 电子发烧友App
电子发烧友App


针对不同的资源,虚拟化主要包含三个方面的内容:计算虚拟化、存储虚拟化和网络虚拟化,接下来咱们就分别详细介绍这三类资源的虚拟化手段和技术。今天主要聊虚拟化中的“计算虚拟化”,也就是主要针对 CPU 的虚拟化。
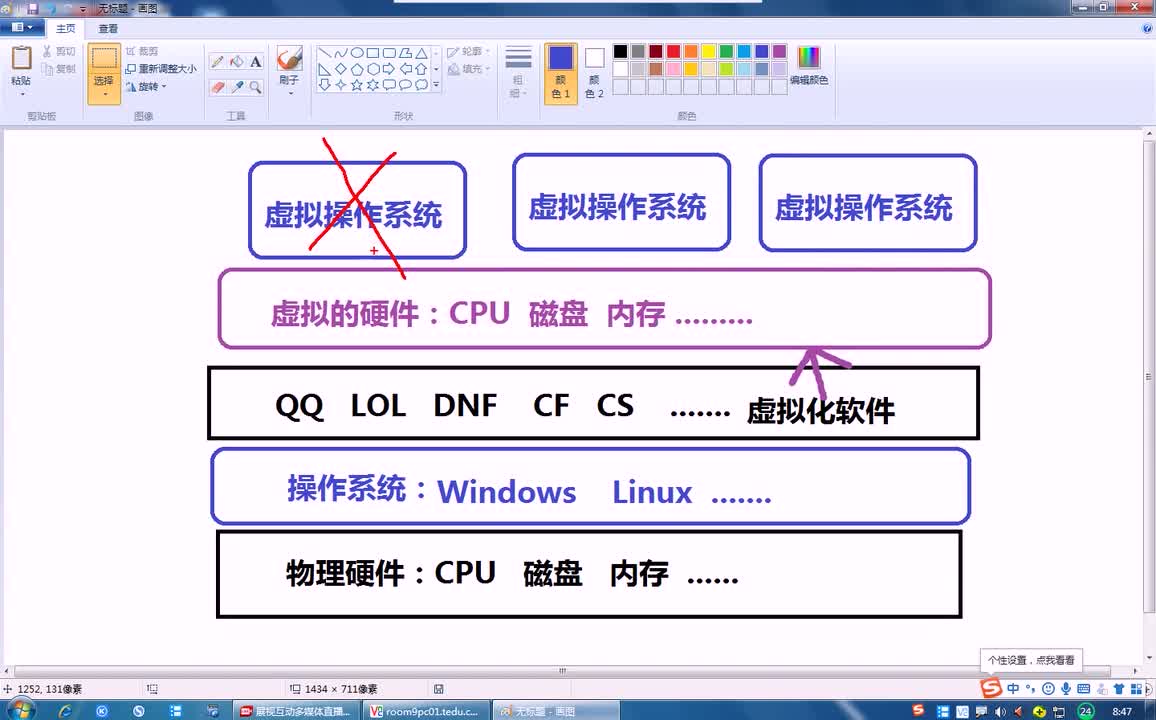
1. 计算虚拟化
计算虚拟化通常包括三方面的内容
(1)CPU虚拟化:由于多个 VM 共享 CPU 资源,需要对 VM 中的敏感指令进行截获并模拟执行。
(2)内存虚拟化:由于多个 VM 共享同一物理内存,需要相互隔离
(3)I/O虚拟化:由于多个 VM 共享一个物理设备,如磁盘、网卡,一般借用 TDMA 的思想,通过分时多路技术进行复用。
CPU虚拟化简介
对于 X86 处理器来说,CPU 虚拟化的基础是因为其保护模式下一共有 4 个不同优先级,分别从 Ring 0 直到 Ring3。这些 Ring 的优先级随其所执行功能的不同也有所不同。其中Ring 0 用于操作系统内核和驱动,优先级最高,拥有最高的“特权”,Ring 1 和 Ring 2 用于操作系统服务,优先级次之,Ring 3 用于应用程序,优先级最低。一般应用程序都放在 Ring 3 等级,至于 Ring 1 和 2 则很少被使用。对于应用程序与 OS 发出的命令要求,CPU 一律采取 Direct Execution,如下图所示:
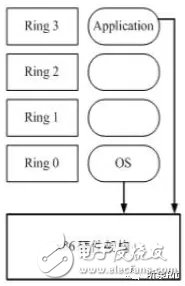
如果要进行虚拟化,Ring 0 这一层就必须交给 VMM来掌控,进行硬件资源的分配处理。
那么问题来了,由于 OS 一定要在 Ring 0 进行访问,直接控制硬件,而现在 Ring 0 的部分已经交给 VMM,操作系统则被调降到 Ring 1,但是由于 X86 CPU 最初定位为单个用户使用,当时并没有考虑到将计算资源分配给不同 OS 的问题;而且 X86 的指令集架构(即ISA,是处理器的一个抽象描述,即设计规范,定义处理器能够做什么。其本质就是一系列的指令集综合。当前主流的 ISA 有 X86、ARM、MIPS、Power 等,这里我们仅讲 X86 ISA)中有 19 条敏感指令不是特权指令,这些指令必须要在 Ring 0 这个层级才能作用,否则操作系统将会产生警告、终止掉应用程序甚至导致系统崩溃。
于是,经过研究,我们的攻城狮们提出以下三种方法来解决这个问题。
(1)全虚拟化(Full Virtualization)
这一方法最初由 VMware 在 1999 年提出,这是一种叫做二进制翻译(Binary Translation)的技术,原理是通过 VMM 来预先拦截这些 OS 当中原本不能被虚拟化的命令(nonvirtualizable instructions),并将其进行二进制转译的替换操作,使操作系统认为自己可以直接掌控硬件,并不知道实际上已经被虚拟化成为虚拟机了。如下图所示:
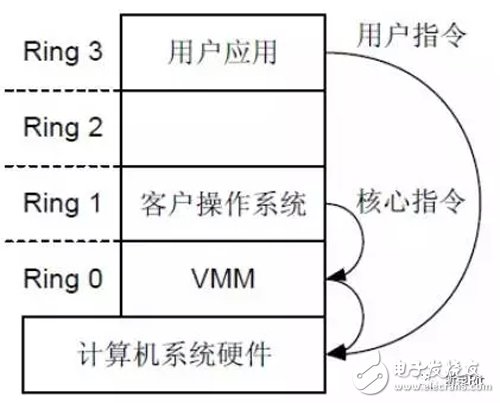
而应用程序一般性的命令则还是直接向硬件请求,以维持良好的性能。
全虚拟化的好处是 OS 不必做任何修改,直接安装即可使用。而且所支持的 OS 种类也最多,但若不靠硬件辅助(Hardware Assisted Virtualization),全虚拟化的实现难度是非常大。
(2)半虚拟化( ParaVirtualization)
半虚拟化的原理是修改 Guest OS 核心中部分代码,植入了 Hypercall(超级调用),从而使 Guest OS 会将和特权指令相关的操作都转换为发给 VMM 的 Hypercall(超级调用),由 VMM 继续进行处理。而 Hypercall 支持的批处理和异步这两种优化方式,使得通过Hypercall 能得到近似于物理机的速度。
这样就能让原本不能被虚拟化的命令(nonvirtualizable instructions)可以经过 Hypercall interfaces 直接向硬件提出请求,Guest OS 的部分还是一样在Ring 0,不用被调降到 Ring 1。如下图所示:
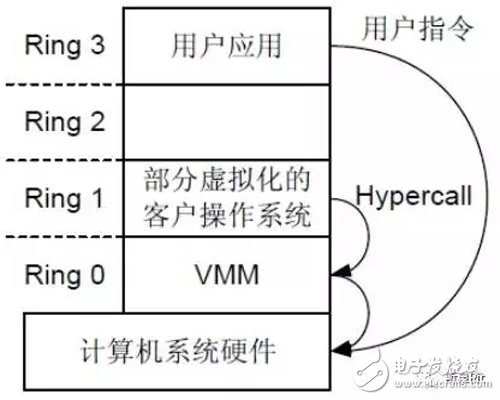
半虚拟化的优点是 CPU、I/O 损耗减到最低,理论上性能胜过全虚拟化技术,缺点则是必须要修改 OS 内核才行,只有 SuSE、Ubuntu 等少数 Linux 版本才支持,OS 兼容性不佳,因为微软不肯修改自家的操作系统内核,因此如果是 Windows 系统,就无法使用半虚拟化了。
VMware 在 2005 年发表了透明半虚拟化(Transparent Paravirtualization),针对支持半虚拟化的 OS 可以在 VMware 的平台通过 VMI(Virtual Machine Interface)打开半虚拟化来增加 I/O 性能,降低CPU 的使用率。
其原理是在支持半虚拟化的 Guest OS 上面由 VMware tools 开一道后门,与 VMM 进行沟通,然后在 OS 上安装半虚拟优化驱动程序,以提高 I/O 性能,降低 CPU 使用率。这是一种在 VMware 平台上可以支持半虚拟化 OS 的最佳方式,但是必须要注意的是,底层 CPU Virtualization 仍然是使用二进制转换(Binary Translation)的全虚拟化技术(Full Virtualization),而不是半虚拟化技术。
(3)CPU 硬件辅助虚拟化( Hardware Assisted Virtualization)
2005 年后,虚拟化渐渐成为潮流,势不可挡。Intel 与 AMD 决定从 CPU 根本架构着手,更改原来的特权等级 Ring 0、1、2、3,将之归类为 Non-Root mode,又新增了一个 Root Mode 特权等级(有人称为Ring -1),这样一来,OS 便可以在原来Ring 0 的等级,而VMM 则调整到更底层的 Root Mode 等级。如下图所示:
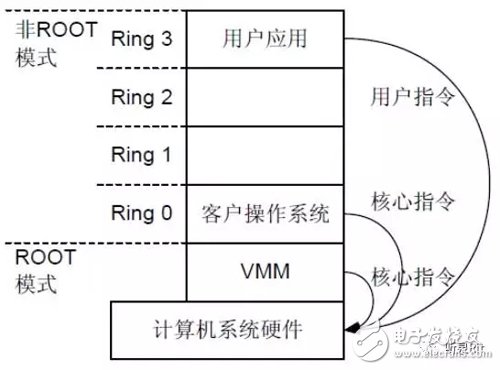
目前主要有 Intel 的 VT-x 和 AMD 的 AMD-V 这两种技术。其核心思想都是通过引入新的指令和运行模式,使 VMM 和 Guest OS 分别运行在不同模式(ROOT 模式和非 ROOT 模式)下,且 Guest OS 运行在 Ring 0 下。通常情况下,Guest OS 的核心指令可以直接下达到计算机系统硬件执行,而不需要经过 VMM。当 Guest OS 执行到特殊指令的时候,系统会切换到 VMM,让 VMM 来处理特殊指令。
硬件辅助虚拟化扩展话题
在硬件辅助虚拟化中,虚拟机的指令集直接运行在宿主机物理 CPU 上,当虚拟机中的指令设计到 I/O 操作或者一些特殊指令的时候,控制权转让给了宿主机(这里其实是转让给了 VMM),也就是一个进程,它在宿主机上的表现形式也就是一个用户级进程。
下图以 KVM 为例。
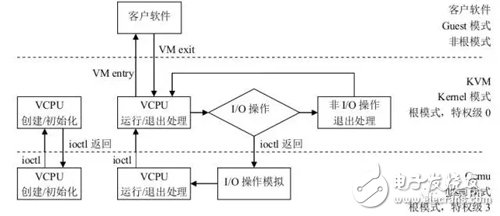
从上图可以比较直观的看到,VMM 完成 vCPU 和内存的初始化后,通过 ioctl 调用 KVM 的接口,完成虚拟机的创建,并创建一个线程来运行 VM,由于 VM 在前期初始化的时候会设置各种寄存器来帮助 KVM 查找到需要加载的指令的入口(main 函数)。所以线程在调用了 KVM 接口后,物理 CPU 的控制权就交给了 VM。VM 运行在 VMX non-root 模式,这是 Intel 的 VT-x 提供的一种特殊的 CPU 执行模式。然后当 VM 执行了特殊指令的时候,CPU 将当前 VM 的上下文保存到 VMCS 寄存器(这个寄存器是一个指针,保存了实际的上下文地址),然后执行权切换到 VMM。VMM 获取 VM 返回原因,并做处理。如果是 I/O 请求,VMM 可以直接读取 VM 的内存并将 I/O 操作模拟出来,然后再调用 VMRESUME 指令,VM 继续执行,此时在 VM 看来,I/O 操作的指令被 CPU 执行了。
下面我们仅针对 VT-x 的一些重点概念展开谈一下。
(1)两种模式
VT-x 为 IA 32 处理器增加了两种操作模式:VMX root operation 和 VMX non-root operation。
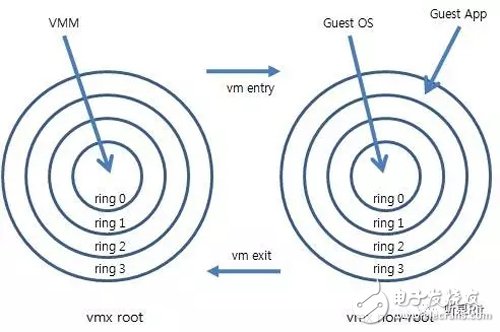
VMM 自己运行在 VMX root operation 模式,VMX non-root operation 模式则由 Guest OS 使用。两种操作模式都支持 Ring 0 ~ Ring 3 这 4 个特权级,因此 VMM 和 Guest OS 都可以自由选择它们所期望的运行级别。
(2)模式转换 VM entry,运行 Guest OS
这两种操作模式可以互相转换。运行在 VMX root operation 模式下的 VMM 通过显式调用 VMLAUNCH 或 VMRESUME 指令切换到 VMX non-root operation 模式,硬件自动加载 Guest OS 的上下文,于是 Guest OS 获得运行,这种转换称为 VM entry。
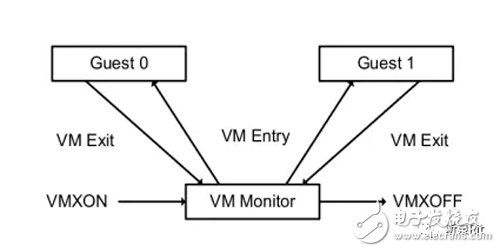
(3)模式转换 VM exit,运行 VMM
Guest OS 运行过程中遇到需要 VMM 处理的事件,例如外部中断或缺页异常,或者主动调用 VMCALL 指令调用 VMM 的服务的时候(与系统调用类似),硬件自动挂起 Guest OS,切换到 VMX root operation 模式,恢复 VMM 的运行,这种转换称为 VM exit。
VMX root operation 模式下,软件的行为与在没有 VT-x 技术的处理器上的行为基本一致;而 VMX non-root operation 模式则有很大不同,最主要的区别是此时运行某些指令或遇到某些事件时,发生 VM exit。
(4) VMM 的生命周期
VMM 开始于 VMXON 指令,结束与 VMXOFF 指令。
第一次启动 Guest,通过 VMLAUNCH 指令加载 Guest,这时候一切都是新的,比如说起始的 rip 寄存器等。后续 Guest exit 后再 entry,是通过 VMRESUME 指令,此指令会将VMCS(后面会介绍到)所指向的内容加载到当前 Guest 的上下文,以便 Guest 继续执行。
(5)虚拟机控制块 VMCS(Virtual-Machine control structure)
VMCS 是一个 64 位的指针,指向一个真实的内存地址,VMCS 是以 vCPU 为单位的,就是说当前有多少个 vCPU,就有多少个 VMCS 指针。
VMM 和 Guest OS 共享底层的处理器资源,因此硬件需要一个物理内存区域来自动保存或恢复彼此执行的上下文。这个区域称为虚拟机控制块(VMCS),包括客户机状态区(Guest State Area),主机状态区(Host State Area)和执行控制区。
VM entry 时,硬件自动从客户机状态区加载 Guest OS 的上下文。并不需要保存 VMM 的上下文,原因与中断处理程序类似,因为 VMM 如果开始运行,就不会受到 Guest OS的干扰,只有 VMM 将工作彻底处理完毕才可能自行切换到 Guest OS。而 VMM 的下次运行必然是处理一个新的事件,因此每次 VMM entry 时, VMM 都从一个通用事件处理函数开始执行;
VM exit 时,硬件自动将 Guest OS 的上下文保存在客户机状态区,从主机状态区中加载 VMM 的通用事件处理函数的地址,VMM 开始执行。而执行控制区存放的则是可以操控 VM entry 和 exit 的标志位,例如标记哪些事件可以导致 VM exit,VM entry 时准备自动给 Guest OS “塞”入哪种中断等等。
(6)VMCS 中的客户机状态区和主机状态区
客户机状态区和主机状态区都应该包含部分物理寄存器的信息,例如控制寄存器 CR0,CR3,CR4;ESP(ESP 寄存器里存储的是在调用函数 fun() 之后,栈的栈顶。并且始终指向栈顶,还有一个 EBP 寄存器,存储的是栈的栈底指针,通常叫栈基址,这个是一开始进行 fun() 函数调用之前,由 ESP 传递给 EBP 的) 和 EIP(EIP寄存器里存储的是 CPU 下次要执行的指令的地址)(如果处理器支持 64 位扩展,则为 RSP,RIP);CS,SS,DS,ES,FS,GS 等段寄存器及其描述项;TR,GDTR,IDTR 寄存器;IA32_SYSENTER_CS,IA32_SYSENTER_ESP,IA32_SYSENTER_EIP 和 IA32_PERF_GLOBAL_CTRL 等 MSR 寄存器。
客户机状态区并不包括通用寄存器的内容,VMM 自行决定是否在 VM exit 的时候保存它们,从而提高了系统性能。客户机状态区还包括非物理寄存器的内容,比如一个 32 位的 Active State 值表明 Guest OS 执行时处理器所处的活跃状态,如果正常执行指令就是处于 Active 状态,如果触发了三重故障(Triple Fault)或其它严重错误就处于 Shutdown 状态,等等。
前文已经提过,执行控制区用于存放可以操控 VM entry 和 VM exit 的标志位,包括:
External-interrupt exiting:用于设置是否外部中断可以触发 VM exit,而不论 Guest OS 是否屏蔽了中断。
(7)Interrupt-window exiting:
如果设置,当 Guest OS 解除中断屏蔽时,触发 VM exit。
(8)Use TPR shadow:
通过 CR8 访问 Task Priority Register(TPR 任务优先级寄存器)的时候,使用 VMCS 中的影子 TPR,可以避免触发 VM exit。同时执行控制区还有一个 TPR 阈值的设置,只有当 Guest OS 设置的 TR 值小于该阈值时,才触发 VM exit。
(9)CR masks and shadows:
每个控制寄存器的每一位都有对应的掩码,控制 Guest OS 是否可以直接写相应的位,或是触发 VM exit。同时 VMCS 中包括影子控制寄存器,Guest OS 读取控制寄存器时,硬件将影子控制寄存器的值返回给 Guest OS。
(10)位图 bitmap:
VMCS 还包括一组位图以提供更好的适应性:
Exception bitmap:选择哪些异常可以触发 VM exit,
I/O bitmap:对哪些 16 位的 I/O 端口的访问触发 VM exit。
MSR bitmaps:与控制寄存器掩码相似,每个 MSR 寄存器都有一组“读”的位图掩码和一组“写”的位图掩码。
每次发生 VM exit 时,硬件自动在 VMCS 中存入丰富的信息,方便 VMM 甄别事件的种类和原因。VM entry 时,VMM 可以方便地为 Guest OS 注入事件(中断和异常),因为 VMCS 中存有 Guest OS 的中断描述表(IDT)的地址,因此硬件能够自动地调用 Guest OS 的处理程序。
硬件辅助技术的出现,使得 VMM 和 Guest OS 的执行通过硬件,自动隔离开来,任何关键的事件都可以将系统控制权自动转移到 VMM,因此 VMM 能够完全控制系统的全部资源。
Guest OS 不但可以运行在它所期望的最高特权级别,因此特权级压缩和特权级别名的问题迎刃而解,而且 Guest OS 中的系统调用也不会触发 VM exit。
硬件使用物理地址访问虚拟机控制块(VMCS),而 VMCS 保存了 VMM 和 Guest OS 各自的 IDTR 和 CR3 寄存器,因此 VMM 可以拥有独立的地址空间,Guest OS 能够完全控制自己的地址空间,地址空间压缩的问题也不存在了。
中断和异常虚拟化的问题也得到了很好的解决。VMM 只用简单地设置需要转发的虚拟中断或异常,在 VM entry 时,硬件自动调用 Guest OS 的中断和异常处理程序,大大简化 VMM 的设计。同时,Guest OS 对中断的屏蔽及解除可以不触发 VM exit,从而提高了性能。而且 VMM 还可以设置当 Guest OS 解除中断屏蔽时触发 VM exit,因此能够及时地转发积累的虚拟中断和异常。
CPU 硬件辅助虚拟化其实又分成初代和二代,二代新增了 MMU(memory management unit)虚拟化,也就是 Intel EPT 和 AMD RVI,如果各位小伙伴有兴趣,可以登录到
VMware、Citrix、Intel 与 AMD 网站查询更详细的相关信息。
有了 CPU 硬件支持虚拟化技术之后,最大的好处就是不再需要以前 BinaryTranslation 或ParaVirtualization 的操作,虚拟化厂商再也不用费心在这里想办法解决问题,全虚拟化厂商的性能追上了半虚拟化厂商,半虚拟化厂商也可支持不修改内核的操作系统了(例如Windows 或绝大多数的 Linux )。
CPU 虚拟化可以说是计算虚拟化最关键的核心,弄清楚了 VM Exit 和 VM Entry。后续的I/O 虚拟化,内存虚拟化都是建立在这个基础上。

























 工商网监
工商网监
评论