 电子发烧友App
电子发烧友App


英特尔今天举行了其数据中心和 AI 投资者网络研讨会,透露其第一代高效至强 Sierra Forest 将配备令人难以置信的 144 个内核,从而提供比 AMD 竞争的 128 核 EPYC Bergamo 芯片更高的内核密度。该公司甚至在其活动的演示中取笑了该芯片。
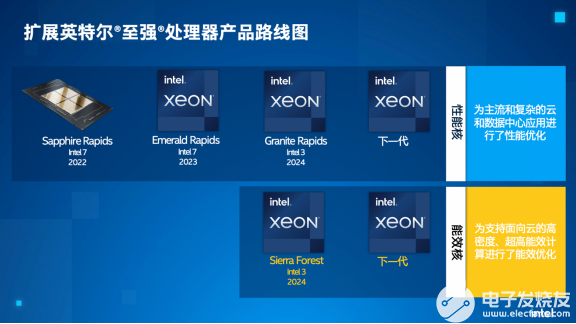
英特尔还透露了 Clearwater Forest 的第一个细节,它是将于 2025 年首次亮相的第二代至强处理器。英特尔跳过了其20A 工艺节点,为这款新芯片选择了性能更高的 18A,这充分说明了其对其健康状况的信心未来节点。该公司还展示了新产品和性能演示以及路线图更新,表明该公司的 Xeon 正在按计划推进。
英特尔还展示了几个演示,包括针对AMD 的 EPYC Genoa 的 正面 AI 基准测试,显示 Xeon 在两个 48 核芯片的正面交锋中具有 4 倍的性能优势,以及内存吞吐量基准测试,显示了下一代的Granite Rapids Xeon 在双路服务器中提供令人难以置信的 1.5 TB/s 带宽。
英特尔的披露,包括我们将在下面介绍的许多其他发展,是在该公司执行其在四年内交付五个新节点的大胆目标之际发布的,这是一个前所未有的速度,将为其广泛的数据中心和包括 CPU 、GPU、FPGA 和Gaudi AI 加速器在内的产品组合提供动力, 。
英特尔在数据中心的性能领先地位已被 AMD 夺走,其救赎之路因Sapphire Rapids和 GPU 产品线的延迟而受阻。然而,该公司表示,它已经解决了其工艺节点技术中的根本问题,并改进了其芯片设计方法,以防止其下一代产品的进一步延迟。让我们看看路线图是什么样的。
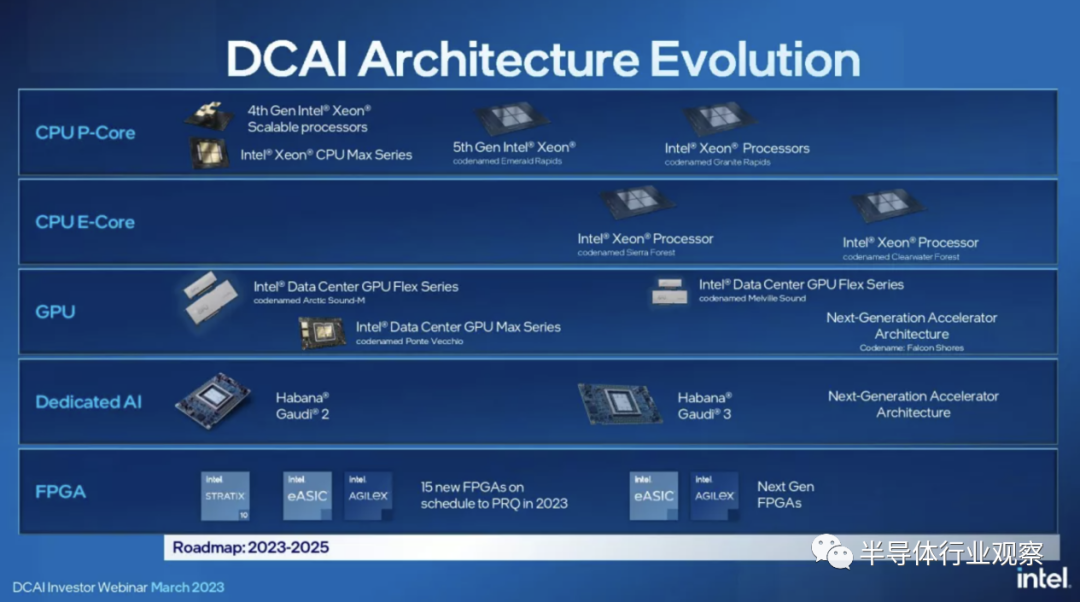
英特尔至强 CPU 数据中心路线图
自 2022 年 2 月上次更新以来,英特尔现有至强产品的路线图保持不变并按计划进行,但现在有一个新进入者——Clearwater Forest。我们将在下面进一步详细介绍该芯片。

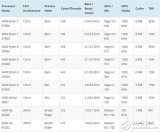
英特尔的数据中心路线图分为两条泳道。P-Core(性能核心)模型是传统的 Xeon 数据中心处理器,其核心仅可提供英特尔最快架构的全部性能。这些芯片专为实现最高的每核和 AI 工作负载性能而设计。它们还与加速器配对,正如我们在 Sapphire Rapids 中看到的那样。

E-Core(效率核心)系列由仅具有较小效率核心的芯片组成,就像我们在英特尔的消费芯片上看到的那样,它避开了一些功能,如 AMX 和 AVX-512,以提供更高的密度。这些芯片专为高能效、核心密度和总吞吐量而设计,对超大规模企业具有吸引力。英特尔的 Xeon 处理器不会有任何型号在同一芯片上同时具有 P 核和 E 核,因此这些是具有不同用例的不同系列。

在这里,我们可以看到英特尔的路线图与AMD 的数据中心路线图相比如何。当前,AMD 去年推出的 EPYC Genoa 和英特尔今年年初推出的 Sapphire Rapids 之间的高性能大战正在激烈进行。英特尔将于今年第四季度推出其更新一代的Emerald Rapids ,该公司表示将配备更多内核和更快的时钟速率,以及注入 HBM 的 Xeon Max CPU。AMD 的 5nm Genoa-X 产品定于今年晚些时候发布。明年,英特尔的下一代 Granite Rapids 将与 AMD 的 Turin 展开较量。
在效率泳道上,AMD 的 Bergamo 通过利用 AMD 密集的 Zen 4c 内核,采用与 Sierra Forest 非常相似的重核方法,但它将在今年上半年到货,而英特尔的 Sierra Forrest 将在2024 年上半年到货。AMD 没有说它的第二代 e-core 模型什么时候到货,但英特尔现在在 2025 年的路线图上有它的 Clearwater Forest。
Intel E-Core Xeon CPU:
Sierra Forest 和 Clearwater Forest
英特尔的 e-core 路线图从 144 核 Sierra Forest 开始,它将在单个双路服务器中提供 256 个内核。第五代 Xeon Sierra Forest 的 144 个内核在内核数方面也超过了 AMD 的 128 核 EPYC Bergamo,但在线程数方面可能并不领先——英特尔面向消费市场的 e 内核是单线程的,但该公司尚未透露数据中心的电子内核是否支持超线程。相比之下,AMD 表示 128 核 Bergamo 是超线程的,因此每个插槽总共提供 256 个线程。

我们也不知道英特尔或 AMD 密集内核的性能细节,因此在芯片上市之前我们无法知道这些芯片的性能。但是,我们确实知道英特尔的 e-cores 不支持其 p-core 支持的某些 ISA;英特尔省略了 AVX-512 和 AMX 以确保最大密度,而 AMD 的 Bergamo Zen 4c 内核支持与其标准内核相同的功能。

不过,英特尔的 Sierra Forest 显然在 2024 年上半年进展顺利:Mountain Stream 系统的图像已经在网上泄露,包括您可以在下面看到的大型LGA7529 插座的图片。该插槽将容纳 e-core Sierra Forest 和 p-core Granite Rapids 处理器。

这表明 Sierra Forest 平台已经与英特尔的合作伙伴合作,该公司还告诉我们,它已经为芯片供电,并在不到 18 小时的时间内启动了操作系统。该芯片是“Intel 3”工艺节点的主要载体,因此成功至关重要。英特尔有足够的信心,它已经向客户提供了芯片样品,并在活动中演示了所有 144 个内核的运行情况。英特尔最初将 e-core Xeon 型号定位于特定类型的云优化工作负载,但预计一旦上市,它们将被用于更广泛的用例。
英特尔还首次公布了Clearwater Forest。英特尔没有透露 2025 年发布时间之外的更多细节,但确实表示它将为芯片使用 18A 工艺,而不是半年前到达的 20A 工艺节点。这将是第一款采用 18A 工艺的至强芯片。英特尔告诉我们,其工艺路线图的压缩性质——该公司计划在四年内交付五个节点——使其可以选择 2024 年到达的 18A 工艺或 2024 年下半年投入生产的 20A 工艺.
18A 节点是英特尔的第二代“Angstrom”节点,类似于 1.8nm。英特尔的第一代 Angstrom 节点,20A,将采用 RibbonFET,一种环栅 (GAA) 堆叠纳米片晶体管技术,以及英特尔的 PowerVia 背面供电 (BSP) 技术。Intel 将用于 Clearwater Forest 的 18A 工艺将比 20A 的每瓦性能提高 10%,以及其他改进,因此 Intel 选择采用该节点,因为它是该公司在Clearwater 发射的时间表。
18A工艺拥有行业未来打算采用的所有前沿技术,如GAA和BSP,因此它代表了一个非常先进的节点。英特尔声称 18A 节点将在其竞争对手台积电和 AMD 中获得明显的工艺领先地位,而该公司决定跳过 20A 并为 Xeon 转向 18A 无疑充分说明了其对该节点健康状况的信心。英特尔还告诉我们,我们不会看到采用 20A 制造的 Xeon 型号。
Intel P-Core Xeon CPU:
Emerald Rapids 和 Granite Rapids
英特尔的下一代 Emerald Rapids 计划于今年第四季度发布,鉴于 Sapphire Rapids 几个月前推出,这是一个压缩的时间框架。Emerald 将落入与 Sapphire Rapids 相同的平台,从而减少客户的验证时间,并且在很大程度上是 Sapphire Rapids 的更新。然而,英特尔表示,它将提供比其前身更快的性能、更好的能效,更重要的是,它将提供更多的内核。英特尔表示,它拥有内部的 Emerald Rapids 硅,并且验证正在按预期进行,硅达到或超过其性能和功率目标。
Granite Rapids 将于 2024 年抵达,紧随 Sierra Forest。英特尔将在“Intel 3”工艺上制造这种芯片,这是“intel 4”工艺的一个大大改进版本,缺少Xeon 所需的高密度库。这是“intel 3”上的第一个 p-core Xeon,它将具有比 Emerald Rapids 更多的内核、来自 DDR5-8800 内存的更高内存带宽,以及其他未指定的 I/O 创新。
值得注意的是,第一个配备 E 核的系列 Sierra Forest 将与 P 核供电的 Granite Rapids 插座兼容;他们甚至共享相同的 BIOS 和软件。英特尔通过将这些芯片转移到 tile-based design来实现这一点,中央 I/O 块处理内存和其他连接功能,就像我们在 AMD 的 EPYC 处理器上看到的那样。这将核心和非核心功能分开,因此英特尔通过使用不同类型的compute tiles来创建不同的处理器类型。这提供了多种好处,例如能够使用相同的系统将更多线程heft与 E 核打包在一起,但在与 P 核模型相同的 TDP 范围内。
在其网络研讨会期间,英特尔演示了双插槽 Granite Rapids,可提供惊人的 1.5 TB/s DDR5 内存带宽;声称比现有服务器内存提高了 80% 的峰值带宽。从长远来看,Granite Rapids 提供的吞吐量高于 Nvidia 的 960 GB/s Grace CPU 超级芯片,专为内存带宽设计,也高于 AMD 的双路Genoa,其理论峰值为 920 GB/s。英特尔使用 DDR5-8800 多路复用器组合列 (MCR) DRAM 实现了这一壮举,这是一种其发明的新型带宽优化内存。英特尔已经与 SK 海力士一起推出了这款内存。
Granite Rapids 和 Sierra Forest 是英特尔最近重组其芯片设计流程的拦截点,这应该有助于避免发现该公司对 Sapphire Rapids 处理器进行多次连续步进导致进一步延迟的问题。英特尔表示,Granite Rapids 在其开发周期中比 Sapphire Rapids 在这一点上走得更远。英特尔表示,Granite Rapids 正在实现所有工程里程碑,并且迈出了健康的第一步。因此,它现在已经在向客户提供样品。
英特尔的数据中心和 AI 更新专注于 Xeon,但该公司的产品组合还包括其他“配料”,如 FPGA、GPU 和专用加速器。英特尔在定制硅领域有很多竞争对手,例如谷歌的 TPU 和 Argos 视频编码芯片(以及许多其他公司),因此 Gaudi 加速器和 FPGA 是其产品组合的重要组成部分。英特尔表示,今年将推出 15 款新 FPGA,创下其 FPGA 集团的记录。我们尚未听说 Gaudi 芯片取得任何重大胜利,但英特尔确实在继续开发其产品线,并在路线图上推出了下一代加速器。Gaudi 2 AI加速器出货,Gaudi 3已录入。

英特尔还表示其 Artic Sound 和 Ponte Vecchio GPU 正在出货,但我们并不知道后者在一般市场上有售——相反,第一批 Ponte Vecchio 型号似乎正用于经常延迟的 Aurora 超级计算机。
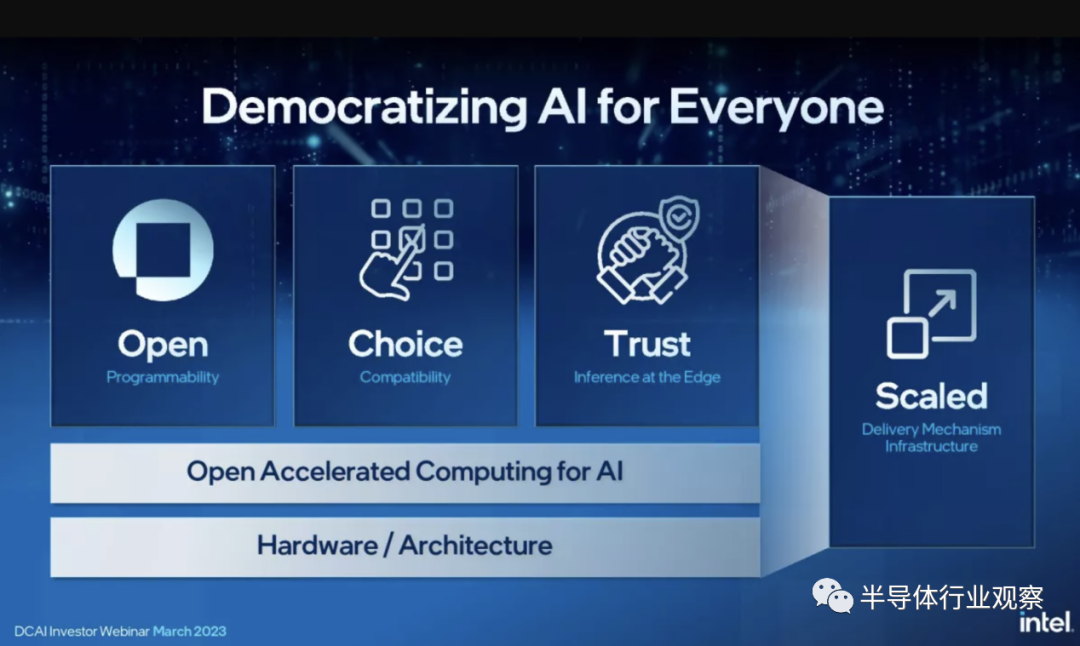
英特尔最近更新了其 GPU 路线图,取消了即将推出的 Rialto Bridge 系列数据中心 Max GPU,并将数据中心 GPU 的发布周期改为两年。该公司的下一个数据中心 GPU 产品将以Falcon Shores的形式出现 基于小芯片的混合芯片,但这些芯片要到 2025 年才会到货。该公司还降低了对 Falcon Shores 的期望,称它们现在将作为纯 GPU 架构出现,并且不会像最初预期的那样包括 CPU 内核选项— 那些“XPU”模型现在没有预计的发布日期。英特尔预测,AI 工作负载将继续主要在 CPU 上运行,所有模型中的 60%,主要是中小型模型,都在 CPU 上运行。同时,大型模型将包含大约 40% 的工作负载,并在 GPU 和其他定制加速器上运行。英特尔还致力于为 AI 构建可与 Nvidia 的 CUDA 相媲美的软件生态系统。这还包括采用端到端的方法,在堆栈的每个点都包含芯片、软件、安全性、机密性和信任机制。
一点思考
几年前,英特尔就开始将其 CPU 转向以人工智能为中心的设计,而如今人工智能通过像 ChatGPT 这样的大型语言模型 (LLM) 进入公众视野,证明这是一个可靠的赌注。然而,今天的 AI 格局每天都在变化。它涵盖了一系列鲜为人知和较小的模型,因此为任何一种算法优化新芯片都是徒劳的。当芯片设计周期长达四年时,这尤其具有挑战性——今天的许多 AI 模型当时并不存在。
我们采访了英特尔高级研究员 Ronak Singhal,他解释说,英特尔很久以前就选择专注于支持人工智能的基本工作负载需求,例如计算能力、内存带宽和内存容量,从而奠定了一个广泛适用的基础,可以支持任何数量的算法。英特尔还稳步扩展了对不同数据类型的支持,例如 AVX-512 及其第一代 AMX 技术,该技术现已出货,支持 8 位整数和 bfloat16。Intel 还没有告诉我们它的第二代 AMX 什么时候到货,但它会支持 16 位整数,并且将来具有支持更多数据类型的扩展性。这种支持基础使英特尔能够在许多不同类型的 AI 工作负载中使用 Xeon 提供令人印象深刻的性能,通常超过 AMD 的 EPYC。
是的,许多 AI 模型太大而无法在 CPU 上运行,而且大多数训练工作负载将保留在 GPU 和定制芯片领域,但较小的模型可以在 CPU 上运行——比如 Facebook 的 LlaMa,它甚至可以在 Raspberry Pi 上运行——与任何其他类型的计算相比,当今更多的推理工作负载在 CPU 上运行——包括 GPU。我们预计这种趋势将随着更小的推理模型继续下去,并且英特尔通过其 P-core Xeon 路线图为这些工作负载做好了准备。
英特尔不乏竞争对手,Arm 生态系统在数据中心的应用越来越普遍,亚马逊的Graviton 2、阿里巴巴的倚天、微软 Azure 中的Ampere Altra、甲骨文云和谷歌云,Nvidia 的Grace CPU、富士通和华为鲲鹏,以及谷歌的Maple 和 Cypress等等。甚至还有两台使用Arm Neoverse V1 芯片的百亿亿级超级计算机部署:SiPearl“Rhea ”和 ETRI K-AB21。
这意味着英特尔和 AMD 一样,需要采用更注重能效和核心密度的优化芯片,以缓解向 Arm 迁移的超大规模和 CSP 的压力。这以英特尔的 e-core Xeon 模型和 AMD 的 Bergamo 芯片的形式出现。如果 AMD 实现了它的路线图,并且没有理由相信它不会,它将凭借其密度优化的 Bergamo 击败英特尔进入市场。这可能会使英特尔在高容量(但利润率较低)的云市场中处于劣势。另一方面,英特尔确实计划将其后续 Clearwater Forest 模型转移到*可能*比 AMD 更先进的节点,从而在 2025 年展开有趣的竞争。
鉴于公司最近的历史,英特尔在去年分享的 Xeon 路线图中仍然坚定不移,这一事实令人鼓舞。18A 节点的加速采用也充分说明了公司更广泛的基础工艺技术影响其业务的各个方面。
编辑:黄飞
















 工商网监
工商网监
评论