 电子发烧友App
电子发烧友App


1. 前言
工作队列(workqueue)的Linux内核中的定义的用来处理不是很紧急事件的回调方式处理方法.
以下代码的linux内核版本为2.6.19.2, 源代码文件主要为kernel/workqueue.c.
2. 数据结构
/* include/linux/workqueue.h */
// 工作节点结构
struct work_struct {
// 等待时间
unsigned long pending;
// 链表节点
struct list_head entry;
// workqueue回调函数
void (*func)(void *);
// 回调函数func的数据
void *data;
// 指向CPU相关数据, 一般指向struct cpu_workqueue_struct结构
void *wq_data;
// 定时器
struct timer_list timer;
};
struct execute_work {
struct work_struct work;
};
/* kernel/workqueue.c */
/*
* The per-CPU workqueue (if single thread, we always use the first
* possible cpu).
*
* The sequence counters are for flush_scheduled_work(). It wants to wait
* until all currently-scheduled works are completed, but it doesn't
* want to be livelocked by new, incoming ones. So it waits until
* remove_sequence is >= the insert_sequence which pertained when
* flush_scheduled_work() was called.
*/
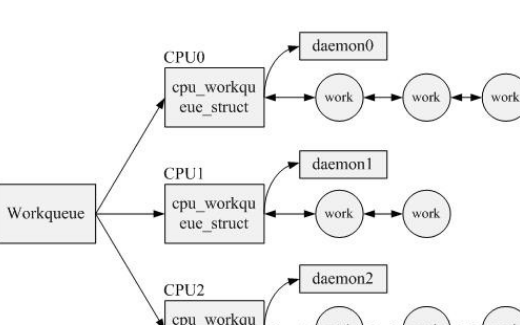
// 这个结构是针对每个CPU的
struct cpu_workqueue_struct {
// 结构锁
spinlock_t lock;
// 下一个要执行的节点序号
long remove_sequence; /* Least-recently added (next to run) */
// 下一个要插入节点的序号
long insert_sequence; /* Next to add */
// 工作机构链表节点
struct list_head worklist;
// 要进行处理的等待队列
wait_queue_head_t more_work;
// 处理完的等待队列
wait_queue_head_t work_done;
// 工作队列节点
struct workqueue_struct *wq;
// 进程指针
struct task_struct *thread;
int run_depth; /* Detect run_workqueue() recursion depth */
} ____cacheline_aligned;
/*
* The externally visible workqueue abstraction is an array of
* per-CPU workqueues:
*/
// 工作队列结构
struct workqueue_struct {
struct cpu_workqueue_struct *cpu_wq;
const char *name;
struct list_head list; /* Empty if single thread */
};
kernel/workqueue.c中定义了一个工作队列链表, 所有工作队列可以挂接到这个链表中:
static LIST_HEAD(workqueues);
3. 一些宏定义
/* include/linux/workqueue.h */
// 初始化工作队列
#define __WORK_INITIALIZER(n, f, d) {
// 初始化list
.entry = { &(n).entry, &(n).entry },
// 回调函数
.func = (f),
// 回调函数参数
.data = (d),
// 初始化定时器
.timer = TIMER_INITIALIZER(NULL, 0, 0),
}
// 声明工作队列并初始化
#define DECLARE_WORK(n, f, d)
struct work_struct n = __WORK_INITIALIZER(n, f, d)
/*
* initialize a work-struct's func and data pointers:
*/
// 重新定义工作结构参数
#define PREPARE_WORK(_work, _func, _data)
do {
(_work)->func = _func;
(_work)->data = _data;
} while (0)
/*
* initialize all of a work-struct:
*/
// 初始化工作结构, 和__WORK_INITIALIZER功能相同,不过__WORK_INITIALIZER用在
// 参数初始化定义, 而该宏用在程序之中对工作结构赋值
#define INIT_WORK(_work, _func, _data)
do {
INIT_LIST_HEAD(&(_work)->entry);
(_work)->pending = 0;
PREPARE_WORK((_work), (_func), (_data));
init_timer(&(_work)->timer);
} while (0)
4. 操作函数
4.1 创建工作队列
一般的创建函数是create_workqueue, 但这其实只是一个宏:
/* include/linux/workqueue.h */
#define create_workqueue(name) __create_workqueue((name), 0)
在workqueue的初始化函数中, 定义了一个针对内核中所有线程可用的事件工作队列, 其他内核线程建立的事件工作结构就都挂接到该队列:
void init_workqueues(void)
{
...
keventd_wq = create_workqueue("events");
...
}
核心创建函数是__create_workqueue:
struct workqueue_struct *__create_workqueue(const char *name,
int singlethread)
{
int cpu, destroy = 0;
struct workqueue_struct *wq;
struct task_struct *p;
// 分配工作队列结构空间
wq = kzalloc(sizeof(*wq), GFP_KERNEL);
if (!wq)
return NULL;
// 为每个CPU分配单独的工作队列空间
wq->cpu_wq = alloc_percpu(struct cpu_workqueue_struct);
if (!wq->cpu_wq) {
kfree(wq);
return NULL;
}
wq->name = name;
mutex_lock(&workqueue_mutex);
if (singlethread) {
// 使用create_workqueue宏时该参数始终为0
// 如果是单一线程模式, 在单线程中调用各个工作队列
// 建立一个的工作队列内核线程
INIT_LIST_HEAD(&wq->list);
// 建立工作队列的线程
p = create_workqueue_thread(wq, singlethread_cpu);
if (!p)
destroy = 1;
else
// 唤醒该线程
wake_up_process(p);
} else {
// 链表模式, 将工作队列添加到工作队列链表
list_add(&wq->list, &workqueues);
// 为每个CPU建立一个工作队列线程
for_each_online_cpu(cpu) {
p = create_workqueue_thread(wq, cpu);
if (p) {
// 绑定CPU
kthread_bind(p, cpu);
// 唤醒线程
wake_up_process(p);
} else
destroy = 1;
}
}
mutex_unlock(&workqueue_mutex);
/*
* Was there any error during startup? If yes then clean up:
*/
if (destroy) {
// 建立线程失败, 释放工作队列
destroy_workqueue(wq);
wq = NULL;
}
return wq;
}
EXPORT_SYMBOL_GPL(__create_workqueue);
// 创建工作队列线程
static struct task_struct *create_workqueue_thread(struct workqueue_struct *wq,
int cpu)
{
// 每个CPU的工作队列
struct cpu_workqueue_struct *cwq = per_cpu_ptr(wq->cpu_wq, cpu);
struct task_struct *p;
spin_lock_init(&cwq->lock);
// 初始化
cwq->wq = wq;
cwq->thread = NULL;
cwq->insert_sequence = 0;
cwq->remove_sequence = 0;
INIT_LIST_HEAD(&cwq->worklist);
// 初始化等待队列more_work, 该队列处理要执行的工作结构
init_waitqueue_head(&cwq->more_work);
// 初始化等待队列work_done, 该队列处理执行完的工作结构
init_waitqueue_head(&cwq->work_done);
// 建立内核线程work_thread
if (is_single_threaded(wq))
p = kthread_create(worker_thread, cwq, "%s", wq->name);
else
p = kthread_create(worker_thread, cwq, "%s/%d", wq->name, cpu);
if (IS_ERR(p))
return NULL;
// 保存线程指针
cwq->thread = p;
return p;
}
static int worker_thread(void *__cwq)
{
struct cpu_workqueue_struct *cwq = __cwq;
// 声明一个等待队列
DECLARE_WAITQUEUE(wait, current);
// 信号
struct k_sigaction sa;
sigset_t blocked;
current->flags |= PF_NOFREEZE;
// 降低进程优先级, 工作进程不是个很紧急的进程,不和其他进程抢占CPU,通常在系统空闲时运行
set_user_nice(current, -5);
/* Block and flush all signals */
// 阻塞所有信号
sigfillset(&blocked);
sigprocmask(SIG_BLOCK, &blocked, NULL);
flush_signals(current);
/*
* We inherited MPOL_INTERLEAVE from the booting kernel.
* Set MPOL_DEFAULT to insure node local allocations.
*/
numa_default_policy();
/* SIG_IGN makes children autoreap: see do_notify_parent(). */
// 信号处理都是忽略
sa.sa.sa_handler = SIG_IGN;
sa.sa.sa_flags = 0;
siginitset(&sa.sa.sa_mask, sigmask(SIGCHLD));
do_sigaction(SIGCHLD, &sa, (struct k_sigaction *)0);
// 进程可中断
set_current_state(TASK_INTERRUPTIBLE);
// 进入循环, 没明确停止该进程就一直运行
while (!kthread_should_stop()) {
// 设置more_work等待队列, 当有新work结构链入队列中时会激发此等待队列
add_wait_queue(&cwq->more_work, &wait);
if (list_empty(&cwq->worklist))
// 工作队列为空, 睡眠
schedule();
else
// 进行运行状态
__set_current_state(TASK_RUNNING);
// 删除等待队列
remove_wait_queue(&cwq->more_work, &wait);
// 按链表遍历执行工作任务
if (!list_empty(&cwq->worklist))
run_workqueue(cwq);
// 执行完工作, 设置进程是可中断的, 重新循环等待工作
set_current_state(TASK_INTERRUPTIBLE);
}
__set_current_state(TASK_RUNNING);
return 0;
}
// 运行工作结构
static void run_workqueue(struct cpu_workqueue_struct *cwq)
{
unsigned long flags;
/*
* Keep taking off work from the queue until
* done.
*/
// 加锁
spin_lock_irqsave(&cwq->lock, flags);
// 统计已经递归调用了多少次了
cwq->run_depth++;
if (cwq->run_depth > 3) {
// 递归调用此时太多
/* morton gets to eat his hat */
printk("%s: recursion depth exceeded: %dn",
__FUNCTION__, cwq->run_depth);
dump_stack();
}
// 遍历工作链表
while (!list_empty(&cwq->worklist)) {
// 获取的是next节点的
struct work_struct *work = list_entry(cwq->worklist.next,
struct work_struct, entry);
void (*f) (void *) = work->func;
void *data = work->data;
// 删除节点, 同时节点中的list参数清空
list_del_init(cwq->worklist.next);
// 解锁
// 现在在执行以下代码时可以中断,run_workqueue本身可能会重新被调用, 所以要判断递归深度
spin_unlock_irqrestore(&cwq->lock, flags);
BUG_ON(work->wq_data != cwq);
// 工作结构已经不在链表中
clear_bit(0, &work->pending);
// 执行工作函数
f(data);
// 重新加锁
spin_lock_irqsave(&cwq->lock, flags);
// 执行完的工作序列号递增
cwq->remove_sequence++;
// 唤醒工作完成等待队列, 供释放工作队列
wake_up(&cwq->work_done);
}
// 减少递归深度
cwq->run_depth--;
// 解锁
spin_unlock_irqrestore(&cwq->lock, flags);
}
4.2 释放工作队列
/**
* destroy_workqueue - safely terminate a workqueue
* @wq: target workqueue
*
* Safely destroy a workqueue. All work currently pending will be done first.
*/
void destroy_workqueue(struct workqueue_struct *wq)
{
int cpu;
// 清除当前工作队列中的所有工作
flush_workqueue(wq);
/* We don't need the distraction of CPUs appearing and vanishing. */
mutex_lock(&workqueue_mutex);
// 结束该工作队列的线程
if (is_single_threaded(wq))
cleanup_workqueue_thread(wq, singlethread_cpu);
else {
for_each_online_cpu(cpu)
cleanup_workqueue_thread(wq, cpu);
list_del(&wq->list);
}
mutex_unlock(&workqueue_mutex);
// 释放工作队列中对应每个CPU的工作队列数据
free_percpu(wq->cpu_wq);
kfree(wq);
}
EXPORT_SYMBOL_GPL(destroy_workqueue);
/**
* flush_workqueue - ensure that any scheduled work has run to completion.
* @wq: workqueue to flush
*
* Forces execution of the workqueue and blocks until its completion.
* This is typically used in driver shutdown handlers.
*
* This function will sample each workqueue's current insert_sequence number and
* will sleep until the head sequence is greater than or equal to that. This
* means that we sleep until all works which were queued on entry have been
* handled, but we are not livelocked by new incoming ones.
*
* This function used to run the workqueues itself. Now we just wait for the
* helper threads to do it.
*/
void fastcall flush_workqueue(struct workqueue_struct *wq)
{
// 该进程可以睡眠
might_sleep();
// 清空每个CPU上的工作队列
if (is_single_threaded(wq)) {
/* Always use first cpu's area. */
flush_cpu_workqueue(per_cpu_ptr(wq->cpu_wq, singlethread_cpu));
} else {
int cpu;
mutex_lock(&workqueue_mutex);
for_each_online_cpu(cpu)
flush_cpu_workqueue(per_cpu_ptr(wq->cpu_wq, cpu));
mutex_unlock(&workqueue_mutex);
}
}
EXPORT_SYMBOL_GPL(flush_workqueue);
flush_workqueue的核心处理函数为flush_cpu_workqueue:
static void flush_cpu_workqueue(struct cpu_workqueue_struct *cwq)
{
if (cwq->thread == current) {
// 如果是工作队列进程正在被调度
/*
* Probably keventd trying to flush its own queue. So simply run
* it by hand rather than deadlocking.
*/
// 执行完该工作队列
run_workqueue(cwq);
} else {
// 定义等待
DEFINE_WAIT(wait);
long sequence_needed;
// 加锁
spin_lock_irq(&cwq->lock);
// 最新工作结构序号
sequence_needed = cwq->insert_sequence;
// 该条件是判断队列中是否还有没有执行的工作结构
while (sequence_needed - cwq->remove_sequence > 0) {
// 有为执行的工作结构
// 通过work_done等待队列等待
prepare_to_wait(&cwq->work_done, &wait,
TASK_UNINTERRUPTIBLE);
// 解锁
spin_unlock_irq(&cwq->lock);
// 睡眠, 由wake_up(&cwq->work_done)来唤醒
schedule();
// 重新加锁
spin_lock_irq(&cwq->lock);
}
// 等待清除
finish_wait(&cwq->work_done, &wait);
spin_unlock_irq(&cwq->lock);
}
}
4.3 调度工作
在大多数情况下, 并不需要自己建立工作队列,而是只定义工作, 将工作结构挂接到内核预定义的事件工作队列中调度, 在kernel/workqueue.c中定义了一个静态全局量的工作队列keventd_wq:
static struct workqueue_struct *keventd_wq;
4.3.1 立即调度
// 在其他函数中使用以下函数来调度工作结构, 是把工作结构挂接到工作队列中进行调度
/**
* schedule_work - put work task in global workqueue
* @work: job to be done
*
* This puts a job in the kernel-global workqueue.
*/
// 调度工作结构, 将工作结构添加到事件工作队列keventd_wq
int fastcall schedule_work(struct work_struct *work)
{
return queue_work(keventd_wq, work);
}
EXPORT_SYMBOL(schedule_work);
/**
* queue_work - queue work on a workqueue
* @wq: workqueue to use
* @work: work to queue
*
* Returns 0 if @work was already on a queue, non-zero otherwise.
*
* We queue the work to the CPU it was submitted, but there is no
* guarantee that it will be processed by that CPU.
*/
int fastcall queue_work(struct workqueue_struct *wq, struct work_struct *work)
{
int ret = 0, cpu = get_cpu();
if (!test_and_set_bit(0, &work->pending)) {
// 工作结构还没在队列, 设置pending标志表示把工作结构挂接到队列中
if (unlikely(is_single_threaded(wq)))
cpu = singlethread_cpu;
BUG_ON(!list_empty(&work->entry));
// 进行具体的排队
__queue_work(per_cpu_ptr(wq->cpu_wq, cpu), work);
ret = 1;
}
put_cpu();
return ret;
}
EXPORT_SYMBOL_GPL(queue_work);
/* Preempt must be disabled. */
// 不能被抢占
static void __queue_work(struct cpu_workqueue_struct *cwq,
struct work_struct *work)
{
unsigned long flags;
// 加锁
spin_lock_irqsave(&cwq->lock, flags);
// 指向CPU工作队列
work->wq_data = cwq;
// 挂接到工作链表
list_add_tail(&work->entry, &cwq->worklist);
// 递增插入的序列号
cwq->insert_sequence++;
// 唤醒等待队列准备处理工作结构
wake_up(&cwq->more_work);
spin_unlock_irqrestore(&cwq->lock, flags);
}
4.3.2 延迟调度
4.3.2.1 schedule_delayed_work
/**
* schedule_delayed_work - put work task in global workqueue after delay
* @work: job to be done
* @delay: number of jiffies to wait
*
* After waiting for a given time this puts a job in the kernel-global
* workqueue.
*/
// 延迟调度工作, 延迟一定时间后再将工作结构挂接到工作队列
int fastcall schedule_delayed_work(struct work_struct *work, unsigned long delay)
{
return queue_delayed_work(keventd_wq, work, delay);
}
EXPORT_SYMBOL(schedule_delayed_work);
/**
* queue_delayed_work - queue work on a workqueue after delay
* @wq: workqueue to use
* @work: work to queue
* @delay: number of jiffies to wait before queueing
*
* Returns 0 if @work was already on a queue, non-zero otherwise.
*/
int fastcall queue_delayed_work(struct workqueue_struct *wq,
struct work_struct *work, unsigned long delay)
{
int ret = 0;
// 定时器, 此时的定时器应该是不起效的, 延迟将通过该定时器来实现
struct timer_list *timer = &work->timer;
if (!test_and_set_bit(0, &work->pending)) {
// 工作结构还没在队列, 设置pending标志表示把工作结构挂接到队列中
// 如果现在定时器已经起效, 出错
BUG_ON(timer_pending(timer));
// 工作结构已经挂接到链表, 出错
BUG_ON(!list_empty(&work->entry));
/* This stores wq for the moment, for the timer_fn */
// 保存工作队列的指针
work->wq_data = wq;
// 定时器初始化
timer->expires = jiffies + delay;
timer->data = (unsigned long)work;
// 定时函数
timer->function = delayed_work_timer_fn;
// 定时器生效, 定时到期后再添加到工作队列
add_timer(timer);
ret = 1;
}
return ret;
}
EXPORT_SYMBOL_GPL(queue_delayed_work);
// 定时中断函数
static void delayed_work_timer_fn(unsigned long __data)
{
struct work_struct *work = (struct work_struct *)__data;
struct workqueue_struct *wq = work->wq_data;
// 获取CPU
int cpu = smp_processor_id();
if (unlikely(is_single_threaded(wq)))
cpu = singlethread_cpu;
// 将工作结构添加到工作队列,注意这是在时间中断调用
__queue_work(per_cpu_ptr(wq->cpu_wq, cpu), work);
}
4.3.2.2 schedule_delayed_work_on
指定CPU的延迟调度工作结构, 和schedule_delayed_work相比增加了一个CPU参数, 其他都相同
/**
* schedule_delayed_work_on - queue work in global workqueue on CPU after delay
* @cpu: cpu to use
* @work: job to be done
* @delay: number of jiffies to wait
*
* After waiting for a given time this puts a job in the kernel-global
* workqueue on the specified CPU.
*/
int schedule_delayed_work_on(int cpu,
struct work_struct *work, unsigned long delay)
{
return queue_delayed_work_on(cpu, keventd_wq, work, delay);
}
/**
* queue_delayed_work_on - queue work on specific CPU after delay
* @cpu: CPU number to execute work on
* @wq: workqueue to use
* @work: work to queue
* @delay: number of jiffies to wait before queueing
*
* Returns 0 if @work was already on a queue, non-zero otherwise.
*/
int queue_delayed_work_on(int cpu, struct workqueue_struct *wq,
struct work_struct *work, unsigned long delay)
{
int ret = 0;
struct timer_list *timer = &work->timer;
if (!test_and_set_bit(0, &work->pending)) {
BUG_ON(timer_pending(timer));
BUG_ON(!list_empty(&work->entry));
/* This stores wq for the moment, for the timer_fn */
work->wq_data = wq;
timer->expires = jiffies + delay;
timer->data = (unsigned long)work;
timer->function = delayed_work_timer_fn;
add_timer_on(timer, cpu);
ret = 1;
}
return ret;
}
EXPORT_SYMBOL_GPL(queue_delayed_work_on);
5. 结论
工作队列和定时器函数处理有点类似, 都是执行一定的回调函数, 但和定时器处理函数不同的是定时器回调函数只执行一次, 而且执行定时器回调函数的时候是在时钟中断中, 限制比较多, 因此回调程序不能太复杂; 而工作队列是通过内核线程实现, 一直有效, 可重复执行, 由于执行时降低了线程的优先级, 执行时可能休眠, 因此工作队列处理的应该是那些不是很紧急的任务, 如垃圾回收处理等, 通常在系统空闲时执行,在xfrm库中就广泛使用了workqueue,使用时,只需要定义work结构,然后调用schedule_(delayed_)work即可。











 工商网监
工商网监
评论