 电子发烧友App
电子发烧友App


-----注:以下文章纯手打原创,评测数据从第三方应用角度测评,如您是以下IC原厂,有专业性的偏颇建议请及时联系小编。
说起评测,大家往往想起手机,电脑,汽车等等,相信大家经常在数码IT网站看到各种各样的数码产品白电家电等功能性能评测,也经常被各种产品发布会,新媒体的手机跑分大赛,电脑跑分数值刷屏。------ 今天 我们来个中国通用32位MCU芯片 跑分大战
说起MCU,在物联网,智能硬件兴起的当下,万物智能,万物互联,小到插座,开关,灯泡都是智能的时代。MCU便是其中不可缺少的大脑核心。
小编对当下几款国内外热门的32位MCU进行横向PK评测。挑选了目前市场常见的几家软硬件兼容32位ARM MCU如下:
STM32F103VET6
GD32F103VET6
HK32F103VET6
AT32F413RCT7
CKS32F103RC
众所周知,衡量MCU处理器的一个重要指标就是性能,另外一个重要指标便是功耗。本期我们先从性能开始,跑分大赛。本次跑分我们把以上所有MCU都运行在同一主频,去评测同一主频下的各个MCU性能跑分数据。
在MCU处理器领域评分的 Benchmarks 非常众多,有某些个人开发的程序,也有某些标准组织,或者商业公司开发的Benchmarks, 在此就不以一一列举。今天我们选用在嵌入式处理器领域最为知名和常见的 Benchmarks 就是CoreMark。
CoreMark是用来衡量嵌入式系统中中心处理单元(CPU,或叫做微控制器MCU)性能的标准。该标准于2009年由EEMBC组织的Shay Gla-On提出,并且试图将其发展成为工业标准,从而代替陈旧的Dhrystone标准。代码使用C语言写成,包含如下的运算法则:列举(寻找并排序),数学矩阵操作(普通矩阵运算)和状态机(用来确定输入流中是否包含有效数字),最后还包括CRC(循环冗余校验)。
CoreMark是一个综合基准,用于测量嵌入式系统中使用的中央处理器(CPU)的性能。CoreMark也是STM32每次发布新品芯片必然要秀的跑分数据。
测试环境:
硬件:统一STM32F103开发板,换上各厂商的测试芯片。
软件:统一同一主频下, 同一COREMARK程序,同时运行并打印跑分测试结果。
由于STM32F103自带Prefetchbuff ,所以以下会有开和不开的两个跑分。
测试项目及文件函数解读:
---注:花一点篇幅介绍下测试代码,普通读者可以略去直接跳到后面测试结果,测试程序,可以联系官网下载。
1、链接列表
(1)概要
core_list_join.c
函数:
(2)描述
此Benchmark所做的项目 1.将一个项目插入列表2.从列表中删除一个项目。3.撤销删除操作。4.在列表中找到一个项目5.反转一个列表6.在不递归的情况下对列表进行排序。
虽然增加了间接访问数据的级别,但这种结构是现实的,可用于许多用于中小型列表的嵌入式应用程序。
列表本身将在将被传递给初始化函数的一块内存上初始化。尽管通常链表使用malloc作为新节点,但嵌入式应用程序有时会直接控制小数据结构(如数组和列表)的内存以避免系统调用的开销,因此这种方法是现实的。
链表将被初始化,以使得列表指针的四分之一指向存储器中的顺序区域,并且列表指针的三分之一以非顺序方式分布。这样做是为了模拟一个链接列表,其中添加/删除操作会暂时中断整齐的顺序,然后一系列可能来自连续内存位置的添加。
对于基准本身:
将执行多个查找操作。这些查找操作可能会导致整个列表被遍历。每次查找的结果将成为输出链的一部分。列表将使用基于data16值的合并排序进行排序,然后根据列表的一部分导出data16项目的CRC。CRC将成为产品链的一部分。
列表将使用基于idx值的合并排序再次排序。这种排序将保证列表在离开函数之前返回到主状态,这样函数的多次迭代将具有相同的结果。列表部分的data16的CRC将再次被计算并成为输出链的一部分。
每个单元中的实际数据16将根据单个16b输入进行伪随机编码,这些输入在编译时无法确定。此外,用于CRC的列表部分也将传递给该函数,并根据在运行时无法确定的输入来确定。
使用链接列表的基准。链接列表是许多应用程序中使用的常见数据结构。就我们的目的而言,这将锻炼处理器的内存单元。特别是使用列表指针来查找和更改数据。
相反,被传入的内存块用于创建一个列表,并且该基准会小心不要添加更多项目,然后可以通过内存块调整。移植层将确保我们有一个有效的内存块。
所有操作均已完成,无需使用任何额外内存。
2、矩阵操纵基准
(1)概要
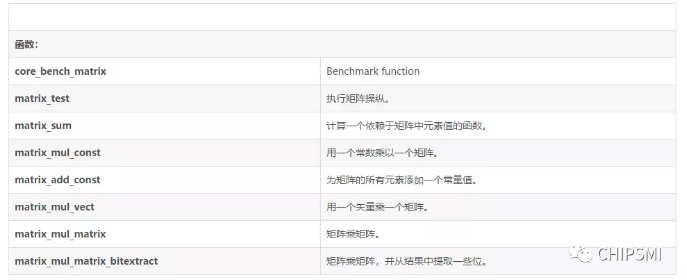
(2)描述
Matrixmanipulation benchmark,这个非常简单的算法构成了许多更复杂算法的基础。紧密的内部循环是许多优化(编译器以及基于硬件)的重点,因此与嵌入式处理相关。
它所做的测试包含1.用一个常数乘以一个矩阵。2.为矩阵的所有元素添加一个常量值。3.用一个矢量乘一个矩阵。4.用矩阵乘以一个矩阵。5.将矩阵乘以矩阵。6.并从结果中提取一些bits。
总可用数据空间将被分为3部分
NxN矩阵A 用较小的值初始化(上部3/4位全部为零)。
NxN矩阵B 初始化为中等值(上半部分全部为零)。
NxN矩阵C 用于结果。
A和B的实际值必须根据编译时不可用的输入来派生。
1、状态机基准
(1)概要
core_state.c
函数:
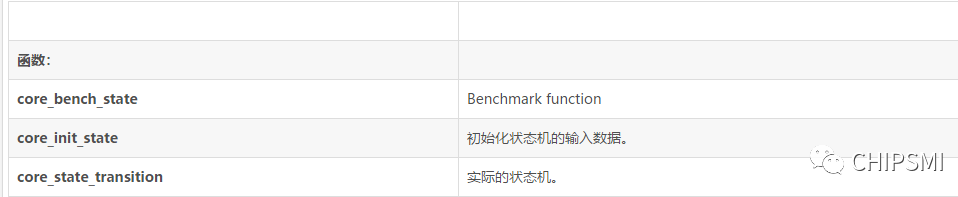
(2)描述
许多嵌入式产品都使用这种简单的状态机。对于更复杂的状态机,有时会使用状态转换表实现,而直接编码的交易速度易于维护。由于在CoreMark中使用状态机的主要目的是为了锻炼switch/if的运转情况,我们使用的是小型moore机器。特别是,这台机器测试字符串输入的类型,试图确定输入是数字还是别的东西。
测试结果:
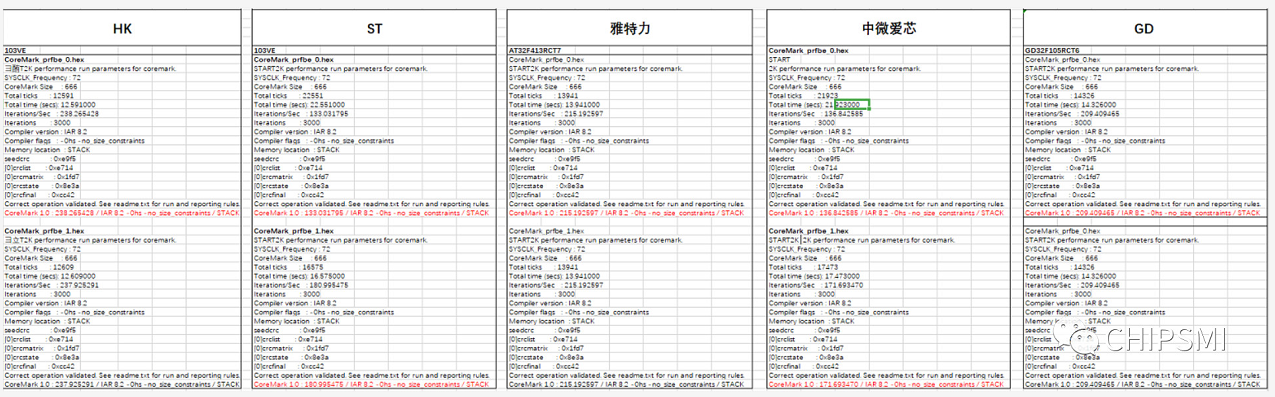
前三名CoreMark分数
HK32F103VET6 238 分
AT32F413RCT7 215 分
GD32F103VET6 209 分
是不是跟小编一样很是意外,我们一一来看后面的数据。
STM32F103的跑分结果,没什么好说,直接上图。 开了Prefetchbuff 跑分多了近50分。
兆易创新GD32 MCU是中国高性能通用微控制器领域的先期领跑者,国内第一个推出的Arm Cortex-M3及Cortex-M4 内核通用MCU产品系列,19个系列300余款产品,当之无愧的ST以外的市场佼佼者。这次横向评测的型号GD32F103 采用的双DIE设计。(2019最新的E系是单DIE,但代码不兼容)GD的FLASH跟MCU合封,这个设计最直接的劣势就是效率低,功耗大。因为两颗DIE, MCU跟FLASH分开,取址效率,程序执行效率低,功耗变大。但GD每颗型号都多加了32K 甚至更大的RAM,上电就把FLASH里的程序放到 RAM里面,这也是GD宣传主打的所谓的 Flash零等待技术,没有了提取指令的时间,通过这个设计来弥补硬件架构上的硬伤。但弊端也很明显,成本高,且超出RAM的部分程序,代码执行效率就非常非常低了。此次测试程序代码大小应该完全是在RAM能提取的部分内。测试之前,猜测GD应该跑分最高。果然GD跑分209分,至于排名第三,是不是因为程序和数据共用一个RAM?
雅特力是位于重庆的一家微控制器芯片(MCU)设计公司,专攻32位 ARM Cortex®-M4 MCU产品, 也是***UMC旗下投资的公司,这次横向评测采用的雅特力芯片AT32F413 也是本次所有测试芯片MCU里面唯一一个M4核的芯片。雅特力采用M4高性能 高主频 先进工艺制程 ,用M4降维兼容ST的 M3系列。主打就是高性能路线。M4的优势就不过多介绍,内核带单精度浮点运算单元(FPU),支持所有ARM ® 单精度数据处理指令和数据类型,更快的处理速度,浮点运算能力,综合效率M4远超M3。测试之前,小编猜测应该雅特力是最高跑分的竞争者之一,果然跑分215分 排名第二。
航顺芯片,说实话在2018年之前开发布会,沙龙,展览因为业界看不懂褒贬不一,2019年在深圳国际嵌入式展会广场巨大广告牌“打出通用/专用32位MCU/SOC孵化100+MCU原厂”血红的“中国科学院 深圳市产业基金 中国航空工业集团联合打造”被吸引。对于国人很多夸张的宣传,什么最牛,第一,最稳定,功耗最低,小编其实是不感冒的,但是航顺这几年逐步占领市场越来越多的得到客户好评而好奇产生冲动一探究竟。说太多吹太多没有用,不服来干。小编一直是这种事实说话的态度。在展会上向航顺芯片申请样品,航顺接待人员非常热情,大方提供各种M0 M3 M4样品,此次测试前基本完全不太看好,但跑分却是本次最大的黑马,238分第一,确实大跌眼镜,大大超乎意料。怪不得国企央企国资都联合背书站台,估计他们看中的就是航顺的核心技术能力,此前业界各种褒贬和友商互相抬高自己打压同行航顺依然一边营销建立品牌一边地推得到很多客户认可,航顺核心技术能力他们应该胸有成竹。但有意打探航顺几位创始人,他们都表示不太方便透露,跑分 性能稳定性 兼容性 功耗低 抗干扰等综合水平好不好其实非常简单,应用客户一测试就知道。翻阅了下HK的芯片手册,新加入的cache 可以提升指令效率,但cache也才1K。至于跑分这么高的原因,小编也只能猜测是不是采用了什么黑科技,CPU跟MEMORY的架构优化做到了很极致。
中微爱芯是中科芯控股旗下的,中字头,中规中矩,跑分也中规中矩。此次跑分是国产唯一家开Prefetchbuff和不开 Prefetchbuff分数有差异的。各项分数也是跟ST差不多。开Prefetchbuff居然还比ST低了几分 171分。从纯模仿的角度,是比较完全按照ST的方式。其余几家国产基本都摈弃了prefetchbuff的做法。我有更快的速度,有cache,有M4,开不开都已经从跑分碾压上完全体现了,完全的模仿有没有必要?当然这只是芯片众多细节的一点。
最后, 国内芯片Coremark跑分都超过了ST,这点很欣慰 (中微爱芯开prefetchbuff 的跑分比ST差一点点)。但这完全得益于后发优势,新的架构和新的工艺。有喜有忧,毕竟STM32F103已是十年前的芯片了,国产芯片仍然任重道远。
2007年STM32首发, 中途历经.18, .13的工艺,改了几版到现在的版本也是十年前的事了。STM32之父、意法半导体微控制器事业部Daniel Colonna曾说过,“十年前我们选择了蝴蝶作为STM32的代表Logo,意味着我们要利用STM32,为工程师、开发者们释放更多创造力。” 如今这只蝴蝶扇动了STM32芯片占据全球市场半壁江山的份额,这几年国产芯片把STM32作为模仿对标学习的对象当之无愧。
记得曾和一个朋友聊天,这么多家仿STM32的芯片。哪家做的最好?国产芯片和国外芯片的差距,到底在哪里?仿STM32,软硬件完全兼容,市场替换快?客户接受度高? 小编的看法确是,模仿或许只是一个切入口。明星模仿秀,比如模仿张学友,一个活生生的自然人硬要做到一模一样,甚至连吃饭走路都刻意要做成一样,最后把自身很多优点习惯都丢掉,甚至走路说话都不正常,这到底是好还是不好?从模仿的角度切入,方便客户替换,便于开发者上手这点很好,但不同的设计架构电路IP理念,不同时期的工艺,纯粹为了模仿而模仿,甚至降维降级去做兼容,有时候讨好的不一定是终端使用者,反而是芯片设计本身的一种浪费和冗杂。模仿却不全仿,抄袭但可以逆袭。同样作为终端应用者的我们也要给与国产芯片更多的耐心与包容,国产替换的过程,一行代码不兼容,一个配置设定不同,就质疑芯片本身,或许使用者本身完全也不全会测试和应用,甚至是外行,过多的关注产品销售和客户本身,却忽略了芯片和方案应用的源本。就像航顺,中微等等国产刚出来的时候被质疑被互损诋毁一样,或许有时候不是芯片不好,是你应用不好。这次跑分的结果或许也能说明某些。中国芯不仅仅是一种情怀,也更需要更包容和更理解的土壤,需要更多的应用者使用者去尝试去参与去等待去共同进步。
创新,革新,做好自己,做更好的自己。从模仿到创新,从抄袭到逆袭。此次的测评跑分国产芯片全面超越ST,除了后发优势,国产芯片的创新,加入cache,M4,程序RAM,跑分全面超越国外芯片。但愿我们能看到一个新的芯时代的开启。
跑分是衡量MCU芯片性能的一个非常非常重要标准,但不是唯一标准,下期将从另外维度评测。由于测试的环境外设,软件硬件的不兼容性,为了确保测试公平一致性,某些代码不兼容的国产芯片(灵动 华大等等)此期暂时不在本文列出。(类似华为手机小米手机跑分比赛,都是安卓平台,有较强的可比性。苹果自建生态跑分的参考性就会有换算的条件)




























 工商网监
工商网监
评论