 电子发烧友App
电子发烧友App


Nvidia 今天宣布,已向最新版本的 MLPerf 提交了其 Grace Hopper CPU+GPU Superchip 及其 L4 GPU 加速器的首个基准测试结果,MLPerf 是一项行业标准 AI 基准测试,旨在为衡量人工智能性能提供一个公平的竞争环境。不同的工作负载。今天的基准测试结果标志着 MLPerf 基准测试的两个值得注意的新第一:添加了新的大型语言模型 (LLM) GPT-J 推理基准测试和改进的推荐模型。Nvidia 声称,在 GPT-J 基准测试中,Grace Hopper Superchip 的推理性能比其市场领先的 H100 GPU 之一高出 17%,并且其 L4 GPU 的性能高达英特尔 Xeon CPU 的 6 倍。
随着该行业迅速发展到更新的人工智能模型和更强大的实施,该行业正在以惊人的速度发展。同样,由 MLCommons 机构管理的 MLPerf 基准也在不断发展,以通过新的 v3.1 修订版更好地反映人工智能领域不断变化的性质。
GPT-J 6B 是自 2021 年以来在现实工作负载中使用的文本摘要模型,现已在 MLPerf 套件中用作衡量推理性能的基准。与一些更先进的人工智能模型(例如 1750 亿参数的 GPT-3)相比,GPT-J 60 亿参数的 LLM 相当轻量,但它非常适合推理基准的角色。该模型总结了文本块,并在对延迟敏感的在线模式和吞吐量密集型的离线模式下运行。MLPerf 套件现在还采用了更大的 DLRM-DCNv2 推荐模型(参数数量增加了一倍)、更大的多热点数据集以及能够更好地表示真实环境的跨层算法。
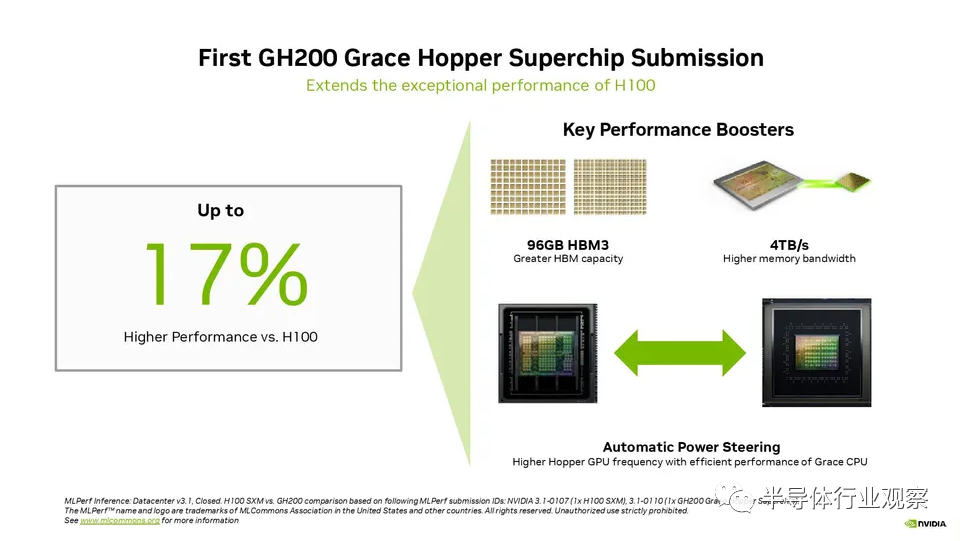
有了这个背景,我们可以在这里看到 Nvidia 的一些性能声明。请注意,Nvidia 本身将这些基准提交给 MLCommons,因此它们可能代表高度调整的最佳情况。
Nvidia 还喜欢指出,它是唯一一家为 MLPerf 套件中使用的每个 AI 模型提交基准的公司,这是一个客观真实的声明。有些公司完全缺席,比如 AMD,或者只提交了一些选定的基准测试,比如英特尔的 Habana 和谷歌的 TPU。缺乏提交的原因因公司而异,但看到更多竞争对手加入 MLPerf 圈就太好了。
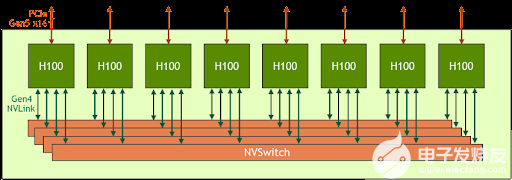
Nvidia 提交了第一个 GH200 Grace Hopper Superchip MLPerf 结果,强调 CPU+GPU 组合的性能比单个 H100 GPU 高出 17%。从表面上看,这令人惊讶,因为 GH200 使用与 H100 CPU 相同的芯片,但我们将在下面解释原因。自然,配备 8 个 H100 的 Nvidia 系统的性能优于 Grace Hopper Superchip,在每项推理测试中都处于领先地位。
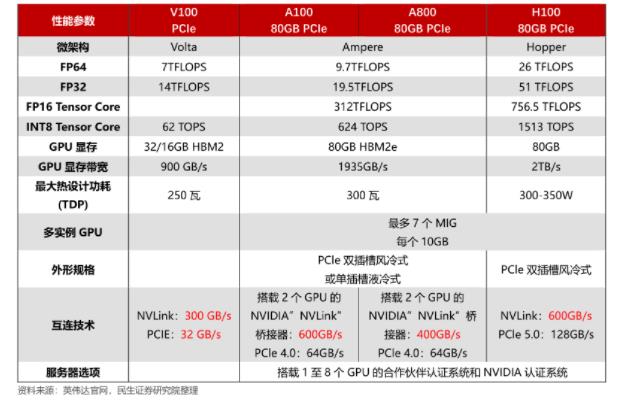
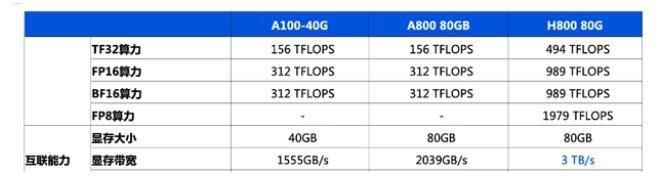
提醒一下,Grace Hopper Superchip 在同一块板上结合了 Hopper GPU 和 Grace CPU,在两个单元之间提供了具有 900GB/s 吞吐量的C2C 链路,从而提供了典型 PCIe 带宽的 7 倍CPU 到 GPU 数据传输的连接,提高了 GH200 的可访问内存带宽,并通过包含 96GB HBM3 内存和 4TB/s GPU 内存带宽的连贯内存池进行了增强。相比之下,在 HGX 中测试的对比 H100 仅具有 80GB 的 HBM3 (下一代 Grace Hopper 型号将在 2024 年第二季度拥有 144GB 的 HBM3e,速度快 1.7 倍)。
Nvidia 还推出了一种名为“ Automatic Power Steering”的动态动力转移技术,该技术可以动态平衡 CPU 和 GPU 之间的功率预算,将溢出预算转向负载最大的单元。这项技术被用于许多竞争性的现代 CPU+GPU 组合中,因此它并不新鲜,但它确实允许 Grace Hopper Superchip 上的 GPU 享受比 HGX 更高的电力传输预算,因为电力从Grace CPU——这在标准服务器中是不可能的。完整的 CPU+GPU 系统以 1000W TDP 运行。
大多数推理继续在 CPU 上执行,随着更大的模型变得越来越普遍,这种情况在未来可能会发生变化;对于 Nvidia 来说,用 L4 等小型低功耗 GPU 取代用于这些工作负载的 CPU 至关重要,因为这将推动大批量销售。本轮 MLPerf 提交还包括 Nvidia L4 GPU 的第一批结果,该推理优化卡在 GPT-J 推理基准测试中的性能是单个 Xeon 9480 的 6 倍,尽管在超薄外形卡中功耗仅为 72W,不需要辅助电源连接。
Nvidia 还声称,通过测量 8 个 L4 GPU 与两个上一代 Xeon 8380s CPU 的性能,视频+AI 解码-推理-编码工作负载的 CPU 性能提高了 120 倍,这有点不平衡。这可能是为了直接比较单个机箱中可以容纳的计算能力。尽管如此,值得注意的是,尽管四路服务器不是最适合这项工作,但仍然可以使用,而且较新的至强芯片在本次测试中可能会表现得更好一些。测试配置位于幻灯片底部的小字中,因此请务必注意这些细节。
最后,Nvidia 还提交了 Jetson Orin 机器人芯片的基准测试,显示推理吞吐量提高了 84%,这主要是由软件改进推动的。
重要的是要记住,在现实世界中,每个人工智能模型都作为较长系列模型的一部分运行,这些模型在人工智能管道中执行以完成特定的工作或任务。Nvidia 的上面的插图很好地体现了这一点,在完成之前对一个查询执行八种不同的 AI 模型 - 并且这些类型的 AI 管道扩展至 15 个网络来满足单个查询并不是闻所未闻的。这是重要的背景,因为上面的面向吞吐量的基准往往侧重于以高利用率运行单个 AI 模型,而不是现实世界的管道,需要更多的多功能性,多个 AI 模型串行运行才能完成给定的任务任务。
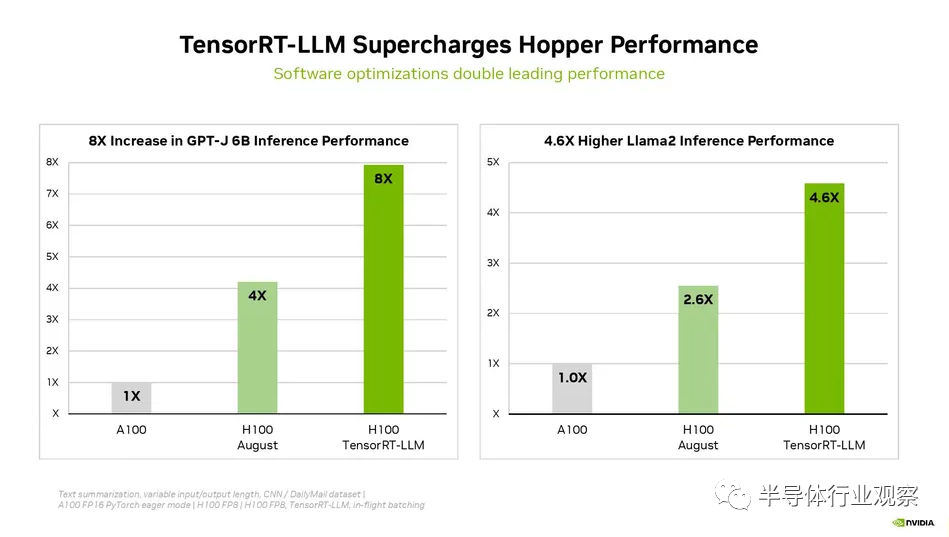
Nvidia 上周还宣布,其用于生成 AI 工作负载的 TensorRT-LLM 软件可在推理工作负载中提供优化的性能,在 H100 GPU 上使用时总体性能提高一倍以上,且无需增加成本。Nvidia 最近提供了有关该软件的详细信息,并指出它还没有为这一轮结果准备好这种推理增强软件;MLCommons 要求 MLPerf 提交需要 30 天的准备时间,而 TensorRT-LLM 当时不可用。这意味着 Nvidia 的首轮 MLPerf 基准测试应该会在下一轮提交中看到巨大的改进。
Nvidia Grace Hopper CPU的设计详解
正如我们在之前的报道中指出,Nvidia 的 Grace CPU 是该公司第一款专为数据中心设计的纯 CPU Arm 芯片,一块主板上有两个芯片,总共 144 个核心,而 Grace Hopper Superchip 则在主板上结合了 Hopper GPU 和 Grace CPU。
根据Nvidia之前透露,Grace CPU采用台积电4N工艺。台积电将“N4”4nm工艺列入其5nm节点家族之下,将其描述为5nm节点的增强版。Nvidia 使用该节点的一种特殊变体,称为“4N”,专门针对其 GPU 和 CPU 进行了优化。
随着摩尔定律的衰落,这些类型的专用节点变得越来越普遍,并且随着每个新节点的出现,缩小晶体管变得更加困难和昂贵。为了实现 Nvidia 4N 等定制工艺节点,芯片设计人员和代工厂携手合作,使用设计技术协同优化 (DTCO) 为其特定产品调整定制功耗、性能和面积 (PPA) 特性。
Nvidia 此前曾透露,其 Grace CPU 使用现成的 Arm Neoverse 内核,但该公司仍未具体说明使用哪个具体版本。不过,Nvidia透露Grace采用Arm v9内核,支持SVE2、Neoverse N2平台是 Arm 第一个支持 Arm v9 和 SVE2 等扩展的 IP。N2 Perseus 平台采用 5nm 设计(请记住,N4 属于台积电的 5nm 系列),支持 PCIe Gen 5.0、DDR5、HBM3、CCIX 2.0 和 CXL 2.0。Perseus 设计针对每功率(瓦特)性能和每面积性能进行了优化。Arm 表示,其下一代核心 Poseidon 直到 2024 年才会上市,考虑到 Grace 的发布日期为 2023 年初,这些核心的可能性较小。
Nvidia 的新 Nvidia 可扩展一致性结构 (SCF:Nvidia Scalable Coherency Fabric ) 是一种网状互连,看起来与与 Arm Neoverse 核心一起使用的标准CMN-700 相干网状网络非常相似。
Nvidia SCF 在各种 Grace 芯片单元(如 CPU 内核、内存和 I/O)之间提供 3.2 TB/s 的对分带宽,更不用说将芯片与其他单元连接起来的 NVLink-C2C 接口了。无论是另一个 Grace CPU 还是 Hopper GPU。
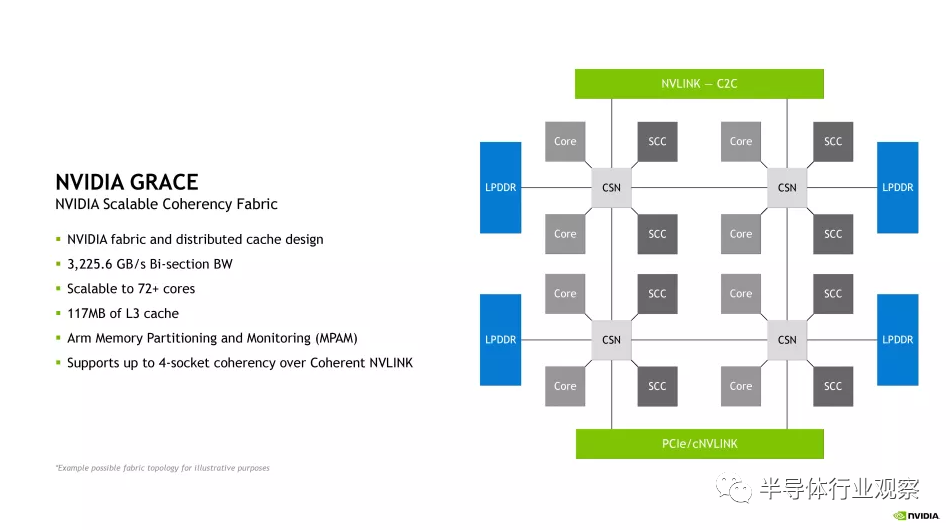
该网格支持 72 个以上核心,每个 CPU 总 L3 缓存为 117MB。Nvidia 表示,上面专辑中的第一个框图是“用于说明目的的可能拓扑”,其对齐方式与第二个图并不完全一致。
该图显示了具有八个 SCF 缓存分区 (SCC:SCF Cache partitions ) 的芯片,这些分区似乎是 L3 缓存片(我们将在演示中了解更多详细信息)以及八个 CPU 单元(这些似乎是核心集群)。SCC 和内核以两个为一组连接到缓存交换节点 (CSN),然后 CSN 驻留在 SCF 网状结构上,以提供 CPU 内核和内存与芯片其余部分之间的接口。SCF 还通过 Coherent NVLink 支持最多四个插槽的一致性。
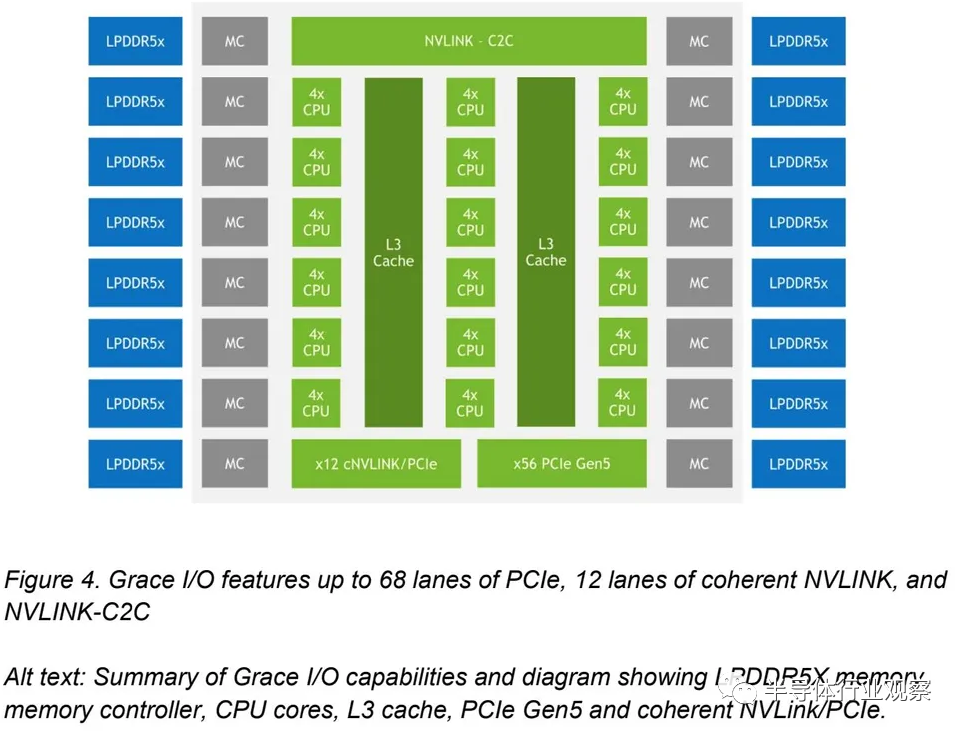
Nvidia 还分享了这张图,显示每个 Grace CPU 支持最多 68 个 PCIe 通道和最多 4 个 PCIe 5.0 x16 连接。每个 x16 连接支持高达 128 GB/s 的双向吞吐量(x16 链路可以分为两个 x8 链路)。我们还看到了 16 个双通道 LPDDR5X 内存控制器 (MC)。
然而,此图与第一个图不同,它将 L3 缓存显示为连接到四核 CPU 集群的两个连续块,这比之前的图更有意义,并且芯片中总共有 72 个核心。但是,我们在第一个图中没有看到单独的 SCF 分区或 CSN 节点,这造成了一些混乱。我们将在演示期间解决这个问题,并根据需要进行更新。
Nvidia 告诉我们,可扩展一致性结构 (SCF) 是其专有设计,但 Arm 允许其合作伙伴通过调整核心数量、缓存大小以及使用不同类型的内存(例如 DDR5 和 HBM)来定制 CMN-700 网格,以及选择各种接口,例如 PCIe 5.0、CXL 和 CCIX。这意味着 Nvidia 可能会为片上结构使用高度定制的 CMN-700 实现。
GPU 喜欢内存吞吐量,因此 Nvidia 自然而然地将目光转向提高内存吞吐量,不仅限于芯片内部,还包括 CPU 和 GPU 之间的内存吞吐量。Grace CPU 具有 16 个双通道 LPDDR5X 内存控制器,最多可支持 32 个通道,支持高达 512 GB 的内存和高达 546 GB/s 的吞吐量。Nvidia 表示,由于容量和成本等多种因素,它选择了 LPDDR5X 而不是 HBM2e。同时,与标准 DDR5 内存相比,LPDDR5X 的带宽增加了 53%,每 GB 功耗降低了 1/8,使其成为更好的整体选择。
Nvidia 还推出了扩展 GPU 内存 (EGM),它允许 NVLink 网络上的任何 Hopper GPU 访问网络上任何 Grace CPU 的 LPDDR5X 内存,但保持本机 NVLink 性能。
Nvidia的目标是提供一个可以在CPU和GPU之间共享的统一内存池,从而提供更高的性能,同时简化编程模型。Grace Hopper CPU+GPU 芯片支持具有共享页表的统一内存,这意味着芯片可以与 CUDA 应用程序共享地址空间和页表,并允许使用系统分配器来分配 GPU 内存。它还支持 CPU 和 GPU 之间的native atomics。
CPU 核心是计算引擎,但互连是定义计算未来的战场。移动数据比实际计算数据消耗更多的电量,因此更快、更有效地移动数据,甚至避免数据传输,是一个关键目标。
Nvidia 的Grace CPU在一块板上由两个 CPU 组成,而 Grace Hopper Superchip 在同一块板上由一个 Grace CPU 和一个 Hopper GPU 组成,旨在通过专有的 NVLink 芯片最大限度地提高单元之间的数据传输。芯片间 (C2C) 互连并提供内存一致性,以减少或消除数据传输。

Nvidia 分享了有关其 NVLink-C2C 互连的新细节。提醒一下,这是一种芯片到芯片和芯片到芯片互连,支持内存一致性,可提供高达 900 GB/s 的吞吐量(是 PCIe 5.0 x16 链路带宽的 7 倍)。该接口使用 NVLink 协议,Nvidia 使用其 SERDES 和 LINK 设计技术设计了该接口,重点关注能源和面积效率。物理 C2C 接口跨标准 PCB 运行,因此不使用专门的中介层。
NVLink-C2C 还支持行业标准协议,例如 CXL 和 Arm 的 AMBA 相干集线器接口(CHI — Neoverse CMN-700 网格的关键)。它还支持多种类型的连接,从基于 PCB 的互连到硅中介层和晶圆级实现。
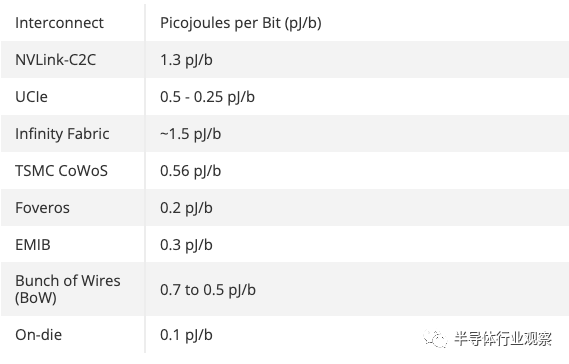
电源效率是所有数据结构的一个关键指标,今天 Nvidia 表示,传输的数据每比特 (pJ/b) 链路消耗 1.3 皮焦耳 (pJ/b)。这是 PCIe 5.0 接口效率的 5 倍,但它的功率是未来将上市的 UCIe 互连的两倍多(0.5 至 0.25 pJ/b)。封装类型各不相同,C2C 链路为 Nvidia 的特定用例提供了性能和效率的坚实结合,但正如您在上表中看到的,更高级的选项可提供更高水平的功效。
Nvidia 将H100 推理性能提高一倍的秘诀
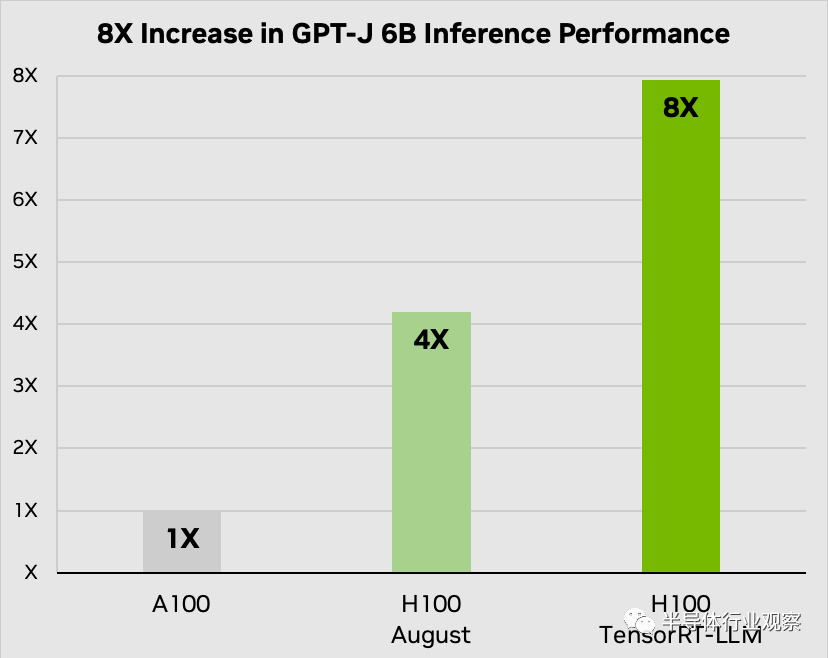
Nvidia 表示,其新的 TensorRT -LL开源软件可以显着提高 GPU 上大型语言模型 (LLM) 的性能。据该公司称,Nvidia TensorRT-LL 的功能使其 H100 计算 GPU 在具有 60 亿个参数的 GPT-J LLM 中的性能提高了两倍。重要的是,该软件可以实现这种性能改进,而无需重新训练模型。
Nvidia 专门开发了 TensorRT-LLM,以提高 LLM 推理的性能,Nvidia 提供的性能图形确实显示,由于适当的软件优化,其 H100 的速度提升了 2 倍。Nvidia TensorRT-LLM 的一个特别突出的功能是其创新的动态批处理技术。该方法解决了LLM动态且多样化的工作负载,这些工作负载的计算需求可能存在很大差异。
动态批处理优化了这些工作负载的调度,确保 GPU 资源得到最大程度的利用。因此,H100 Tensor Core GPU 上的实际 LLM 请求吞吐量翻倍,从而实现更快、更高效的 AI 推理过程。
Nvidia 表示,其 TensorRT-LLM 将深度学习编译器与优化的内核、预处理和后处理步骤以及多 GPU/多节点通信原语集成在一起,确保它们在 GPU 上更高效地运行。这种集成得到了模块化 Python API 的进一步补充,它提供了一个开发人员友好的界面,可以进一步增强软件和硬件的功能,而无需深入研究复杂的编程语言。例如,MosaicML 在 TensorRT-LLM 之上无缝添加了所需的特定功能,并将它们集成到其推理服务中。
Databricks 工程副总裁 Naveen Rao 表示:“TensorRT-LLM 易于使用,功能齐全,包括令牌流、动态批处理、分页注意力、量化等,而且效率很高。” “它为使用 NVIDIA GPU 的LLM服务提供了最先进的性能,并使我们能够将节省的成本回馈给我们的客户。”
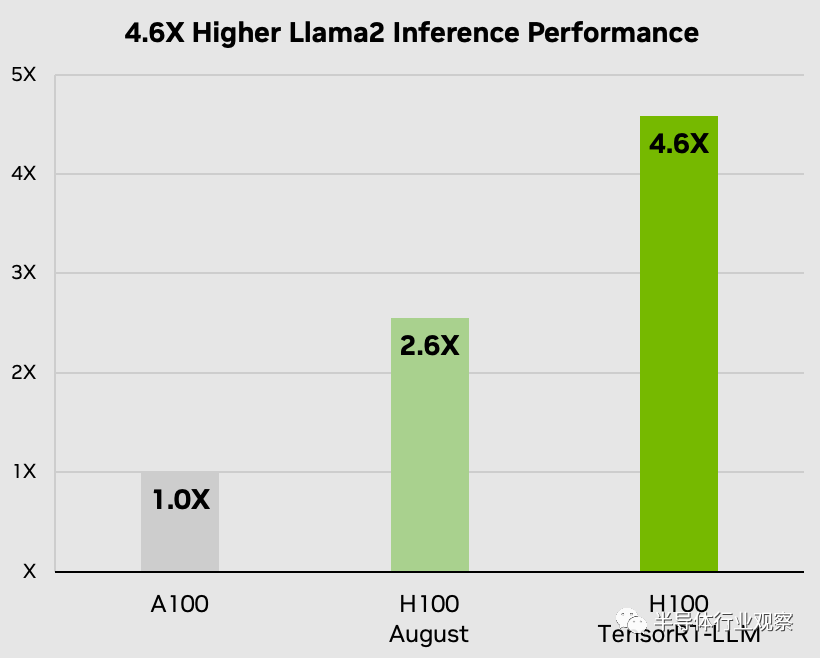
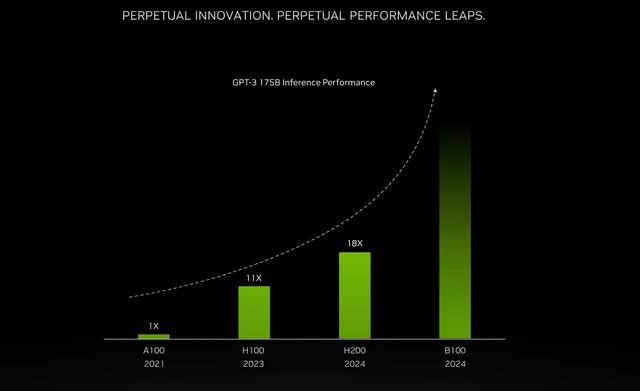
Nvidia H100 与 TensorRT-LLM 结合使用时的性能令人印象深刻。在 NVIDIA 的 Hopper 架构上,H100 GPU 与 TensorRT-LLM 配合使用时,性能是 A100 GPU 的八倍。此外,在测试 Meta 开发的 Llama 2 模型时,TensorRT-LLM 的推理性能比 A100 GPU 提高了 4.6 倍。这些数字强调了该软件在人工智能和机器学习领域的变革潜力。
最后,H100 GPU 与 TensorRT-LLM 结合使用时支持 FP8 格式。此功能可以减少内存消耗,而不会损失模型准确性,这对于预算和/或数据中心空间有限且无法安装足够数量的服务器来调整其 LLM 的企业来说是有益的。
编辑:黄飞




























 工商网监
工商网监
评论