 电子发烧友App
电子发烧友App


在这篇文章中,我们将探索MIPS军工级I级I6500 CPU处理器的异构设计如何大幅提升性能及降低功耗。
高性能处理器通常使用深度多指令执行、分支预测及无序处理等技术以使性能最大化,但这却可能会影响功效。
如果其中一些任务是并行的,随之便会在一系列CPU中进行分区,这样便可以提供高性能高效的方案。为此,CPU供应商提供了多核集群,操作系统和应用程序开发人员则设计了相关软件以开发这些功能。
采用多线程
即使采用无序执行,通常的工作负载使得CPU将大多数时间花在等待内存系统的访问上。新引入的MIPS I6500支持多线程,即每个线程作为单独的处理器出现在软件中。根据不同的应用程序,添加第二个线程至CPU中时,通常10%的面积需要总体性能提升40%。MIPS I6500可以容纳6个CPU,每个都有4个线程,这样就不必在单个集群中运行24个线程。
MIPS I6500集群添加了对系统层硬件相干性的支持,并使用AMBA ACE添加接口至系统中。AMBA ACE是一个一致性总线接口,可以兼容最常用的相干NoC产品,如 NetSpeed公司的Gemini及Arteris公司的Ncore。有了NetSpeed Gemini 产品,64 MIPS I6500集群将可以连接高达384个处理器,运行1536个线程,这着实令人惊叹。
对于许多消费产品,其所需的处理性能随着时间的推移可能会有很大的差别。通常,它们只是偶尔需要峰值性能。大多数的时间却只需要较低的性能,而这通过使用一个更简单更高效的处理器大幅降低总功耗便可以实现。
信息共享
将任务从一个处理器移至另一个处理器需要每个处理器可以共享相同的指令集及系统内存信息。这通过共享虚拟内存(支持向量机)便可以实现。程序中的任何指针必须继续指向相同的代码或数据,且初始处理器中任何不良缓冲必须让随后的处理器可见。

图一:内存在集群中传输时的移动轨迹

图二:集群内传输时内存移动轨迹更短速度更快
维持处理器之间的缓存一致性
缓存一致性可以通过软件管理。这要求最初的处理器(CPU A)在传输任务至后续处理器(CPU B)之前冲刷主存储器的缓存。CPU B从主存储器中获取数据和指令。这个过程可能生成许多内存访问,因此将耗费时间和功率。访问主存储器所需的功率比获取缓存时的功率高一个数量级,所以这种影响还将被放大。为了解决这一问题,I6500 CPU集群支持硬件缓存一致性,以将功耗和性能成本降至最低。
在使用I6500集群的系统中,当一个任务从CPUA传输至CPU B中时,CPU B将访问驻留在CPU A中的本地缓存线路。硬件缓存一致性将跟踪这些缓存线路的位置,并在必要时窥探缓存情况,以确保访问数据的正确性。
I6500集群的另一个优势是可以在集群中被发现。在典型的异构系统中,高性能处理器驻留在一个集群中,面积更小更高效的处理器驻留在另一个集群中。在这些不同类型处理器之间进行任务传输时,新处理器第1层和第2层的缓存都是非激活的。要激活这些缓存需要一定的时间,并需要先前的缓存层在过渡阶段仍然保持活跃。
MIPS I6500是不同的。我们称这种差异性为“异构内置”,这意味着I6500支持异构混合类型的处理器,允许高性能和功率优化处理器处在同一集群中。将任务从一种类型的处理器传输至另一类处理器中将更有效,因为只有第1层缓存是未激活的,窥探上一层缓存的成本降低,因而过渡时间变得更短。
CPU配置专用加速器
CPU是通用的设备。其灵活性使其可以处理任何任务,且任务处理具有成本效率。而PowerVR GPU能够高性能高效率地处理更大且高度并行的计算任务,其代价是灵活性相比CPU则较为降低,但其同时支持良好的软件开发生态系统环境如OpenCL。
专用硬件加速器的专业化又有效地融合了多种性能,其性能效率相比CPU又高出了几个数量级,不过相应地灵活性则大为降低。
不过,多次使用加速器操作可以将潜在的性能和功效最大化。专业计算元素如音频和视频处理以及机器学习中使用的神经网络处理器使用了相似的数学运算。此类操作使用最为广泛的是向量点积(每向量中对应元素产品的总和)。配置在CPU上的专用加速器使用此函数则可以显著地提高性能并节省功率,同时又保留了CPU的灵活性。
通过增加单指令多数据(SIMD)功能与浮点算术逻辑单元(ALU)可以将硬件加速耦合至CPU中。不过,尽管通过SIMD处理数据,CPU仍然作为直接内存访问(DMA)控制器移动数据,且CPU是非常低效的直接记忆器存取(DMA)控制器。
相反,异构系统本质上却可以二者兼得。它包含了一些专用的硬件加速器,可以与大量的CPU耦合,提供更大的功效,同时又大量保留了CPU的灵活性。
功率的节省及性能的提升取决于加速器进行有用工作的时间。适合加速器的工作包范围较广——你可以预期少量的大型任务,又可以预期大量的小型任务。

图3:最小函数来证明转换成本的降低
在CPU与加速器之间进行传输处理将产生成本,限制任务的大小将节省功耗或提高性能。对于较小的任务,节省的功耗及传输任务所需的时间将超过使用加速器所需的功耗及节省的时间。
降低数据传输成本
I6500具有共享硬件虚拟内存功能,可以保持缓存一致性。这就大大节省了传输任务所需的成本,因为其消除了数据复制和缓存冲刷的工作。
为进一步减少时间及功率成本,还需要借助一些其他的技术。HSA Foundation开发了一个支持系统中异构处理元素集成的环境,其扩展超越了CPU和GPU。HSA系统有一个名为HSAIL的中间语言,该语言提供了一种常见的编译路径至异构指令集架构(ISA)中,极大地简化了系统软件开发,并同时定义了用户模式队列。
这些队列使任务有序进行,且信号在其它处理元素中触发任务,使得序列任务的执行成本较低。
相干单元
除了集群中的CPU ,MIPS I6500还支持许多IO相干单元(IOCU)。这些IOCU具有内存管理单元(MMU)功能,当处理CPU的任务时,其可以将任务处理映射至物理地址空间,并以同样的方式经过共享的第二层缓存,保持与所有本地缓存的一致性。对于许多系统而言,这种功能使加速器可以与CPU进行有效的集成。
对于加速器中较大的任务,直接内存访问(DMA)引擎的带宽可以非常大,甚至可能被存储系统的容量限制住。这样一来,加速器中内存系统的处理任务将进行列队,且将列队延迟添加至CPU共享了相同端口及路径的任务中。处理大型数据集的加速器对任务处理有些依赖,允许加速器预取数据。这样,即使是CPU中不共享的内存延迟也可以高度容忍。

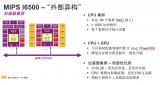
图4:使用了I6500、PowerVR GPU和加速器的异构系统图
MIPS I6500及其相干的总线接口允许加速器使用独立的系统内存路径并同时保留CPU集群的一致性。我们称之为“异构外置”。
异构的优势
异构系统可以大幅提升系统性能、降低系统功耗,使系统不因工艺精简而受到限制。多线程、异构和一致性CPU集群如MIPS I6500则是这些系统最完美的搭档。
它们在许多市场的下一代产品中都占据优势,如:高级驾驶员辅助系统(ADAS)及自动驾驶、网络、无人机、工业自动化、安全、视频分析、机器学习等。
Follow @ImaginationTech
英文链接:
https://imgtec.com/blog/heterogeneous-inside-revolutionary-mips-i6500-pr...








 工商网监
工商网监
评论