 电子发烧友App
电子发烧友App


众所周知,汇编语言具有更高的性能优势,而用C语言编码则能更容易和快速地实现。DSP处理器功能的不断增强以及编译器优化技术的提高,使得传统的用汇编语言编写DSP应用程序的做法逐渐被淘汰。现在的DSP应用程序几乎都是由C代码和汇编代码混合组成的。在那些对性能起决定性作用的关键功能中,DSP工程师将继续使用高度优化的汇编代码,同时转用C语言编写那些不太关键的功能,这将有利于代码维护和移植。而C和汇编代码的这种结合要求DSP工程师具备专门的工具和方法。
正确混合C代码和汇编代码
问题是在哪里划分C代码和汇编代码的界限。这取决于跟踪器(profiler)所能提供的性能分析结果。然而在使用跟踪器之前,DSP工程师需要为应用程序定义清晰的目标,这些目标一般包括循环数、代码规模和数据量。目标一旦确定后,应该先全部用C语言编写和创建应用程序,然后才使用跟踪器来分析性能。
在某些特定情况下,主要是控制应用中,C语言级的编码就足够了。但在大多数情况下,初始编写的C语言应用程序是不能满足一个或更多目标要求的。这通常意味着多少需要一些汇编代码。在求助于汇编编程之前,强烈建议保存原始的C代码。这样不仅方便调试,而且当条件成熟(比如采用更强大的平台),还可以返回到这些C语言的实现。
汇编部分代码应尽可能少。为此,工程师需要认真分析跟踪器提供的性能结果,并确定应用程序中的关键函数。关键函数是指占用大部分执行时间,而必须用汇编语言重写才能满足性能目标的那些函数。重写其中的几个关键函数后,需要重新进行性能分析。如果仍达不到目标要求,那就应该确定其它关键函数,再进行重写。图1显示了利用专用硬件机制获得高度优化的汇编代码。

图1:用C语言创建的循环缓冲器代码(左)以及由CEVA-teakLite-III创建的等效汇编代码(右)。
对编译器的考虑事项
在编写需要与C代码结合的汇编代码时,汇编编程人员必须了解编译器的约定和假设。汇编编程人员还必须了解编译器的寄存器使用约定。通常,寄存器使用约定将硬件寄存器分成被调用方保存(或调用方使用)和被调用方使用(或调用方保存)寄存器。图2给出了从CEVA-X1641 DSP内核FFT实现中摘取的汇编代码例子。左边第二行的add指令符合CEVA-X1641编译器传递r0地址寄存器中指针参数的调用约定。右边的pushd指令用于备份后面函数会用到的被调用方保存寄存器。

图2:从CEVA-X1641 DSP内核的FFT实现中摘取的一段汇编代码。
除了调用约定和寄存器使用约定外,一些编译器在人工编写的汇编代码方面可能还会有一些额外的假设。这些假设通常是专门针对某个编译器的,因此编译器提供商会提供完善的资料和说明。
用于C和汇编连接的常用C语言扩展
用于嵌入式平台的大多数编译器,特别是用于DSP编程的编译器,都具有丰富的C语言和汇编语言连接功能。其中绝大部分功能不属于标准C语言,因此被称为C语言扩展。下面列出的是其中有益于DSP编程的一些功能。
内联汇编(inline assembly):该功能可以帮助编程人员将汇编指令插入C代码。
硬件寄存器绑定C变量:该功能经常与汇编指令内联功能结合在一起,帮助内联汇编代码访问C语言级的变量(见图3)。

图3:结合内联汇编和硬件寄存器绑定功能的代码示例。
存储区属性:该功能允许编程人员将上述变量和函数分配到独特的用户定义存储区,可以让编程人员将C语言级单元分配到实际的存储器位置,这对DSP应用来说非常关键。
用户定义的调用约定:在某些情况下,汇编函数可以通过用户定义的调用约定取得更好的优化效果。编译器内部函数(Compiler intrinsics):是指能够使用专门的宏或函数调用触发的内建编译器功能总称。没有内部函数支持的编译器必须调用用户定义的函数,这样做可能会令用户定义函数可能会在一个环路里产生函数调用和返回(见图4),从而产生巨大的开销。

图4:ETSI的mult_r(乘法和取整)基本操作的C代码实现(左)和对应的由CEVA-TeakLite-III编译器生成的汇编代码(右)。
汇编内部函数:是将汇编代码内联进C代码的一种先进方法,下文将有详细介绍。
把汇编指令当作C语句一样来编写
内联汇编功能具有显著的缺点。它会破坏各种编译器优化操作,因为编译器不了解内联代码的内容,会使用最坏假设;以及它可能迫使编程人员处理底层问题,如寄存器分配和指令调度。
汇编内部函数可以帮助编程人员实现内联汇编代码,并且不存在这些缺点。从编程人员的角度看,汇编内部函数就像是C语言宏或函数。它们接收C语言变量,返回C语言输出结果,同时表现为单个汇编指令。由于涉及该功能的所有代码都在C语言等级,因此编程人员不必担心寄存器分配、指令调度和其它底层问题。汇编内部函数不仅不会妨碍编译器优化操作,还会参与优化过程,就像它们是编译器正常产生的汇编指令一样。这些特征使得汇编内部函数的功能非常强大。
利用汇编内部函数,编程人员可以从编译器不可能产生的独特汇编指令中受益。例如,CEVA-X1641的bitrev(位反向)指令就是为FFT等算法定制的。由于编译器不太可能把一个程序看作一个FFT并使用bitrev指令,因此编程人员可以完全把bitrev汇编内部功能嵌入到C代码中。结合对应用的透彻了解,编程人员还可以使用C应用程序的性能决定段里的精确序列汇编内部函数,从而能够确保编译器生成的代码效率就像手工编写的一样高。
图5是CEVA-X1641编译器与汇编内部函数一起使用的例子。汇编内部函数还受益于由CEVA-X1641编译器处理的问题所决定的机器,如寄存器分配、指令调度和硬件单元分配。

图5:CEVA-X1641编译器支持的汇编内部函数的使用。
调试混合代码的应用程序
汇编代码的调试需要对延迟和存储器对齐限制等架构和机器级问题有深入的了解。只是简单地把C代码和汇编代码放在一起会使事情更麻烦,因为编程人员现在还必须调试C代码和汇编代码之间的连接。
调试混合代码应用程序的第一步就是分隔问题。假设保持汇编代码的C语言实现不变以及C语言实现方案工作正常,那么将汇编函数转换成C语言实现并重新测试应用程序就相对比较容易。为了迅速检测出问题,编程人员可以在每一步把受怀疑函数的一半转换为相应的C语言实现方案。
一旦有问题的汇编函数被确定,它就应该同时作为独立的汇编问题和C与汇编的连接问题加以分析。调试独立的汇编问题对汇编编程人员来说十分简单明了,但C与汇编的连接问题就有点麻烦。在考虑汇编函数本身时,C与汇编的连接问题是不可见的,这与独立的汇编问题有所不同。为了找出这些问题,编程人员必须检查编译器的约定,比如调用约定和寄存器使用约定。
编程人员还必须检查编译器假设,比如汇编指令的行踪。为了节省调试时间,编程人员应该在第一次实现汇编函数时验证是否遵循所有的编译器约定和假设。
本文讨论的技术和方法已被CEVA公司用于各种各样的应用,包括视频编解码器、音频编解码器、声音合成器和设备驱动器。而本文所述的功能在这些应用中都可以显著提高性能。H.264视频编码器是一个很好的研究案例。它在处理能力及其它资源方面要求非常严格,尤其是相比语音编解码器等其它类型的编解码器而言。
CEVA公司的CEVA-X16xx高端DSP内核系列及其MM2000多媒体平台可以为这种编码器提供所需的处理能力。先用高级跟踪技术确定这种编码器的关键函数,然后逐步对之进行优化。首先,利用汇编内部函数在C语言级对这些函数进行全面优化。然后,在汇编语言级对编译器提供的汇编代码作进一步优化。
图6展示了通过对这种编码器的关键函数进行全面优化所获得的性能提高。只有最后一个优化阶段涉及到纯汇编编程,所有其它阶段都基于带有汇编内部函数的C代码。这些汇编内部函数主要用于SIMD操作,如avg_acW_acX_acZ_4b。这条指令对8个输入字节取平均,产生4字节结果。这种SIMD操作对执行大量字节级计算的视频编解码器非常有用。
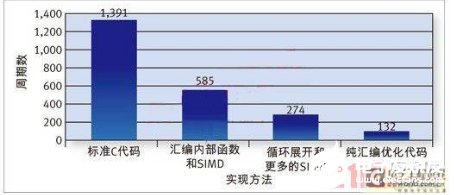
图6:对H.264编码器的关键函数进行优化以提升性能。AMR-NB(自适应多速率-窄带)是广泛用于无线通信应用的语音编解码器。通常都是采用纯汇编来实现声音合成器,但C语言实现与CEVA-X1620编译器利用本文讨论的各种功能可以获得与汇编实现媲美的结果。图7显示了整个AMR-NB应用经过全面优化而取得的以MCPS(每秒百万周期)计的性能提高幅度。只有最后的优化阶段涉及到了纯汇编编程,所有其它阶段都基于带有ETSI内部函数和汇编内部函数等的C代码。
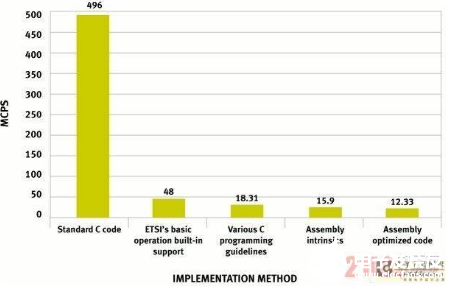
图7:通过各种优化方法取得的ARM-NB性能改进。
总之,H.264编码器和AMR-NB例子清楚地表明了汇编实现方案的性能优势,但也表明纯汇编实现并非首选的优化方法。利用高质量软件开发工具提供的C与汇编功能,DSP编程人员无需纯汇编语言也能使整个应用程序达到令人满意的性能。










 工商网监
工商网监
评论