 电子发烧友App
电子发烧友App


iPhone 8/8p和iPhone X都搭载了苹果自研的A11 Bionic(仿生)芯片。虽然苹果全程并没有在这款芯片上花太多功夫介绍,但我们仍旧知道它集成了一个专用于机器学习的硬件——“神经网络引擎(Neural Engine)”
可别小看了这块A11,通过智东西仔细研究发现,它不仅是iPhone X中一众“黑科技”的来源,而且苹果为了打造这块芯片早在9年前就开始了技术布局。
一、参数亮相,跑分爆表了
在介绍A11里专门用于机器学习的“神经网络引擎”之前,我们先来看看A11的基本参数。
工艺方面,A11采用了台积电10nm FinFET工艺,集成了43亿个晶体管(上一代采用16nm工艺的A10 Fusion集成了33亿个晶体管,华为麒麟970则用10nm工艺集成了55亿个)。
A11搭载了64位ARMv8-A架构的6核CPU,其中包括2个名为“Monsoon”的性能核(performance core)和4个名为“Mistral”的能效核(high-eggiciency core),性能核比上一代A10里的快了25%,能效核则快了70%。
而且,与A10不同,A11中使用了苹果自研的第二代新型性能控制器,允许6个CPU内核同时使用,整体性能比上一代快了70%。
至于为什么分为性能核和能效核呢?当手机进行发短信、浏览网页等轻量任务时,系统会选择调用能耗更低的能效核(high-eggiciency core),而当手机需要运行对计算能力要求更高的软件时,则需要动用性能核(performance core)进行处理,借此可以有效延长平均电池寿命。搭载了A11的iPhone X在充满电后,将会比iPhone 7延长2个小时的待机时间。
A11的另外一大亮点就是首次搭载了苹果自研的GPU,这是一款3核GPU,性能相比A10 Fusion提升30%,只需要一半的功耗就能达到A10的表现。这是今年4月苹果宣布和英国GPU设计公司Imagination Technologies“分手”后推出的首款自研GPU,针对AR、沉浸式3D游戏等方面都进行了优化,比A10快了30%。
A11里还集成了苹果自研的ISP、自研的视频编解码器等等。从种种强调的“自研”我们不难发现,苹果已经越来越强调架构的自主化。在彻底跟老朋友Imagination Technologies分手后(并且导致人家股价断崖式下跌70%后),苹果的下一个自研目标也许会移到基带技术上,与高通旷日持久的专利诉讼案件算得上是前兆了。
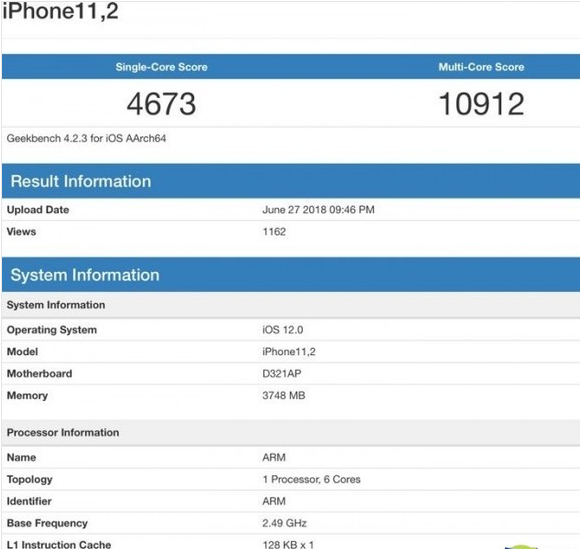
此外,我们也可以从A11在Geekbench的跑分上一窥究竟:在Geekbench中有A11的几个跑分,其中单核性能最高的是4274,多核性能最高的是10438,而取这些跑分平均值后,单核性能是4169,多核性能是9836。
这是什么概念呢?跟上一代A10的“单核成绩3332,多核成绩5558”比起来,A11在两方面的性能有接近30%和50%的飙升。而iPad Pro中的A10X单核性能平均在3900左右,而多核性能是9200左右,依然弱于A11。
而Android阵营的种子选手——高通骁龙835的GeekBench成绩为单核2000左右,多核6500左右。
二、A11就是“人工智能芯片”
这次,苹果在自家的A11 Bionic芯片上搭载了一个专用于机器学习的硬件——“神经网络引擎(neural engine)”。
现在所谓的手机处理器,比如高通的835、苹果的A11、麒麟970等,实际上所指的是一个“处理器包”封装在一起,这个计算包专业一点说叫Soc(System-on-a-Chip),高大上的说法是“计算平台”;根据分工不同,很多专用功能的处理单元加进来,比如我们最熟悉的是GPU,现在这个包里的独立单元数量已经越来越大,比如ISP(图像处理)、Modem(通信模块)、DSP(数字信号处理)等。
不同的数据进来,交给不同特长的计算模块来处理将会得到更好的效果、更高的能效比,A11的神经网络引擎(neural engine)跟麒麟970的NPU一样,是在手机处理器平台新加入的一个擅长神经网络计算的硬件模块。
而这也是为什么从20nm、16nm、到现在的10nm、以及研发中的7nm,各大芯片设计商、代工商都在拼命把芯片技术往小了做,为的就是在不影响芯片大小的前提下挤进更多的独立处理单元。
A11的神经网络引擎采用双核设计,每秒运算次数最高可达6000亿次,相当于0.6TFlops(寒武纪NPU则是1.92TFlops,每秒可以进行19200次浮点运算),以帮助加速人工智能任务,即专门针对Face ID,Animoji和AR应用程序的ASIC(专用集成电路/全定制AI芯片)。
有了神经网络引擎,苹果高级副总裁Phil Schiller很有底气的表示:
“A11 Bionic是一款智能手机到目前为止所能拥有的最强劲、最智能的芯片。而基于ASIC的深度学习,实现了高准确率之外,还能比基于通用芯片(GPU、FPGA)的方案减少功耗。”
不过,苹果对这款神经网络引擎的功耗、实测性能等方面都没有进一步披露。
A11同时也支持Core ML,这是苹果在今年WWDC开发者大会上推出的一款新型机器学习框架,能让开发者更方便地将机器学习技术整合到自己的App中。Core ML支持所有主要的神经网络,如DNN、RNN、CNN等,开发者可以把训练完成的机器学习模型封装进App之中。
三、买买买,买出来的AI帝国
从去2010年开始,苹果就没有停止过收购人工智能创企的步伐,并且每次给出的都是惯常声明:“苹果会不时收购规模较小的科技公司。我们通常不讨论目的或计划。”非常有“事了拂衣去,深藏功与名”的意思。
而且,每个被苹果收购的公司都会立即关闭对外的产品和服务,像是忽然从世界消失一般。
收购芯片厂商
以芯片为例,早在2008年,苹果就以2.78亿美元收购了2003年成立加州的高性能低功耗处理器制造商PA Semi。
随后在2010年,苹果以1.21亿美元收购了1997年成立的美国德州半导体逻辑设计公司Intrinsity,专注于设计较少晶体管、低能耗同时具备高性能的处理器。
2011年年底,苹果又以3900万美元的价格收购了以色列闪存控制器设计公司Anobit。
2013年8月1日,苹果收购了成立于2007年的加州半导体公司Passif Semiconductor,其专长于低功耗无线通讯芯片(大胆地猜测一下Apple Watch的芯片技术是不是来自这里)。
其后的2015年底,苹果再次斥资1820万美元,收购了一间位于加州圣何塞北部的面积7万平方英尺(6500平方米)的芯片制造工厂。这座工厂原属于芯片制造商Maxim Integrated Products,其设施包括了芯片制造工具,而且工厂地址靠近三星半导体公司。
从以上一连串的买买买我们可以看到,苹果的芯片布局早在近十年前就开始了。
除了芯片之外,从2010年至今,苹果已经陆续收购了四五十家创企,包括语音识别、图像/面部识别、计算机视觉、AR、数据挖掘、机器学习、地图、定位等等,而这其中几个比较具备代表性的有:
收购面部识别/表情追踪厂商——Animoji和Face ID的技术来源
2010年,苹果以2900万美元收购瑞典面部识别创企Polar Rose,他们开发的面部识别程序可以可以为用户自动圈出照片中的人脸。
2015年11月,苹果收购《星球大战》背后的动作捕捉技术公司Faceshift,这家苏黎世的创业公司开发了实时追踪人脸表情,然后再用动画表现出来的技术。该技术还可以实现面部识别。
2016年1月,苹果收购了加州AI初创Emollient,该公司使用人工智能技术读取图片中的面部表情。
2017年2月,苹果以200万美元收购了面部识别以色列创企RealFace,该公司开发了一种独特的面部识别技术,其中整合人工智能并将人类的感知带回数字过程。
收购AR引擎巨头
2015年5月,苹果收购AR引擎巨头德国Metaio公司。彼时Metaio与Vuforia并肩称霸AR引擎行业,Metaio拥有约15万名开发者,Vuforia则拥有大约18万,两家的SDK开发者占到了当时整个市场的95%以上,在AR的行业地位有如Windows和Mac OS之于PC。这个收购举措,可以看作是ARkit的技术来源。
收购25年德国老牌眼球追踪企业
而离现在最近的一次收购,就是苹果今年6月时宣布收购德国老牌眼动追踪企业SMI(SensoMotoric Instruments)。其历史要追溯到1991年,SMI从柏林自由大学学术医疗研究院剥离出来,独自成立眼球追踪技术公司,迄今已经有超过25年的发展历史了。产品包括面向企业与研发机构的眼球追踪设备/应用、医疗医疗眼控辅助设备、手机、电脑、VR设备等的眼控技术支持等。
目前,眼球追踪技术已经被集成在了iPhone X里。在用Face ID解锁时,只要你眼睛没有看着屏幕,屏幕也是不会解锁的。
四、用来干啥:Face ID背后的结构光学技术
既然是“人工智能芯片”,当然是用来做人工智能——人脸识别、图像识别、面部表情追踪、语音识别、NLP、SLAM等等。
而A11的神经网络引擎第一个重要的应用就是iPhone X的刷脸解锁——Face ID。
虽然刷脸解锁并不是什么石破天惊的新技术,但是苹果的Face ID解锁跟普通的基于RGB图像的人脸识别解锁不同。寒武纪架构研发总监刘少礼博士说:
“我们这次对苹果A11的AI引擎了解不多,特别是功耗、实测性能等方面苹果发布会基本没有提。个人觉得iPhone X这次最大的亮点是距离传感器,用来支持3D的Face ID,这个功能在业内还是引起了不小震动,后续会给予这功能开发出不少有趣的应用。通过结构光发射器和红外摄像头配合,可以捕捉人脸的深度信息,比之前用2D图像作人脸识别进步了很多。”
根据原理和硬件实现方式的不同,行业内所采用的3D机器视觉主要有三种:结构光、TOF 时间光、双目立体成像。
三种主流的 3D 视觉方案代表性产品
双目立体成像方案软件算法复杂,技术还不成熟;结构光方案技术成熟,功耗低,平面信息分辨率高,但是容易受光照影响,识别距离近;TOF 方案抗干扰性好,识别距离远,但是平面分辨率低,功耗较大。
综合来看,结构光方案更加适合消费电子产品前置近距离摄像,可应用于人脸识别 、手势识别等方面,TOF方案更加适合消费电子产品后置远距离摄像,可应用于 AR、体感交互等方面。
iPhone X的Face ID采用了人工智能加持的结构光方案:数据采集由该机正面上方的景深感知摄像机(即“刘海儿”,TrueDepth Camera System)完成,其红外线发射器可以发射3万个侦测点,利用神经引擎(Neural Engine)将反射回来的数据与储存在A11芯片隔区内的数据进行对比,实现用户面部的3D读取与处理。通过神经网络训练的加持,Face ID失误率仅为百万分之一,远小于Touch ID的五万分之一。
与此同时,iPhone X还具备眼球追踪功能,在你面对屏幕,但是眼睛没有看着它的时候,也是不会解锁的。所以,这样的人脸解锁是照片骗不了的。
而且,苹果的软件工程高级副总裁Craig Federighi曾表示,“我们不会在用户注册Face ID时收集数据,它会保留在你的设备上,不会被发送到云端进行训练。” 符合苹果一贯的“用户隐私为上”理念。
最为神奇的是,用户面容适应(化妆、佩戴眼镜、长胡子、随着年龄增长而变容改变等)过程需要用到的深度学习训练也是在本地完成的。深度学习分为训练(Training)和推理/应用(Inference)两部分,训练阶段所需的计算量比应用阶段的要大上许多。
另一方面,计算与训练的本地化也有助于让Siri变得更加智能。毕竟有不少人认为由于苹果对用户的隐私过于重视,导致Siri发展较慢,竞争对手们后来居上。
此外,在A11的加成下,iPhone X前头“刘海儿”实现的脸部追踪技术还可以用于个人定制化表情Animoji(能捕捉并分析 50 多种不同的肌肉运动)、AR滤镜等,新的互动的方式有望提高用户的参与度和粘性,提高AR社交平台的经济价值。而3D视觉所提供的景深信息和建模能力是现有普通摄像头无法比拟的。
而iPhone X还搭载了全新陀螺仪和加速计,刷新率达到60 fps,可以实现准确的动作追踪以及很好的渲染效果。在发布会上,苹果全球市场营销高级副总裁Phil Schiller是这么说的:“这是第一款真正为AR打造的智能手机。”
五、火热的AI芯片产业
当前人工智能芯片主要分为GPU、ASIC、FPGA。代表分别为NVIDIA Tesla系列GPU、Google的TPU、Xilinx的FPGA。此外,Intel还推出了融核芯片Xeon Phi,适用于包括深度学习在内的高性能计算,但目前根据公开消息来看在深度学习方面业内较少使用。
其中,苹果的A11、寒武纪的A1、谷歌的TPU等都属于ASIC,也就是专用集成电路。
ASIC(Application Specific Integrated Circuit)。顾名思义,ASIC就是根据特定的需求而专门设计并制造出的芯片,能够优化芯片架构,针对性的提出神经网络计算处理的指令集,因而在处理特定任务时,其性能、功耗等方面的表现优于 CPU、GPU 和 FPGA;但ASIC算法框架尚未统一,因此并未成为目前主流的解决方案。
如何评价苹果A11处理器?
CPU:
发布会前,当4000/10000左右的GB4跑分泄露的时候,我既觉情理之中,又觉出乎意料。情理之中的是在移动SoC的晶体管开销的限制下,Apple也已经摸到了单核性能的天花板,算一下会发现,A11和A10X单核的同频性能是几乎一样的,已经没多少手脚可以动了。意料之外的是,2big+4LITTLE的配比,居然能跑到上万分。当时抱着手上的A10X酸酸地发了一下呆,之后我汗毛突然竖了起来。为什么?因为这意味着Apple很有可能在A11上使用了全新设计的Cache Coherent总线,使得大小核可以同时工作,并且衰减很低。之前一直觉得要是Ax开始堆核了,友商的ARM们怕是会很难受。3个月前在A10X上出现的时候,还觉得果然很遥远,现在突然啪的一下产品就放在眼前了,速度之快令人咋舌。
从X光扫描图可以看到,在台积电10nm FFT的制程下,A11整体面积相对A10减小了30%,CPU部分也减小了30%,内存控制器减小了40%。但占用整个芯片的面积比例几乎没有发生变化,CPU只占了大约15%的面积,内存控制器占用了8%的面积。也就是说,光在CPU核心上,A11就比A10多了将近30%的晶体管(这远不是多出来的2个小核可以达到的)。而在CPU性能上,A11与A10X对比是更加科学的,因为二者有着更加接近的频率以及同样的缓存结构。稍微算一下,我们能发现A11比A10X同频单核心能提升了大约6%,可能是架构微调带来的性能提升。在如此大的多核调度改进的同时,能稳步优化微架构,Apple也算是(比Intel)良心了。
GPU:
想起4月份Apple在挖空了PowerVR的人后宣布以后将不依赖PowerVR使用自主设计的GPU时,PVR股价大跌的惨状。这到底是Apple挖墙脚搞技术垄断,还是持着8%的股份不甘寂寞自导自演准备收购PVR,我们时至今日仍然不清楚Apple酒里卖的什么葫芦。我们只知道,当时说好的“Within the next two years”怎么过了半年就出来了?这个研发效率和实力,我只能说,还有这种骚操作?不过从硬件本身的性能上来说,在Mali,Adreno的ALU,API都动不了都没法继续往上堆的时候,Apple的GPU也显得保守,30%的提升似乎可以全部归功于10nm制程。从扫描图中可以看出来,A11的GPU面积相对于A10减少了40% (比Adreno540大了将近80%),也就是说从晶体管数量上看,二者区别不大。而再仔细瞧一眼,这个声称三核的自主核心,其实还是一个6核心的架构,Chipworks也认为跟A10的整体结构区别不大。那么我们能不能推测,Apple提到的30%的性能提升,只来自于10nm制程带来的频率提升(可能要达到1100MHz以上)和Metal2带来的进一步针对性优化呢?还需要时间来验证。
Connection:
A11的配套基有两个型号,第一是在非CDMA地区使用的英特尔XMM7480(PMB9948)配合英特尔双PMB5757射频IC,最高Cat.15 4CA 800Mbps,官方的Product Brief如下:https://www.intel.com/content/dam/www/public/us/en/documents/platform-briefs/xmm-7480-brief.pdf
第二个是我们喜闻乐见的支持全网通的高通基带X16 (MDM9655)配合高通单WTR5975射频IC,最高支持Cat.16 4CA 1Gbps。
明明有14nm的Gigabite Modern XMM7560却赶不上,只能说相当遗憾。也许这是iPhone团队内够用党的又一次胜利,也许这是亦敌亦友的Intel拖后腿的无奈之举,毕竟连XMM7480都几乎不能如期交货。
此外,A11还配套博通的BCM4361——首款支持BT5.0的通讯SoC,与三星S8属于同款。因此A11搭载的机型支持BT5.0与2×2 MIMO WiFi,使得在无线连接性上能与骁龙835和猎户座8895看齐。这点上,华为可能要闭嘴不敢吭声了。
AI Relative:
对于新兴的AI模块/神经处理单元,我也属于小白。现在仅有的两个厂商的硬软件实现思路可能会有比较大的差别,所以目前还没有公认的评估体系去评价一个神经引擎的好与坏,我只能从最基础的晶体管开销,指令效率去大致推测其性能。A11比A10多了10亿晶体管,Kirin970比Kirin960多了15亿晶体管,考虑到4组G7x,我们可以大致说,A11的NE和Kirin970的寒武纪NPU使用了相近数量的晶体管。A11官网给出的是0.6T OPS(估计是FP32),而Kirin970官方给出的是1.92T OPS(未知是否包含了GPU的能力)。A11给出了与970 NPU类似的Neural Engine,搭配了与Zeroth类似的开发平台Core ML用于机器学习,并且在发布会的时候,显摆了一下他们已经做到的程度,如Stage light等特殊滤镜,以及本由大型计算机完成的人脸识别与建模。虽然比起快了25X的寒武纪NPU是逊色了,但是这两家的眼光和实力都是值得肯定的。
ISP/DSP:
4K@60Hz HDR HEVC编码这个是首屈一指的,与8895规格相同,并且还支持240fps@1080P,是现今SoC中FHD慢速摄录的最高规格。而在音频方面,Apple至今还掐着Hi-res不肯支持也是首屈一指的。A11硬件本身配套的Codec对音频的支持到了什么程度呢?我们看到iFixit的iPhone X拆解图中,赫然出现了双晶振,并且上面就是老牌音频厂家Wolfson (已经被Cirrus收购)的IC,实在是让人浮想联翩,加上iPhone8/X新增了对FLAC的支持,是不是代表着Hi-Res的开放呢?
这两块iPhoneX独占的多出来的小板让X比8Plus多了35%的电路板面积
总结:
A11很强,相当强。待到845,9810等等规格都出来之后,再对比一下这些SoC,将会是一件非常有趣的事。









 工商网监
工商网监
评论