 电子发烧友App
电子发烧友App


本文来源“专用处理器比较分析(2022)”。 专用处理器 (或专用加速器), 顾名思义, 就是用于处理 “特定应用” 的处理器, 相对于通用处理器而言, 这类处理器性能更高、功耗更低、通常价格也更便宜, 但是使用范围也相对有限。 计算芯片产业在过去 50 年的发展历程中, 比较成功的专用处理器门类只有数字信号处理器 (DSP)、图形处理器(GPU) 和网络处理器 (NPU), 这是 20 世纪 90 年代就已经基本定型的格局。
AI芯片专利技术研发态势
在过去 5 年中, 用于处理深度学习的神经网络处理器 (AI 芯片) 也开始快速发展, 比较成功的案例包括 Google 公司的张量处理器 TPU、寒武纪公司的 DianNao 系列深度学习处理器 [5] 等。 专用处理器的最终目标不是替代通用 CPU, 而是与现有的通用 CPU 技术协作, 即将部分 CPU 运行效率低下的应用卸载 (offloading) 到用加速器上运行, 通过构建异构计算平台来高效地处理计算任务。 从产业生态的视角来看, 相比于通用处理器的硬件与软件分离的 “水平” 模式, 专用加速器更注重软硬协同的 “垂直” 发展模式。
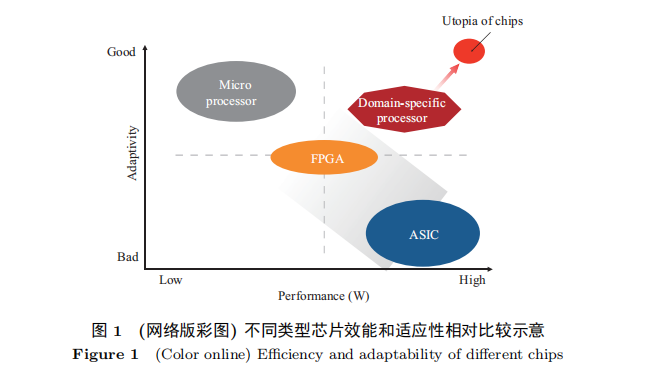
从芯片的效能和适应性两个维度来刻画芯片的特征。 这里效能指的是单位功耗下提供的计算能力, 适应性就是通常意义下的通用性。 业界通常将数据处理芯片大体分为三大类: 处理器芯片、ASIC(application specifific integrated circuit) 芯片和 FPGA (fifield programmable gate array) 芯片。
处理器芯片包括 CPU, GPU, DSP 等, 是用户可编程的芯片; ASIC 是面向特定应用 (application-specifific) 的专用集成电路 [8], 通常也称之为全定制芯片, 不可编程; FPGA 器件属于专用集成电路中的一种半定制电路, 是可 “编程” 的逻辑列阵, 利用查找表来实现组合逻辑, 但 FPGA 的 “编程” 与处理器芯片的软件编程不同, 主要是配置逻辑, 可以理解为硬件编程。
从相对性能来看, ASIC 芯片最好, 处理器芯片最差, FPGA 介于二者之间; 但是从应用的适应性来看, 处理器芯片最好, FPGA 次之, ASIC 芯片最差。
值得注意的是这种分类标准并不是按照电路制造工艺, 例如处理器芯片和 ASIC 芯片本质上都是全定制的集成电路, 处理器芯片本质也是一种 ASIC, 但与通常意义上 ASIC 的最大差别还在于是否具有指令集, 有指令集的就更类似传统的处理器, 反之就归类为 ASIC. 此外, 处理器芯片由于其使用广泛、出货量大, 与软件生态联系尤其紧密, 所以将其独立为一个大的类别。
无论是 DSP、GPU、AI 芯片、NPU, 还是现在更新的各种 “XPU”, 都是处理数据的芯片, 最终都需要执行二进制代码的程序来完成计算。 因此专用处理器设计也大都需要涉及如下 6 方面内容:
(1) 约定二进制代码的格式, 即指令;
(2) 需要将指令变换为机器码, 即汇编;
(3) 为了提高编程方便程度, 需要将高层程序语言转换为汇编语言, 即编译;
(4) 为了提高编程的效率, 提供了各种编程环境, 即集成开发环境 (integrated development environment, IDE);
(5) 充分复用高度优化的代码, 即应用程序库;
(6) 为了方便程序调试, 还需要提供各种仿真工具, 即仿真器 (emulator)。
所以, 从系统抽象层次来看, 与通用处理器几乎没有区别。 但是不同的 DSIC 侧重点不同, 有些 DSIC 只提供 API (application programming interface) 方式的调用, 例如早期的 GPU, 将编译、汇编等过程全都凝结在运行时库中,从用户角度看, 调用过程与使用 OpenCL [9] 中的 “内建核函数 (built-in kernels)” 类似,与调用普通的库函数过程相同; 虽弱化的可编程性, 但是强化了用户使用的便利性。 但也有些 DSIC, 如 DSP, 使用了大量底层编程, 虽编程难度高, 但方便精确地性能调优。
DSP: 灵活的数据格式
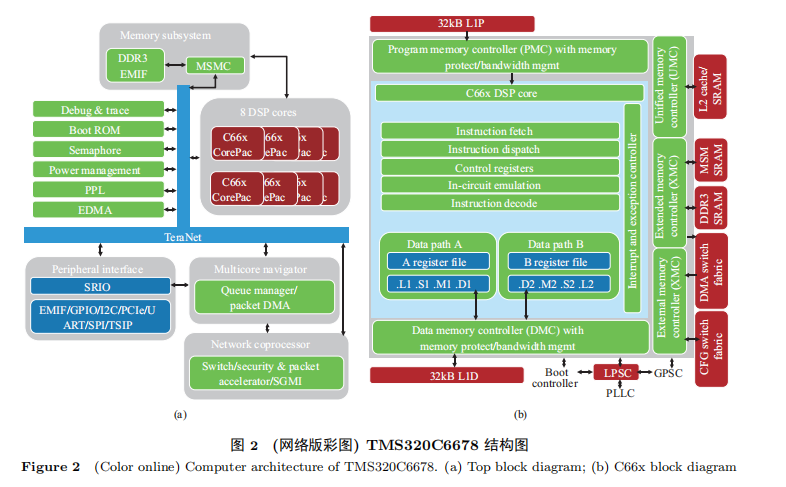
DSP 也许是最早出现的专用集成电路。 DSP 的使用范围非常广, 从简单的 MP3 播放器到最新一代的 5G 通信都有使用场景。 常见的 DSP 大多带有丰富的外设接口, 例如 PCIe、以太网、UART、I2C等, 尤其在很多嵌入式设备中, 丰富的外设接口对于提高系统的集成度、降低成本和功耗都有很大帮助, 所以很多 DSP 产品也演变成带有丰富外设接口的 SoC (system on chip) 芯片, 如图 2(a) 所示。
但是 DSP 最大的特点还是进行数字信号处理的核。 大多数 DSP 由于使用场景多为移动设备, 或者只是作为 CPU 系统的数据输入前端, 在系统中的地位并不高, 通常在功耗、散热等方面都不可能给予太高容限, 所以功耗敏感、计算位宽对 DSP 很重要, 定点、浮点, 半精度、单精度、双精度, 16 位、24 位、32 位、40 位等各种数据格式规范 “五花八门”。 在寻址上, DSP 对于数据对齐方式也最灵活, 设置了大量专门的指令对数据进行对齐操作。
TI 公司是 DSP 芯片的龙头, 被媒体评为是半导体行业利润率最高的公司。 2019 财年营业总收入144 亿美金, 税后净利润高达 50 亿美金, 利润率高达 35%. 作为比较, 同期 Intel 收入 720 亿美金, 利润率 29%; 英伟达总营收 110 亿美金, 利润率 25%. TI 公司的 DSP 主要分为 3 大系列: C2000 系列,集成了 AD 转换、Flash 存储等, 主要用于控制马达、变频器等工控产品; C5000 系列, 16 位定点, 主要用于便携声音、视频、机顶盒等设备; C6000 系列, 采用了 VLIW (very long instruction word) 架构, 每秒执行指令峰值可达百亿条, 主要用于数字通信、图像增强、传输、加密解密等对性能要求更高的场景。 下面就以比较复杂的 C6678 为例做简要介绍, 其顶层架构如图 2 所示。
1、通过 VLIW 架构提高性能
在 C6000 系列的 DSP 中, 采用了超长指令字 (VLIW) 技术, 性能的提升主要是通过引入 SIMD(single instruction multiple data) 来实现。 从 2 路 16 位、4 路 8 位 SIMD 操作, 到 8 路 16 位、4 路 32 位向量操作。 为了支持较宽的向量化操作, C66x 系列 DSP 设置了 8 个功能单元、两组寄存器堆文件、两条独立数据通路; 每组寄存器文件包含 32 个 32 位通用寄存器, 而且可以支持 8, 16, 32, 40, 64 位等非常灵活的数据位宽打包存储。 例如一个完整 32 位寄存器连同相邻寄存器的低 8 位存储一个 40 位的浮点数, 同时相邻寄存器的高 24 位还可以用于存其他的数。 乘法器支持 128, 40, 64 位数据。 显然支持那么多 “非标” 的定点和浮点数, 如何来安排寄存器的分配成为一个很有挑战的问题。
2、指令缓存和程序缓存分离
将指令与数据分离也就是著名的 “哈佛结构”, 一级程序缓存 (L1P) 采用直接映射, 一级数据缓存(L1D) 采用多路组相连。 这样导致了缓存替换策略的不同, L1P 采用新缓存行替换同一位置的旧缓存行, 采用读 – 分配 (read-allocate) 策略。 相较而言, L1D 复杂的多, 采用了最近最少使用 (least recently used, LRU) 替换策略和回写 (writeback) 机制: 当数据被更新时, 并不立即更新相应的缓存位置和存储器地址, 而只做 “dirty” 标记, 只有数据被替换出缓存, 或者手动启动一致性操作指令, 或出现长距离访问 (此时所有高速缓存的局部性都极有可能被破坏), 才会写回到存储器。 这也说明指令的局部性是比数据的局部性显著得多, 而且对于核而言, 指令缓存是只读的, 而数据缓存可读可写, 从这个意义上看, 将二者分开也是有好处的。 此外, DSP 的缓存还支持很多先进的管理功能, 例如强制冻结模式(freeze mode), 可以防止中断程序破坏已经建立在缓存中的数据局部性, 降低中断恢复后 “冷启动” 性能开销。 这些操作也全都由程序员来完成。
3、硬件指令支持一致性管理
多核并不是 CPU 的 “专利”, C6000 系列也提供多核的 DSP, 由于多核引入会导致数据一致性的问题, C66x 系列 DSP 也提供了栅栏指令 (MFENCE) 来处理缓存回写, 强制或阻止一致性操作的执行等, 方便程序员管理数据一致性。
4、硬件化的带宽管理防止运行阻塞
DSP 核中还设置了硬件化带宽管理, 负责管理一级数据缓存 (L1D)、一级程序缓存 (L1P)、二级缓存 (L2)、寄存器配置总线等 4 类资源的访问优先级。 访问发起方包括 DSP、外部 DMA (enhanced direct memory access, EDMA)、内部 DMA (internal direct memory access, IDMA)、数据一致性操作。
管理按照每次访问授予优先级, 而不是按照访问类型固定优先级, 通过设置竞争强度计数器来反映对资源的 “饥渴” 程度, 即便是最低优先级的访问, 随着等待时间增加, 优先级就会逐渐升高, 当达到最长等待周期数, 就会强制授予一次访问。 而这些都是硬件管理的, 程序员只能设置最长等待时间, 不能设置竞争计数器。 这样的硬件化维护资源公平性的设置在 CPU 中并不常见。
由以上分析可以看出, DSP 作为一类典型的专用处理器, 其结构与数字信号处理需要丰富的 IO接口便于集成, 强大的浮点处理能力支持高带宽的信号处理, 还提供了丰富的底层数据通路的控制手段方便专业用户的性能调优。
编辑:黄飞












 工商网监
工商网监
评论