 电子发烧友App
电子发烧友App


毫无悬念地,神经网络和人工智能是目前最炙手可热的科技辞藻,它们应用广泛,在各种你喜欢或者不喜欢的社交平台上助力识别图像,在智能音箱上实现语音识别, 在智能手机里担任数字语音助理,神经网络比人类有更好的识别模式能力,这意味着它们现在可以帮助医生识别癌症,帮助农民提升产量,并在人流中识别特定人物,不久,它们会很快应用到注入安全摄像头这样的嵌入式设备中,并且通过脸部识别来解锁手机,这样的手机未来会越来越多。
然而训练神经网络需要强大的硬件,同时耗费大量的时间。此外在云端强大的服务器上运行的应用不能简单的就移植到移动设备上来,因为它们在计算能力和电池方面有限制。
幸运的是,在训练一个神经网络,“离线的”和可以实时识别新对象的训练模型(称为“推理”)之间是有区别的,例如,如果一个神经网络设计成用来识别过往的图片,例如一只猫,那么就需要从数千张猫的图像数据库中了解到猫是什么样的。 经过适当的训练,当你给一个有神经网络的设备展示猫先生的图片时,它就能够认出猫,即使它以前没有见过猫,这就是推理。
在PowerVR Series2NX NNA平台上运行的实时推理Demo
因此当电力和电池寿命受限时就如同移动设备,任何创建神经网络应用的工程师都想以这种方式来训练它,尽可能地优化推理阶段,这主要是通过降低计算复杂度和带宽来实现的,同时也可以大大节省功耗。
在今年年初举办的嵌入式视觉会议上,Imagination公司视觉和AI部门的首席研究工程师Paul Brasnett发表了演讲,你可以在EVA网站上查看完整内容,但你可能需要完成注册流程。
那这是如何实现的呢?从本质上讲,优化神经网络其实就是不断剔除冗余,让神经网络简单、易于执行。这与数字图片从未压缩状态转变为格式化如JPG图片一样,在概念上是相似的,如果压缩算法好,那么在图片质量上几乎没有明显区别。从神经网络角度来看,图片的质量等同于推理精度,经过合适的训练,优化后的神经网络在尺寸和复杂度方面都会大大的降低,与此同时还能保证推理操作有较高的精度。
当然并不是所有的网络都是相同的,第一步则是选择应用适合的最好的神经网络模型,毕竟如果不是最合适的,即使再怎么优化也不会帮助我们获得正确结果。
消除,然后减少
假设你有适合自己类型最佳的神经网络模型,优化过程包括两个关键阶段——消除,然后减少。
首先你想降低神经网络操作的次数,然后你想进一步减少各种操作的计算成本。
在任何给定的网络中都有两种类型的数据贯穿整个网络,权重(系数)和“激活”数据在任何时刻都可能被处理,因此我们需要的就是尽可能的消除权重和相关数据的依赖。权重系数表示神经网络在网络中识别特征的重要性,它将一张图片划分为不同的分层。因此如果权重系数被设置为零,那么这条数据通路就可以从卷积网络中去掉,因此神经网络系统就可以运行得更快。类比我们进行的数字图像压缩其实就是删除图像中的冗余信息。
这个消除的处理过程需要使用两项技术:裁剪和正规化,然后降低剩下的计算成本,这也是需要量化操作来实现的。
网络裁剪
裁剪网络的目的是增加权重系数的稀疏程度,我们可以将其看作是移除连接数或者将权重设置为零——最终的效果都是一样的。
为了成功的进行的裁剪,我们有必要从核心功能的角度出来移除对提升精度不显著的权重参数。有两种方法可以解决这个问题,虽然都可以实现相同的效果但是实现方法略有不同。第一种是如果权重的值低于某个阈值那么它将自动被设置为零,从而消除掉。第二种方法是将一小部分权重值设置为零。
这个阶段的关键好处是一旦权重值被设置为零,那么就相当于永远消失了。

然而尽管裁剪是一个好的开始,但是它最终的影响也意味着降低你的任务系统的性能,我们需要做些什么来恢复性能,因此我们增加了额外的训练阶段。
提炼和规范化
把知识从一个网络转移到另一个网络,这是通过“提炼”来完成的,我们有原始的“未压缩的”浮点网络,它已经被训练成用于一个给定任务,我们将它与我们的裁剪的网络进行比较 – 目的是让裁剪网络的“softmax”输出更精准,与原网络想匹配,通过不断的裁剪和训练,提升网络的精度。
我们也可以实现规范化,它可以说是深度神经网络(DNN)训练过程中一项关键工具,它是增加一项约束,是训练后的网络递归到零。
如下图所示,我们可以看到原始的权重参数值,经过L1级规范化和进一步裁剪操作后,在观察下两者之间的对比。
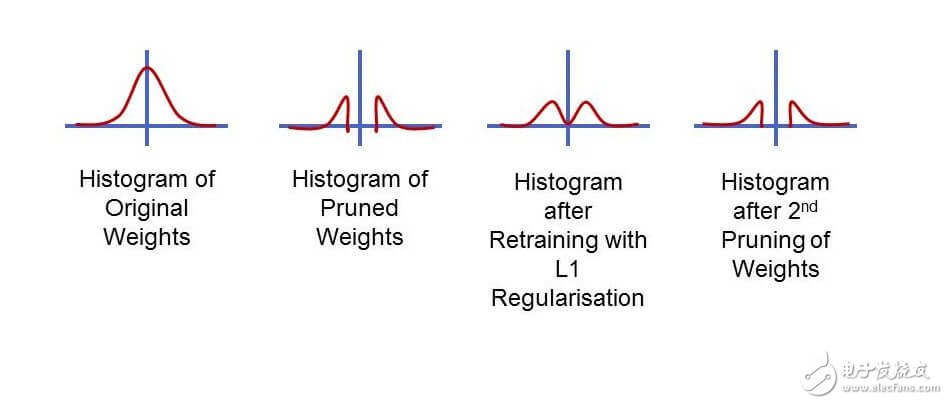
在消除数据和数据相关操作之后,我们如何才能降低这些数据的相关成本呢?
这主要是通过降低每种权重参数的位数来解决的,我们开始采用的是32位全精度浮点数,我们可以自定义设置目标位宽,并重新进行训练,量化处理后会随机返回选择的权重子集。这意味着随着时间的推移,我们将权重值不断的进行量化,使得网络不断的适应这种情形,最终,我们会将权重值固定在最接近的量化值。
我们选择的目标位宽比32位要少,这样会明显降低每个推理操作的功耗,尤其如果你降低到4位,那么选择的硬件平台都会支持。
例如,我们最近推出了PowerVR Series2NX NNA,支持这种精简的位宽,可以设置为4位甚至是不规则的5位,这区别于传统的DSP和神经网络加速器。我们要注意到在神经网络加速器系统中数据是被打包和优化后存储在内存中的,虽然内部管道是高精度的,但是在每个处理分层上它也是支持可变的数据位宽,因此你可以真正的进行优化训练实现最大的效率和精确度。
进行网络训练时,开发者可以选择量化到与权重相同的位宽深度,也可以高于或者低于权重的活跃精度,激活数据相比权重有更大的位宽明显会带来更好的效果。
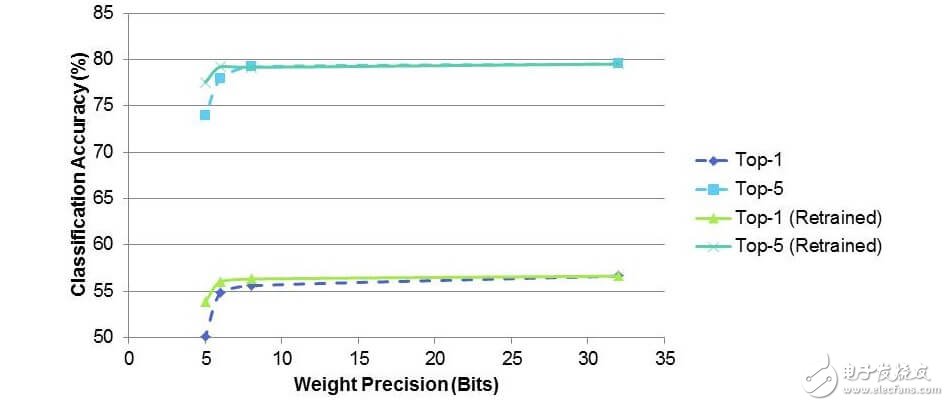
从上图我们可以看出当将稀疏度提升到90%时,在进行训练是非常有效的,能够确保保持前5的分类精度。

然后我们在观察下权重从32位降低到5位的变化过程,下降到8位时虽然没有进行重新训练也并没有带来较多的性能损失,当再继续降低时,如果我们想在嵌入式设备中使用时,那么进行重新训练给带来很大的好处。
总结
从上文我们可以看出,优化神经网络实现高效的推理并不是一件轻松的事情,但从降低带宽和功耗角度来看,它会给我们带来很多好处。PowerVR Series2NX NNA提供的流程工具将复杂的任务进行了精简,提供一步处理过程快速构建神经网络应用原型,然而借助本文提到的优化方法会让我们充分利用选择的硬件平台,这对于移动和嵌入式平台至关重要。
虽然我们可以使用GPU,但是专用的加速器比如Series2NX将能够提供更高数量级性能,这也使其成为目前市场上仅有的神经网络加速器IP。它能够满足未来下一代AI和视觉应用强大的性能需求,而且还可以移植到嵌入式平台完全可以应用到便携设备上。














 工商网监
工商网监
评论