 电子发烧友App
电子发烧友App


引言
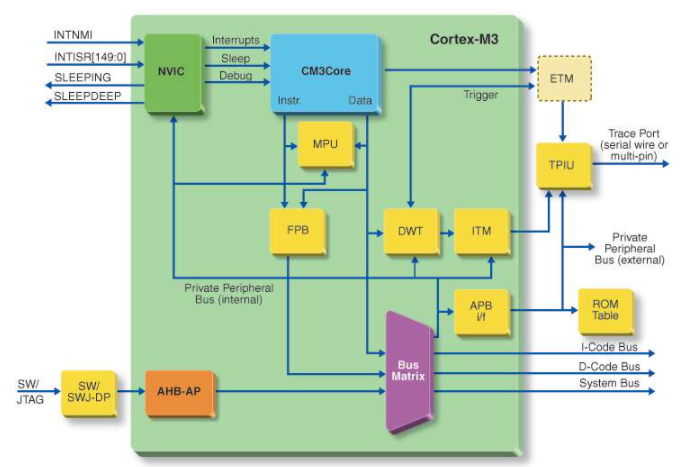
CortexM3是ARM公司第一款基于ARMv7M的微控制器内核,在指令执行、异常控制、时钟管理、跟踪调试和存储保护等方面相对于 ARM7有很大的区别。尤其在异常处理机制方面有很大的改进,其异常响应只需要12个时钟周期。NVIC(Nested Vectored Interrupt Controller,嵌套向量中断控制器)是CortexM3处理器的一个紧耦合部件,可以配置1~240个带有256个优先级、8级抢占优先权的物理中断,为处理器提供出色的异常处理能力[1].同时,抢占(preemption)、尾链(tailchaining)、迟到 (latearriving)技术的使用,大大缩短了异常事件的响应时间。
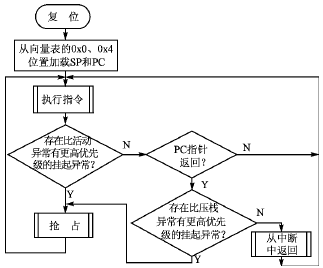
异常或者中断是处理器响应系统中突发事件的一种机制。当异常发生时,CortexM3通过硬件自动将编程计数器(PC)、编程状态寄存器(xPSR)、链接寄存器(LR)和R0~R3、R12等寄存器压进堆栈。在Dbus(数据总线)保存处理器状态的同时,处理器通过Ibus(指令总线)从一个可以重新定位的向量表中识别出异常向量,并获取ISR函数的地址,也就是保护现场与取异常向量是并行处理的。一旦压栈和取指令完成,中断服务程序或故障处理程序就开始执行。执行完ISR,硬件进行出栈操作,中断前的程序恢复正常执行。图1为CortexM3处理器的异常处理流程[2].

图1 CortexM3异常处理流程
1 CortexM3异常类型
同ARM7相比,CortexM3在异常的分类和优先级上有很大的差异,如表1所列。

表1CortexM3异常类型及优先级
CortexM3将异常分为复位、不可屏蔽中断、硬故障、存储管理、总线故障和应用故障、SVcall、调试监视异常、PendSV、 SysTick以及外部中断等。CortexM3采用向量表来确定异常的入口地址。与大多数其他ARM内核不同,CortexM3向量表中包含异常处理程序和ISR的地址,而不是指令。复位处理程序的初始堆栈指针和地址必须分别位于0x0和0x4.这些值在随后的复位中被加载到适当的CPU寄存器中。向量表偏移控制寄存器将向量表定位在CODE(Flash)或SRAM中。复位时,默认情况下为CODE模式,但可以重新定位。异常被接受后,处理器通过 Ibus查表获取地址,执行异常处理程序。
在CortexM3的优先级分配中,较低的优先级值具有较高的优先级。NVIC将异常的优先级分成两部分:抢占优先级(preemption priority)部分和子优先级(subpriority)部分,可以通过中断申请/复位控制寄存器来确定两个部分所占的比例。抢占优先级和子优先级共同作用确定了异常的优先级。抢占优先级用于决定是否发生抢占,一个异常只有在抢占优先级高于另一个异常的抢占优先级时才能发生抢占。当多个挂起异常具有相同的抢占优先级时,子优先级起作用[3].通过NVIC设置的优先级权限高于硬件默认优先级。当有多个异常具有相同的优先级时,则比较异常号的大小,异常号小的被优先激活。
2 CortexM3异常处理
2.1 异常的进入
当一个异常出现以后,CortexM3处理器由硬件通过Dbus保存处理器状态,同时通过Ibus读取向量表中的SP,更新PC和LR,执行中断服务子程序。
为了应对堆栈操作阶段到来后的更高优先级异常,CortexM3支持迟到和抢占机制,以便对各种可能事件做出确定性的响应。
抢占是一种对更高优先级异常的响应机制。CortexM3异常抢占的处理过程[2] 如图2所示。当新的更高优先级异常到来时,处理器打断当前的流程,执行更高优先级的异常操作,这样就发生了异常嵌套。迟到是处理器用来加速抢占的一种机制。如果一个具有更高优先级的异常在上一个异常执行压栈期间到达,则处理器保存状态的操作继续执行,因为被保存的状态对于两个异常都是一样的。但是,NVIC马上获取的是更高优先级的异常向量地址。这样在处理器状态保存完成后,开始执行高优先级异常的ISR.

图2 异常抢占流程
2.2 异常的返回
CortexM3异常返回的操作[2]如图3所示。当从异常中返回时,处理器可能会处于以下情况之一[4]:
◆ 尾链到一个已挂起的异常,该异常比栈中所有异常的优先级都高;
◆ 如果没有挂起的异常,或是栈中最高优先级的异常比挂起的最高优先级异常具有更高的优先级,则返回到最近一个已压栈的ISR;
◆ 如果没有异常已经挂起或位于栈中,则返回到Tread模式。
为了应对异常返回阶段可能遇到的新的更高优先级异常,CortexM3支持完全基于硬件的尾链机制,简化了激活的和未决的异常之间的移动,能够在两个异常之间没有多余的状态保存和恢复指令的情况下实现backtoback处理。尾链发生的2个条件[2]:异常返回时产生了新的异常;挂起的异常的优先级比所有被压栈的异常的优先级都高。
尾链发生后,CortexM3处理过程如图3中尾链分支所示。这时,CortexM3处理器终止正在进行的出栈操作并跳过新异常进入时的压栈操作,同时通过Ibus立即取出挂起异常的向量。在退出前一个ISR返回操作6个周期后,开始执行尾链的ISR.

图3 异常的返回
3 CortexM3和ARM7中断控制器比较
在过去的十年中,基于ARMv4的ARM7系列微控制器广泛应用在各个领域。在ARM7系列中,并没有对中断进行独立的服务,而是通过牺牲处理器一定的性能来换取有效的中断响应和中断处理机制。CortexM3高度耦合的NVIC可以实现硬件中断处理,同时支持迟到和尾链机制,加快了异常响应的速度,充分发挥了处理器的性能。
图4 为CorexM3和ARM7在中断控制器结构方面的差异。
比较可知,NVIC是直接作为CortexM3处理器的一部分,集成在处理器核内部;而VIC只是游离在ARM7内核的外围,这样就必然占用内核资源,影响了处理速度。CortexM3和ARM7中断控制器在功能和实现方式上的差异如表2所列。

图4 CortexM3和ARM7中断控制器结构的差异

表2 CortexM3和ARM7中断控制器功能和实现方式的差异
3.1 处理器响应单个异常
CortexM3和ARM7异常处理过程如图5所示。

图5 CortexM3和ARM7异常处理过程
ARM7处理器的异常开销:
CortexM3处理器的异常开销:
其中,TARM7为ARM7处理异常的时间开销;TARM7_PUSH和TARM7_POP为ARM7进行压栈和出栈的操作时间;TCoretxM3为CortexM3处理异常的时间开销;TM3_PUSH和TM3_POP为CortexM3进行压栈和出栈的操作时间。
可见,由于采用处理器状态硬件保存,CortexM3处理器少用了18周期,节省了42.8%的异常开销。
3.2 处理器响应迟到异常
CortexM3和ARM7在处理迟到高优先级异常时的差异如图6所示。
当IRQ2正在为执行ISR2保存处理器状态时,迟到了一个优先级更高的异常IRQ1.这时ARM7继续进行压栈操作。在压栈操作完成后,ARM7继续为执行ISR1进行压栈操作,然后执行ISR1.其实,两次压栈操作所保存的内容是一样的。因此,CortexM3对这个阶段的操作进行了优化,引进了迟到异常技术,只进行一次的压栈操作。并且在ISR1执行完成之后,CortexM3没有进行出栈操作,而是通过一个6周期的尾链,直接进入ISR2的执行。

图6 NVIC对迟到的具有更高优先级异常的响应
在上面的例子中,ARM7处理器的异常开销:
CortexM3处理器的异常开销:
其中,TARM7_later和TM3_later分别为ARM7和CortexM3处理迟到异常所用的时间开销;Ttailchaining为CortexM3处理尾链所用的时间。
通过计算可以看出,CortexM3少用了44周期,节省65%的异常开销。
3.3 处理器处理backtoback异常
若一个新的异常在上一个异常寄存器出栈时到来,ARM7和CortexM3的处理方式也有很大不同。CortexM3和ARM7在处理 backtoback异常时的差异如图7所示。ARM7继续当前的出栈操作,在出栈操作完成后,处理器为执行ISR2进行压栈操作,然后执行 ISR2.其实,这时候处理器出栈和压栈的内容是一致的。CortexM3同样优化了这个阶段的操作,引进了尾链机制。当IRQ2到来时,CortexM3立即中止已经进行了8个周期的出栈操作,转而进行尾链操作,然后执行ISR2.

图7 NVIC抢占出栈
在处理backtoback异常时,ARM7处理器用在ISR1到ISR2转换的异常开销:
CortexM3处理器用在ISR1到ISR2转换的异常开销:
其中,TARM_btb和TM3_btb分别为ARM7和CortexM3处理backtoback异常转换所用的时间开销;Tcancel为发生尾链时CortexM3已用于状态恢复的时间。
通过计算可以看出,CortexM3少用了28周期。其实,CortexM3处理器用在ISR1到ISR2转换的异常开销最低可以优化到只用6个周期, 这样就极大地提高了backtoback异常的响应能力。
结语
本文阐述了CortexM3处理器的异常处理机制。通过和ARM7进行比较,量化分析了CortexM3在异常处理方面的优势,对工程师使用CortexM3的异常处理会有一定参考和帮助。
STM32/STM8
意法半导体/ST/STM











 工商网监
工商网监
评论