 电子发烧友App
电子发烧友App


Ascend310 AI处理器逻辑架构昇腾AI处理器的主要架构组成:芯片系统控制CPU(Control CPU)AI计算引擎(包括AI Core和AI CPU)多层级的片上系统缓存(Cache)或缓冲区(Buffer)数字视觉预处理模块(Digital Vision Pre-Processing,DVPP)等AI Core:集成了2个AI Core。
下载链接:
Ascend310 AI处理器规格
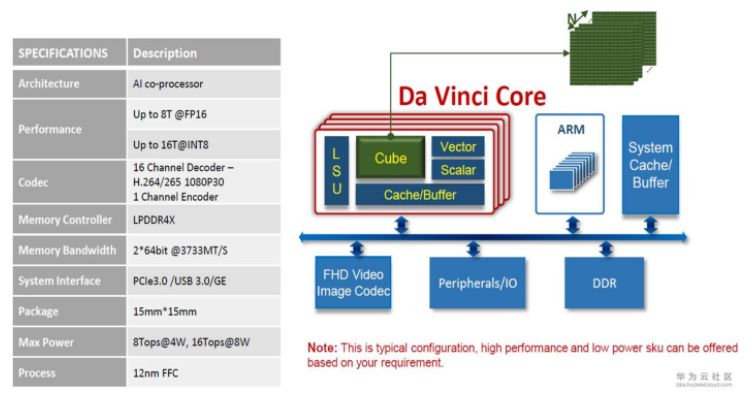
Ascend310 AI处理器逻辑架构
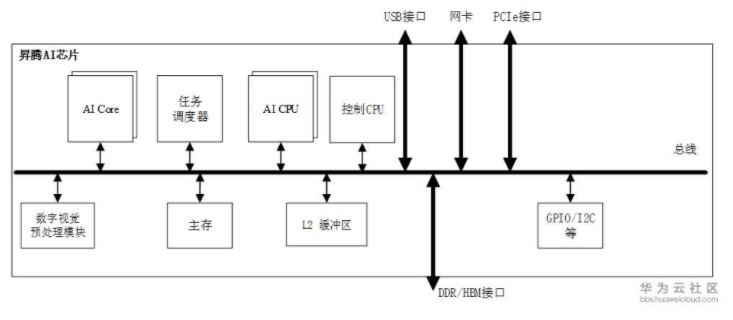
昇腾AI处理器本质上是一个片上系统(System on Chip,SoC),主要可以应用在和图像、视频、语音、文字处理相关的应用场景。其主要的架构组成部件包括特制的计算单元、大容量的存储单元和相应的控制单元。该芯片大致可以划为:芯片系统控制CPU(Control CPU),AI计算引擎(包括AI Core和AI CPU),多层级的片上系统缓存(Cache)或缓冲区(Buffer),数字视觉预处理模块(Digital Vision Pre-Processing,DVPP)等。芯片可以采用LPDDR4高速主存控制器接口,价格较低。目前主流SoC芯片的主存一般由DDR(Double Data Rate)或HBM(High Bandwidth Memory)构成,用来存放大量的数据。HBM相对于DDR存储带宽较高,是行业的发展方向。其它通用的外设接口模块包括USB、磁盘、网卡、GPIO、I2C和电源管理接口等。
昇腾AI处理器的主要架构组成:
芯片系统控制CPU(Control CPU)
AI计算引擎(包括AI Core和AI CPU)
多层级的片上系统缓存(Cache)或缓冲区(Buffer)
数字视觉预处理模块(Digital Vision Pre-Processing,DVPP)等
AI Core:集成了2个AI Core。昇腾AI芯片的计算核心,主要负责执行矩阵、向量、标量计算密集的算子任务,采用达芬奇架构。
ARM CPU核心:集成了8个A55。其中一部分部署为AI CPU,负责执行不适合跑在AI Core上的算子(承担非矩阵类复杂计算);一部分部署为专用于控制芯片整体运行的控制CPU。两类任务占用的CPU核数可由软件根据系统实际运行情况动态分配。此外,还部署了一个专用CPU作为任务调度器(Task Scheduler,TS),以实现计算任务在AI Core上的高效分配和调度;该CPU专门服务于AI Core和AI CPU,不承担任何其他的事务和工作。
DVPP:数字视觉预处理子系统,完成图像视频的编解码。用于将从网络或终端设备获得的视觉数据,进行预处理以实现格式和精度转换等要求,之后提供给AI计算引擎。
Cache & Buffer:SOC片内有层次化的memory结构,AI core内部有两级memory buffer,SOC片上还有8MB L2 buffer,专用于AI Core、AI CPU,提供高带宽、低延迟的memory访问。芯片还集成了LPDDR4x控制器,为芯片提供更大容量的DDR内存。
对外接口:支持PCIE3.0、RGMII、USB3.0等高速接口、以及GPIO、UART、I2C、SPI等低速接口。
昇腾AI处理器集成了多个ARM公司的CPU核心,每个核心都有独立的L1和L2缓存,所有核心共享一个片上L3缓存。集成的CPU核心按照功能可以划分为专用于控制芯片整体运行的主控CPU 和专用于承担非矩阵类复杂计算的AI CPU。两类任务占用的CPU核数可由软件根据系统实际运行情况动态分配。
除了CPU之外,该芯片真正的算力担当是采用了达芬奇架构的AI Core。这些AI Core通过特别设计的架构和电路实现了高通量、大算力和低功耗,特别适合处理深度学习中神经网络必须的常用计算如矩阵相乘等。目前该芯片能对整型数(INT8、INT4) 或对浮点数(FP16)提供强大的乘加计算力。由于采用了模块化的设计,可以很方便的通过叠加模块的方法提高后续芯片的计算力。
针对深度神经网络参数量大、中间值多的特点,该芯片还特意为AI计算引擎配备了容量为8MB的片上缓冲区(On-Chip Buffer),提供高带宽、低延迟、高效率的数据交换和访问。能够快速访问到所需的数据对于提高神经网络算法的整体性能至关重要,同时将大量需要复用的中间数据缓存在片上对于降低系统整体功耗意义重大。为了能够实现计算任务在AI Core上的高效分配和调度,还特意配备了一个专用CPU作为任务调度器(Task Scheduler,TS)。该CPU专门服务于AI Core和AI CPU,而不承担任何其他的事务和工作。
数字视觉预处理模块主要完成图像视频的编解码,支持4K分辨率,视频处理,对图像支持JPEG和PNG等格式的处理。来自主机端存储器或网络的视频和图像数据,在进入昇腾AI芯片的计算引擎处理之前,需要生成满足处理要求的输入格式、分辨率等,因此需要调用数字视觉预处理模块进行预处理以实现格式和精度转换等要求。数字视觉预处理模块主要实现视频解码(Video Decoder,VDEC),视频编码(Video Encoder,VENC),JPEG编解码(JPEG Decoder/Encoder,JPEGD/E),PNG解码(PNG Decoder,PNGD)和视觉预处理(Vision Pre-Processing Core,VPC)等功能。图像预处理可以完成对输入图像的上/下采样、裁剪、色调转换等多种功能。
开发者在利用昇腾硬件进行神经网络模型训练或者推理的过程中,可能会遇到以下场景:
训练场景下,将第三方框架(例如TensorFlow、PyTorch等)的网络训练脚本迁移到昇腾AI处理器时遇到了不支持的算子。
推理场景下,将第三方框架模型(例如TensorFlow、Caffe、ONNX等)使用ATC工具转换为适配昇腾AI处理器的离线模型时遇到了不支持的算子。
网络调优时,发现某算子性能较低,影响网络性能,需要重新开发一个高性能算子替换性能较低的算子。
推理场景下,应用程序中的某些逻辑涉及到数学运算(例如查找最大值,进行数据类型转换等),希望通过自定义算子的方式实现这些逻辑,从而获得性能提升。
此时我们就需要考虑进行自定义算子的开发,本期我们主要带您了解CANN自定义算子的几种开发方式和基本开发流程,让您对CANN算子有宏观的了解。
一、算子基本概念
相信大家对算子的概念并不陌生,这里我们来做简单回顾。深度学习算法由一个个计算单元组成,我们称这些计算单元为算子(Operator,简称OP)。
在网络模型中,算子对应层中的计算逻辑,例如:卷积层(Convolution Layer)是一个算子;全连接层(Fully-connected Layer, FC layer)中的权值求和过程,是一个算子。
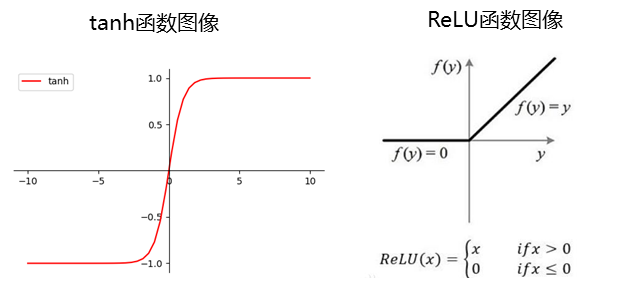
再例如:tanh、ReLU等,为在网络模型中被用做激活函数的算子。
二、CANN自定义算子开发方式
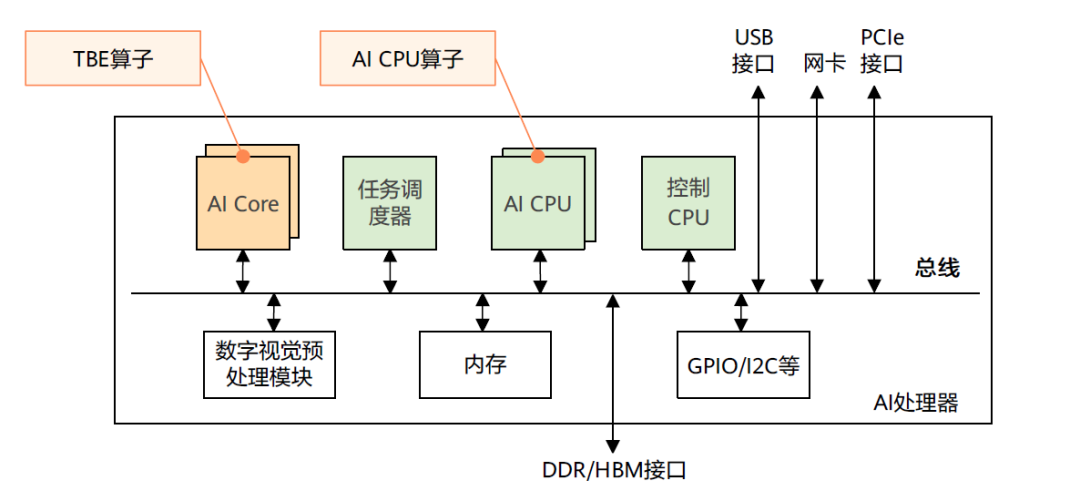
学习CANN自定义算子开发方式之前,我们先来了解一下CANN算子的运行位置:包括AI Core和AI CPU。
AI Core是昇腾AI处理器的计算核心,负责执行矩阵、向量、标量计算密集的算子任务。
AI CPU负责执行不适合跑在AI Core上的算子,是AI Core算子的补充,主要承担非矩阵类、逻辑比较复杂的分支密集型计算。
CANN支持用户使用多种方式来开发自定义算子,包括TBE DSL、TBE TIK、AICPU三种开发方式。其中TBE DSL、TBE TIK算子运行在AI Core上,AI CPU算子运行在AI CPU上。
1. 基于TBE开发框架的算子开发
TBE(Tensor Boost Engine:张量加速引擎)是CANN提供的算子开发框架,开发者可以基于此框架使用Python语言开发自定义算子,通过TBE进行算子开发有TBE DSL、TBE TIK两种方式。
TBE DSL(Domain-Specific Language ,基于特性域语言)开发方式
为了方便开发者进行自定义算子开发,CANN预先提供一些常用运算的调度,封装成一个个运算接口,称为基于TBE DSL开发。DSL接口已高度封装,用户仅需要使用DSL接口完成计算过程的表达,后续的算子调度、算子优化及编译都可通过已有的接口一键式完成,适合初级开发用户。
TBE TIK(Tensor Iterator Kernel)开发方式
TIK(Tensor Iterator Kernel)是一种基于Python语言的动态编程框架,呈现为一个Python模块,运行于Host CPU上。开发者可以通过调用TIK提供的API基于Python语言编写自定义算子,TIK编译器会将其编译为昇腾AI处理器应用程序的二进制文件。
TIK需要用户手工控制数据搬运和计算流程,入门较高,但开发方式比较灵活,能够充分挖掘硬件能力,在性能上有一定的优势。
2. AI CPU算子开发方式
AI CPU算子的开发接口即为原生C++接口,具备C++程序开发能力的开发者能够较容易的开发出AI CPU算子。AI CPU算子在AI CPU上运行。
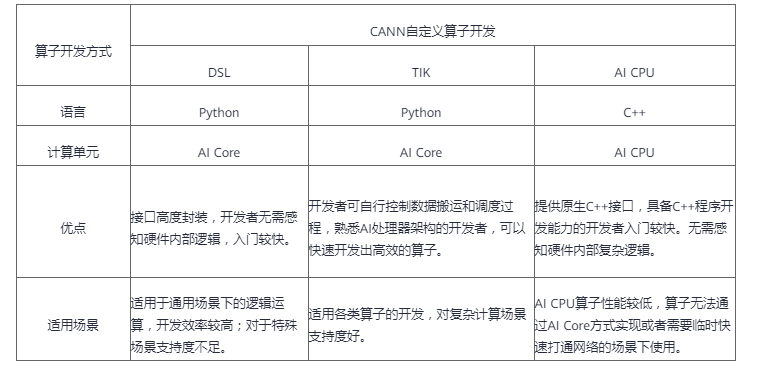
下面的开发方式一览表,对上述几种开发方式作对比说明,您可以根据各种开发方式的适用场景选择适合的开发方式。
三、CANN算子编译运行
算子构成
一个完整的CANN算子包含四部分: 算子原型定义、对应开源框架的算子适配插件、算子信息库和算子实现。 这四个组成部分会在算子编译运行的过程中使用。
算子编译
推理场景下,进行模型推理前,我们需要使用ATC模型转换工具将原始网络模型转换为适配昇腾AI处理器的离线模型,该过程中会对网络中的算子进行编译。
训练场景下,当我们跑训练脚本时,CANN内部实现逻辑会先将开源框架网络模型下发给Graph Engine进行图编译,该过程中会对网络中的算子进行编译。
CANN算子的编译逻辑架构如下:
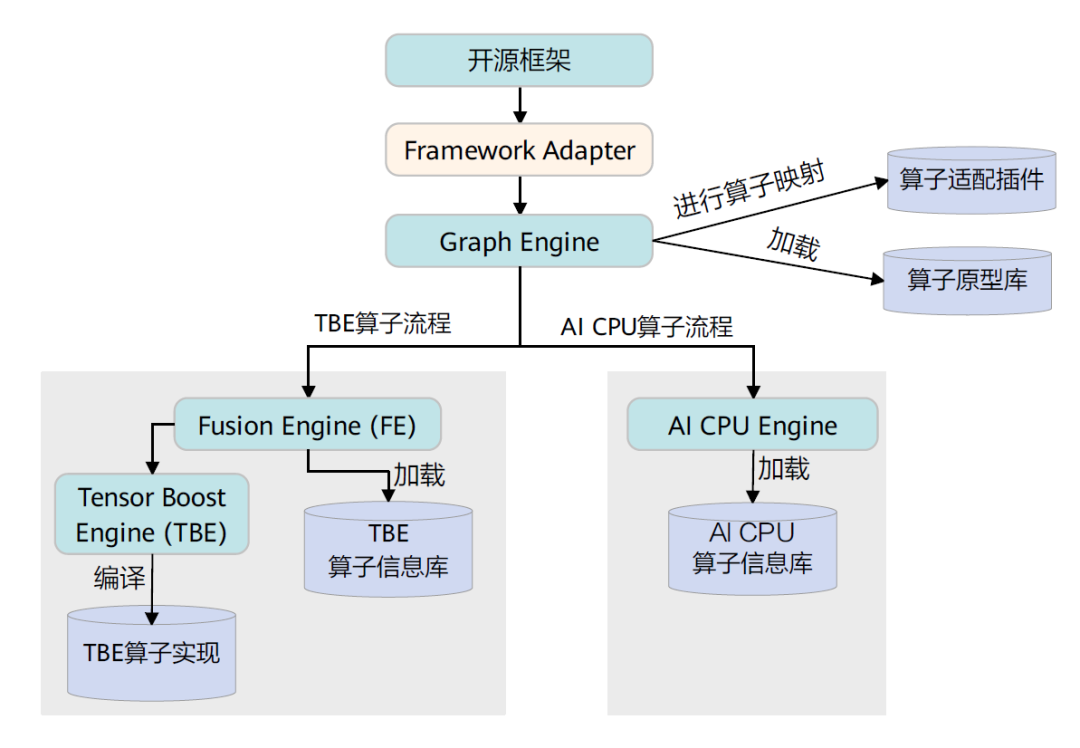
具体的CANN算子编译流程如下,在编译流程中会用到上文提到的算子的四个组成部分。
Graph Engine调用 算子插件 ,将原始网络模型中的算子映射为适配昇腾AI处理器的算子,从而将原始开源框架图解析为适配昇腾AI处理器的图。
调用算子原型库校验接口进行基本参数的校验,校验通过后,会根据原型库中的推导函数推导每个节点的输出shape与dtype,进行输出tensor的静态内存的分配。
Graph Engine根据图中数据将图拆分为子图并下发给FE。FE在处理过程中根据算子信息库中算子信息找到 算子实现 ,将其编译成算子kernel,最后将优化后子图返回给Graph Engine。
Graph Engine进行图编译,包含内存分配、流资源分配等,并向FE发送tasking请求,FE返回算子的taskinfo信息给Graph Engine,图编译完成后生成适配昇腾AI处理器的模型。
算子运行
推理场景下,使用ATC模型转换工具将原始网络模型转换为适配昇腾AI处理器的离线模型后,开发AscendCL应用程序,加载转换好的离线模型文件进行模型推理,该过程中会进行算子的调用执行。
训练场景下,当我们跑训练脚本时,内部实现逻辑将开源框架网络模型下发给Graph Engine进行图编译后,后续的训练流程会进行算子的调用执行。
CANN算子的运行逻辑架构如下:
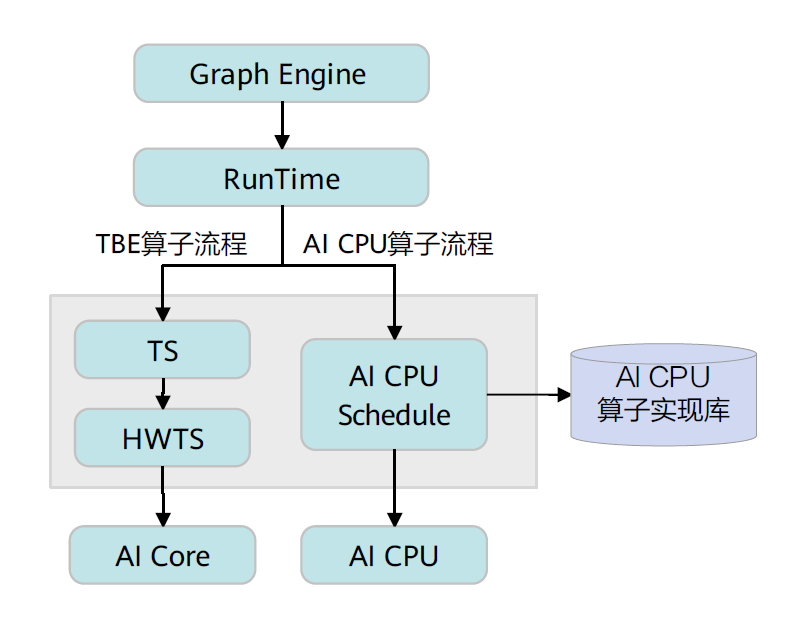
具体流程如下,首先Graph Engine下发算子执行请求给Runtime,然后Runtime会判断算子的Task类型,若是TBE算子,则将算子执行请求下发到AI Core上执行;若是AI CPU算子,则将算子执行请求下发到AI CPU上执行。
审核编辑:汤梓红
















 工商网监
工商网监
评论