭代的最佳划分阶段,从码书中搜索训练矢量的最近码字需要大量的存储空间和繁琐的计算;
2. 初始码书的选择影响码书训练的收敛速度和最终码书的性能;
码书设计的第一个缺点可采用各种快速码字搜索算法来解决,但这些算法无法改善码书的性能,第2个缺点产生的原因是:LBG算法是一种下降算法,每次迭代总能减少(至少保持不变)平均失真,而且每次迭代通常只能产生码书的局部变化,即每次迭代后,与旧码书相比,新码书不可能有非常大的变化。因此,一旦选定初始码书,该算法只能得到局部最优的码书,即LBG算法一般不能得到全局最优的码书。
与LBG算法相比,MD算法的计算量少且所产生的码书性能好。另一方面, MD算法倾向于分割元素较多的胞腔,而不会去分割只有一个元素的胞腔,而这种情况在LBG算法中却常常出现。然而,在MD算法中,多维胞腔的最优分割超平面的搜索是一个非常困难的问题。为减少计算量,这些算法的搜索范围被限制在与矢量空间的基本矢量正交的超平面上,这个矢量空间可由离散余弦变换(DCT)得到。但是,在这种限制条件下,算法常常搜索不到最优超平面。
3.2 码字搜索算法
3.2.1 基于不等式的快速码字搜索算法
1. 部分失真不等式排除法
部分失真搜索(Partial Distortion Search,PDS)算法【12】是一种较简单有效的最近邻搜索算法。它的基本思想是:在计算某个码字与输入矢量之间失真测度的过程中,始终判断累加的部分失真是否已经超过目前的最小失真,如果一旦超出则终止该码字与输入矢量之间的失真计算,转而开始计算另一个码字与输入矢量的失真测度。PDS常被用来与其他快速搜索算法结合起来运用,来排除其它快速算法最后无法排除的码字。
在编码过程中计算前面部分维数的失真距离,若其超出当前最小距离,则排除此码字为最匹配码字,否则继续搜索其它码字。
据如下(3.10)所示的柯西一许瓦尔兹不等式【14】:
(3.10)
可得一个不等式判据 若 ,则能保证 ,yi可被排除。因为|yi|可离线计算,所以节省了计算量。
首先判断 是否成立,若成立,则排除码字Yi否则,再判断是否满足 ,若满足,yi也可被排除。这缩小了搜索范围,他们还融入部分距离失真法节省计算量。双测试法的缺陷在于要求矢量的所有分量都为正值,而图像变换域编码中产生的变换系数有正有负,必须对这些系数进行正补偿,使所有矢量分量均大于零。
2. 整数投影法
整数投影法是一种适用于图像矢量量化的快速码字搜索算法。他们为每个m×m图像块 ,定义三种整数投影【14】,如下公式(3.11)(3.12)(3.13)所示:
块状投影: (3.11)
垂直投影: (3.12)
水平投影: (3.13)
在这三种投影的基础上定义了三个不等式条件,公式(3.14)(3.15)(3.16)所示:
(3.14)
(3.15)
(3.16)
可以证明,只要不满足上述任何一个条件,可排除yi是最匹配码字。
3. 三角不等式法
基于三角不等式d(Y i,yj) < d (x ,Yi)+ d (x ,yj)提出三种改进算法【14】。第一种算法先计算码书中每两个码字之间的距离,以当前匹配码字yi为中心,2hi(h i为输入矢量与当前匹配码字之间的欧氏距离)为半径划定搜索范围,即只搜索满足d(yj,yi)< 2hi的码字yj,j= 1,2,…,N;
第二种算法是将搜索范围定为满足:x-hi
第三种算法取前两种算法搜索区域的交集作为搜索区域。
这三种算法都涉及如何确定初始匹配码字的问题,一般取范数与输入矢量范数最相近的码字。第一、三种算法比第二种算法要多耗费存储空间来存储码字之间的距离。最小均方误差编码算法,取一长训练矢量序列,计算每个Voronoi区域内的训练矢量与该区域质心矢量(码字) 的最大距离di,求平方根后得ri,按其升序排列。编码时,从最小的ri开始,排除对任意 ,满足 .的码字;那些对所有j,满足 的码字,则采用部分失真排除判定法,确定此码字为最佳匹配码字或者在以该码字为开始的剩余码字中搜索最佳匹配码字。
3.2.2 等均值等方差最近邻搜索算法
均值等方差最近邻码字搜索算法是将均值不等式判据和用方差不等式判据相结合,进一步缩小了码字搜索范围。k维输入矢量x的方差定义公式(3.17)【9】为
(3.17)
其中:Mx为输入矢量x的均值。
等均值等方差最近邻搜索算法所用到的方差判别准则为:
设码字 为输入矢量x的当前最近邻码字, ,输入矢量x和码字Y,的方差分别为Vx和Vyi,如果公式(3.18)成立,
(3.18)
则有d(x,yi) >d( x,yp),码字yi,可以被排除是输入矢量x的最近邻码字。对式(3.12)作适当变形,可得公式(3.19)和(3.20)
(3.19)
(3.20)
即码字Yi的方差满足以上两式时,码字Yi可以被排除是输入矢量x的最近邻码字。
由几何知识可知,在欧几里得空间 中以空间中心线L为轴心的超圆柱面上,各点的方差相等,该超圆柱面称为等方差超圆柱面。由式(3.13)和(3.14)可知,等方差判别准则将码字搜索范围限制在方差分别为Vmax和V min的两个超圆柱面内。则等均值判别准则与等方差判别准则相结合的等均值等方差最近邻搜索算法将码字的搜索范围限制在了如图3.2所示的阴影部分内。
图3.1 等均值等方差最近邻搜索算法搜索范围二维示意图
图3.1 所示是EENNS算法搜索范围的二维示意图,图中以中心线L为轴心的超圆柱面分别是方差为Vmin和Vmax的等方差超圆柱面,与中心线L垂直的超平面分别是均值为Mmax和Mmin的等均值超圆柱面。等均值等方差最近邻搜索算法将码字的搜索范围限制在超圆柱面V1, V2和超平面Ll,L2所夹的范围内,即图中的阴影区域。EENNS算法减少了码字搜索范围,从而可以提高码字搜索速度。EENNS算法具体步骤如下: 第四章 矢量量化算法的实现 图4.1程序模块框图 图4.2程序运行初始界面 4.2.2 LBG矢量量化 如图4.2所示的流程图,对随机生成初始码书,码书大小N,训练矢量序列,停止计算门限和起始平均失真的初始码书进行劳埃德迭代。用初始码书为已知的心形,把训练序列重新划分为N个胞腔。计算新的平均失真和相对失真,判断新的失真是否满足门限条件,如果满足则退出劳埃德迭代否则继续进行劳埃德迭代直到满足门限条件,生成码书。LBG算法的关键代码如下: 图4.3 软件流程图 图4.4 压缩前的程序界面 图4.5 恢复后的程序界面 如上表所示,随着码书的加大,系统的信噪比在升高,当码书大小为512时,PSNR可以达到29.28。图像虽然有一定程度上的失真,但是并不是十分明显,基本上保持了图像原有的图像质量。 第五章 结论与展望
(A)预处理:计算并存储码书C中的均值和方差,按均值的大小对码书进行排序。
(B)在线处理:
Step l:计算输入矢量x的均值Mx和方差Vx,在已排序码书中找到均值与Mx 最 接近的码字 作为输入矢量X的初始匹配码字。计算当前最小失真 d min = d (x ,yp )。使集合
Step 2:如果集合G为空,转Step 7;
Step 3:往返搜索法搜索初始匹配码字yp两侧的码字yj;
Step 4:如果码字满足 或者 ,则执行
下列步骤的(a)或者(b)。否则,转步骤5;
(C)如果Myj> Mx,则从集合G中删除所有码字yi,i
Step 5:判断码字Yi的方差是否满足 或者 如果 满足, 则从删除集合G中删除码字Yi,否则,转Step6;
Step 6:用部分失真排除算法搜索码字Yi,如果d(x, Yi)
3.3 码字索引分配算法
3.3.1 BSA算法
BSA算法是在1990年提出基于二元对称信道模型的码字索引分配算法【16】。该算法对于任何索引映射函数 ,选择码字y,作为输入矢量x的最近码字后将产生索引 的传输,该过程与首先将码书中的码字进行位置交换等价,即对每一索i,码字y最终移动到码书中索引为 的位置。
基于这个事实,很自然地想到一种最简单的码字索引分配方法:首先在给定码书基础上随机产生一个初始码字排列,然后将所有码字的排列位置以特定方式进行交换,使信道失真不断减少。因此,这种算法的输入是一个码书,输出仍是一个码书,只不过码字存放在不同的位置。这带来一个附加优点:除了存储码书所需的空间以外,不需要任何额外信息来详细描述索引映射函数n,从而不需要信道编码和信道解码。
BSA算法的主要思想是通过不断交换码字的位置,使得信道噪声失真的目标函数场获得局部最优值.随着交换的进行 不断下降,而且索引映射函数 也跟着不断变化。在每次迭代中,码字的交换对是按一定的顺序选择的。所有的码字y,都对应一个函数 ,用来描述当该码字的索引(在当前码书中)在噪声信道中传输时可能产生的失真,其定义为公式(3.21):
(3.21)
BSA算法每次按 从大到小的顺序对码字进行排序。拥有最大函数值 的码字被选为首先交换的候选对象。首先进行试验性的交换, 与其他每一个码字分别进行交换,并计算每次交换后 的下降值。选择能使 出现最大下降的那一个码字与 进行真正地交换,然后进入下一次迭代。如果不存在这样的码字,则对yi作相同的交换试验。如果每一个码字按这种方法与其他码字进行交换后。不再下降,则终止算法,从而获得一个局部最优的码字索引分配方案。算法的具体步骤如下:
Step 1:初始化。随机打乱码字的排序;
Step 2:整理排序。根据 从大到小的顺序对码字yi进行排序。令n=-1;
Step 3:试验性交换。令n=n+1从j=n+1到N一1,分别计算索引n和索弓!j交换后所能引起的失真减少量,比较这些失真减少量,获得最大的失真下降量 ;
Step 4:如果 >0,则交换索引n和引起最大失真下降的索引j,并转Step 2;
Step 5:终止算法。如果n=N一1,则终止算法,否则,转Step 3。
可以看出,BSA算法根据函数值 将码字进行排列而选择出哪一个码字最先进行交换,从而在运算上给出了一个方向性引导。如果由于程序运行时间的限制而使算法的迭代次数有限,则这种方向性引导将显得尤为重要。每一次成功交换的完成,代表一次迭代的结束。若一次迭代中的所有试验性交换产生的失真下降都不大于O,则说明算法已经达到一个局部最优解.应该指出的是:从不同的初始码字排序出发,可获得不同的局部最优解,从而保证BSA算法对于码字交换的限制不会影响它获得全局最优码字索引分配方案的可能性。实验证明,该算法获得的码字索引分配方案的失真比随机码字索引分配方案的失真有较大改进。
3.3.2 禁止搜索码字索引算法
禁止搜索的基本思想是通过一系列移动来搜寻所有可行解的搜索空间,并且在当前迭代中禁止某些搜索方向以避免死循环和跳入局部极小。由当前解到其邻域解的移动被部分地或完全地记录在禁止表中,目的是为了禁止以后迭代中的重复操作。
令 为测试解的集合,其中元素si可以被表示为式【8】(3.22):
(3.22)
其中,N为码书的尺寸,Si(j)表示在解si中分配给码字Yj的索引, 令 和 分别表示当前解和最优解。中码字Yj的索引,Sb(j)仍表示分配给解Sb中码字Yi的索引。
令 , 和 分别代表测试解组的目标函数值集合,当前解的目标函数值和最优解的目标函数值,其中 是测试解 的目标函数值,0
Step 2:把当前解Sc拷贝给每一个测试解si, 0
Step 4: 如果vb>vc,令Sb=Sc,Vb=Vc,把从旧当前解到新当前解所交换过的索引插入禁止表中。禁止表的插入点设为ti=ti+1;如果ti>Ts,令ti=l,如果i
4.1 需求分析与整体设计
4.1.1需求分析
随着数字技术的飞速发展,越来越多的信息(文本、图形、图像、动画、音频及视频影像等)采用数字化的形式存储、传输和检索。由于网络上的数据流量飞速增长,而且网络的带宽总是满足不了需求,数据压缩编码技术的迅猛发展,要求在尽量不损伤多媒体质量的情况下压缩数据量。
正是由于这种需求的存在,要求开发一套完整的数据压缩软件,利用矢量量化的数据压缩算法,能够调用BMP格式的图像,对载入的图像进行压缩并显示解压后的图像效果,能够选择路径保存解压后的图像实现SNR信噪比的计算,便于对压缩软件性能的评价。
4.1.2 整体设计
软件的设计在Eclipse开发工具下编译Java应用程序。利用Java语言的面向对象的特点,充分利用他的可封装性,重用性和多态性等特点,开发一整套完整的基于矢量量化数据压缩算法的压缩软件。
将这个数据压缩软件从整体上分五个模块来实现的。Bmp格式图像的调入和保存模块,图像矢量块的划分模块,初始码书生成模块,LBG量化模块,图像解压模块。如图4.1所示:
软件界面的设计。在JAVA的运行环境下要实现基于矢量量化数据压缩算法对BMP格式的静止图像进行压缩与解压。软件界面的设计,在图像界面的左侧可以显示调入的图像,右侧显示图像信息。在浏览按钮上可以调入待压缩的图像,并且可以选择解压后的图像的保存位置。选择好解压图像后点击压缩按钮即可开始对图像进行矢量量化的压缩。最后显示压缩的结果,包括原始图像的大小,压缩后的大小,压缩比,压缩时间及PSNR值等信息。软件运行的初始界面如图4.2所示:
4.2 矢量量化算法的实现过程及说明
4.2.1 初始码书的生成
这个程序利用了随机编码生成码书的方法,即根据输入信源分布直接从训练序列中随机选择N个训练矢量作为初始码字以构成初始码书。该方法的优点是计算量低,初始码书的生成较为容易。虽然可能出现码书的分布不均匀的现象,但是配合LBG算法的多次迭代可以得到补偿。需要注意,这里所说的随机编码是说初始码书的选择方式是随机的,而一旦码书选定,编码器的工作方式则是按着最近邻方式进行的。随机码书的生成代码如下:
codebook=new MyBlock[N];
for(int i=0;i
} codebook[0]=tv.randomselect();
for(int j=1;j
do{ t++;
n=0;
codebook[j]=tv.randomselect();
for(int l=0;l
{ n=1; break; }
}
}while(n!=0&&t<100);}
图4.2 LBG码书设计流程图
flag=0;//循环标识
tcb(s,tv);//训练集和码本建立关系
for(int i=0;i
yn[i]=n;
} }dsum=0;
for(int i=0;i
}d1=(double)(dsum/tv.M);
d=Math.abs(((double)(d0-d1)/(double)d1));
if(d1
{for(int i=0;i
{o=core(tv,i,s);
codebook[i].vcopy(o);
}d0=d1;
flag=1;
}while(flag==1);
在这段代码中,首先建立码本与训练矢量的关系,并经过多次的劳埃德迭代直到满足门限条件,生成新的码书。这里应用了LBG算法他具有如下的优点:
1.不用初始化计算,可大大减少计算时间
2.初始码字选自训练序列,无空胞腔问题
虽然LBG算法有如上的优点,但是他本身也存在一些缺点和不足的地方,比如在计算的过程中可能会选到一些非典型矢量作码字,因而该胞腔中只有很少矢量,甚至只有一个初始码字,而且每次迭代又都保留了这些非典型矢量的形心;还可能会造成在某些空间把胞腔分得过细,而有些空间分得太大。这些缺点都会导致码书中有限个码字得不到充分利用,还需要进一步的改进算法。
程序整体流程图如图4.3所示:
4.2.3 矢量量化码字索引与恢复
在这个程序中没有考虑快速码字搜索的算法,应用了最佳码字搜索的方法,使输入矢量与所有的码字进行比较,选出距离最小的那个码字成为匹配码字,生成索引。这种算法虽然增加了计算量,但是减少了图像数据压缩过程中的失真。
在输出端,将编码过后生成的索引对照码书,将图像数据进行还原。
4.3 实验结果及评价
在初始界面点击浏览按钮调入.BMP图像。图像就会显示在程序运行初始界面的左侧,如图4.3所示:
点击”压缩”按钮,程序就会自动进行矢量量化的压缩,下面的进度条会显示压缩的百分比,当进度达到100%时,程序就会将解压好的图像显示在程序界面的左侧。并显示一系列的压缩信息,包括压缩源文件的大小,压缩后的码本大小,压缩比,压缩过程所需要的时间以及峰信噪比PSNR等信息。压缩后的界面如图4.5所示:
程序显示的压缩结果的压缩比和压缩时间上可以看出,这个利用矢量量化编码算法的压缩软件可以达到16:1的高压缩比,并且压缩时间比较短。所以矢量量化压缩编码是一种非常有效的压缩算法。
从压缩图像的效果来看,实验测试的图像均采用的512×512,8比特/象素的women图像作为训练图像产生各种大小的码书,矢量维数均为16,对压缩程序进行测试。通过变换码书的大小,运行程序得到不同的信噪比。测试结果如下表4.1所示:
表4.1 不同码书的信噪比
序号 码书大小 PSNR
1 64 27.36
2 128 27.74
3 256 28.54
4 512 29.28
这个程序采用的是矢量量化码书生成算法中的LBG算法,通过运行程序以及对运行结果的分析可以看出这种从标量量化劳埃德迭代操作推广出来的迭代算法具有以下两个优点:
1.不用初始化计算,可大大减少计算时间
2.初始码字选自训练序列,无空胞腔问题
虽然LBG算法在具有如上的优点,但是因为LBG算法是一种下降算法,每次迭代总能减少(至少保持不变)平均失真,而且每次迭代通常只能产生码书的局部变化,即每次迭代后,与旧码书相比,新码书不可能有非常大的变化。所以初始码书的选择影响码书训练的收敛速度和最终码书的性能,一旦选定初始码书,该算法只能得到局部最优的码书,即LBG算法一般不能得到全局最优的码书。
在每次迭代的最佳划分阶段,从码书中搜索训练矢量的最近码字需要大量的存储空间和繁琐的计算;这对软件大的运行要求比较高的运行环境。这个可以通过快速码字搜索的算法来解决这个问题。
本文主要针对矢量量化的算法和实现研究与探讨,本章主要对本文内容与研究工作进行一下总结。最后对矢量量化技术在今后发展方向上作了一些展望。
矢量量化技术作为数据压缩领域里的一个分支,主要优点是压缩比大以及解码简单,在图像压缩方面已经得到成功地应用。目前, 矢量量化技术的研究主要集中在三个方面:矢量量化器的码本设计,矢量量化码字快速搜索算法设计,矢量量化码字索引分配问题。本文主要研究了矢量量化码本设计算法和码字快速搜索算法,并讨论了矢量量化技术的应用问题。全文主要工作可以总结如下:
首先,介绍了数据压缩算法的基本理论和发展现状,讨论了数据压缩算法的分类体系和发展历程。
其次,介绍了矢量量化技术的来源和发展历程,重点介绍了关于矢量量化技术的技术基础和矢量量化算法中的关键技术。
再次,研究了经典的矢量量化的设计算法,分别研究讨论了矢量量化中的LBG算法,最大下降算法;快速搜索算法中的基于不等式的快速搜索算法和码字索引分配中的BSA算法等,并讨论了现有各种矢量量化算法。
最后,介绍了一种LBG矢量量化算法的实现方法,并对实验结果进行了性能评价。
以上是本文内容的总结。还有许多问题没有涉足或研究的深度不够。矢量量化技术领域虽然已经取得了长足的进步,但总体上来说还有许多问题需要进一步研究。下面对矢量量化未来发展的展望:
(1) 矢量量化是一种信源编码技术,在矢量量化器设计的过程中,考虑如何降低信道传输中可能造成的噪声干扰的影响,可以提高矢量量化系统的整体性能。归结起来,可以用矢量量化码书索引分配问题来描绘,即研究如何合理的安排码书中码字的排序,使得编码系统在信道传输中的容错能力增强。
(2) 矢量量化作为一种数据压缩技术,如何更好地应用到实际的数据压缩和传输系统中去,在实际应用中体现编码算法的优越性,是一个很实际的问题,在设计算法的同时,要考虑应用的实际情况。
(3) 本文中在图像的编码方面对矢量量化进行研究,矢量量化技术并不仅仅用在图像编码中,可以根据实际需要,可以深入对其进行深入研究,如可以在语音压缩编解码、音视频压缩和远程会议等方面,还可以将这些成果应用到其方面一数字水印、语音识别、语音合成以及文字合成以及文字的识别等。













 工商网监
工商网监
评论