 电子发烧友App
电子发烧友App


随着计算机应用的日益普及,用户对计算机的处理能力的需求成指数级增长。为了满足用户的需求,处理器生产厂商采用了诸如超流水、分支预测、超标量、乱序执行及缓存等技术以提高处理器的性能。但是这些技术的采用增加了微处理器的复杂性,带来了诸如材料、功耗、光刻、电磁兼容性等一系列问题。因此处理器设计人员开始寻找新的途径来提高处理器的性能。Intel公司于2002年底推出了超线程技术,通过共享处理器的执行资源,提高CPU的利用率,让处理单元获得更高的吞吐量。
1 超线程技术背景
传统的处理器内部存在着多种并行操作方式。①指令级并行ILP(Instruction Level Paramllelism):同时执行几条指令,单CPU就能完成。但是,传统的单CPU处理器只能同时执行一个线程,很难保证CPU资源得到100%的利用,性能提高只能通过提升时钟频率和改进架构来实现。②线程级并行TLP(Thread Level
Paramllesim):可以同时执行多个线程,但是需要多处理器系统的支持,通过增加CPU的数量来提高性能。
超线程微处理器将同时多线程技术SMT(Simultaneous Multi-Threading)引入Intel体系结构,支持超线程技术的操作系统将一个物理处理器视为两个逻辑处理器,并且为每个逻辑处理器分配一个线程运行。物理处理器在两个逻辑处理器之间分配高速缓存、执行单元、总线等执行资源,让暂时闲置的运算单元去执行其他线程代码,从而最大限度地提升CPU资源的利用率。
Intel 超线程技术通过复制、划分、共享Intel的Netburst微架构的资源让一个物理CPU中具有两个逻辑CPU。(1)复制的资源:每个逻辑CPU都维持一套完整的体系结构状态,包括通用寄存器、控制寄存器、高级可编程寄存器(APIC)以及一些机器状态寄存器,体系结构状态对程序或线程流进行跟踪。从软件的角度,一旦体系结构状态被复制,就可以将一个物理CPU视为两个逻辑CPU。(2)划分的资源:包括重定序(re-order)缓冲、Load/Store缓冲、队列等。划分的资源在多任务模式时分给两个逻辑CPU使用,在单任务模式时合并起来给一个逻辑CPU使用。(3)共享的资源:包括cache及执行单元等,逻辑CPU共享物理CPU的执行单元进行加、减、取数等操作。
在线程调度时,体系结构状态对程序或线程流进行跟踪,各项工作(包括加、乘、加载等)由执行资源(处理器上的单元)负责完成。每个逻辑处理器可以单独对中断作出响应。第一个逻辑处理器跟踪一个线程时,第二个逻辑处理器可以同时跟踪另一个线程。例如,当一个逻辑处理器在执行浮点运算时,另一个逻辑处理器可以执行加法运算和加载操作。拥有超线程技术的CPU可以同时执行处理两个线程,它可以将来自两个线程的指令同时发送到处理器内核执行。处理器内核采用乱序指令调度并发执行两个线程,以确保其执行单元在各时钟周期均处于运行状态。
图1和图2分别为传统的双处理器系统和支持超线程的双处理器系统。传统的双处理器系统中,每个处理器有一套独立的体系结构状态和处理器执行资源,每个处理器上只能同时执行一个线程。支持超线程的双处理器系统中,每个处理器有两套独立体系结构状态,可以独立地响应中断。

2 Linux超线程感知调度优化
Linux从2.4.17版开始支持超线程技术,传统的Linux O(1)调度器不能区分物理CPU和逻辑CPU,因此不能充分利用超线程处理器的特性。Ingo Monlar编写了“HT-aware scheduler patch”,针对超线程技术对O(1)调度器进行了调度算法优化:优先安排线程在空闲的物理CPU的逻辑CPU上运行,避免资源竞争带来的性能下降;在线程调度时考虑了在两个逻辑CPU之间进行线程迁移的开销远远小于物理CPU之间的迁移开销以及逻辑CPU共享cache等资源的特性。这些优化的相关算法被Linux的后期版本所吸收,具体如下:
(1)共享运行队列
在对称多处理SMP(Symmetrical Multi-Processing)环境中,O(1)调度器为每个CPU分配了一个运行队列,避免了多CPU共用一个运行队列带来的资源竞争。Linux会将超线程CPU中的两个逻辑CPU视为SMP的两个独立CPU,各维持一个运行队列。但是这两个逻辑CPU共享cache等资源,没有体现超线程CPU的特性。因此引入了共享运行队列的概念。HT-aware scheduler patch在运行队列struct runqueue结构中增加了nr_cpu和cpu两个属性,nr_cpu记录物理CPU中的逻辑CPU数目,CPU则指向同属CPU(同一个物理CPU上的另一个逻辑CPU)的运行队列,如图3所示。

在Linux中通过调用sched_map_runqueue( )函数实现两个逻辑CPU的运行队列的合并。sched_map_runqueue( )首先会查询系统的CPU队列,通过phys_proc_id(记录逻辑CPU所属的物理CPU的ID)判断当前CPU的同属逻辑CPU。如果找到同属逻辑CPU,则将当前CPU运行队列的cpu属性指向同属逻辑CPU的运行队列。
(2)支持“被动的”负载均衡
用中断驱动的均衡操作必须针对各个物理 CPU,而不是各个逻辑 CPU。否则可能会出现两种情况:一个物理 CPU 运行两个任务,而另一个物理 CPU 不运行任务;现有的调度程序不会将这种情形认为是“失衡的”。在调度程序看来,似乎是第一个物理处理器上的两个 CPU运行1-1任务,而第二个物理处理器上的两个 CPU运行0-0任务。
在2.6.0版之前,Linux只有通过load_balance( )函数才能进行CPU之间负载均衡。当某个CPU负载过轻而另一个CPU负载较重时,系统会调用load_balance( )函数从重载CPU上迁移线程到负载较轻的CPU上。只有系统最繁忙的CPU的负载超过当前CPU负载的 25% 时才进行负载平衡。找到最繁忙的CPU(源CPU)之后,确定需要迁移的线程数为源CPU负载与本CPU负载之差的一半,然后按照从 expired 队列到 active 队列、从低优先级线程到高优先级线程的顺序进行迁移。
在超线程系统中进行负载均衡时,如果也是将逻辑CPU等同于SMP环境中的单个CPU进行调度,则可能会将线程迁移到同一个物理CPU的两个逻辑CPU上,从而导致物理CPU的负载过重。
在2.6.0版之后,Linux开始支持NUMA(Non-Uniform Memory Access Architecture)体系结构。进行负载均衡时除了要考虑单个CPU的负载,还要考虑NUMA下各个节点的负载情况。
Linux的超线程调度借鉴NUMA的算法,将物理CPU当作NUMA中的一个节点,并且将物理CPU中的逻辑CPU映射到该节点,通过运行队列中的node_nr_running属性记录当前物理CPU的负载情况。
Linux通过balance_node( )函数进行物理CPU之间的负载均衡。物理CPU间的负载平衡作为rebalance_tick( )函数中的一部分在 load_balance( )之前启动,避免了出现一个物理CPU运行1-1任务,而第二个物理CPU运行0-0任务的情况。balance_node( )函数首先调用 find_busiest_node( )找到系统中最繁忙的节点,然后在该节点和当前CPU组成的CPU集合中进行 load_balance( ),把最繁忙的物理CPU中的线程迁移到当前CPU上。之后rebalance_tick( )函数再调用load_balance(工作集为当前的物理CPU中的所有逻辑CPU)进行逻辑CPU之间的负载均衡。
(3)支持“主动的”负载均衡
当一个逻辑 CPU 变成空闲时,可能造成一个物理CPU的负载失衡。例如:系统中有两个物理CPU,一个物理CPU上运行一个任务并且刚刚结束,另一个物理CPU上正在运行两个任务,此时出现了一个物理CPU空闲而另一个物理CPU忙的现象。
Linux中通过active_load_balance( )函数进行主动的负载均衡,active_load_balance( )函数用于在所有的逻辑CPU中查询该CPU的忙闲情况。如果发现由于超线程引起的负载不平衡(一个物理CPU的两个逻辑CPU都空闲,另一个物理CPU的两个逻辑CPU都在运行两个线程),则唤醒一个需要迁移的线程,将它从一个忙的物理CPU迁移到一个空闲的物理CPU上。
active_load_balance( )通过调用cpu_rq( )函数得到每一个逻辑CPU上的运行队列。如果运行队列上的当前运行线程为idle线程,则说明当前逻辑CPU为空闲;如果发现一个物理CPU两个逻辑CPU都为空闲,而另一个物理CPU中的两个逻辑CPU的运行队列为繁忙的情况,则说明存在超线程引起的负载不均衡。这时当前CPU会唤醒迁移服务线程(migration_thread)来完成负载均衡的线程迁移。
(4)支持超线程感知的任务挑选
在超线程处理器中,由于cache资源为两个逻辑处理器共享,因此调度器在选取一个新任务时,必须确保同组的任务尽量共享一个物理CPU,从而减少cache失效的开销,提高系统的性能。而传统的调度器只是简单地为逻辑CPU选取一个任务,没有考虑物理CPU的影响。
Linux进行线程切换时会调用schedule( )函数进行具体的操作。如果没有找到合适的任务schedule()函数,则会调度idle线程在当前CPU上运行。在超线程环境中Linux调度idle线程运行之前会查询其同属CPU的忙闲状况。如果同属CPU上有等待运行的线程,则会调用一次load_balance( )函数在两个同属CPU之间作一次负载均衡,将等待运行的线程迁移到当前CPU上,保证优先运行同属CPU上的任务。
(5)支持超线程感知的CPU唤醒
传统的调度器只知道当前CPU,而不知道同属的逻辑CPU。在超线程环境下,一个逻辑CPU正在执行任务时,其上的一个线程被唤醒了,此时,如果它的同属逻辑CPU是空闲的,则应该在同属逻辑CPU上运行刚刚唤醒的任务。
Linux通过wake_up_cpu( )函数实现CPU唤醒,在try_o_wakeup、pull_task、move_task_away加入了wake_up_cpu( )函数的相应调用点。wake_up_cpu()首先查询当前CPU是不是空闲的,如果当前CPU为空闲,则调用resched_cpu( )函数启动调度器,将唤醒的线程调度到当前CPU执行;否则查找其同属逻辑CPU。如果同属逻辑CPU是空闲的,则将唤醒的线程调度到同属逻辑CPU上执行;否则比较唤醒的线程和当前CPU上运行的线程的优先级。如果唤醒的线程的优先级高,或者优先级相等但是时间片多,则进行线程切换,在当前CPU上调度执行唤醒的线程。如果上述条件都不满足,最后比较唤醒的线程和当前CPU的同属逻辑CPU上运行的线程的优先级,如果唤醒的线程的优先级高,或者优先级相等但是时间片多,则在同属逻辑CPU上调度执行唤醒的线程。
3 性能测试
Linux-2.6.0 HT-aware scheduler patch实现了上述超线程调度优化。这里根据linux-2.6.0 HT-aware scheduler patch对这几种调度优化进行了性能测试。
测试硬件环境:Xeon 2.2GHz处理器(支持超线程)×4,2GB SDRAM内存。
Benchmark:(1)Volanomark是一个纯Java的benchmark,专门用于测试系统调度器和线程环境的综合性能。它建立一个模拟Client/Server方式的Java聊天室,通过获取每秒平均发送的消息数来评测宿主机综合性能(数值越大性能越好)。Volanomark测试与Java虚拟机平台相关,本文使用Sun Java SDK 1.4.2作为测试用Java平台,Volanomark版本2.5.0.9。(2)LMBench是一个用于评价系统综合性能的多平台开源benchmark,对其进行修改后实现了lat_thread_ctx接口,用来测试线程的切换开销。
图4表明开启超线程后Volanomark在Linux-2.6.0平台下平均吞吐量提高了25.5%。由于Linux的O(1)内核调度器比较好地实现了SMP负载均衡算法,所以在超线程环境下整个系统的性能也有了比较好的提升。
图5显示出Linux在进行了超线程调度优化后,在支持超线程的平台上所获得的性能加速比。在Linux-2.6.0加入HT-aware scheduler patch后Volanomark的平均吞吐提高了 8.5%,分别实现主动负载均衡、被动的负载均衡、CPU唤醒和任务挑选的相关代码后,吞吐量分别提高了1.8.%、2.5%、2.3%和2.1%。


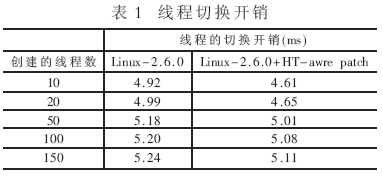
使用Lmbench创建10~150个线程,在不同的负载条件下测试线程的切换开销。表1的数据显示HT-aware scheduler patch可以将线程的切换开销减少3%~7%。数据显示:在轻负载情况下,系统可以获得更多的加速比。这是因为被动的负载均衡以及主动的负载均衡只有在系统有CPU空闲时才能发挥比较好的作用。

4 相关工作和展望
采用支持超线程技术的Linux可以获得较大的性能提升。但是其调度算法还要根据实际的应用进一步研究。参考文献[7]中提出了用“Symbiosis”概念来衡量多个线程在SMT环境中同时执行的有效性。参考文献[8]中提出了线程敏感的调度算法,用一组硬件性能计数器计算两个逻辑CPU上运行不同作业子集的执行信息,利用这些信息来预测不同作业子集的执行性能,并选择具有最好预测性能的作业子集调度同一个物理CPU执行。参考文献[9]中主要研究了适合SMT 结构并考虑作业优先级的调度器。研究结果表明,这些调度算法能有效地提高超线程系统的性能。
Intel的超线程技术是其企业产品线中的重要特征,并将会集成到越来越多的产品中,它标志着Intel微处理器一个新的时代:从指令级并行到线程级并行,这样可使微处理器运行模式与多线程应用的运行模式更加接近,应用程序可以充分利用线程级并行和指令级并行进行优化。随着超线程处理器的发展,可能会出现操作系统使用处理器系统中硬件性能监视器估算系统在某一时间段的某些性能指标,然后利用这些性能指标来指导线程的调度策略。
STM32/STM8
意法半导体/ST/STM













 工商网监
工商网监
评论