 电子发烧友App
电子发烧友App


基准可让您比较处理器,但仍有大量可变性。了解和运行标准基准可以让设计人员更深入地了解和控制他们的应用程序。
比较微处理器从来都不是一件容易的事。即使比较通常具有相同基本架构的所有变体的处理器的台式机或笔记本电脑也可能令人沮丧,因为与“更差”的计算机相比,具有更快数字的计算机可能运行得非常慢。在嵌入式世界中事情变得更加艰难,处理器和配置的数量实际上是无限的。
基准测试是解决这个难题的常用方法。多年来,Dhrystone 基准(对 Whetstone 基准的一种发挥,其中包括 Dhrystone 省略的浮点运算)是城里唯一的游戏。但是,它存在许多重大问题。其中最主要的是它不反映任何真实世界的计算,它只是试图模仿各种操作的统计频率。此外,编译器通常可以在编译时完成大部分计算,这意味着在运行基准测试时不必完成这些工作。
对基准的真正测试是,在详细查看结果(尤其是那些最初看起来很奇怪的结果)时,您可以合理化为什么结果看起来如此。一个理想的基准测试将提供一个纯粹反映处理器性能能力的分数,而与系统的其余部分无关。不幸的是,这是不可能的,因为没有处理器是孤立地运行的:所有处理器都必须与内存交互——高速缓存、数据内存和指令内存,其中每一个都可能会或可能不会以完整的处理器频率运行。此外,这些处理器必须都运行编译器生成的代码,不同的编译器生成不同的代码。
根据您在编译代码时选择的优化设置,即使是同一个编译器也会生成不同的代码。这种差异是无法避免的,但要避免的主要事情是优化实际的基准代码。
尽管结果可能取决于编译器和内存,但您应该能够仅根据处理器本身、编译器(和设置)和内存速度来解释任何此类结果。Dhrystone 基准测试并非如此。然而,来自嵌入式微处理器基准联盟 (EEMBC) 的最新 CoreMark 基准已经克服了这些缺陷,并被证明更加成功。
EEMBC 于 2009 年开发并公开发布了 CoreMark 基准测试(现已有 4,100 多名用户下载)。它已适用于包括 Android 在内的众多平台。开发人员特别注意避免旧基准的陷阱。通过查看 CoreMark 基准测试的工作原理以及一些示例结果,我们可以看到它不仅可以作为可靠的性能指标,还可以帮助确定微控制器和编译器性能可以改进的地方。
CoreMark 基准测试程序
CoreMark 基准测试程序使用三种基本数据结构来表示实际工作。第一个结构是链表,它执行指针操作。第二个是矩阵;矩阵运算通常涉及紧密优化的循环。最后,状态机需要难以预测的分支,并且其结构远不如用于矩阵运算的循环。
为了让尽可能多的嵌入式系统(无论大小)都能访问,该程序的代码占用空间为 2 kb。图 1 说明了该程序的工作原理。前两个步骤可能看起来微不足道,但它们实际上至关重要——它们是确保编译器无法预先计算任何结果的步骤。直到运行时才知道要使用的输入数据。
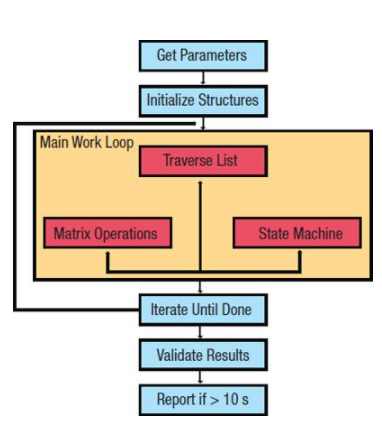
图 1:CoreMark 基准测试流程。
大部分基准测试工作量发生在主工作循环中。扫描其中一种数据结构,一个链表。每个条目的值决定了要执行矩阵运算还是状态机运算。重复此决策操作步骤,直到列表用尽。至此,单次迭代就完成了。重复工作循环,直到经过至少 10 秒。强制要求 10 秒以确保有足够的数据提供有意义的结果。如果它运行的时间少于这个,那么基准程序将不会报告结果。但是,如果用户在模拟器上运行基准测试,则可以修改此时间要求。
主要工作完成后,利用通用循环冗余校验(CRC)功能;它充当自检以确保在执行期间没有出现任何问题(意外或其他原因)。假设一切顺利,程序会报告 CoreMark 结果。这个数字表示每秒执行时间主工作循环的迭代次数。
虽然大多数基准测试用户都是诚实的,但确保任何基准测试方案都具有防止滥用的保护措施始终很重要。有人可以尝试篡改结果的主要方式有两种:编辑代码(在移植层内除外),因为代码必须以源代码形式提供,以及简单地伪造结果。CRC 有助于检测代码损坏时可能出现的任何问题,EEMBC 技术中心的认证是最终仲裁者。没有人需要对其结果进行认证,但认证增加了显着的可信度,因为它确认中立的第三方获得了相同的数字。
调整基准测试运行
虽然程序会根据用户参数来初始化数据,但您并没有明确提供原始数据。那将是太多的工作,而且它还可以通过仔细选择初始化数据来进行操作。相反,程序会查找必须由用户设置的三种子值。
这些数字以对用户不透明的方式指导数据结构中值的初始化。虽然它们充当“种子”,但其中没有随机因素。这些结构是完全确定的,使用相同种子多次运行基准测试将导致相同的执行和结果。
您可能还需要调整基准以考虑系统分配内存的方式。拥有充足资源的系统可以简单地使用 heap 和 malloc() 调用。这允许在需要时进行每次内存分配,并且准确地分配所需的内存量。然而,这种灵活性是有代价的,更好的系统需要更快的内存使用方式。
最快的方法是完全预分配内存,但使用链表操作是不可行的。一种中间方法是创建许多预定义的内存块(内存池),可以根据需要分配这些内存块。权衡是您无法选择在每个块中获得多少内存——您获得的是固定大小的块。移植层允许您使基准测试适应被评估系统上使用的内存分配方案的类型。如果您的系统支持,并行性是您可以利用的另一个特征。您可以为并行操作构建 CoreMark 基准,指定在执行期间要生成的上下文(线程或进程)的数量。但是,您应该避免使用 CoreMark 来表示处理器的多核性能,因为这个基准测试肯定会扩展到 99。
理解结果
当然,您对基准测试结果所做的事情可能会导致混淆(有意或无意)。为此,EEMBC 提出了严格的报告要求。CoreMark 网站 http://www.coremark.org 有一个报告结果的地方,您不能只输入一个 CoreMark 分数。还有一些其他关键变量可能会影响您的结果。
最大的是编译基准时使用的编译器和设置的选项。您必须在提交结果时报告该信息。
第二个主要影响因素是分配内存的方式——如果它不是堆(malloc),您必须报告所采用的方法。
相关的第三个因素是并行化。您必须报告创建的上下文数量。
还有另一种方法可以报告结果。您可以规范化时钟频率,而不是指定原始 CoreMark 值,以便单独关注架构效率。这是一个 CoreMark/MHz 值,用于测量每百万时钟周期的迭代次数。如果您报告这个数字,那么您还必须报告相对于处理器时钟速度的内存速度。如果可以相对于处理器频率配置高速缓存频率,则还必须报告该配置。
查看一些具体结果有助于了解各种所需的报告元素如何与不同的基准分数相关,以及为什么在报告结果时识别这些元素很重要。以下所有数字均来自 CoreMark 网站上的公开结果列表。
编译器版本的简单影响可以从表 1 的结果中看出。ADI 处理器显示,使用较新的编译器版本可实现 10% 的加速,这可能表明新编译器的性能更好。Microchip 示例显示了两个更远的 GNU C 编译器 (gcc) 版本之间的更大差异。对于两个 NXP 处理器,所有编译器都是同一版本的细微变化,从而最大限度地减少了差异。
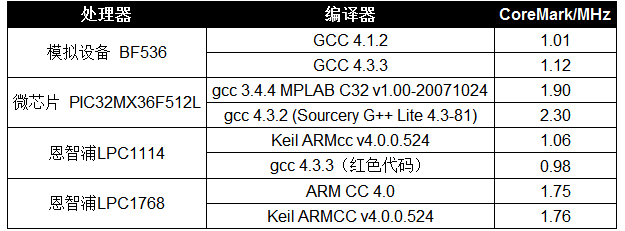
表 1:不同编译器对 CoreMark 结果的影响。
即使使用相同的编译器,不同的设置当然也会产生不同的结果,因为编译器会尝试以不同的方式优化程序。表 2 显示了一些示例结果。

表 2:更改编译器设置会产生不同的 CoreMark 结果。
在第一个示例 (PIC24JF64GA004) 中,针对更小的代码大小进行优化是以降低大约 10% 的基准性能为代价的。第二种情况的差异更为显着,当设置了过程抽象优化标志 (-mpa) 时,运行速度会慢 30%。最后一个处理器上编译器设置之间的差异也反映了优化量的差异,大约 10% 受益于 –O3 设置提供的更高速度优化。
内存的影响可以在表 3 中看到。在第一种情况下,当时钟频率超过闪存可以处理的频率时,会引入等待状态,从而减少 CoreMark/MHz 数。同样,在第二种情况下,DRAM 跟不上 50 MHz 以上的处理器,因此内存和处理器之间的时钟频率比下降到 1:2,降低了 CoreMark/MHz 数。
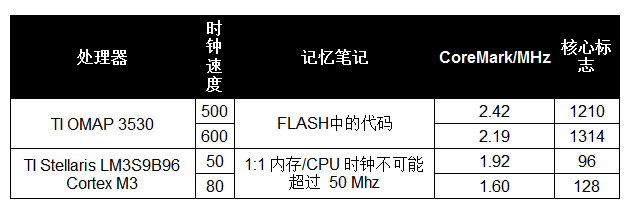
表 4:更改缓存大小对 CoreMark 结果的影响。
然而,在这两种情况下,时钟频率的增加都大于运行效率的下降,因此原始 CoreMark 数字仍然随着时钟频率的增加而上升;它只是没有增加频率。
最后,缓存大小的影响可以在表 4 中看到。这里,代码适合第一个配置的 2 kb 缓存,但它完全填满了缓存。堆栈上的函数参数都不适合,因此会有一些缓存未命中。在第二种情况下,缓存的容量是第一个示例的两倍,这意味着它不会遭受与第一个示例相同的缓存未命中,从而获得更高的分数。

表 3:内存设置对 CoreMark 结果的影响。
请注意,与第一种情况的三级管道相比,第二种情况有一个五级管道。由于状态机示例的广泛分支,较长的管道会导致性能下降。当分支被错误预测时,更长的管道需要更长的时间来重新填充。因此,较高的 CoreMark 分数表明较大的缓存足以弥补这种退化。
所有这些例子中的分数都证明了两个事实。首先,单个数字(在本例中为 CoreMark/MHz)可以准确地表示底层微控制器架构的性能;后面的例子清楚地证明了这一点。然而,第二个事实是背景很重要。编译器可以影响它生成的代码的执行情况。这几乎是显而易见的——人们花费大量时间开发和改进编译器来改进他们创建的结果,但“好的”结果取决于你的目标是快速代码还是小代码。更快的代码会运行得更快,而更小的代码则不会(除了那些实际上有助于优化内存或缓存利用率的情况)。
然而,这些例子显示的最重要的事情是结果之间的差异有合理的解释。它们不是由实际基准测试代码的某些虚构可能导致一种微控制器架构优于另一种,或者由编译器直接丢弃代码引起的。从这个意义上说,CoreMark 基准测试是公平和平衡的,它真实反映了编译器和架构,并且只反映了编译器和架构。

















 工商网监
工商网监
评论