 电子发烧友App
电子发烧友App


串口通信具有传输距离远、传输稳定、简单实用等特点,已被广泛应用于工业控制、数据采集、网络通信等领域。在这些应用领域中,串口通信用于实时地从各个串口接收数据,而向各个串口发送的主要是控制信息,一般不要求严格的实时性。因此提高串口设备接收的实时性至关重要。
设备接收到数据时,系统可通过两种途径获取数据包到达的信息。一种是中断方式,利用硬件中断机制实现设备和系统的应答对话,即当外部设备需要CPU处理数据时,设备就发一个中断信号给系统,系统在收到中断请求时要保存中断现场,调用相应的中断服务程序响应设备的中断请求,退出中断处理程序后要恢复现场。上下文的切换要占据系统开销,在数据量过载时会使得中断频率过高,CPU忙于处理硬件中断,上层应用程序对于数据包的处理无法执行,而中断程序还不断往队列中放数据,系统将自陷在中断响应这一环节,产生所谓的“活锁”。另一种是轮询方式,系统每隔一定时间便检查一次物理设备,若设备“报告”有数据到达,则调用相应的处理程序。但固定的轮询周期增加了数据等待处理时间,降低了系统实时性。而且当数据量比较小时,频繁查询没有数据达到的设备也是对CPU资源的浪费。
可见中断和轮询方式都不能满足不同负载情况下系统的实时性要求。本文借鉴Linux系统中NAPI[1]方法,结合中断与轮询的优点,提出一种轮询与中断结合的调度方式。这种调度机制在多串口系统中,当负载在不同的串口通道不均衡时,可以提高CPU的利用效率,并能满足业务的时延要求。另外,根据到达数据量分析得出了轮询、中断切换门限和轮询周期。
1 算法描述
在同一系统中处理相同业务量时,中断和轮询处理的时间相同。因为过程相同,都是把数据从外设缓冲搬移到CPU内存中,所不同的是中断进行上下文切换要占据系统开销,而轮询只是查询一下寄存器状态。相比之下,轮询占用CPU的时间很短,一般中断为几个μs,轮询为几百ns,根据不同系统而有差别。相反,在数据量比较小的情况下轮询中存在空转情况,无疑增加了系统开销。
目前,处理中断和轮询互换的方法有定时中断法(Clocked Interrupts),即设置一个定时器,定时器到时,如果有中断,则响应中断,调用中断服务程序处理数据。这种方法在数据量大时类似于轮询,在负载小时中断由异步事件触发降低了开销。但是这种机制需要一个精确的、频率很高的系统时钟,并且这种方法受固定定时周期的限制,不是在任何情况下都有效。
在并行系统中还应用了一种叫轮询定时(Polling Watchdog)的机制,这种方法主要是为了解决接收处理中的等待时延问题。基本思想就是在轮询接收开始时设置一个看门狗定时器,以满足业务的最小时延要求,而且中断要在接收超时才产生。此方法的不足之处是在负载小时解决不了轮询空转问题。
混合中断、轮询方式(HIP)主要应用在网络接口系统中。工作方式为基于观测接收的负载,改变切换门限,自动在中断和轮询两种方式中切换。中断方式没有考虑到超时中断,当数据到达间隔很大时,会降低实时性。在比较中断和轮询开销时,定义VI+V(B)为中断开销,其中VI为中断的固有开销,V(B)为系统接收B字节数据的开销,VP+V(B)为轮询开销,VP为轮询的固有开销。但在一次轮询和中断接收中,中断和轮询所接收的数据可能不相等,中断开销和轮询开销便失去了比较意义。
以上几种方法均有不足,但在多路串口系统中,还各有不同的特点,即在每个独立的通道可能存在不同的负载情况。如果对全部的串口通道统一应用中断方式或查询方式,则显然不能适应各自串口通道的数据量,不能满足系统实时性和高效率的综合要求。根据这一特点,提出了在多路串口系统中,轮询和中断相结合的接收策略,在中断方式下还灵活应用了批中断技术。
算法描述:
com0=polling.。.comN=polling
For comID←0 up to comMAX
If TI》γ or PU=PUMAX Then
comID=interrupt
DelList(comID)
N路串口的初始状态为轮询,检查轮询队列,如果数据到达间隔时间TI大于门限γ或者轮询空转次数PU等于空转门限PUMAX,则该端口改为中断状态,在轮询队列中删除该端口。根据不同的系统,间隔时间门限γ和空转门限PUMAX的取值不同。
If TI《γ Then
comID=polling
AddList(comID)
在中断状态下,如果数据到达间隔时间TI小于门限γ,则该端口改为轮询状态,在轮询队列中增加该端口。
2 门限设计
如果事件随机发生而且发生频率很低,以致大多数轮询都认为事件没有发生,则中断就会是首选的事件通知机制;如果事件定期发生且可以预测,而大多数轮询都发现事件已发生,则首选机制是轮询。在这两者之间存在这样一种情况,即轮询行为和反应型行为的效果都相同,在它们之间如何选择都无关紧要。这种情况即为所寻找的轮询和中断的切换门限。
2.1 门限度量标准的选择
数据多少的衡量都是以单位时间内的吞吐量计算,即数据速率。如果以吞吐率的多少作为切换门限的标准,则在分组定长情况下,这种计算方法可以近似体现出负载情况,但当分组不定长时就不能体现实际负载了,如图1所示的四种情况。
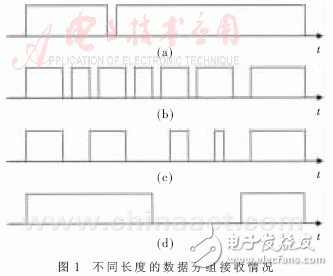
图1(a)和图1(b)的分组长度不同,但之间的到达间隔都很小。计算得出图1(b)单位时间的吞吐率明显要比图1(a)小,但如果图1(b)采用中断方式,就要频繁地响应中断,效率将大大降低。图1(d)的分组很长,一次接收中接收到的数据非常多,但之间的到达间隔很长,如果计算吞吐率选择的单位时间正好为数据接收时间,在这一段时间内吞吐率很大,则误认为数据量很大,选择轮询方式接收。相比之下,图1(c)和图1(d)选用中断方式更为理想。
根据以上分析可以发现,用数据到达的时间间隔可以近似地表示数据量的大小。如果数据到达间隔很小,且频繁到达,则认为负载很大,选择轮询方式;如果数据到达间隔很大,则认为负载很小,选择中断方式。在轮询方式中,如果根据已知的到达时间,推算出下一数据的到达时间,根据计算出的结果来设定轮询周期,则轮询效率更加提升。
2.2 门限的计算
上述计算到达间隔判断切换时机的方式,不能体现数据到达间隔的变化规律。可选用平均到达时间的均方根和均值的比值作为判断切换的标准,这个比值系数代表了平均到达时间的变化程度。当比值小时表明预测的值与平均值偏差很小,数据到达的间隔时间是有规律的,可以预测。这种情况显然要应用轮询方式,把轮询周期设为平均到达间隔时间。
平均到达间隔时间的计算方法如下式:
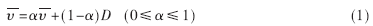
式中:D为最后一个数据到达的间隔时间;α为平均到达间隔时间的加权系数,α控制着D相对于以往的到达时间间隔历史所占的比重。用这种方法,平均到达间隔时间就可以积累到达间隔时间了。
平均到达时间的方差用下式估计:
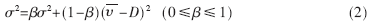
式中:β为到达间隔时间的方差加权系数,且控制估计器的记忆性。σ2开方就得到平均到达间隔时间的均方根σ了。
下式表明了切换到轮询时的门限:

式中:γ为预测门限,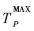 为系统可容忍的最大轮询周期,在本系统中为满足上层的应用,为20 ms。
为系统可容忍的最大轮询周期,在本系统中为满足上层的应用,为20 ms。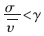 表明数据到达间隔规律;
表明数据到达间隔规律;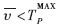 表明平均到达间隔小于系统所能忍受的最小间隔。数据到达不频繁,认为满足以上两个条件时切换到轮询模式;当满足的条件相反时,切换到中断方式。
表明平均到达间隔小于系统所能忍受的最小间隔。数据到达不频繁,认为满足以上两个条件时切换到轮询模式;当满足的条件相反时,切换到中断方式。
3 实例分析
在可接收10路空中信号的多串口系统中对该算法进行实现,系统结构如图2。该系统可将数据信息(主要为语音数据)接收后转换为以太网数据包,通过10MHz以太网口送出。同时,它从以太网口接收来自控制台的各类指令,完成相应的处理任务。
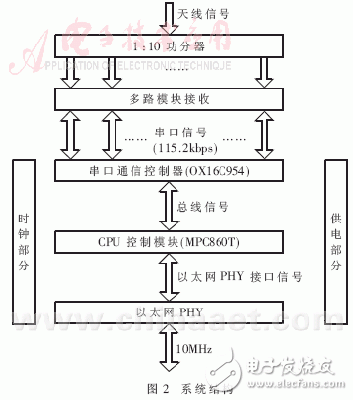
信号经过1:10功分器,分给10个RF接收模块,完成RF接收,输出串行信号,每路串口为串行信号的最大速率115.2kbps,RF接收模块每20ms发一个数据包,一个数据包最大为30bit。之后串行信号经过3片OX16C954(每片有4路UART)转换成并行总线信号,输出给MPC860T(CPU)。每片OX16C954设置有128B的环形缓冲区,所以经过时间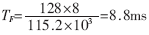 缓冲区就会被写满。为了保证不丢失数据,应该在8.8ms内完成对10个终端接收模块进行一次接收。OX16C954中断门限设为64B,当接收缓冲超过64B时,OX16C954产生接收中断。在OX16C954还设置有超时中断,当从接收最后一个停止位中心开始计时,在四个符号周期内没有接收新的信息,即
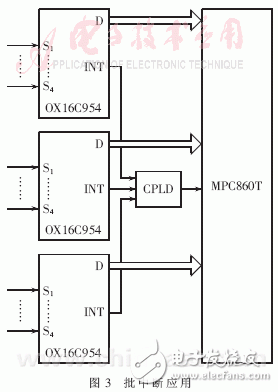
缓冲区就会被写满。为了保证不丢失数据,应该在8.8ms内完成对10个终端接收模块进行一次接收。OX16C954中断门限设为64B,当接收缓冲超过64B时,OX16C954产生接收中断。在OX16C954还设置有超时中断,当从接收最后一个停止位中心开始计时,在四个符号周期内没有接收新的信息,即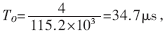 就产生超时中断。批中断的应用如图3。多个串口通过CPLD共享一个中断源,在中断频繁,多个串口同时产生中断的情况下,实现了批中断,节约了中断资源,提高了中断效率。
就产生超时中断。批中断的应用如图3。多个串口通过CPLD共享一个中断源,在中断频繁,多个串口同时产生中断的情况下,实现了批中断,节约了中断资源,提高了中断效率。
本系统的设计基于VxWorks操作系统。VxWorks操作系统提供对多种处理器的广泛支持,具有完善的开发环境、开放的软件接口、优异的实时性能和全面可靠的网络功能及良好的可裁剪性,适用于各种嵌入式环境的开发。
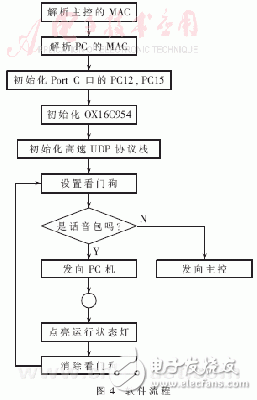
程序实现过程:系统加电待操作系统启动之后,应用程序首先根据主控和PC机的IP地址,得到它们的MAC地址,为以后进行UDP数据传送做准备;初始化MPC860T的Port C口,把PC12、PC15初始化为数据输出口,分别用于点亮运行时的状态灯和设置/清除硬件看门狗;初始化OX16C954,打开10路串口,接收终端模块的数据;同时向终端模块发送数据,初始化UDP协议栈;最后,进入无限循环中,从各个串口收集数据,解开数据包,以UDP的方式,把话音包发给PC机,把非话音包发给主控;同时,从网络上接收来自主控的UDP数据,根据端口号,把数据转发给各个终端模块。PC机不直接向DPM发送UDP数据,只有主控向各个终端发送数据,故由DPM至PC机的数据为单向。管理看门狗,每循环一次,开关一次看门狗,处理一次状态灯。整个程序的流程如图4所示。
在10路都没有数据的极限情况下测量轮询开销VP。在这种极限情况下,应用全中断的方式,10路串口没有数据不会产生中断,中断开销为0;应用全轮询的方式,CPU每次只查询外部寄存器但不接收数据,所以每次CPU都是空转,测量出来的为轮询的固定开销VP=163.84μs。在这种情况下,中断显然要优于轮询。
3.1 均衡负载
在多路负载均衡的情况下,测量中断吞吐率OI= B1为达到OX16C954中断门限后,触发的接收中断所接收的数据量(B1≥64B);B2为产生超时中断时所接收的数据量(B2≤64B)。轮询吞吐率OP=
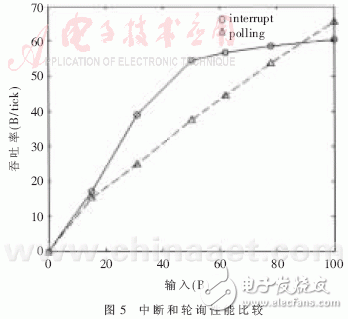
B1为达到OX16C954中断门限后,触发的接收中断所接收的数据量(B1≥64B);B2为产生超时中断时所接收的数据量(B2≤64B)。轮询吞吐率OP=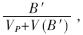 B′为轮询接收的数据量。如图5所示,在VxWorks系统中1tick=1/8000(s)。因为设置了中断门限,所以中断在数据量低的时刻有一个跃变;轮询的跃变由轮询的周期设置,如果改变轮询周期,跃变点将发生转移。轮询的吞吐率随输入数据量的增加而呈线性增长;在数据量低时中断要优于轮询,随着数据量的增长轮询就要优于中断,在两者相交的时刻,通过实验可以找到γ和PUMAX的值。
B′为轮询接收的数据量。如图5所示,在VxWorks系统中1tick=1/8000(s)。因为设置了中断门限,所以中断在数据量低的时刻有一个跃变;轮询的跃变由轮询的周期设置,如果改变轮询周期,跃变点将发生转移。轮询的吞吐率随输入数据量的增加而呈线性增长;在数据量低时中断要优于轮询,随着数据量的增长轮询就要优于中断,在两者相交的时刻,通过实验可以找到γ和PUMAX的值。
3.2 非均衡负载情况
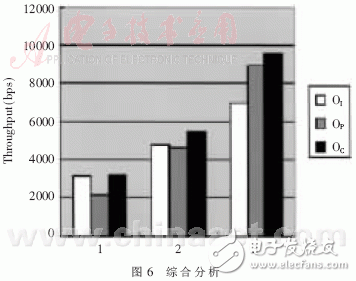
非均衡负载情况,即m1路数据负载大、m2路数据负载小的情况(m1+m2=10)下,测量OI、OP和OC(中断和轮询相结合的吞吐率)。如图6所示,在横坐标为1处,为m1=3,m2=7的情况,由于应用了批中断,中断的效率要优于轮询,中断和轮询相结合的方法要略优于中断;在横坐标为2处,为m1=5,m2=5的情况,相结合的方法要略优于中断和轮询;在横坐标3处为m1=7,m2=3的情况,相结合的方法近似轮询,要优于中断。
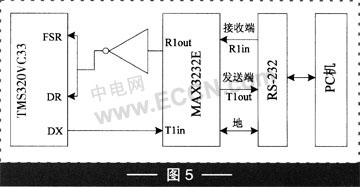
本文在综合分析各种串口接收方式不足的基础上,提出了中断和轮询相结合的方法。实验结果表明,在满足系统实时性要求的前提下,改进后的高速多串口系统吞吐率比应用单一的中断或轮询方式在多路高速串口系统中、各串口负载不均衡的情况下,得到了明显的提高。









 工商网监
工商网监
评论