 电子发烧友App
电子发烧友App


导读
AI大模型的热潮不断,预计未来十年,AGI时代即将到来。但目前支撑AI发展的GPU和AI专用芯片,都存在各种各样的问题。 那么,在分析这些问题的基础上,我们能不能针对这些问题进行优化,重新定义一款能够支持未来十年AGI大模型的、足够灵活通用的、效率极高性能数量级提升的、单位算力成本非常低廉的、新的AI处理器类型?
01. 首先分析场景特点,做好软硬件划分
1.1 一方面,AI处理器存在问题
差不多是从2015年前后,开始兴起了专用AI芯片的浪潮。以谷歌TPU为典型代表的各种架构的AI专用芯片,如雨后春笋般涌现。 但从AI落地情况来看,效果并不是很理想。这里的主要问题在于:
AI芯片专用设计,把许多业务逻辑沉到硬件里,跟业务紧密耦合;但业务变化太快,算法不断更新,芯片和业务的匹配度很低。
AI算法是专用的,面向具体场景,比如人脸识别、车牌识别,各种物品识别等。综合来看,算法有上千种,加上算法自身仍在快速演进,加上各种变种的算法甚至超过数万种。
用户的业务场景是综合性的,把业务场景比做一桌宴席,AI芯片就是主打的那道主菜。对AI芯片公司来说,自己只擅长做这一道菜,并不擅长做其他的菜品,更不擅长帮助用户搭配一桌美味可口、荤素均衡、营养均衡的宴席。
1.2 另一方面,GPU也存在问题
NVIDIA的GPU是通用并行处理器:
性能效率相对不高,性能逐渐见顶。要想算力提升,只能通过提升集群规模(Scale Out,增加GPU数量)的方式。
增加集群规模,受限于I/O的带宽和延迟。一方面,集群的网络连接数量为O(n^2),连接数量随着集群规模的指数级增加;另一方面,AI类的计算任务,不同节点间的数据交互本身就非常巨大。因此,受阿姆达尔定律影响,I/O的带宽和延迟,会约束集群规模的大小。(在保证集群交互效率的情况下,)目前能支持的集群规模大约在1500台左右。
还有另外一个强约束,就是成本。据称GPT5需要5万张GPU卡,单卡的成本在5W美金左右,再加上其他硬件和基础设施已经运营的成本。仅硬件开销接近50亿美金,即350亿RMB。这对很多厂家来说,是天文数字。
1.3 问题的核心:芯片的灵活性要匹配场景的灵活性
首先,仍然是从我们之前很多文章中提到的这个“从软件到硬件的典型处理器划分图”开始分析。
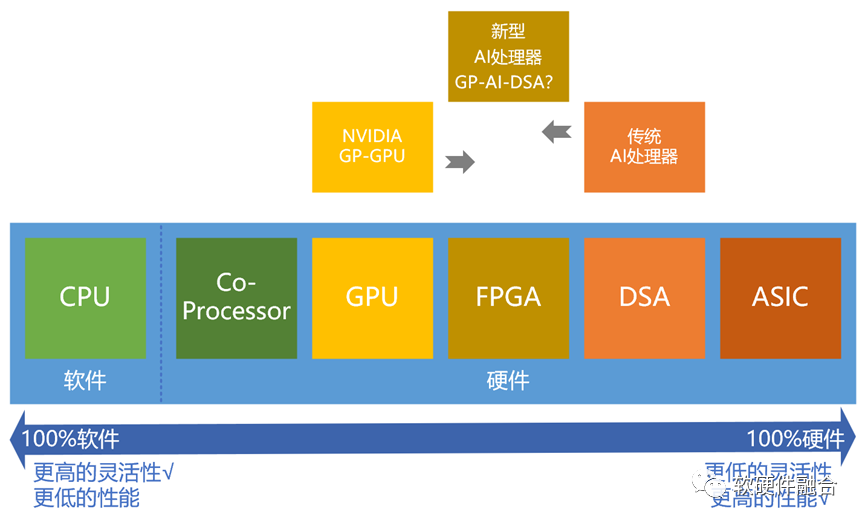
指令是处理器软件和硬件的媒介:有的指令非常简单,就是基本的加减乘除等标量计算;有的指令非常复杂,不是纯粹的向量、矩阵或多维张量计算,而是各种维度计算再组合的一个混合的宏指令,或者说是一个算子甚至算法,就对应到一条(单位计算)指令。 AI专用处理器是一种DSA,是在ASIC基础上具有一定的可编程能力。性能效率足够好,但不够灵活,不太适合业务逻辑和算法快速变化的AI场景。而GPU足够灵活,但性能效率不够,并且性能逐渐达到上限。 从目前大模型宏观发展趋势来看:
Transformer会是核心算法,在大模型上已经显露威力。未来模型的底层算法/算子会逐渐统一于Transformer或某个类Transformer的算法。从此趋势分析可得:AI场景的业务逻辑和算法在逐渐收敛,其灵活性在逐渐降低。
此外,AI计算框架也走过了百家争鸣的阶段,目前可以看到的趋势是,PyTorch占据了绝大部分份额。这说明整个生态也在逐渐收敛,整个系统的迭代也在放慢。
这两个趋势都说明了,未来,“专用”的AI芯片会逐渐地绽放光芒。当然了,作为AI芯片的公司,不能等,而是需要相向而行:
需要定义一款,其性能/灵活性特征介于GPU和目前传统AI-DSA处理器之间的,新型的通用AI处理器。“比GPU更高效,比AI芯片更通用”。
通用性体现在两个方面:
一方面,处理器的通用性。能够适配更多的算法差异性和算法迭代,覆盖更多场景和更长的生命周期。
另一方面,面向AGI通用人工智能。不再是专用AI的“场景千千万,处理器千千万”,架构和生态完全碎片;而是一个通用的强人工智能算法,一个通用的强处理器平台,去强智能化的适配各种场景。
02. 大核少核 or 小核众核?
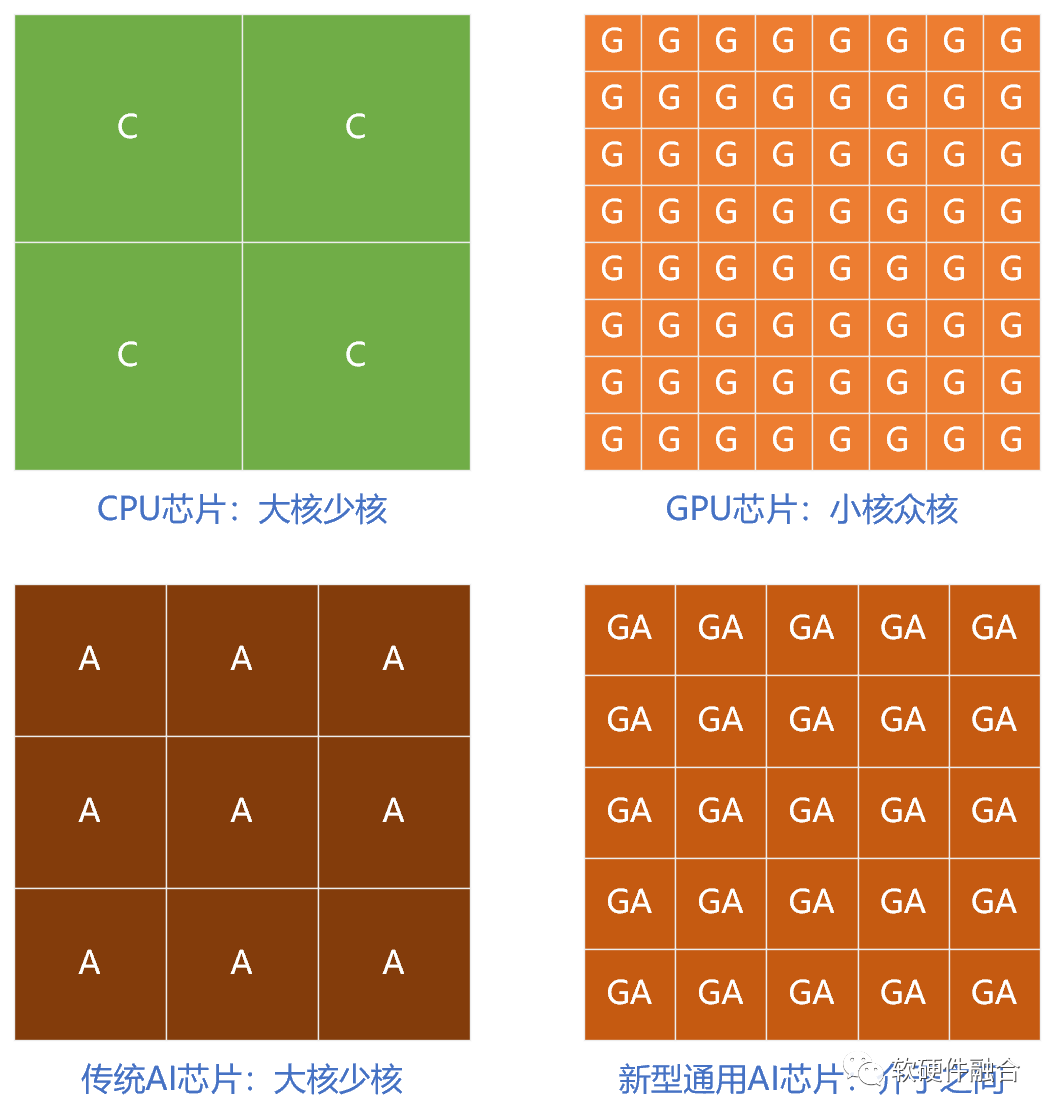
CPU是大核,但通常一个芯片里只有不到100个物理核心;而GPU是小核众核的实现,目前通常在上万个核左右;而传统AI芯片,通常是大的定制核+相对少量核(100核以内)的并行。
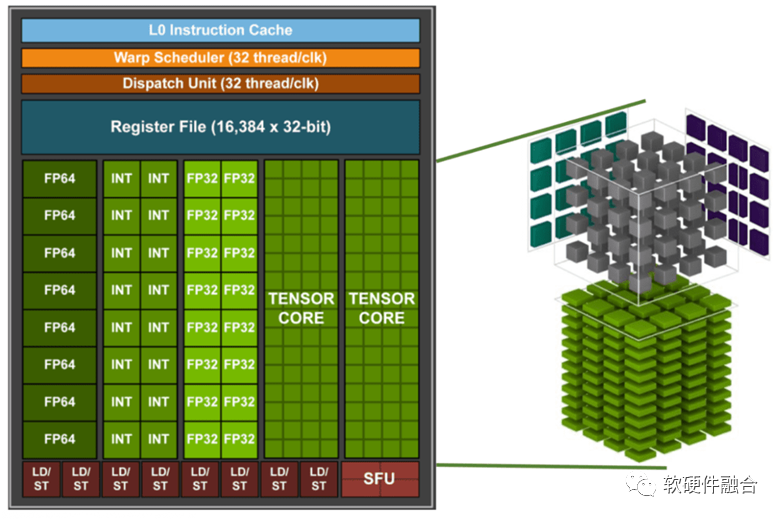
此外,一个很重要的现象是,GPU核,不再是之前只有CUDA核的标量处理器,而是增加了很多Tensor核的类协处理器的部分。新的GPU处理器不再在处理器核的数量上增加,反而把宝贵的晶体管资源用在单个核的协处理器上,把单核的能力做更多的强化。 因此,新型通用AI芯片需要:
在目前工艺情况下,并行的单芯片处理器核心(GA,通用AI处理器核心)数量在500-1000之间比较合适;
单个GA采用通用高效能CPU核(例如定制的RISC-v CPU)+强大的Tensor协处理器的方式。
03. 极致扩展性,多层次强化内联交互
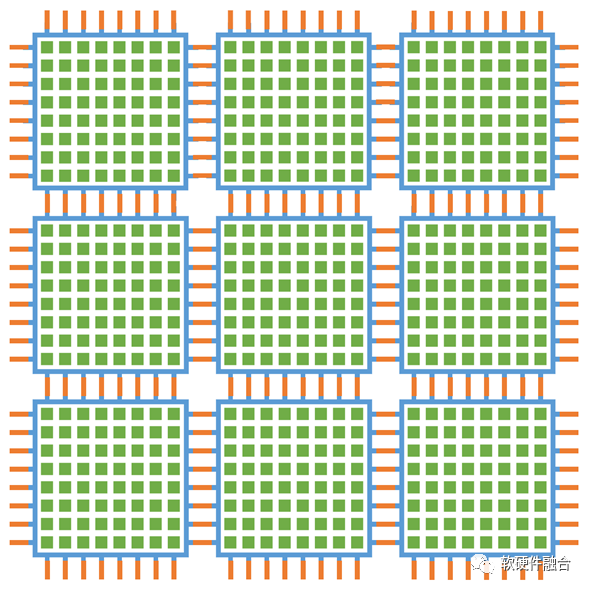
要想实现极致扩展性,通常需要多个层次的资源切分和整合:
首先,单核心内部。可以支持资源的虚拟切分和整合(类似CPU的分时共享和虚拟化vCPU)实现从1-m个vGA核的自由扩展。
其次,单芯片内部。可以从1-n个核的扩展资源切分和整合,也就是说vGA可以实现1-m*n个资源的扩展。
最后,众多芯片构成的计算集群。多个芯片可以组成一台服务器、多个服务器组成一个机柜、多个机柜组成一个POD集群。可以通过集群互联实现1-k个芯片的扩展,也就是说,vGA实现1-m*n*k个资源的极致扩展。
此外,每个层次的数据交互都要求极高,内部需要非常强劲的NOC总线,外部需要带宽数量级提升的高性能网络的支持。
04. AI芯片案例
4.1 Tenstorrent的案例
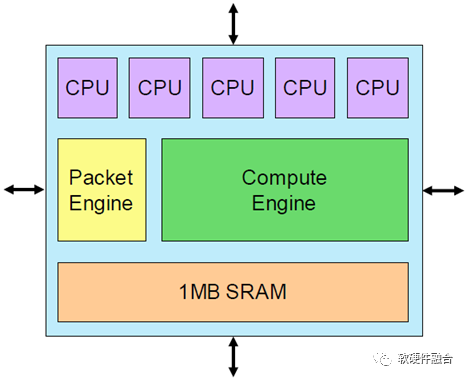
Tenstorrent的AI核称为Tensix,第一代Tensix每个核有五个标量RISC CPU,单个计算引擎的性能为3 TOPS。
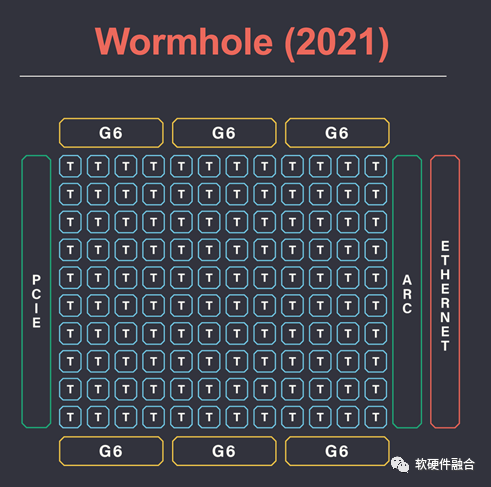
整个芯片代号为Wormhole,有80个Tensix核心,并且集成了ARC架构的Host CPU。此外,Wormhole支持16个100Gbps的Ethernet网络接口。
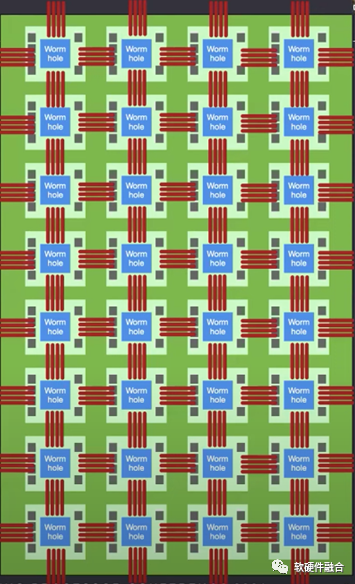
采用Wormhole芯片,Tenstorrent设计了nebula(星云)服务器,一个4U服务器包含32个Wormhole芯片。
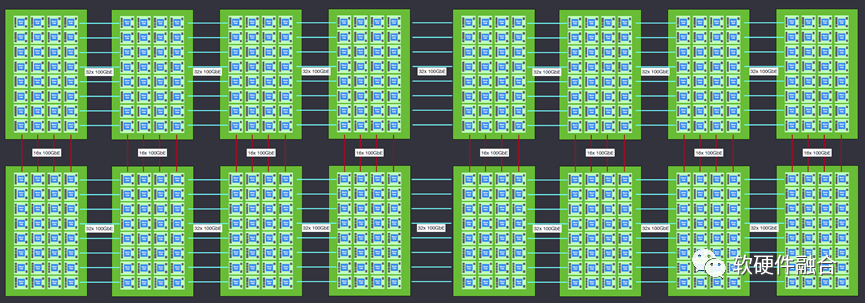
一个机柜包含8台nebula服务器,上图为两个机柜互联的架构示意图。 当然,Scale out横向扩展功能并不止于此,Wormhole在机架级连接方面是非常灵活的。理论上可以达到几乎无限的扩展连接能力。
4.2 Tenstorrent Roadmap
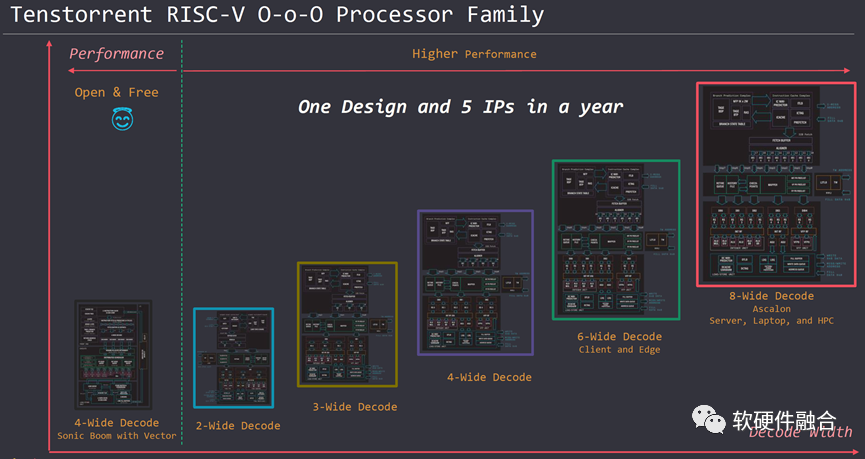
Tenstorrent推出了自研的RISCv处理器 IP,从用于AI-DSA的小CPU核,用于IoT的MCU级别的CPU核心,到笔记本电脑、边缘和服务器以及HPC场景的高性能CPU核。

目前,Tenstorrent的AI芯片,已经量产的有Grayskull和Wormhole,BlackHole在公司内部调试中。
2024年将推出基于Chiplet的AI芯片,集成了自研的RISC-v CPU和AI处理器。
4.3 Tenstorrent Wormhole的不足
从软硬件融合的理念和理论出发,对Tenstorrent Wormhole进行分析,仍有不少待优化的地方:
单个Tensix核心的能力仍有待优化。单核心内部小的用于控制的CPU核,其工作仍需要进一步优化,哪些可以硬件卸载加速,哪些还需要在协处理器增强。此外,内部的各种缓存设计仍需要进一步优化。
核数太少。通过优化单核的资源消耗,以及通过更先进工艺和Chiplet封装等方式把核数再增加4/8倍,比较符合未来2-3年大模型现状(从最新的Roadmap看,已经在规划中了)。
核间通信需要进一步优化。很多核间通信需要CPU参与,一方面集成CPU更高效(已经在规划中了),另一方面,进一步把相关任务从CPU卸载到硬件加速。
片间通信优化。支撑极致扩展性的网络端口,对高性能网络技术的要求非常之高,需要进一步加强。
软硬件耦合设计。软件和硬件必须解耦,而不是紧耦合。只有充分的解耦,才能各自“放飞自我”,实现更多的创新能力增强。
软件定义。做AI大模型的客户,通常都是大客户。大客户的业务系统是已经存在的,客户需要的仅仅是性能提升和成本下降。客户并不想大范围修改业务逻辑,更不想有平台依赖。需要解决这个问题。
编辑:黄飞









 工商网监
工商网监
评论