 电子发烧友App
电子发烧友App


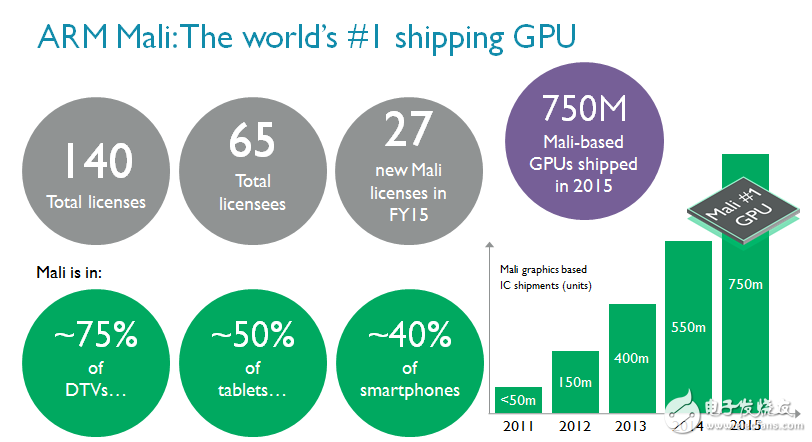
GPU市场增长与Mali™ 技术的成功
2006年,图形处理器(GPU)总出货量约为1.35亿,广泛用于智能手机、DTV和平板电脑等多种设备。同年,ARM® 完成对挪威Falanx公司的收购,并获得其移动GPU技术,完成对原有IP技术的扩展。10年后的今天,仅智能手机的全球出货量就已达到15亿台(据ARM内部数据和Gartner数据显示);短短10年时间,ARM Mali技术也已成为全球出货量第一的GPU,2015年总计出货量超过7.5亿。
本文将重点讨论GPU市场、技术、应用案例,以及GPU爆炸式发展背后的深层原因。同时,文章还将简述ARM Mali GPU及其架构在过去10年的演进,并介绍搭载全新Bifrost架构的Mali-G71。
API与制程节点开发
对图形领域而言,2015年振奋人心——全新应用程序接口(API)的出现允许开发商将基础图形硬件发挥至技术允许的最高水平。
同年,Khronos团队的工作引发有关Vulkan的热烈讨论。Vulkan是新一代OpenGL API,为新一代图形API设计量身打造。Vulkan足以满足全部需求,并彻底终结了OpenGL ES和OpenGL作为API各自为政的时代。
Vulkan于2016年2月正式发布,是首款按照开发商需求设计的Khronos API。它由游戏引擎开发商、芯片提供商、IP公司和操作系统供应商共同开发,以期打造兼顾各相关方需求的最佳解决方案。Vulkan API应运而生,采用全新异构系统,不仅内置多线程支持,而且可以最大程度发挥硬件一致性的优势。Vulkan属于底层API,允许开发商自主决定硬件交互方式,并通过底层接入以找到最佳平衡点。
上述特性对虚拟现实(VR)等新兴应用尤为重要,帮助开放商减少延迟,优化图形流水线。
对聚焦GPU运算应用的开发商来说,OpenCL 2的发布是一个重要节点,多项全新理念进一步简化了高性能GPGPU应用的开发流程。虚拟存储共享概念的提出可以说最为关键,允许CPU和GPU之间的虚拟地址共享。与硬件一致性结合后,细粒度缓冲器共享成为现实。该技术简化了实现CPU和GPU工作负载共享所需的开发工作,因为两者间的数据双向传输不再是必要条件。
半导体制造工艺也经历了巨大革新。2014年,台积电与三星推出20纳米工艺节点,标志着平面工艺节点的10年历史终于落幕。2015年,三星在Exynos 7420上使用全新14纳米FinFet技术,台积电紧随其后,推出16纳米FinFet工艺,并搭载于苹果A9芯片。2016年,工艺节点获得进一步完善,成本降低,产量增加。步入2017年, 10纳米工艺节点也不再是梦想。
从GPU的角度看,工艺节点技术的进步对整个行业意义非凡。首先,工艺节点越先进,单位区域(或功耗)的晶体管密度就越大。GPU属于并行处理器,只要架构扩展,性能就会随之提升。然而,先进工艺节点对布线的扩展效果不如晶体管。恰恰相反,Ergo 工艺制程从28纳米优化至14纳米,SoC设计师得以实现更高的晶体管密度,但却不如布线的扩展。这意味着,如果设计10纳米GPU时采用与28纳米同样的方法,设计结果必然会打折扣,因为晶体管和布线各有权衡,不尽相同。设计师常常需要妥协,使IP适应某个节点,这种权衡随着先进工艺节点数量的增加变得愈加重要。
深入探讨高端移动GPU的性能如何继续提高之前,我们需要特别指出GPU性能从2011年到2016年提升了20倍这个有趣的事实。由于手机同时变得更加轻薄,因此该数字并不能代表技术进步的全景,但现代移动设备开发商对性能提升的渴求已经可见一斑。
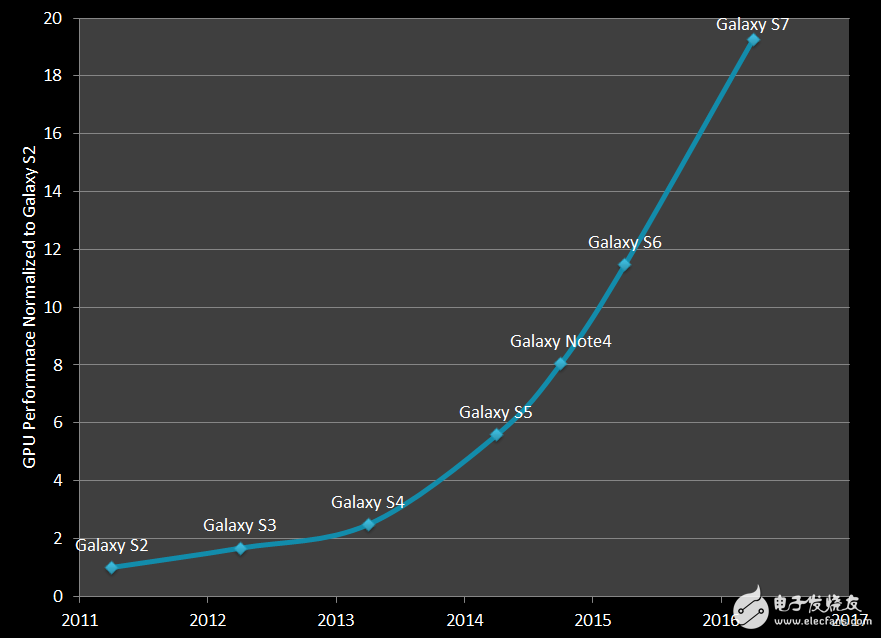
移动设备开发商不断完善现有用例,开发颠覆性的新用例,以保持创新节奏,并从新一轮的性能升级中获益。
案例开发
随着移动平台的发展,各类传感器层出不穷。凭借飞速提升的系统性能、不断改善的屏幕精度和日益增加的电池寿命,移动设备开发商已经坐拥创新的最佳平台。
增强现实(AR)可以充分挖掘并展现智能手机的强劲性能。AR的原理并不复杂,利用高级摄像头捕捉图像,经过CPU、GPU、ISP、VPU和DPU,最后显示在高清屏幕上。这个过程中,增强内容将覆盖实际影像。根据应用目标的不同,物体识别、方位补偿(使用电子罗盘和/或加速度计)或高级渲染技术都将各有用武之地。
一些人气移动应用让AR不再远在天边,并一举进军大众市场,比如将滤镜叠加在用户脸部,然后生成图片和视频用于分享的Snapchat;以及让用户在真实地点看到动画人物的Pokemon Go。无独有偶,还有一些应用采取了更高级的AR技术,比如将摄像头捕捉与3D物体相结合。这些创新用例层出不穷,并可以用于包括零售和高端游戏在内的各行各业。举个例子,用户可以使用移动设备查看家具是否与硬装搭配,家具巨头宜家就打算在2017年发布AR产品目录。
虚拟现实已经不算新理念了,但其核心技术却仍在经历巨变。硬件设备已经万事俱备,拥有足够强大的性能运行炫目的VR内容;一个适合创新的大规模开发商生态系统也已经形成。这一点在移动平台的体现格外深刻,因为人人都能用,且其移动性自身便是重要优势。与台式机和游戏机不同,移动设备无拘无束。当然,实现这一点需要在设备上安装各类传感器。实际上,VR领域的许多重大突破都是在移动设备上实现的——利用VR技术增强用户体验的云霄飞车就是高性能移动应用的一个典型案例。
尽管推陈出新的颠覆式应用不断刷新智能手机的使用方式,但我们经常会忘记一点现实,最普遍的移动应用情景依然是网页浏览和游戏。近几年,屏幕分辨率和刷新率都得到提升,用户界面(UI)的视觉效果和使用体验也越来越自然。这些优化对GPU提出了更高要求,成为成本导向型市场不小的挑战。
移动设备已经成为最主要的游戏平台,由于移动游戏的便捷性,玩家人数持续增加,并进一步推动游戏数量的上升。从免费的独立游戏到数百万美元投资的工作室游戏,现代玩家有丰富的游戏类型、价格和质量等级可供选择。随着可选游戏数量的上升,视觉效果也得到显著改善。GPU刚刚引入移动设备时,3D游戏简单粗暴,不堪入目。而现在呢?游戏画面丰富多彩,景色怡人,动态感十足,在上一代的手柄游戏机时代都是前所未闻的。
上图是ARM演示团队制作的三张示意图。我们先来看看相对简单(以今天的标准)的3D内容,演示游戏为2010年推出的True Force,运行于2011年款的Galaxy S2。每帧图元16k,片段处理每像素时钟周期3.7次,基于OpenGL ES 2.0。
3年后的2013年,OpenGL ES 3.0正式推出,改善了GPU 对GPU运算的支持(并不是OpenGL ES 3.0 API的主打特色,而随OpenGL ES 3.1正式推出);允许开发商使用更多高级渲染技术。结合基础硬件后,视觉质量显著提升。将Trollheim演示与TrueForce比较一下便可一目了然,前者的复杂性比后者高了不少。TrueForce的每帧图元为16k,而Trollheim为150k,TrueForce的片段处理每像素时钟周期为3.7次,而Trollheim则为16次。
2016年,Vulkan正式推出,API效率大幅提高,与OpenGL ES相比能够以更低的开销帮助开发商更好地发挥硬件性能。当然,硬件本身也快速发展,比较一下Lofoten和Trollheim演示,我们即可清楚地看到复杂度的提升:每帧图元提高了300%,片段复杂度提高了150%。
智能手机设计的挑战与趋势
使用场景的变化仅是一个方面,移动设备本身也经历大幅升级。智能手机市场最初主打旗舰机型,随着智能化程度的不断提高,很多 PC特性已经可以实现,但通讯依旧是其主要功能。然而,过去短短几年间,智能手机用途不断扩展,打电话已不再是智能手机的主要功能,图像显示成为了关注焦点。
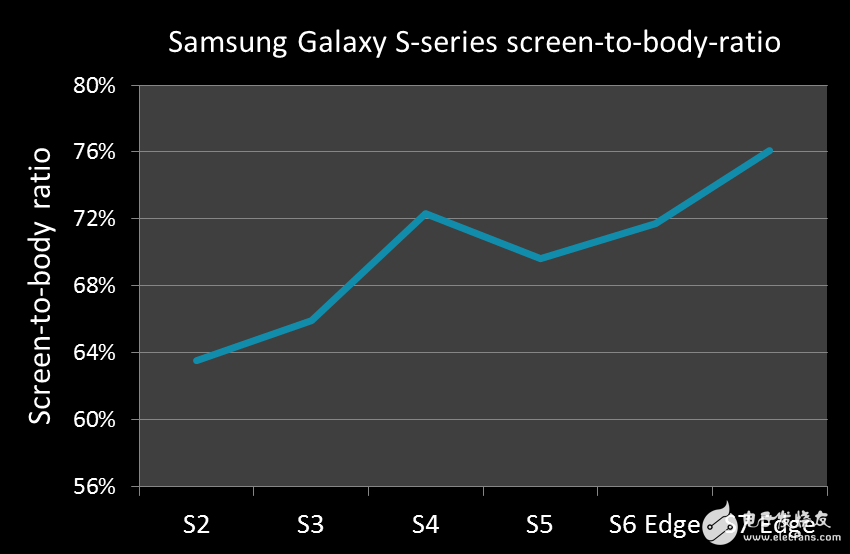
过去,手机电池寿命一般用单次充电支持的通话时长来衡量,而现在的标准则是网络浏览或高端游戏的续航时间。GPU与显示性能一起备受关注。用户希望体验更高质量的视觉效果,到目前为止,这一目标都是经由智能手机设计改善,以及显示内容的美感和流畅性来实现,一个证据就是屏幕边框变得越来越窄。市场的大致趋势是朝着屏幕包裹设备的方向发展,设计美感更多由UI而非硬件来实现。下图中,我们可以看出屏幕占整个设备的比例不断增加。这一趋势在三星Galaxy S7 Edge等机型上体现得尤为明显,已经实现屏幕对设备的全包裹。
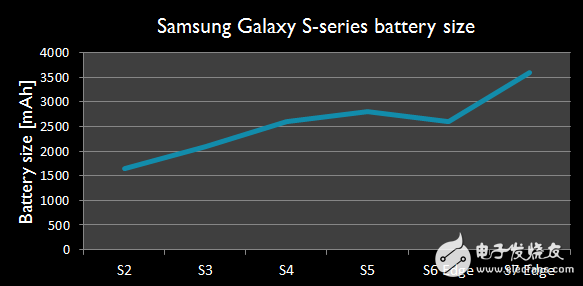
除了打电话,现代智能手机还能提供极为丰富的功能,如邮件、社交媒体、导航定位、支付、浏览网页、游戏、拍照和视频等等。用户在期待功能升级的同时,也希望电池寿命不断延长。但是,即便使用当前所有最先进的技术,智能手机的电池容量还是要不断增大,具体变化趋势见下图。
除了电池容量变大,智能手机还变得越来越薄。一些机型的厚度甚至已经达到了7毫米以下,考虑到现代智能手机的技术含量,如此纤薄实在令人惊讶。
这样的发展方向并非完全没有弊端。屏幕增大导致电池尺寸变大,机身变薄,设备散热能力下降,因为屏幕的散热效率不如金属机身。此外,机身变薄后,用以散热的表面积也会减少。现代高端智能手机的性能上限很大程度上被散热能力牵制,如何保证机身内部元器件不因为高温而受损则因此成为另一大挑战。
现代智能手机装有多种耗电发热的核心元件,如摄像头子系统、屏幕、调制解调器、Wi-Fi、非易失性存储器、DRAM和主芯片本身(包括CPU、GPU和其他处理器)。因为总功耗一致,所以其中任何一个元件功耗的减少,都可以增加其他元件可以使用的配额,这也是系统功耗配比由用例决定的原因。
现代GPU非常复杂,严重依赖CPU运行驱动程序,以实现基于软件与应用程序进行交互。多亏了Vulkan这样的现代API,驱动程序的开销下降了,但是CPU依然需要运行驱动程序,所以不能完全避免耗电。由于所有元件功耗预算共享,因此在CPU中使用的、用于GPU交互的功耗就是不能应用于GPU本身的功耗。基于上述原因,降低CPU功耗势在必行,不仅是为GPU发展扫清瓶颈,更是要为尽可能的提高GPU可用功耗铺平道路。
与之类似,在运行复杂3D游戏的现代系统中,GPU会消耗大量DRAM带宽。由于要处理大量数据(上述提及的Lofoten每帧处理600,000个三角),消耗带宽责无旁贷,但DRAM的读写本身就是耗电的过程,也需要占用系统的总功耗预算。减少DRAM带宽可以降低其功耗,并用于其他元件。
现代智能手机的设计和日益复杂的用例对GPU提出了前所未有的挑战。下一章,我们将介绍ARM新一代GPU和GPU架构是如何应对这些挑战的。
为下一代设备打造的Mali-G71
Mali-G71是ARM最新推出的高性能GPU,也是首款基于全新Bifrost架构的GPU,性能和效率都获得显著提升。
Mali-G71是迄今为止ARM性能最高的GPU。为满足现代用例所需性能,着色器核心数量从1扩展至32,帮助芯片制造商根据目标市场自主权衡性能和功耗。出于这个原因,我们认为Mali-G71将在各类应用中将大展拳脚。
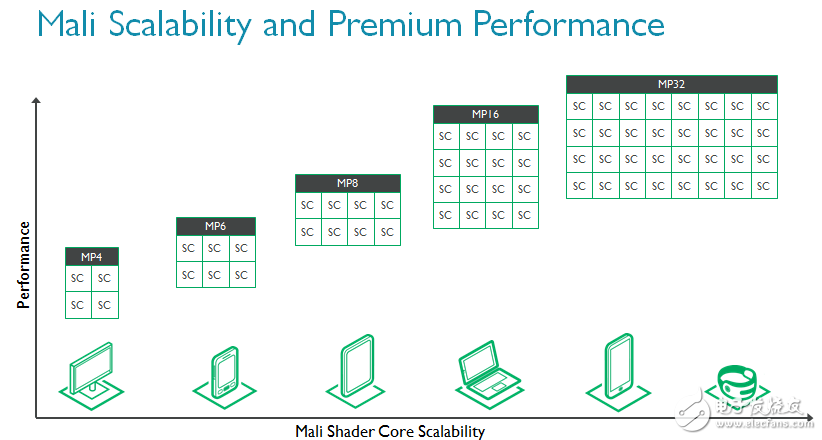
如前文所述,智能手机的很多性能都受到散热的限制,还有一些手机的限制因素则是成本,或者说是芯片尺寸。为了实现更高性,Mali-G71和Bifrost架构同时升级了能源效率(单位瓦特性能)和性能密度(单位芯片面积性能),帮助功耗与散热性能遭遇挑战的芯片制造商实现更高的GPU性能。相似条件下,Mali-G71的能源效率相较Mali-T880最多可提高20%,性能密度最多可提高40%。此外,外部存储消耗的总带宽降低20%,进一步减少整体系统功耗。

Bifrost架构发展
为了进一步说明Mali-G71为何具备远超历代ARM GPU的性能,我们首先来探讨一下GPU架构本身,以及实现这些性能的设计方法。
Bifrost是ARM的第三代可编程的GPU架构,其研发知识与经验传承自Utgard和Midgard GPU架构。
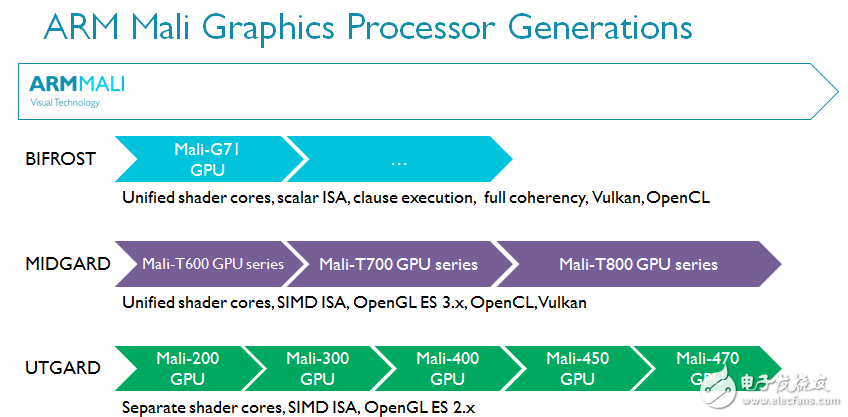
ARM的前两代GPU架构——Utgard和Midgard都取得了巨大成功。它们专为新兴的移动GPU市场打造,无论出货量还是内部科技的运用都可圈可点。Utgard是ARM首款可编程GPU,支持GLES 2.x,片段着色器与顶点着色器相互独立。Midgard则引入了统一着色器,支持GLES 3.x,并可与OpenCL 1.x Full Profile协同实现GPGPU运算。Midgard是一款前瞻性的GPU架构,甚至包括了一些可以支持Vulkan的功能特性。考虑到这是5年前设计的架构,就足以成为了不起的成就。
然而,随着内容和用例的改变,架构本身也必须进行根本性的升级,以适应各类下一代用例。
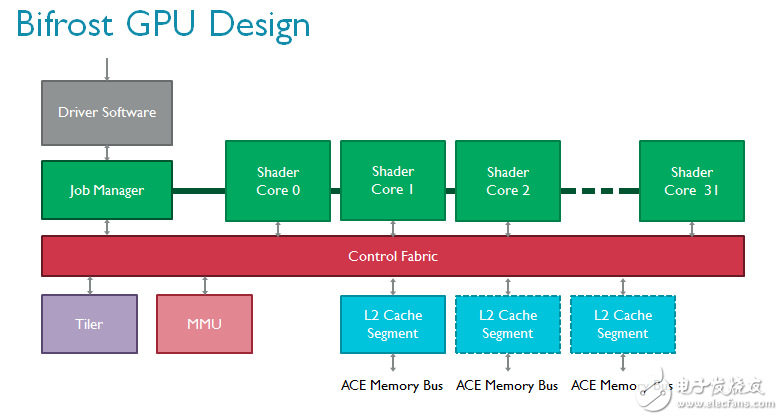
从顶层设计看,与Midgard架构相比,Bifrost的GPU内核没有明显变化。表面上依然包括多个可扩展的着色器核心、一个负责与驱动程序交互的任务管理器、一个负责处理内存页表的MMU以及一个tiler(Bifrost 仍然是一个 Tile based 渲染架构),但全部模块都获得了显著提升。
通过AMBA ACE或AXI-Lite与外界交互的L2子系统为支持AMBA 4 ACE专门设计,帮助Mali-G71彻底实现硬件一致性,并在GPU和CPU等其他单元之间实现了基于硬件的细粒数据透明共享。
我们对tiler做了重新设计,以支持一种全新的渲染流,即索引驱动的位置渲染。该技术的理念是将顶点着色分为两部分以节省带宽,因为无需读写屏幕上看不见的变化参数(varying)1;而且由于无需写回不可见位置,带宽可以得到进一步节省。
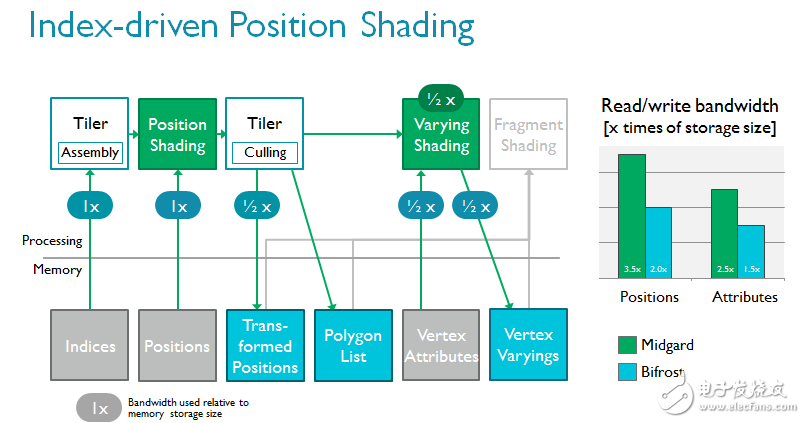
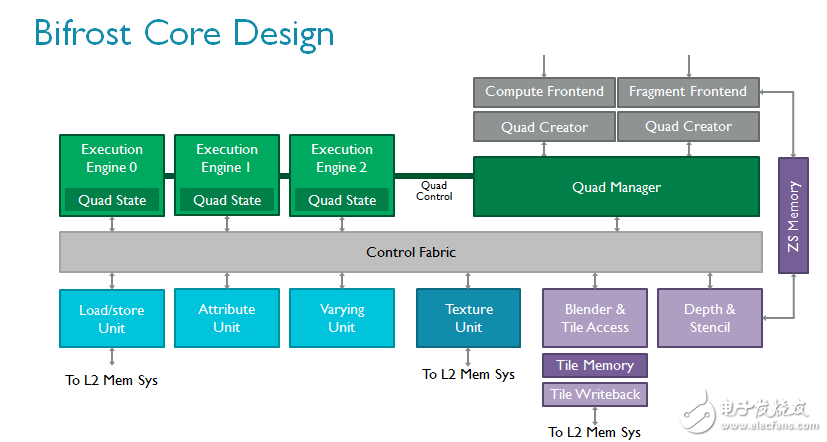
着色器核心本身的变化更为巨大。ARM在Bifrost中引入全新指令集,根据大量的内容和趋势分析以及长年的行业经验开发。现代GPU的总体趋势是执行越来越多的复杂可编程着色器,通常通过算法完成并采用大量标量代码。作为全新引擎的一部分,Bifrost采用全新的算法单元,以极高的效率执行高级着色器核心。它们更容易扩展,如果未来需求有增加,该架构也可以轻松应对。
Bifrost的属性(attribute)单元和变化参数单元相互独立,这些操作在图形处理中极为普遍,使用独立的高度优化硬件模块更为合理。全新的指令集引入高效的四线程组以节省控制逻辑,并通过四线程组管理器将线程组切换至执行引擎。我们还加入了一个控制架构以提高物理利用率。如上文所述,此特性对现代工艺节点非常重要。
Bifrost引入了名为子句着色器的概念,专门用于处理执行引擎内部的布线密度问题。你可以将子句想象成一组连续自动执行的指令,也就是说,一个子句的执行不能被中断,无论是分支(如分支只发生在子句边界上)还是其他任何事件都无法中断。这意味着子句是可以预测的,数据路径周围的控制逻辑变得更容易。比如说,你无需在子句内部更新程序计数器,因为GPU知道它会在执行前(或执行后)根据子句内部的指令数量向前推进。
对CPU而言,这一行为并不可取,因为CPU必须迅速处理分支,而且分支的出现并不偶然。但恰恰相反,对GPU而言,该技术又可以进一步优化设计。请想象一组指令集正在经过。连续的指令经常使用上一条指令作为输入(见下方一排中的多个ADD正在积累数据)。如果你经常观察到这一现象,而且你知道访问暂存器组的代价非常高昂(因为这是一个巨大的存储模块),有一种方法来缓解这个问题,那就是巧妙地使用临时寄存器来减少寄存器组的访问量。由于寄存器是临时的,数据只会在一个时钟周期中保留,所以要想实现,子句必须确保在子句内部原子执行。
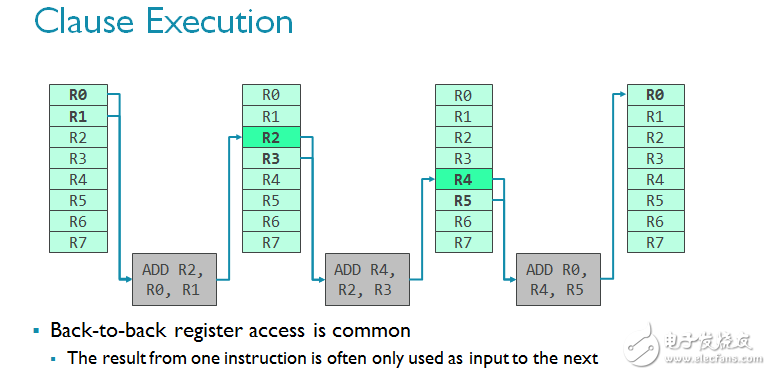
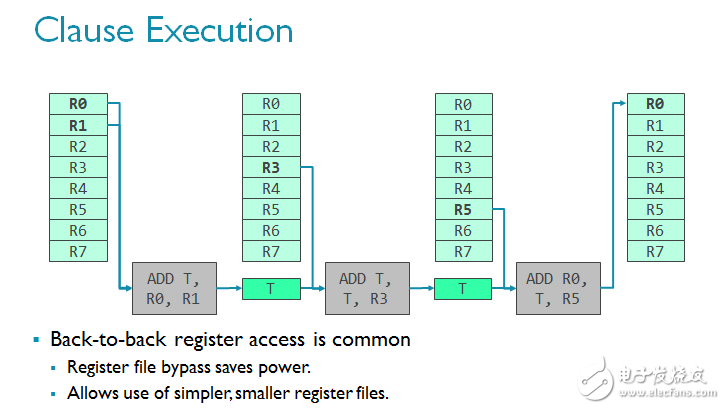
请参考下图的简单着色器程序,从指令集的角度了解子句着色器的工作原理。需要指出的是,这是开发者所看不到的,由编译器完成的。

总结
通过对Bifrost架构如何提高效率和性能的详细解读,我们可以清楚地了解Mali-G71具备哪些根本性的创新技术,以实现万众期待的GPU性能升级。通过支持全新的现代API(如Vulkan和OpenCL 2.0),Mali-G71有助于实现出色的新兴应用场景体验。ARM将继续研发Bifrost架构,满足下一代内容的需求并超越行业期待。2016年,更多新技术将现身ARM Mali 多媒体组件。









 工商网监
工商网监
评论