 电子发烧友App
电子发烧友App


引言
在已有的基于块的视频编解码系统中,当码率较低时都存在方块效应,新的视频编码标准H.264中亦是如此。产生这种方块效应的主要原因有两个:一是由于对变换后的残差系数进行的基于块的整数变换后,以大的量化步长对变换系数进行量化会使得解码后的重建图像的方块边缘出现不连续;二是在运动补偿中插值运算引起的误差使得编解码器反变换后的重建图像会出现方块效应。如果不进行处理,方块效应还会随着重构帧积累下去,从而严重地影响图像的质量和压缩效率。为了解决这一问题,H.264中的去方块滤波技术采用较为复杂的自适应滤波器来有效地去除这种方块效应。因此,如何在实时视频解码中优化去方块滤波算法,降低计算复杂度,提高重建图像质量,就成了H.264解码的一个关键问题。
1、 H.264的去方块滤波
1.1 滤波原理
大的量化步长会造成相对较大的量化误差,这就可能将原来相邻块“接壤”处像素间灰度的连续化变成了“台阶”变化,主观上就有”伪边缘”的方块效应。去方块效应的方法就是在保持图像总能量不变的条件下,把这些台阶状的阶跃灰度变化重新复原成台阶很小或者近似连续的灰度变化,同时还必须尽量减少对真实图像边缘的损伤。
1.2 自适应滤波过程
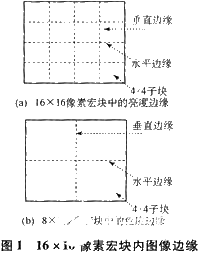
在H.264中,去方块滤波器是按照16×16像素的宏块为单位顺序进行的,在宏块中按照每个4×4子块之间的边缘以先垂直后水平的顺序进行,从而对整个重建图像中的所有边缘(图像边缘除外)进行滤波。具体的边缘示意图如图1所示。对于16×16像素的亮度宏块,共有4条垂直边缘,4条水平边缘,每条边缘又分为16条像素边缘。而对应8×8像素的色度宏块有垂直边缘和水平边缘各2条,每条边缘分为8条像素边缘。像素边缘是进行滤波的基本单元。
1.2.1 滤波器在两个层次上的自适应性
H.264中的去方块滤波所以有较好的滤波效果,是由于它在以下两个层次上的自适应性。
1) 滤波器在4×4子块级别的自适应性
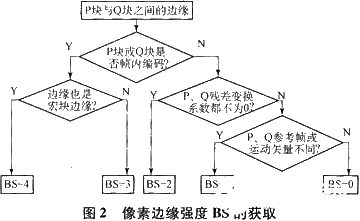
滤波是基于各个子块中的像素边缘进行的,通过对每一条像素边缘定义一个参数BS(边缘强度)来自适应地调节滤波的强弱和涉及的像素点。色度块的像素边缘强度与相应的亮度像素边缘强度相同。假设P和Q为两个相邻的4×4子块,其中的像素边缘强度通过图2的步骤获得。BS的值越大,则对相应的边缘两侧进行的滤波越强,这是根据产生方块效应的原因来设定的,如采用帧内预测模式的子块的方块现象较明显,则对该子块中的对应边缘设定较大的像素边缘强度值来进行强滤波。
2) 滤波器在像素点级别上的白适应性
正确区分由于量化误差、运动补偿产生的虚假边缘和图像中的真实边界才能得到好的滤波效果。通常,真实边界两侧的像素梯度差值要比虚假边界两侧的像素梯度差值大,因此,滤波器通过对边缘两侧像素点的灰度值的梯度差值设定门限α、对同一侧的相邻像素点的灰度值的梯度差值设定门限β来进行真伪边界的判定。α和β的值主要与量化步长有关,当量化步长大时,量化误差也大,方块效应就明显,易产生虚假边界,因此门限值随之变大,放宽滤波条件。反之,量化步长小时门限值也变小,体现了自适应性。采样点的设置见图3。若条件都满足,则进开始滤波。

除了这两种自适应性,还可以通过设置位于片级的系数LoopFilterAlphaC0Offset、LoopFilterBetaOffset来调整滤波的强度。例如当传输码率较低时,方块效应较明显,接收端想要主观质量相对较好的图像,则编码端可通过设置位于片头信息中的滤波偏移量LoopFil-terAlphaC0Offset,LoopFilterBetaOffset为正值,以此增大α和β来加强滤波,通过去除方块效应来提高图像主观质量。或者对于高分辨率的图像,可以通过传送负值偏移来减弱滤波,尽量保持图像的细节。
1.2.2 依据各像素边缘BS值对相邻的像素滤波
若当前像素边缘符合滤波条件,则根据其相应的BS值选取对应的滤波器进行滤波并且进行适当的剪切操作,以防止图像的模糊。
当BS值是1,2,3时,采用一个4抽头的线性滤波器,对输入的P1、P0、Q0、Q1进行滤波调整得到新的Q0、P0,如果内部有虚假边界,则进一步调整Q1、P1的值。
当BS值是4时,则对应的是采用帧内编码模式的宏块边缘,应采用较强的滤波以达到增强图像质量的目的。对于亮度分量,若条件(| P0~Q0 | 《((α》2)+2))&abs(P2-P0)成立,则选择5拙头滤波器对P0、P2进行滤波,使用较强的4抽头滤波器对P1进行滤波;若条件不成立,则只使用较弱的3抽头滤波器对P0进行滤波,而P1、P2的值保持不变。对于色度分量,若上述条件满足,则对P0进行3抽头滤波,若条件不满足,则所有的像素值都不修改。对Q0、Q1、Q2的滤波操作与P0、P1、P2的滤波操作相同。
2、 BF533的特点和结构
我们的H.264去方块滤波是在ADI公司的Blackfin ADSP-BF533处理器上实现的。Blackfin系列DSP主要具有以下特点:
a) 高度并行的计算单元。Blackfin系列DSP体系架构的核心是DAU(数据算术单元),包括2个16位的MAC(乘法累加器)、2个40位的ALU(算术逻辑单元),1个40位单桶形的移位器,4个8位视频ALU。每个MAC能在单一时钟周期内对4个独立的数据操作数执行16位乘16位的乘法运算。40位的ALU可累加2个40位的数字或者4个16位的数字。这种体系架构可灵活地进行8值、16位、32位的数据运算。
b) 动态电源管理。处理器可以通过改变电压和工作频率,消耗比其他DSP更少的功耗。Blackfin系列DSP体系架构的允许电压和频率独立调整,使得每一项任务的消耗能量最小,在性能和功耗间有较好的平衡,适合实时视频编/解码器的开发,特别是对功耗有严格要求的实时运动视频处理。
c) 高性能的地址产生器。具有2个DAG(数据地址产生器),用于产生支持高级DSP滤波运算的地址的复合装入或存储单元。支持位倒序寻址和循环缓冲以及其他多种寻址方式,提高了编程的灵活性。
d) 分层结构的内存。分层结构的内存缩短了内核对内存的访问时间,以获得最大的数据吞吐量、较少的延迟和缩短的处理空载时间。
e) 特有的视频操作指令。提供适合DCT(离散余弦变换)、霍夫曼编码等视频压缩标准中常用的操作指令,这些视频指令还消除了主处理器与一个独立的视频编解码器之间的复杂和易混和通信问题。这些特点有助于为终端应用缩短产品上市时间,同时降低了系统的总体成本。
我们使用的ADSP-BF533可以实现600 MHz的持续工作,具有:4 GB的统一寻址空间;80 kB SRAM的L1指令指令存储器,其中16 kB可配置成4路的联合Cache;2个32 kB SRAM的L1数据存储器,其中一半可配置为Cache;集成丰富的外围设备和接口。
3 、基于BF533的H.264去方块滤波优化实现
去方块滤波器在Blackfin BF533优化实现主要分为系统级别的优化、算法级别的优化、汇编级别的优化3个级别。
3.1 系统级别的优化
打开DSP平台中编译器的优化选项并将优化速度设置为最快,打开Automatic Inlining开关(自动内联开关)以及Interprocedural optimization开关(优化过程开关),通过以上的一些设置充分发挥Blackfin BF533的硬件性能。
3.2 算法级别的优化
将JM8.6参考模型中的去方块滤波部分进行适当的系统修改,移植到原有的基于Blackfin BF533的H.264基本挡次的解码器中,并通过图像序列对其进行耗时分析。选用码率为400 kbit/s左右的Paris.cif、Mobile.cif、Foreman.cif、Claire.cif序列,去方块滤波所耗费的时钟周期约为1 600 MHz~1 800 MHz,即使在经过系统优化后,计算复杂度仍然相当大,效率很低,对于Blackfin BF533处理器600 MHz的持续工作频率是相当大的负担。
通过分析JM8.6中去方块滤波程序,其效率低下的主要原因是:
a) 算法中的函数逻辑关系复杂,判断、跳转、函数调用等情况特别多;
b) 最耗时的部分,即函数循环的内部存在大量的重复计算,造成计算复杂度剧增;
c) 算法中用到的不少数据,例如运动矢量、图像的亮度和色度数据等存放在速度较慢的片外SDRAM中,但在滤波过程中的频繁调用,使数据搬运时间剧增。
针对耗时的原因,对算法进行了以下改进:
3.2.1 将原程序中复杂的函数及循环简单化
指令长度和运算速度是相互制约的,往往将代码通过条件判断可以进行高度精简,但由于增加了机器的判断工作量而使得速度变慢;反之,将代码中的判断去除,程序进行展开,往往可以减少耗费的指令周期,但代码长度会增加。JM8.6中的去方块滤波代码较短,将其中的函数间关系简单化,以代码长度增加换取执行速度的增加。
对于系统运行最耗时的循环体,采取适当改写循环形式、多重循环体展开等方法有效地减少运算的复杂度。此外,减少调用函数次数,改写if-else语句也是有效的优化手段。
3.2.2 去除参考代码中的大量冗余代码和重复计算
a) 因为使用的参考代码是JM8.6中的去方块滤波模块,该模块可以对H.264的各种挡次和级别的码流进行滤波,而解码器是基于基本挡次的,仅仅涉及到I帧、P帧的滤波操作,因此可以将参考代码中的关于B帧、SP/SI帧、场模式和帧场自适应模式的相关滤波部分去除。
b) 程序在获取滤波强度BS和进行亮度/色度的滤波过程中,都要获取当前子块所在的宏块的相邻宏块的可达性的信息(即这个宏块能否被使用,通过调用GetNeighbour 函数实现),由于滤波是按照宏块中的边缘先垂直后水平进行的,对于一条边缘获取的信息是相同的,因此这个操作可以对每条边缘获取一次即可,不必在循环内部反复判断。同时在滤波算法中,仅需要获取在当前宏块上面和左边的宏块的可达性信息,可将获取当前宏块的左上及右上角宏块信息的冗余操作去除。同时,获取水平方向的滤波强度的函数调用getNeighbour时,getNeighbour参数的取值分别是luma为定值1,xN是[-1,3,7,11],yN是[0-15],此时函数getNeighbour中的很多if-else语句是无效的判断,这些冗余判断占用了大量的时钟周期。此外,对各个分支的概率进行分析,将概率最大的判断分支放在前面执行,也提高了函数执行的速度。
以下是精简后的GetNeighbour函数代码,仅有数条语句,大大减少了运算量。

c) 在JM86参考代码中对于一个亮度宏块的16×4共64条像素边缘的BS值逐条获取,而通过对BS获取条件进行分析可知,处于两个子块间垂直边缘或水平边缘的4条像素边缘的BS值分别是相等的。因此,对一条边缘仅要进行获取第1、5、9、13条像素边缘的BS值,再赋给相应的其他像素边缘即可,由于获取BS值的操作位于循环中,需要经过许多判断及运算,通过这一改进,大大简化了计算复杂度。
d) 参考代码中的循环内部有很多语句与循环参数无关,可以将这些语句调整至循环外部,避免了冗余计算。
3.2.3 利用BPP分块处理技术解决片外数据频繁调用的问题
针对频繁调用片外数据影响了程序的运行速度的问题,采用BPP分块技术进行优化。在片内的L1缓存中开辟3块空间分别存放待滤波的亮度分量、色度U分量、色度V分量。根据每个宏块进行滤波时可能涉及的像素范围,在对CIF图像进行滤波时,将一帧的396个宏块分成4类:A类为第1个宏块,其上边缘和左边缘都是图像边缘,对其滤波前读入的亮度数据是16×16,色度数据是2个8×8;B类为第1个宏块行中除去第1个宏块的其余宏块,其上边缘是图像边缘,对其滤波前读入的亮度数据是16×20,色度数据是两个8×12;C类是第1个宏块列中除去第1个宏块的其余宏块,其左边缘是图像边缘,对其滤波前读人的亮度数据是20×16,色度数据是2个12×8;D类是除掉A、B、C这3类宏块的其余宏块,也就是上边缘和左边缘都在当前图像内的宏块,对其滤波前读入的亮度数据是20×20,色度数据是2个12×12。
进行滤波时,首先按宏块的类型以不同的数量从片外的数据缓存中整块地读入亮度和色度数据到片上的3块滤波缓存,然后进行滤波处理,并将结果数据重新存储到片外存储空间中。通过这种方法,一方面在一定程度上减少了频繁调用片外数据的时间,提高了运行速度;另一方面通过对待滤波宏块的细分,减少了参考代码中的判断引起的流水线中断,也在一定程度上提升了程序速度。
3.3 汇编级别的优化
BlackfinBF533处理器的内核支持C或C++语言,但由系统自动将C程序翻译成汇编语言效率比较低下,因此对一些系统调用比较频繁、耗时较多的模块,可以用人工将其转化成高效率的汇编语言来提高运行速度。主要通过以下几个方面来提高程序的速度:
a) 以寄存器变量代替局部变量。在C语言中,子程序和函数中往往使用局部变量来暂时存放数据。当程序运行时,编译器为声明的所有局部变量开辟临时内存空间,对于局部变量的存取操作都涉及到内存的存取,而内存访问的速度相对于寄存器访问是很慢的。因此,可以利用系统中的数据寄存器、指针寄存器来替代仅仅起暂存作用的局部变量,从而大大节省系统访问内存带来的时间延迟。但由于系统中的寄存器数量对于局部变量来说相当有限,因此必须合理高效地使用寄存器。
b) 以硬件循环代替软件循环。软件循环是指在for或while等循环的开始或结尾处设置判断条件来控制循环的开始、继续、结束。软件循环的条件判断指令会动态地选择分支,一旦发生跳转,会阻塞流水线,而保持流水线的畅通是保持高效运行的关键因素。Blackfin处理器有专用的硬件支持两级嵌套的零开销硬件循环,这种方式不需要判断条件转移,DSP硬件根据预定的循环次数自动执行循环并结束循环,从而保证了流水线的畅通,提高速度。
c) 充分利用数据总线宽度。Blackfin533外部数据总线宽度32位,一次可存取4字节。因此,充分利用数据总访问宽度,特别在操作大量数据时,保持一次存取4字节,可减少指令周期数,从而提高执行速度。
d) 高效使用并行指令和向量指令。并行指令和向量指令是Blackfin系列DSP的一大特点。通过对并行指令的使用,可以充分发挥Blackfin处理器的SIMD系统结构的优点及硬件资源的并行处理能力,减少指令数,从而提高程序执行效率。往往通过对程序的合理安排可以做到使用1条并行指令来替代2条或3条非并行指令。向量指令则充分利用指令宽度,同时对多个数据流进行相同操作,如要进行2个16位的算术或移位操作,完全可以通过1个32位的向量指令来实现,从而以1个时钟周期来实现原来2个周期的工作。例如R3=abs R1(V)就用1个指令周期同时实现2个16位数据的求绝对值操作。
e) 合理配置数据存储空间。限于DSP片内和片外数据存储空间的访问速度和容量特点,片内空间存取速度快但容量很小,而片外空间较大但访问速度慢,因此,合理地分配数据存放位置对于提高程序的运行速度是十分关键的。对于使用频率高的数据尽量放在片内空间中,而不常用的数据放在片外空间中。若要存取位于片外的数据时,应将待存取的数据尽量安排成连续分布,一次将大块的片外数据读进片内缓存,避免频繁读取片外数据带来的时间浪费。
4、 优化实现的结果
测试优化效果的方法是将参考代码JM8.6中的去方块滤波C程序模块加到原有的解码器中进行测试,并与经过系统、算法、汇编3个级别优化的去方块滤波汇编程序模块的测试周期进行对比。选择的测试图像序列为Clarie.cif、Paris.cif、Mobile.cif,测试数据见表1。

由表1可以看出,与未优化前的JM8.6中的C程序代码相比,经过优化后的去方块滤波汇编模块效率提高了7倍左右。
5 、结束语
本文通过系统、算法及汇编3个级别优化实现了H.264中的去方块滤波功能,特别是通过改进去方块滤波的实现算法,对待滤波的宏块进行分类以及充分地利用并行指令、向量指令等汇编级别的优化手段,取得了较好的优化效果。优化实现的去方块滤波模块,基于原有的H.264解码器上对一个25帧约400 kbit/s的图像序列进行滤波,大概需要250 MHz的时钟周期,而解码器的总周期约为700 MHz的时钟周期,从而使得解码器的解码速度达到约20帧/s,基本达到准实时解码的要求。
该实现方法相对于参考模块进行了较好的优化,但通过对程序进行耗时分析,在读取待滤波数据和重新写入已滤波的数据,获取BS值的GetBs函数和进行滤波的EdgeLoop函数方面都还有进一步提升的空间。对于片外片内数据的交互可以采用DMA技术,在滤波的同时进行数据读写,从而抵消数据搬移消耗的时钟周期;对于GetBs和EdgeLoop中的汇编代码实现效率还有进一步改进的空间;这两方面也是下一步的改进方向。
责任编辑:gt










 工商网监
工商网监
评论