 电子发烧友App
电子发烧友App


前言:这次是酷睿Ultra 不是14代酷睿
8月底去了趟马来西亚,一方面参观了Intel位于马来西亚槟城、居林的封测工厂、实验室,另一方面参加了Meteor Lake技术分享,全面了解了第一代酷睿Ultra处理器的架构设计、技术特性。
现在,终于可以和大家分享了!
首先再“科普”一下1代酷睿Ultra、14代酷睿的关系,因为Intel这次的产品和命名体系确实有点混乱,别说普通玩家,很多业内人士也一直分不清……
今年6月15日,Intel正式公布了全新的酷睿Ultra品牌,第一代产品代号Meteor Lake,采用全新的Intel 4制造工艺和封装技术、全新的分离式模块化架构、全新的CPU架构与3D高性能混合架构、全新的锐炫GPU核显、全新的NPU AI引擎,可以说是Intel第一颗微处理器4004 1971年诞生以来,变革最大的一代。
不过比较可惜,Intel 4工艺第一次登场和之前的14nm、10nm有些类似,性能上还未达到足够高的水准,所以只能用于笔记本移动平台的主流H系列、低功耗P系列,分为酷睿Ultra 9/7/5三个子系列。
对于桌面S系列、顶级游戏本HX系列,将在原有Raptor Lake 13代酷睿的基础上进行升级,包括增加E核并扩大缓存、提升频率、加速内存等,也就是Raptor Lake Refresh 14代酷睿,继续使用LGA1700接口,继续兼容600/700系列主板,分为酷睿i9/i7/i5/i3四个子系列。
此外,超低功耗的U系列也会是13代酷睿升级版,但命名为一代酷睿(注意没有任何后缀),分为酷睿7/5/3三个子系列。
今天的主角,就是Meteor Lake酷睿Ultra,但这一次,我们只讲它的架构设计、制造和封装工艺、技术特性。
具体的型号命名、规格参数、性能跑分,将在12月14日正式发布的时候公开。
14代酷睿预计还是分为两步走,其中高端的K/KF系列下个月首先登场,主流和低功耗系列大概率也要到CES 2024。
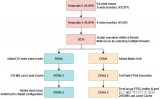
总体架构设计:极具创意、极高效率的分离式模块


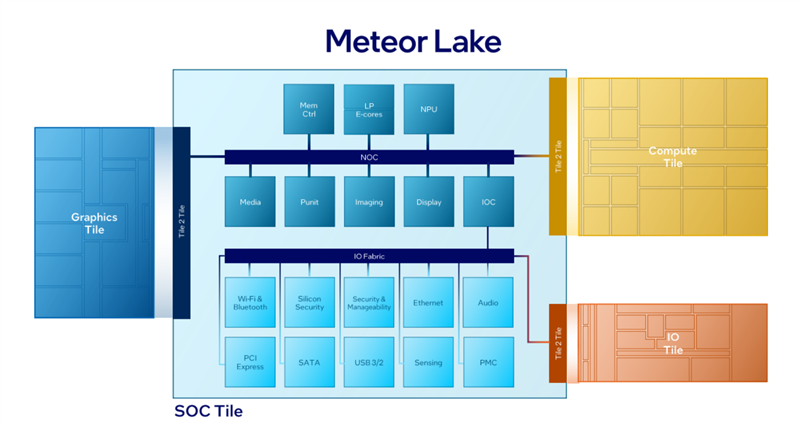
酷睿Ultra处理器是Intel在消费级市场上第一次采用分离式模块化架构,将传统的单芯片一分为四,分别叫做计算模块(Compute Tile)、SoC模块(SoC Tile)、图形模块(GPU Tile)、IO模块(IO Tile),如同搭积木一般。
这其实就是我们已经见过很多次的Chiplet(小芯片/芯粒),Intel Sapphire Rapids第四代可扩展至强处理器、Ponte Vecchio GPU加速器就都是这种设计,AMD更是锐龙、霄龙、Radeon、Instinct全线都在用。
酷睿Ultra当然不是简单粗暴地将整个芯片分开,而是精心地进行了各种优化设计,比如重组计算密集型IP、增加低功耗AI核心、重建电源管理模块、提升IO带宽与扩展性等等,再结合不同的先进制造工艺、封装技术,实现了性能、能效的飞跃。

计算模块,就是CPU核心与缓存,包括最多6个全新Redwood Cove架构的P核(性能核)、最多8个全新Crestmont架构的E核(能效核)。
它首次采用了Intel最先进的Intel 4制造工艺,也是酷睿Ultra四大模块中唯一使用该工艺的。
其他三个模块的具体情况暂未公开,目测大概率是台积电的5-7nm,甚至不排除IO模块使用更成熟的12nm。

图形模块就是核显,升级到了全新的Xe LPG架构,和桌面上的锐炫Arc A系列的Xe HPG架构同宗同源,并针对低功耗做了优化,性能和能效都有了飞跃。
但是,这里只有GPU图形渲染相关单元,以前在一起的媒体引擎、显示引擎都搬到了SoC模块,显示物理层则搬到了IO模块。
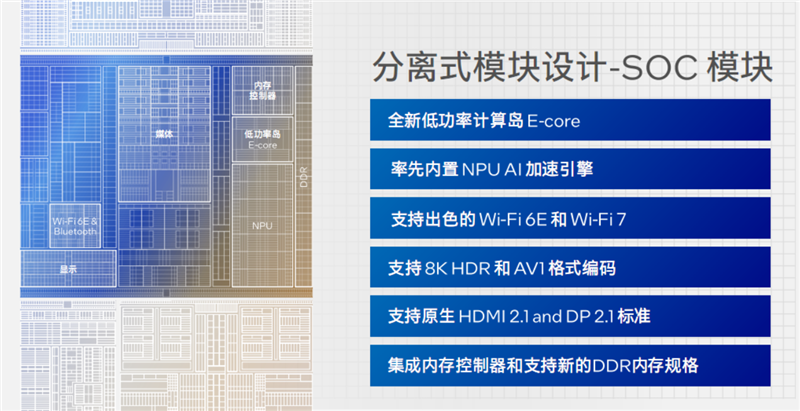

SoC模块不是传统意义上的System on Chip,但同样集成了众多功能模块,包括低功耗E核(LPE)、NPU AI独立引擎、内存控制器、无线控制器、媒体引擎、显示引擎、安全引擎、图像信号处理器、电源管理单元、系统代理、IO缓存(IOC)等等。
尤其是其中的两个低功耗E核,也就是LPE核,和计算模块的P核、E核联合构成了全新的3D高性能混合架构。
这也是Intel 12代酷睿首次引入混合架构之后,最为重大的一次变革。

IO模块当然就是负责输入输出连接了,包括雷电4控制器、PCIe 5.0控制器,但不仅于此。
如前所述,Chiplet设计不是简单地把一颗大芯片拆成多颗小芯片那么简单,需要在多个层面进行新的思考与优化。
首先就是不同芯片、不同功能单元之间的通信如何才能达到最高效率,不能出现“交通拥堵”反而造成通信效率的下降,直接拖累性能。
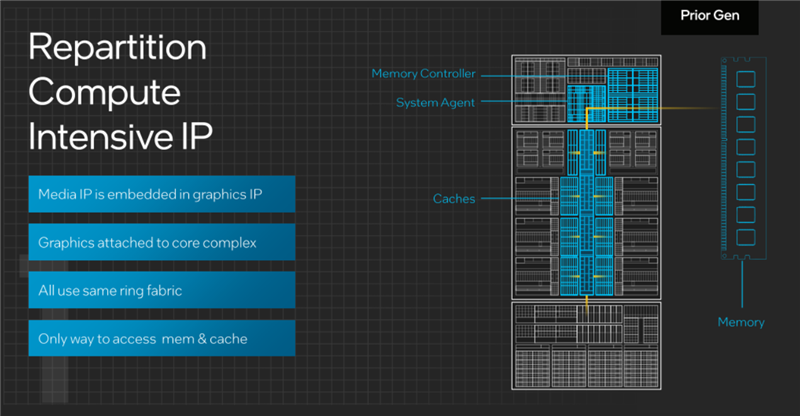
比如在以往的设计中,媒体引擎、显示引擎一直都和图形引擎同时集成于图形模块之中,以至于我们一直默认它们就是一个整体,而且通过同一条环形交叉总线和CPU核心、缓存、内存相连,仿佛“华山一条道”。
但其实,它们都是在不同场景下执行不同的工作,并不需要同时开启,比如看视频和玩游戏就是完全不一样的。
同时,无论图形引擎还是媒体引擎,但它们需要访问内存的时候,CPU核心就不得不都陪着保持开启状态。
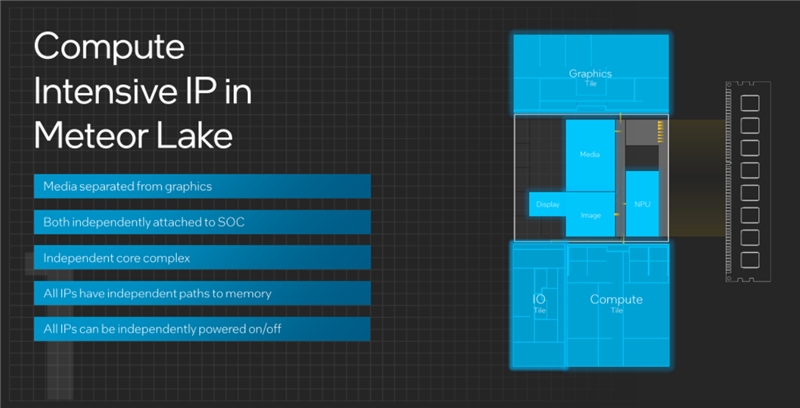
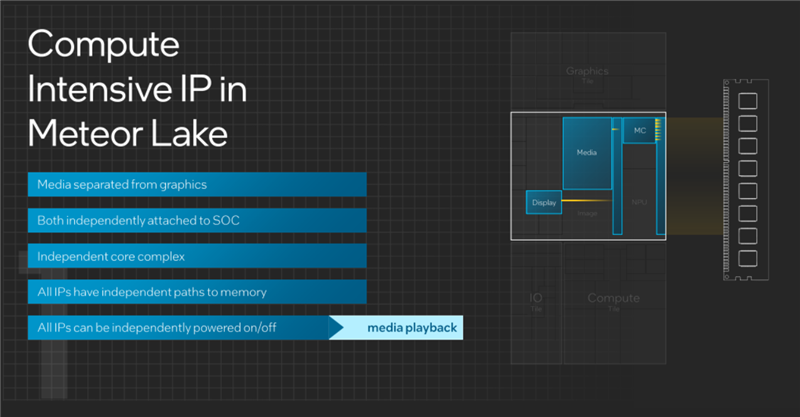
酷睿Ultra将媒体引擎、显示引擎都转移到了SoC模块中,而且彼此是独立的,也不再依赖于CPU核心即计算模块。
如此一来,所有的IP都可以通过单独的路径分别访问内存,也都可以独立开启或者关闭。
比如看视频的时候,只需要开启显示引擎、媒体解码,其他部分就都可以关掉。
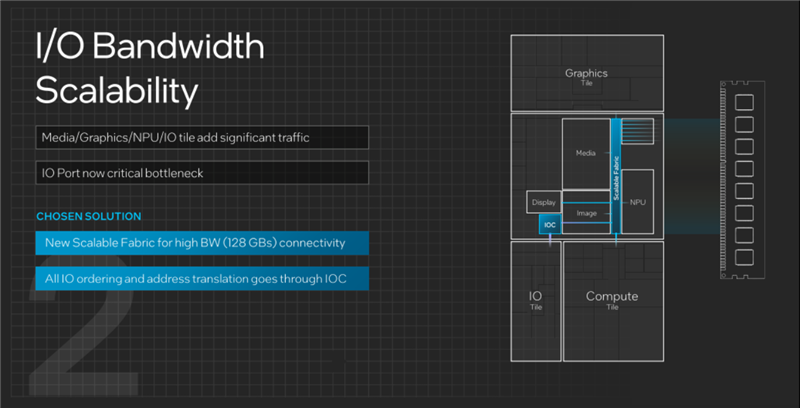
随着芯片规模的增大、功能的丰富,无论是单芯片设计还是多芯片设计,都面临同样的IO通信带宽与效率问题,稍有不慎就容易成为瓶颈。
酷睿Ultra这样的分离式模块架构上,随着媒体与显示引擎分离、低功耗E核加入、NPU AI单元加入,依次连接不同单元的的传统单一直连总线显然已经无法满足如此众多、多样的通信需求。
一种解决方法是为每个IP单元加入相应的通信通道,但这一方面会大大增加设计的复杂度,另一方面也不够灵活,未来如果要调整或加入更多单元又得重新设计。
Intel的解决方案分为两部分,一是带宽高达128GB/s的全新可扩展交叉总线,以其为中心直连各个单元模块,二是单独设计的IO缓存(IOC),统一管理所有的IO排序与寻址转换。
这种设计不仅可以解决传输带宽与延迟问题,而且是非常弹性的,未来有更高的需求,可以轻松提升带宽、增加缓存。
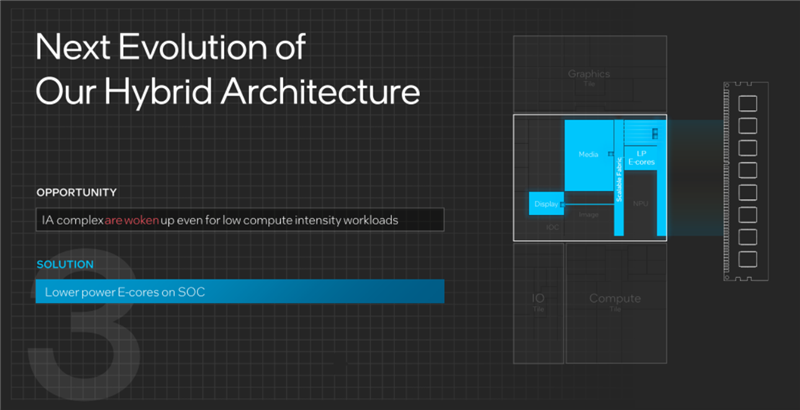
12代酷睿引入的混合架构,提高了不用负载计算的灵活性,但也存在一个问题,那就是哪怕轻量级负载,也得让整个CPU计算部分保持开启状态,造成极大的浪费,这也是12/13代酷睿笔记本续航普遍不佳的一个关键原因。
酷睿Ultra的解决方法是在SoC模块中,引入了一个低功耗计算岛,包括2个低功耗E核,它的架构和常规E核相同,只是频率和功耗更低,专门负责单独处理一些连常规E核都用不到的特别轻的负载任务。
比如看视频的时候,有了低功耗E核的掌控,不但SoC模块里的其他单元可以休息,媒体模块、计算模块、IO模块更是可以全部关掉,从而节省非常可观的功耗,极大地延长续航。
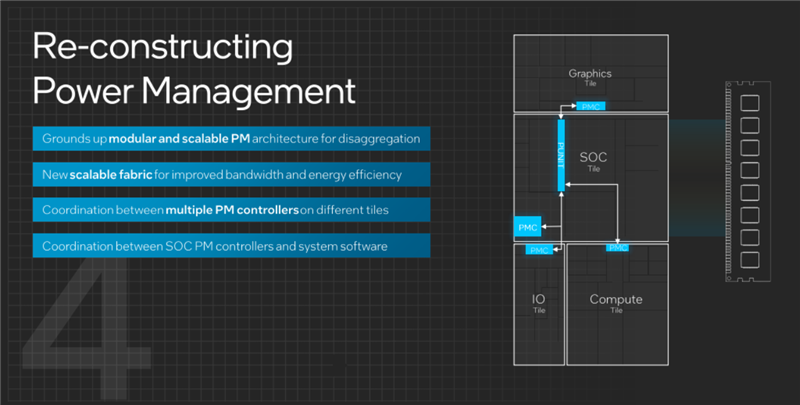
然后是电源管理部分,进行了彻底的重组,随着不同芯片的分离而分离,在四大模块中都有单独的电源管理单元。
其中,SoC模块上的处于核心地位,不但管理所在的SoC模块,还通过新的高带宽、低延迟、可扩展交叉总线,与其他模块上的电源管理单元联系在一起,起到协调沟通的作用,保证集体行动的一致性。
另外,SoC上的电源管理单元还负责与系统、软件层面的联络,实现软硬件的协调一致和高效率。
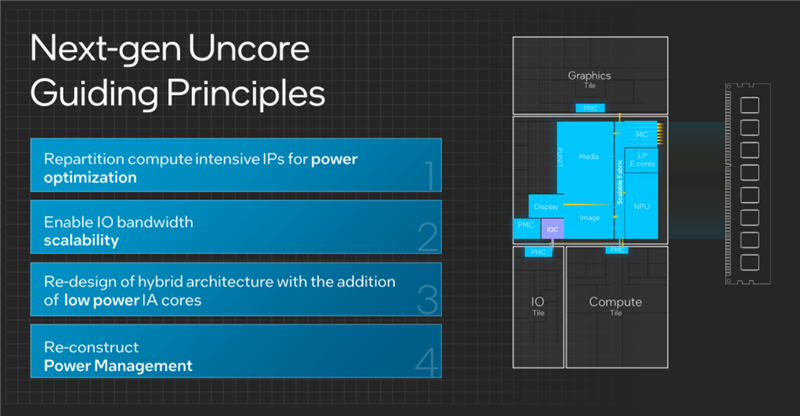
总的来说,酷睿Ultra在非核心部分做了大量的改进工作,成就了有史以来最高效的设计,尤其是在架构、电源管理方面做了多方面的大胆尝试,也为未来发展奠定了基础。
接下来,我们再深入各个不同的模块,看看它们都是怎么设计和工作的。
三种CPU核心:3D混合架构 关键在于调度
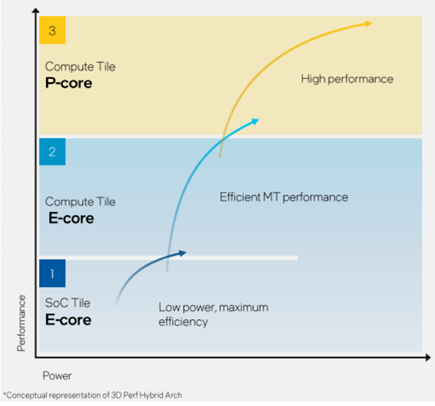
其实,单纯的计算模块没什么好讲的(缓存容量都暂未公开),最大的变化来自于SoC模块中新增的两个低功耗E核(LPE),专门用于处理器轻负载任务,能够让整个计算模块可以按需关闭,节省功耗。
这两个LPE核心,加上内存子系统、媒体引擎、显示引擎、IPU单元、NPU单元、可扩展交叉总线等,共同构成了所谓的低功耗岛(Low Power Island)。
Intel称之为3D性能混合架构。
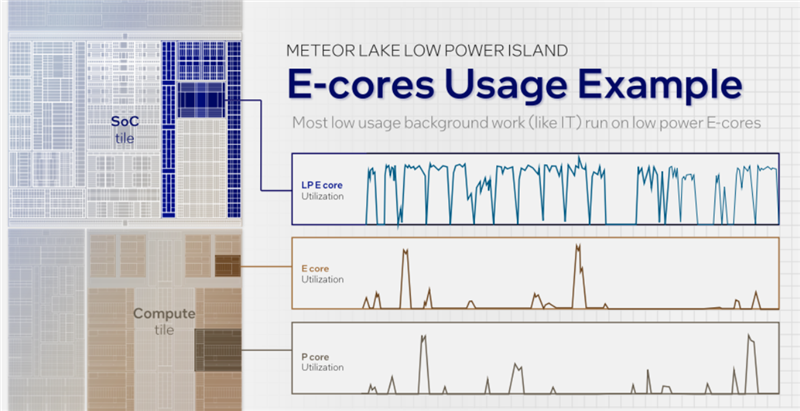
两个LPE核与E核、P核虽然位置不同,但地位是相等的,对于系统也都是透明的,所以会在Windows任务管理器中会看到三种核心及其各自的使用率。
目前已知酷睿Ultra的最高规格是6+8+2核心,也就是6个P核、8个E核、2个LPE核,组成16核心22线程。
当然,这种更复杂的混合架构,非常依赖软硬件两个层面的调度优化,比如操作系统当时最好使用最新版的Windows 11。
与此同时,Intel对线程调度器做了大幅的革新,比如增强的系统反馈机制、增强的模块间能效分配、动态的IP间功耗分配、基于SoC运行时能力的更新、基于系统运行模式与硬件特性的指导,等等。
需要强调的是,线程调度器并不是直接调度线程的,不会直接把某个线程分配到某个核心上,严格来说是介于处理器硬件、Windows系统软件中间的一层机制,基于P核、E核、LPE核的实时状态与能力,向操作系统进行反馈、推荐,由操作系统最终决定线程的分配。
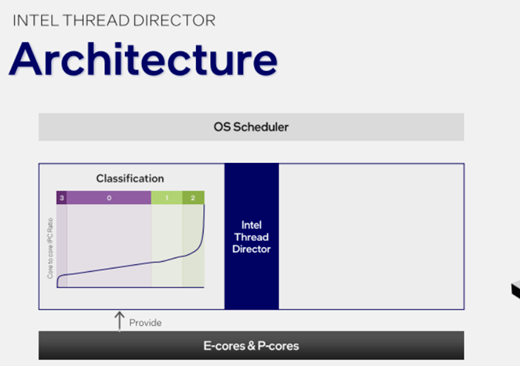
如上图,Intel和微软联合对不同的线程负载进行了分类,其中Class 0代表在P核、E核上执行时的每时钟周期指令数基本一致,也就是让谁跑都无所谓,就看谁闲着。
Class 1代表P核执行效率高于E核,比如大部分浮点运算,会优先分配给P核,如果P核不够用了也可以分一些给E核。
Class 2则代表P核执行效率远大于E核,比如AI运算,就必须让P核来做。
Class 3是新增的,代表那些在LPE核上的执行效率与能效反而更高。
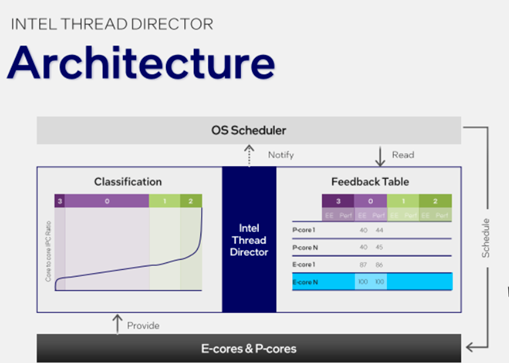
线程调度器会随时将这样的指令/线程分类反馈给系统调度器,然后共同形成一份“表格”,对线程负载进行打分,在多大程度上追求高性能(Perf)还是追求高能效(EE),再结合每个核心当前的实时能力,决定让哪个核心执行哪个指令。
这样的反馈和推荐机制是实时的,还会根据当下的功耗情况,甚至某个核心是不是刚刚执行完一条指令,动态报告给操作系统。
就是这样一套机制,可以尽可能保证在正确的时间,让正确的核心运行正确的线程,保证硬件效率的最大化。
举个例子:一个前端应用需要高性能,它有四个线程分配给P核,然后有两个轻负载的线程分配给E核。
之后经过一段时间,P核上的四个线程执行完毕,E核上的两个线程还在执行。
此时,线程调度器很可能就会建议系统将这两个线程转移到LPE核上,然后关掉整个计算模块。
再比如,有两个线程正运行在LPE核上,此时SoC模块开启、计算模块关闭,然后来了四个要求高性能的线程,于是计算模块打开,它们被分配到P核上。
这个时候,线程调度器就会提出建议,将LPE核上的两个核心转移到E核上继续执行,同时就可以关闭SoC模块上的LPE核以及相应的内部总线。
酷睿Ultra的这种设计无疑是为了进一步提高能效,使用最合适的核心运行最合适的负载。
同时它还加入了专门的NPU AI引擎,可以非常高效地持续执行一些AI推理任务负载,无需动用CPU核心,可以让后者随时关闭。
正是这些设计,使得Intel喊出了酷睿Ultra是其史上能效最高的消费级处理器,让我们对酷睿Ultra笔记本的续航充满了期待。
图形与媒体:全新架构2倍性能 第二家支持光追
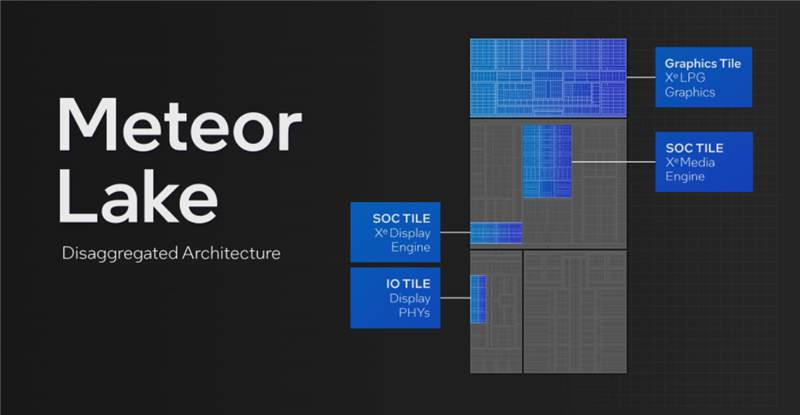
酷睿Ultra整体上采用了分离式模块架构,CPU、GPU也各自都进行了分离,前者就是刚才说的SoC模块上的LPE核。
GPU部分的分离更加彻底,甚至可以说GPU这个概念都模糊了:
独立的图形模块部分,现在是纯粹的图形渲染单元,而媒体引擎、显示引擎转移到了SoC模块,显示物理层则转移到了IO模块,彼此再进行高效互连。
这样一来,不同的功能模块在不同的地方各司其职,方便按需开关。
酷睿Ultra GPU架构来自于独立显卡Arc A系列使用的Xe HPG,同样支持最新的DX12 Ultimate,同时针对低功耗整合做了调整和优化,命名为Xe LPG,可以做称之为兼具低功耗和高性能的Xe架构。
Intel声称,它的能效相比12/13代酷睿上使用的Xe LP低功耗架构的锐炬Xe核心,提升了足足两倍。
事实上,近些年每次核显架构换代,都能带来能效的翻倍——不是性能翻倍。


酷睿Ultra的核显最多有8个Xe核心,也就是128个适量引擎,可以粗略地理解为128个执行单元,比现在的96个增加了1/3。
这已经超越了入门级独立显卡Arc A310 6个Xe核心的规模,达到了Arc A380相同的水平,当然受制于频率、功耗,性能会低于Arc A380。
同时,它还有2条几何流水线、8个采样器、4个像素后端、8个光追加速器——是的,它有光追!
这也是AMD锐龙6000系列上的Radeon 680M之后,第二家支持硬件光追的核显。
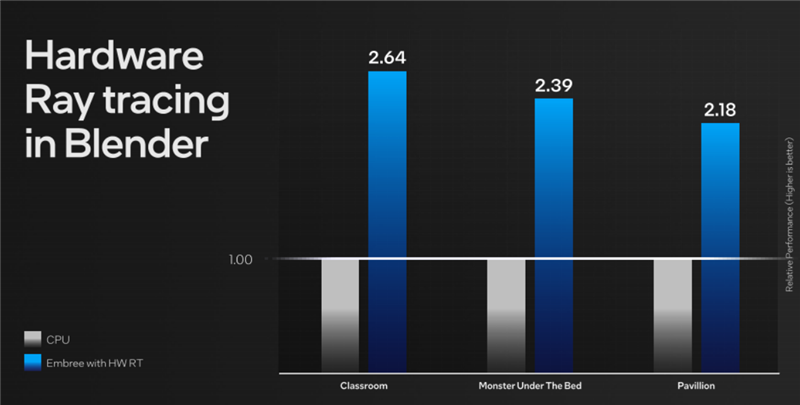
当然,这种级别的核显不能指望流畅运行光追游戏,哪怕有XeSS的加持也不行,但做一些光追加速渲染创作还是很有效率的。
按照Intel的说法,酷睿Ultra核显利用硬件光追运行Blender,性能相比纯CPU要快上2倍多。
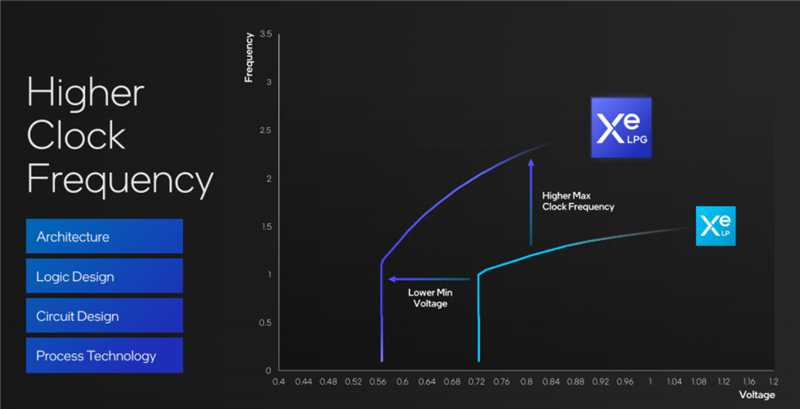
此外,Xe LPG架构的频率/电压曲线相比上代Xe LP更加高效,比如同样达成1GHz频率,所需最低电压仅为0.55V左右,降低了接近四分之一。
比如同样的0.8V左右电压下,Xe LPG的运行频率可以大大超过2GHz。

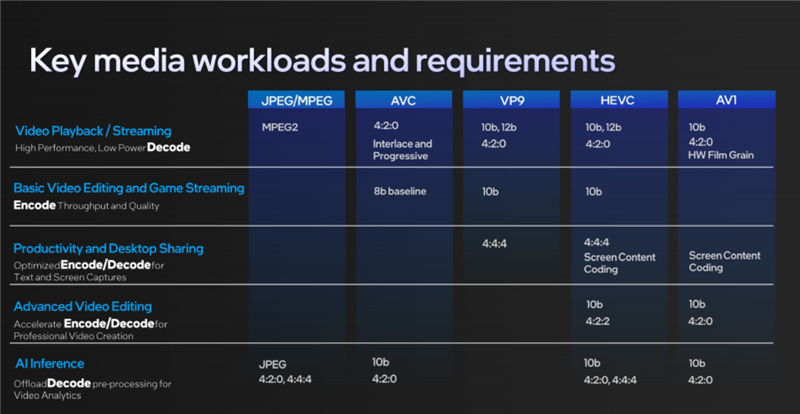
媒体引擎部分和Xe HPG架构同样强大,最高支持8K60 10-bit HDR解码、8K 10-bit HDR编码,视频格式支持VP9、AVC、HEVC(H.265)、AV1等等。
针对基本视频播放与流媒体、基本视频编辑与云游戏、生产力创作与桌面捕捉共享、高级视频编辑、AI推理等不同场景,也支持不同级别的编解码格式。

显示输出部分也不遑多让,支持最新的HDMI 2.1、DP 2.1 20Gbps、eDP 1.4等输出格式,最高分辨率可达单屏8K60 HDR、四屏4K60 HDR、慢动作1080p360/2K360。
可以说,无论图形渲染,还是视频编解码、输出显示,酷睿Ultra的核显都达到了一个新的高端,真正可以全面媲美入门级独立显卡。
NPU AI引擎:专业的人高效做专业的事
这是一个AI无处不在的时代,Intel一贯以来的XPU战略,更是水到渠成地在从软到硬全线推进AI。
与此同时,AI的使用场景也在迅速从云侧向边缘和端侧延伸,AI PC的应用场景和需求突飞猛进,包括智能语音降噪、视频背景模糊、超分辨率、游戏精彩时刻智能截取、大语言模型对话,以及文生图、图生图、文生视频等等AIGC场景。
酷睿Ulra首次引入了神经网络单元NPU,所有型号都有,可以从CPU、GPU接手持续的、低负载的AI工作,通过专门功能硬件高效运行,而且功耗极低。
酷睿Ultra NPU单元既可以执行固定功能任务,也可以做可编程计算,就看实际需求了,同时也支持混合精度数据,并提供标准化的编程接口。
同时,快速响应、低延迟的CPU,高性能、高吞吐量的GPU,也都会闲着,同样担负部分AI算力需求,比如CPU适合轻量级的单次推理,GPU适合多媒体、3D渲染,三者合作共同推进AI PC。
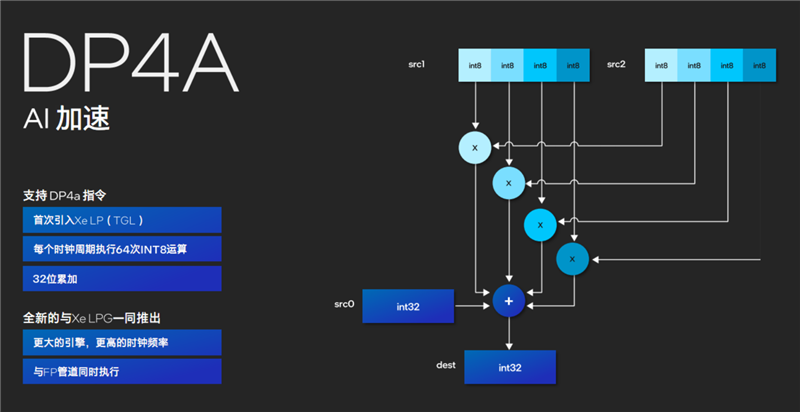
尤其是Xe LPG架构的新一代核显,与锐炫显卡一样支持DP4a指令,同样可用于AI加速。
它面向整数类型处理,可以与浮点流水线并行,在每个时钟周期内可以执行多达64次INT8整数运算,并支持32位累加,也就是融合成INT32整数类型,再加上更高的频率,执行效率得以大大提升。
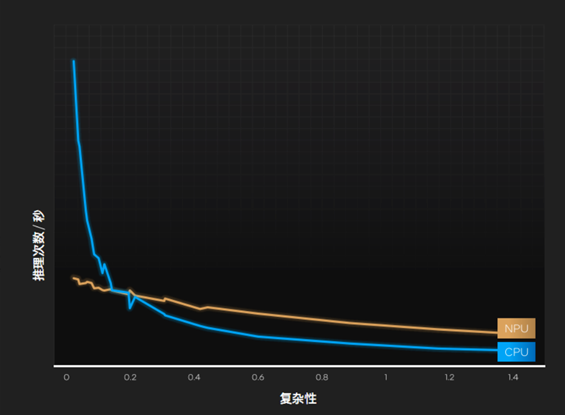
比如轻量级的神经网络模型MobileNet v2,在非常低的复杂度下,CPU的效率是极高的。
但是,随着复杂度的增加,CPU很快就跟不上了,这个时候就要看NPU的发挥,在高复杂度下的效率远超CPU,而且非常稳定。
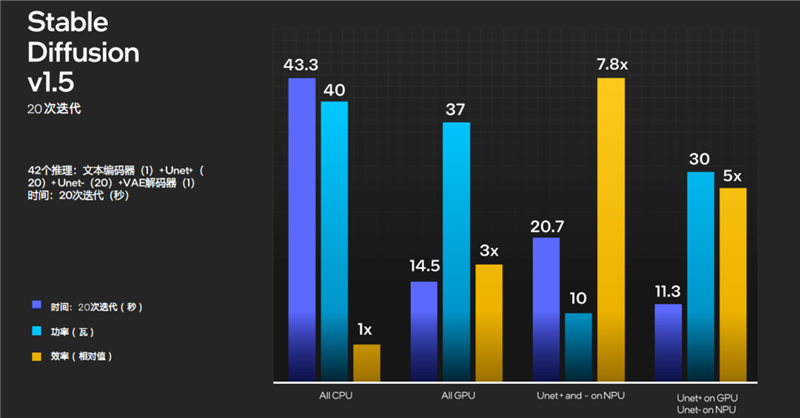
Stable Diffusion这样的典型文生图AI应用,NPU执行起来更是得心应手,效率可以全面远远超越CPU、GPU。
Intel官方实测,完全使用NPU进行推理,所需时间不到CPU的一半,会略长于GPU,但所需功耗比它俩都低得多,相对效率可以达到CPU的几乎8倍、GPU的2倍多。
NPU还可以和CPU、GPU配合,各自承担不同的任务,综合起来大大节省所需时间和功耗,效率可以做到CPU的多达5倍、GPU的接近2倍。

在硬件架构上,NPU最关键的就是两路神经计算引擎和推理流水线,包括MAC阵列、可编程DSP、激活函数、数据转换、存储与载入等单元,同时搭配DMA引擎、暂用内存单元,构成一个完整的神经神经网络引擎,可以支持多种神经网络模型。
其中,MAC阵列可以高效灵活地执行矩阵乘法和卷积运算,每周期多达2048,支持INT8、FP16数据类型。
通俗地讲,NPU就是通过专用硬件单元,让专业的“人”做专业的“事”,效率自然高得多,当然专用性也意味着一方面缺乏通用性,另一方面需要专门适配。

换言之,AI硬件是容易做的,真正难的是软件和场景适配、优化,如何充分释放硬件潜力。
在这方面,Intel的影响力和号召力就体现得淋漓尽致了,一方面与微软深度合作,全面导入Office、Windows Studio Effects、Teams、DirectML,另一方面整个行业都在积极跟进。
不但有Adobe、Zoom、Webex、Blender、CyberLink、杜比、虚幻引擎这样的国际大牌,也有字节跳动、腾讯、虎牙直播、爱奇艺这样的国内巨头。
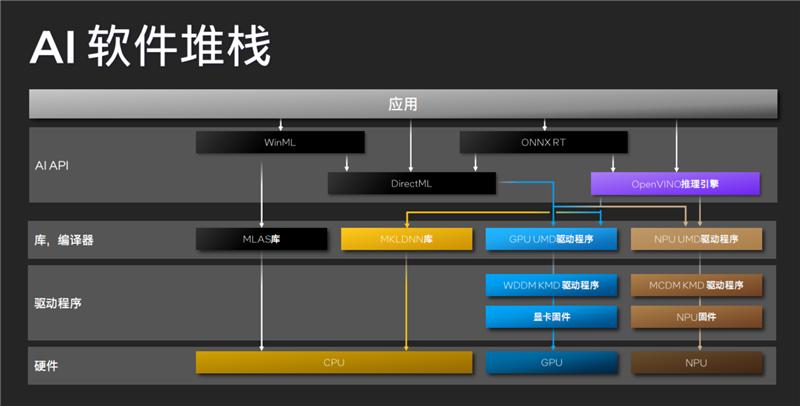
这也得益于Intel全面、成熟、易用的配套软件开发平台,从驱动程序到库、编译器再到OpenVINO这样的顶层API,都全面针对CPU、GPU、NPU AI应用提供支持,大大简化和加速开发,开发者也可以根据自己的应用和场景需求,灵活选择最合适、最高效的执行途径。
比如Microsoft Teams/Studio Effects就借助从NPU硬件到OpenVINO引擎的体系来优化音频、视频的AI加速,Adobe CC通过DirectML API发挥GPU的能力,视频分析工作则可以同时借助NPU、GPU的力量。
Intel 4制造工艺:感受下EUV的力量

再好的硬件设计,没有及时、成熟的制造工艺,只能停留在纸面上。
早些年,Intel走的是Tick-Tock策略,逐年交替升级工艺和架构,后来大家都知道,逐渐慢了下来。
而今在基辛格的领导下,Intel正在近乎疯狂地提速,要在四年内实现五个制程节点,而且灵活地开放外包与代工,除了用自己工艺造自家产品,还会引入合适的外部工艺制造部分产品或模块,并为其他客户制造产品。
Intel 4已经在酷睿Ultra上投入量产并在提升产能。
Intel 3将在Intel 4的基础上,进一步提升设计库密度,更多地应用EUV极紫外光刻技术,增加驱动电流的晶体管并降低通孔电阻。
现已做好生产准备,将用于明年的Sierra Forest、Granite Rapids两大至强产品线,前者最多288个E核。
Intel 20A将进入埃米时代,首发PowerVia背部供电技术、RibbonFET全环绕栅极晶体管技术,用于未来两代酷睿Arrow Lake、Lunar Lake,将按计划在2024年做好投产准备。
Intel 18A就是20A的升级版,能效继续提升10%,夺回Intel在制程工艺方面的领导地位。
它既会用于自家的消费级Panther Lake、服务器级Clearwater Forest,外部代工也已拿下Arm、爱立信等客,预计2025年投产。
再往后,Intel将会用上ASML的下一代高NA EUV***。
一台典型的EUV***价格超过16亿元,重达180吨,需要4架波音747飞机和35辆卡车才能运输,还需要加固的地板和更高的天花板才能安装固定,目前只有荷兰ASML才能制造。
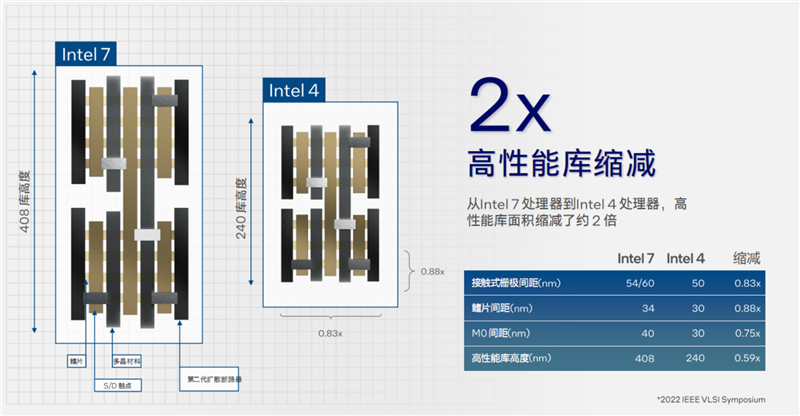
Intel 4工艺的技术细节非常丰富,但因为专业性太强,我们不会过于深入,只讲一些比较直观的变化。
Intel 4工艺的高性能逻辑库高度仅为240nm,接触栅极间距收窄到50nm,M0底层金属层间距、鳍片间距都做到了30nm,相比于Intel 7分别缩小了41%、17%、12%、25%,整个库的面积只有原来的大约一半。

金属层堆叠到了多达18层,密度相当高,并针对高性能计算进行了优化,包括5个增强型铜层、13个铜互连层,其中多个层都使用了EUV极紫外光刻,搭配四重曝光技术。
此外,缩小到30nm的金属层间距,为布线提供了良好的技术支持。
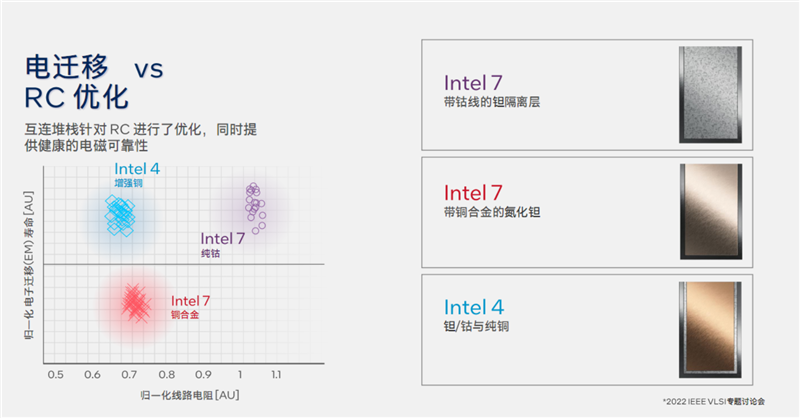
开发新的制程工艺时,既要在缩小间距的同时提升导电性、降低电阻,还要保证电子迁移的长寿命。
Intel 7工艺上使用了不同材料的特殊金属层,包括带钴的钽隔离层、带铜合金的氧化碳,但效果不能百分百令人满意,前者可延长电子迁移寿命,但电阻变大了,后者可降低电阻,但电子迁移寿命变短了。
Intel 4工艺使用了新的增强铜技术工艺,结合了钽、钴与纯铜材料,结果非常好地平衡了电子迁移寿命和电阻。

EUV极紫外光刻的引入,不仅可以提升晶体管密度、缩小了整体面积,还大大简化了整个工艺流程。
比如在Intel 7工艺下,没有EUV,就需要更多的光刻和掩膜环节,以及更多的分层,而在Intel 4工艺搭配EUV之后,只需单个层就够了,在这里的生产步骤减少了多达3-5倍。
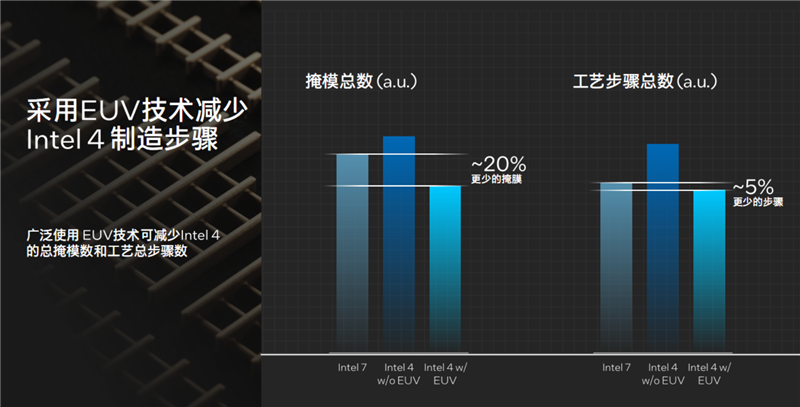
根据估算,Intel 4工艺如果没有EUV,无论掩膜总数还是工艺步骤总数,其实都是要比Intel 7明显增加的,从而导致更高的复杂度和成本,也很容易影响良品率。
EUV的加入,使得掩膜总数比Intel 7工艺减少了20%,生产步骤总数也减少了5%。

此外,EUV可以让连接结构变得非常标准化,Intel 7工艺上的一些非标准连接已经不见了,这样在布局走线方面就可以实现更加高效的自动化。
打个比方就像是堆积木,Intel 4 EUV的标准连接结构就显示所有积木都是标准接口,拿过来就能对接,非常整齐。

这一套组合拳下来,Intel 4的良品率就做得非常好,第一代就超越了14nm、10nm经过多代优化的水平。
这对于后续的Intel 3/20A/18A也奠定了很好的基础,是实现四年五代制程节点的一个关键点。
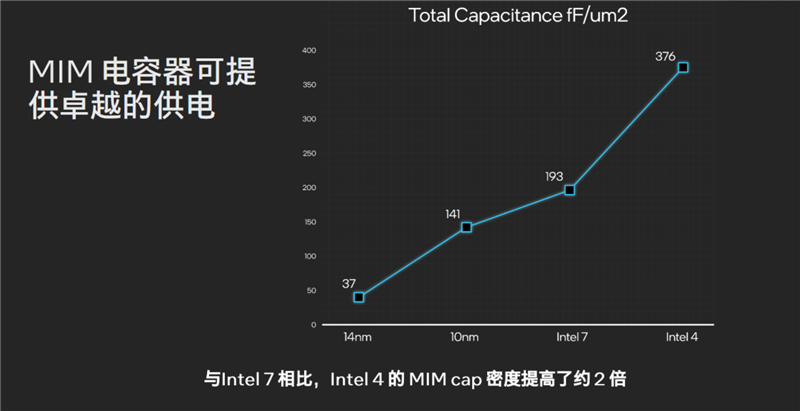
此外,Intel 4工艺下的MIM(金属-绝缘体-金属)电容的密度也得到了加大,对比Intel 7工艺下提高了约2倍,能让处理器实现更高效的供电。
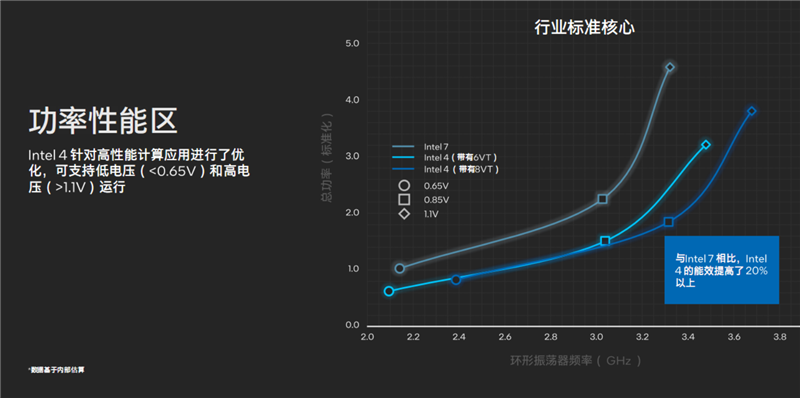
Intel 4工艺搭配6VT或者8VT,可以大大改善能效,可以在0.65V以下低电压、1.1V以上高电压运行,综合能效比Intel 7工艺提升了超过20%,再结合全新的架构设计,这才使得酷睿Ultra成为史上能效最高的一代。
总的来说,Intel 4工艺搭配EUV实现了一次技术和效率层面的飞跃,良品率也非常理想。虽然现在做不到足够高的频率,以至于无法应用于顶级游戏本和桌面市场,而且只会用这一代,不像14nm、10nm那样会多次迭代挖掘潜力,但也为后续的Intel 3/20A/18A开了一个好头。
相信随着工艺技术的不断推进与成熟,尤其是随着EUV的不断深入与完善,后边几代制程工艺会有更好的表现。
封装技术与组装流程:一分为四、合四为一的魔术

所谓封装(package),就是把做好的芯片包装起来,安装在主板上,用于主板和芯片之间的供电、信号传输,也可以保护芯片。
早期的封装都比较简单,作用也很单一,而随着制造技术的复杂度、成本急剧增加,加之应用需求的多样化,各种先进封装技术应运而生。


其实早在1965年,Intel创始人之一、半导体行业传奇戈登·摩就预言过,在构建大型芯片系统时,将其分解为单独封装并互相连接的较小的功能模块,可能更具经济性。——这就是眼光!
目前,Intel已经在多个产品上使用了不同的先进封装技术,比如2017年的Straix 10首次时候用EMIB(嵌入式多芯片互连桥接),2023年的Sapphire Rapids第四代至强也用了它。
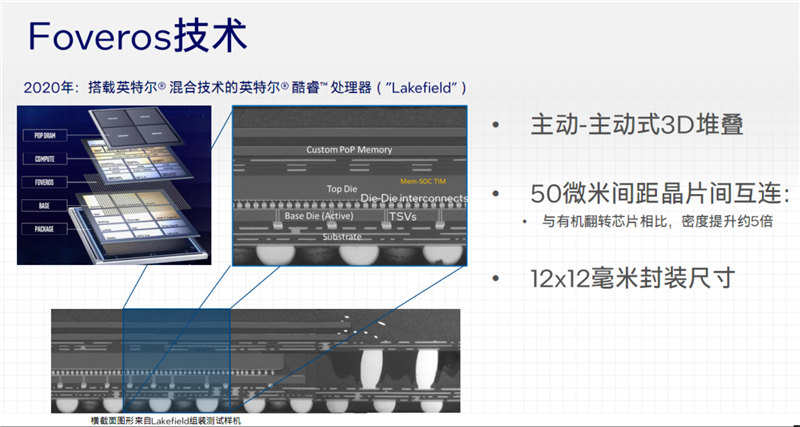
2020年的Lakefiel处理器尝试主动式3堆叠技术Foveros,2022年的Ponte Vecchio GPU加速器则综合了Foveros、EMIB封装,也叫作Co-EMIB。
同时,Intel还准备了Foveros Omni、Foveros Direct等新的封装技术。

酷睿Ultra则是首个应用Foveros封装技术的消费级处理器,四个不同Tile模块利用它组装在一起,可以实现极低功耗、极高密度的芯片间互联,可以为每个模块选择不同的最合适的制造工艺,可以灵活定制不同模块组合实现不同SKU型号,可以提高晶圆使用率和良品率。

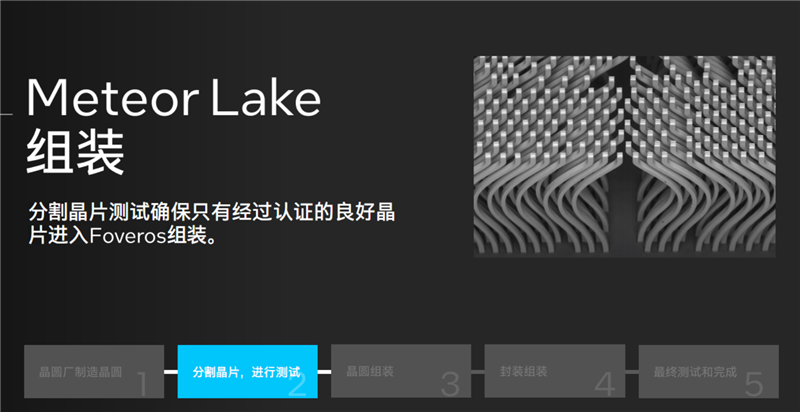
因为采用了全新的分离式模块化架构和先进的Foveros封装工艺,酷睿Ultra的制造、组装、测试流程也与以往的处理器截然不同。
它需要使用不用工艺、在不同工厂制造各个模块,预计作为基底的基础中介层,各自进行切割、测试,合格的才能组合在一起,统一封装为复合体,再进行整体性测试验证,才能得到最终的成品,成为我们看到的一颗颗酷睿Ultra。
对于处理器封测具体流程感兴趣的,可以参考我们之前的Intel马来西亚工厂游记,酷睿Ultra就正在那里量产。

到这里,我们的酷睿Ultra Meteor Lake架构设计、技术特性、工艺封装之旅就结束了,等到12月14日就可以看到具体的型号、规格、性能表面,明年初就可以买到全新的AI笔记本。
酷睿Ultra Meteor Lake并不完美,尤其是性能未能达到预期,无法应用在所有市场领域,但作为Intel 40年来最具革命性的处理器,它在你能想到的几乎每个地方都有了飞跃式的变化,是一次极为大胆、激进的尝试,也是对这个AI时代的强力回音,更为后续发展奠定了坚实的基础。
Intel也多次坦然承认,自己在很多方面都处于追赶的地位,为此正在以前所未有的广度、深度、速度跑步前进,而这种变化对于一家雄踞半导体行业半个多世纪的巨头来说是相当不易的,也是最让我们欣喜的地方。
期待Intel重返巅峰的那一天!期待你追我赶的激烈竞争给我们带来越来越精彩的技术和产品!
编辑:黄飞





















 工商网监
工商网监
评论