 电子发烧友App
电子发烧友App


随着 SoC 芯片性能的提高,各模块间的数据交换成为提高微处理器系统运行速度的瓶颈。DMA 控制器能够有效替代微处理器的加载/存储指令,显著提高系统的并行能力。传统的 DMA 的结构专用性强而可扩展性不足[1~3]。在高速并行系统中,单时钟域的设计已不能有效控制功耗的增长。面对 SoC 不断扩大的规模,还必须设计一种动态配置 DMA 通道的结构以提高逻辑资源的利用率。本文介绍了在 0.18um 工艺下,面向完整的 AMBA 总线结构的高性能 32 位 DMA 控制器的 ASIC 实现,提出了使用双时钟域配合具有同步复位的门控时钟(Gated Clock)实现功耗控制的方法。握手信号路由阵列的设计使得有限数量的通道可以匹配更多的总线外设。
VLSI是超大规模集成电路(Very Large Scale Integration)的简称,指几毫米见方的硅片上集成上万至百万晶体管、线宽在1微米以下的集成电路。由于晶体管与连线一次完成,故制作几个至上百万晶体管的工时和费用是等同的。大量生产时,硬件费用几乎可不计,而取决于设计费用。
超大规模集成电路是70年代后期研制成功的,主要用于制造存储器和微处理机。64k位随机存取存储器是第一代超大规模集成电路,大约包含15万个元件,线宽为3微米。目前超大规模集成电路的集成度已达到600万个晶体管,线宽达到0.3微米。用超大规模集成电路制造的电子设备,体积小、重量轻、功耗低、可靠性高。利用超大规模集成电路技术可以将一个电子分系统乃至整个电子系统“集成”在一块芯片上,完成信息采集、处理、存储等多种功能。例如,可以将整个386微处理机电路集成在一块芯片上,集成度达250万个晶体管。超大规模集成电路研制成功,是微电子技术的一次飞跃,大大推动了电子技术的进步,从而带动了军事技术和民用技术的发展。超大规模集成电路已成为衡量一个国家科学技术和工业发展水平的重要标志。也是世界主要工业国家,特别是美国和日本竞争最激烈的一个领域。超大规模集成电路将继续得到发展。
DMA 结构的比较
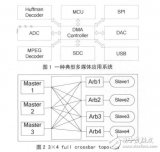
AMBA是 ARM 公司提出的用于微处理器片上通信的先进的总线结构。一种典型的 AMBA 总线由 AHB 和 APB 总线分段构成。总线上的设备可以分为能够主动读写的主设备(Master)与只能接收来自 Master 请求的从设备(Slave)。
近来针对 DMA 控制器的研究引出了新的 SoC 架构,如使用分布式 Flyby DMA 结构[1];为数据吞吐量大的模块预设专用通道[2,3]等。这些结构的共同点在于数据在搬移过程中不需要经过缓存就可以达到指定地址。然而缺乏缓存结构的 DMA 有一定的局限性。从应用的角度来讲,在音视频编解码程序中普遍存在同端口内存数据块搬移的操作,而非缓存结构的 DMA 无法在同端口上实现单周期的先读后写操作。此外,在 APB 总线上只能存在一个 Master 设备,所以既无法为每个外设配置独立 Master 以获取数据,也不可能在低速总线上完成单周期传输。从功耗的角度看,当系统中存在较多 Master 模块时,总线仲裁器的负担就被加重,而仲裁器正是AMBA 总线功耗的主要来源。使用缓存结构的系统级 DMA 尽管存在数据传输的延时,但能适用于 AMBA 不同速度的分段总线,可扩展性远高于非缓存结构 DMA。
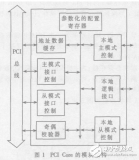
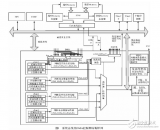
如图 1 所示,本文提出的 DMA 控制器在整个系统中可分为 3 个部分。DMA Master 端解析来自当前通道的命令包并发出 AHB 总线请求,完成缓存区与 AHB 总线的数据交换。 DMA 的引擎(DMA Engine)包含各个通道的逻辑资源与双口缓存结构(Dual Port FIFO)及相应的控制逻辑。DMA 控制器的 APB Master 发出 APB 的总线请求,这些信号与来自 AHB 的转换信号一起在两段总线的桥接(Bridge)部分进行仲裁选择,实现 APB 总线与 DMA 缓存区的数据交换。
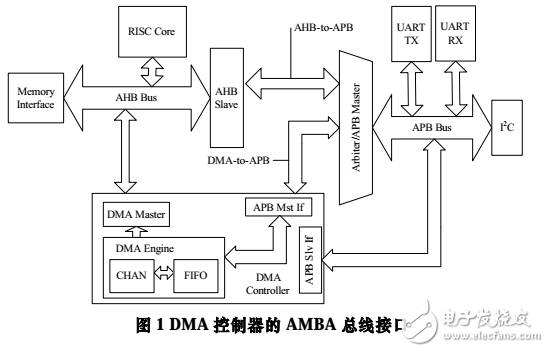
DMA 控制器的 VLSI 实现
DMA 的时钟域
在不具备 DMA 的 AMBA 总线中,APB 唯一的 Master
在 AHB 总线的驱动下进行数据传输。两段总线以串行的方式工作。从表 1 中可知,由于在 AMBA 结构中微处理器不提供对 APB 的 Burst 操作,完成对 APB 的 4 个 Word 的传输,至少需要 20 个 AHB 的时钟周期。而当存在 DMA 控制器时, APB 总线能缓存需要和 AHB 交换的数据,并且可以独立地驱动数据传输。不仅使传输周期减少了 50%,而且实现了 APB与AHB 的并行运行。
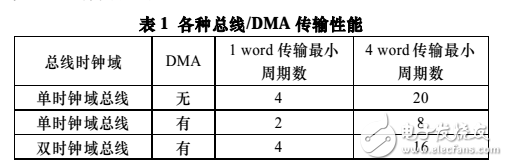
由于并行的实现,APB 总线上某些时间段中数据传输更加频繁。DMA 的 APB 信号进入总线以前必须经过仲裁,当使用类似于高速总线上的 Burst 模式时,APB 可以多个连续两周期的传输来运行,这增加了互连线的翻转频率。尤其在 DMA 多个通道相互交替占有 APB 时,这种翻转间隔便被缩小。因此,依据功耗 P = CV 2 f ,AHB 总线的二分频时钟被用来驱动 APB 总线。在这种配置下,相对于使用指令集进行的传输依然持有速度上的优势。
DMA 的内部结构
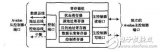
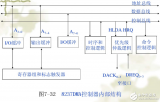
DMA 控制器的核心部分围绕通道状态机和双口缓存数据的 FIFO 结构来设计。如图 2 所示,功能模块包括非整字地址对齐逻辑(Read/Write Aligner)、64×32bit 双口 FIFO、FIFO 控制逻辑、DMA 引擎、DMA 握手信号路由器(HandshakeRouter)和功耗管理电路。其中 DMA 引擎又包括 DMA 通道状态机逻辑和通道仲裁器(Chan Arb)。
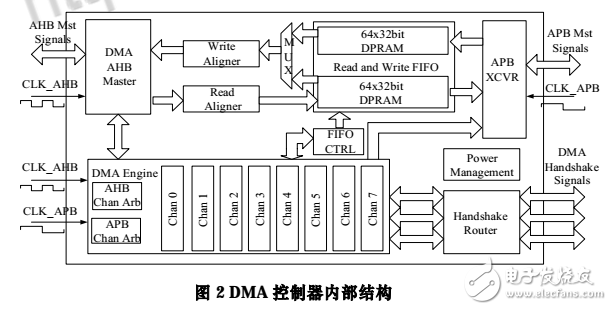
双时钟域设计的难点在于时钟域的划分以及不同时钟的相位要求。从图 2 中可以看到,DMA 的数据通路部分由 2 个总线接口及 2 块 64×32bit 的双口 SRAM 组成,其中 DMA Master 接口与数据对齐逻辑由 CLK_AHB 来驱动,而 APB 端由 CLK_APB 来驱动。DMA 的通道根据数据流方向共分为两种:一种控制 AHB 上模块的数据交换;另一种控制 AHB 与 APB 上模块的数据交换。
为了减小面积,利用 APB 时钟是 AHB 时钟二分频的特点,将两种不同类型的通道复用同一个存储端口。这样,两种通道的状态机逻辑中使用各自的时钟产生 SRAM 读写地址与控制信号。为了支持多通道独立读写操作以提高并行度,每个 AHB 与 APB 交换数据的通道必须使用读写独立的SRAM。这样,使用 2 块双口 SRAM 实现了不同时钟域缓存共享。每个通道拥有 2 块 8×32bit 的不同流向的缓存容量,以匹配 DMA 的 AHB Master 端最高支持 4 个 Word 的 Burst操作。
DMA 通道的状态机与仲裁
DMA 的通道是指能够控制数据从起点传输到终点的逻辑资源以及相应的缓存空间。图 3 展示了两种类型通道在传输数据过程中的状态机变化。其中虚线对应 AHB 到 AHB 的通道,实线对应 AHB 与 APB 间数据交换的通道。

AHB 与 APB 的数据交换以接收来自 AHB 的命令符作为传输的开始。AHB 和 APB 能够根据当前的缓存充溢情况独立地发出总线请求。于是相应的逻辑各自进入 AHB_RD(WR)_REQ 和 APB_REQ 状态,并根据目的地址与当前剩余的传输字节数来调整单次传输的字节。DMA 的 AHBMaster 和 APB Master 在状态机的控制下,独立地对 Read FIFO 或 Write FIFO 的一个端口进行操作。
类似地, AHB 数据通道在接收命令符以后,进入AHB_RD_REQ 状态,在 FIFO 不足半满的情况下,APB Mst从起始地址读出数据放入缓存;在 FIFO 超过半满的Signals情况下,AHB_WR_REQ 状态从缓存中取出数据送至的地址。
由于在同一时刻只能有一个通道占有 AHB 或APB 总线,DMA 多通道的总线请求必须经过仲裁器的仲裁。根据文献[6]的分析,Round Robin 策略在相应多设备的请求中能最有效地利用已知带宽。为了让AHB 的传输减少延时,在不同类型通道间使用固定优先级。在同类型通道间,使用 Round Robin 策略使各设备有相同几率被服务。
DMA 握手信号路由阵列
当 AMBA 总线上的外设数量增加时,数据源设备与目标设备之间的对应关系也随着数量线性增加。必须设计一种可以动态配置每个通道占有设备的方法,以减少通道的数量。
本文提出了一种基于握手信号路由阵列动态配置通道的方法。 DMA 的握手信号控制着通道起始和终止状态。 DMA_REQ 信号是目标设备对 DMA 控制器的输入,标识可以开始传输数据。当传输完成后,目标设备发出 DMA_ CMD_END 信号以通知 DMA 结束传输过程。由于目标设备处理总线数据的速度可能低于总线的传输速度,因此通常在总线接收端使用小规模的缓存。而握手信号即用来控制缓存数据不会在进入处理流程之前被来自总线的新数据覆盖。
图 4 展示了连接 8 个总线外设的 DMA 控制器的握手信号路由阵列的单元。2 个二级选择器阵列分别用作 2 个握手信号的路由。H1~H8 是来自目标设备的握手信号。每个通道使用 2 个 4 选 1 和 1 个 2 选 1 的选择器级联成一个单元来从 8 个握手信号中选出当前占有通道设备的信号。在命令字获取阶段得到的目标设备地址映射为一个 8bit 的信号(如00000001,00000010),输入 8/3 编码器来产生阵列的选择信号。当系统具有 16 个总线外设时,阵列单元为 4 个 MUX4、 2 个 MUX2 和最后一个 MUX2 的三级级联,以此类推。

2.4 功耗管理和同步复位的实现
在 0.18µm 的工艺下,由于时钟树的反转引起的电容充放电对功耗的贡献达到了整体功耗的 30%~40%。一种有效的遏制此类功耗的方法是采用门控时钟。使用低电平有效的锁存器和与门串连的方法得到门控时钟,可以避免时钟毛刺的产生。
由于时钟无效以后 DMA 模块进入状态锁存,在下一次时钟有效时,系统将以上一次时钟关闭时锁存的状态进入运行。为了避免一个不确定的状态在关闭时钟时被锁存,同步复位的电路将在时钟关闭之前先复位所有触发器电路。如图 5 所示,一个两级移位寄存器电路的输出用来产生门控时钟的使能信号 CLK_DISABLE。当 Soft_Rst 信号为低时,门控时钟的使能信号为 0,DFF3 输入为 0,时钟正常输入。当需要关闭时钟时,Soft_Rst 先通过 APB 总线被写高,在第 1 个 APB 时钟周期后,模块同步复位成功且 Soft_Rst 已经移位至 DFF1 的输出,随后组合逻辑把使能信号拉高,DFF3 的输入信号为 1。在第 2 个 APB 时钟上升沿,DFF3 输出为高,在随后到来的相应时钟域的低电平时段,LAT 通路,于是时钟被关闭。

仿真结果与性能
经过 Design Compiler 逻辑综合,DMA 控制器在 SMIC 0.18um 的工艺下,能够达到 AHB 时钟域 180MHz,APB 时钟域 90MHz 的工作频率。
ALP3310 是基于 AMBA 总线开发并采用了该 DMA 控制器的 32 位 RISC 处理器,含有 UART、I2C 等 16 个总线外设。DMA 控制器具有 2 个 AHB 数据通道,6 个 AHB 与 APB的数据通道。
不同的内部结构和系统仲裁的实现都会影响 DMA 的总线占有率。仿真表明,忽略 AHB 总线竞争以及 DMA 内部通道竞争的影响,DMA 的 AHB 端口平均每 10 个 AHB 周期可以完成 4 个 Word 的传输,达到约 280MB/s 的传输速度。
在 AHB 和 APB 上对比 DMA 与软件传输数据的速度。在 AHB 上,分别用微处理器和 DMA 将 SRAM 中的 128 个字节的数据搬移到 SRAM 的另一段地址中。如表 2 所示,DMA 的 AHB 传输对比软件传输具有 80.0%的速度优势。

对于 APB 的传输,通过微处理器直接写 APB 外设花费了 7 100 个 AHB 周期。而写入 SRAM 仅花费了 5 400 个 AHB周期,并且微处理器随即被释放,剩余的工作由 DMA 完成,从而减少了 26.7%的传输时间。
本文提出了面向 AMBA 总线的 32 位高性能 DMA 控制器的设计方法,引入了双时钟域、同步复位门控时钟和握手信号路由阵列的设计,并根据仿真结果进行了性能分析。实验结果表明,采用了该 DMA 控制器的 32 位 RISC 处理器 ALP3310 的总线传输速度得到大幅提高。












 工商网监
工商网监
评论