 电子发烧友App
电子发烧友App


AMD RDNA的4年:又一个Zen还是新的Bulldozer? 2019年,AMD推出了一款新的GPU架构,这是该公司七年来首次推出主要的图形芯片设计。自首次亮相以来,该架构经历了两次修订,强调了chiplet和缓存在渲染领域的重要性。鉴于这些发展,评估AMD凭借其工程能力所取得的成就并考虑每次更新的影响是有意义的。
我们将探索这项技术,评估其在游戏中的表现,并研究其对AMD的财务影响。
RDNA是否像Zen一样取得了巨大的成功?或者,各种各样的修改是否会给AMD带来另一个“Bulldozer”时刻?让我们来看看。
为什么GCN需要改变
目前AMD的GPU 分为两个截然不同的产品领域,一个是针对游戏的,另一个是用于超级计算机、大数据分析和机器学习系统的。
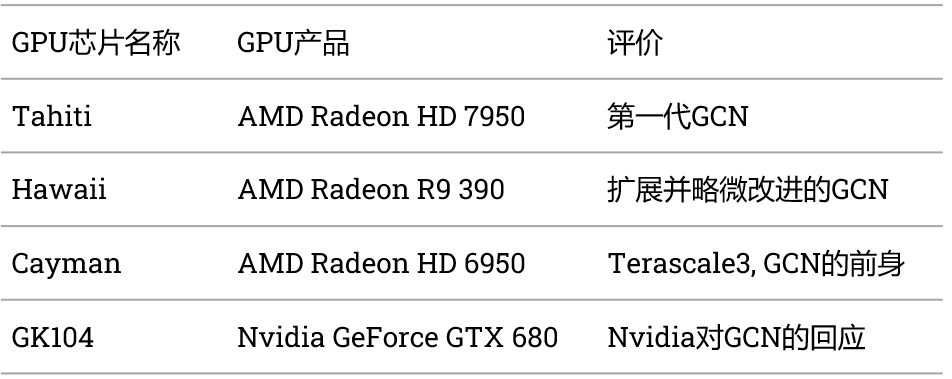
然而,它们都有着相同的传统——一种被称为Graphics Core Next(GCN)的架构。它首次出现于2012年,尽管在此过程中进行了一些重大修改,但仍使用了近10年。GCN是对其前身TeraScale的彻底改革,从一开始,它就被设计为具有高度可扩展性,在图形和通用计算(GPGPU)应用中同样适用。
缩放是处理单元组合在一起的方式。从GCN的最初版本到最终版本,GPU的基础由4个计算单元(CU)组成。
每个处理器都包含4个SIMD(单指令,多数据)矢量单元,在16个数据点上执行数学运算,大小为32位,还有一个标量单元用于基于整数的逻辑运算。
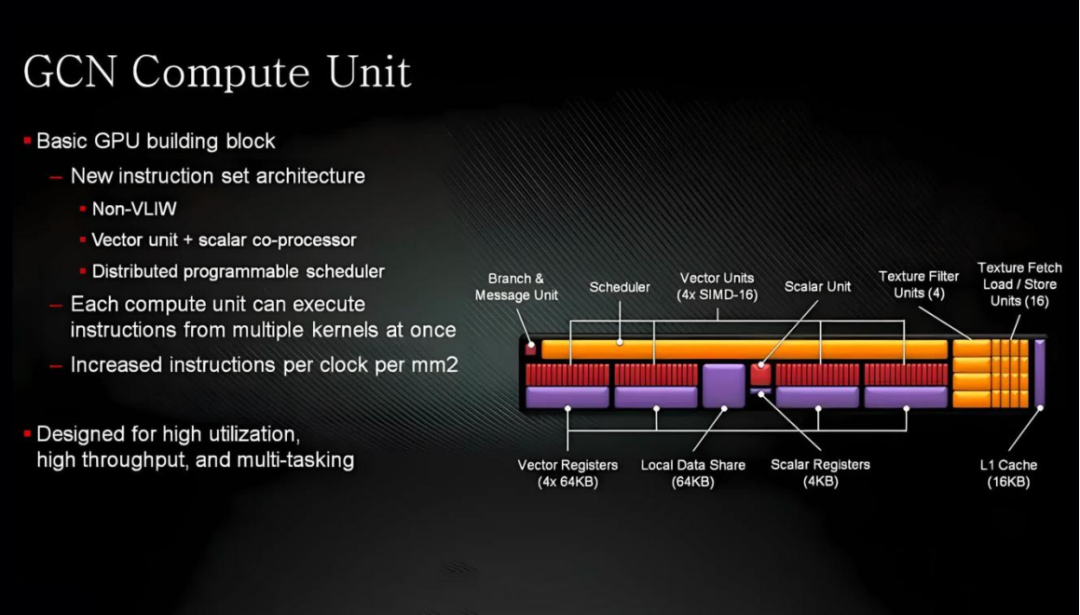
每个矢量SIMD都有一个64 kB的寄存器文件,所有四个单元共享一个64 kB的暂存块(称为本地数据共享,LDS),所有处理单元共享一个16 kB的L1数据缓存。四组CU共享一个16 kB的标量缓存和一个32 kB的指令缓存,所有这些缓存都链接到一个GPU级的L2缓存。
到2018年GCN 5.1发布时,这些都没有太大变化,尽管对缓存层次结构的操作方式进行了多次改进。然而,对于游戏世界来说,GCN有一些明显的缺点,但可以总结为,对于开发者来说,从芯片中获得处理吞吐量和带宽利用率方面的最佳性能是一个挑战。
例如,GPU以64个线程为一组(每个线程称为一个波或波前)进行调度,每个SIMD单元可以使用不同的波发出,最多排队10个深度。然而,指令的发布率是每4个周期1次,因此为了确保单元保持繁忙,需要调度大量线程——这在计算世界中是可以实现的,而在游戏中则不然。
GCN的第一个版本拥有称为异步计算引擎(ACE)的硬件结构。当涉及到在3D游戏中的渲染帧时,GPU会由排在长队列中的系统发出命令。然而,它们并不都需要按照严格的线性顺序完成,这就是ACE发挥作用的地方。
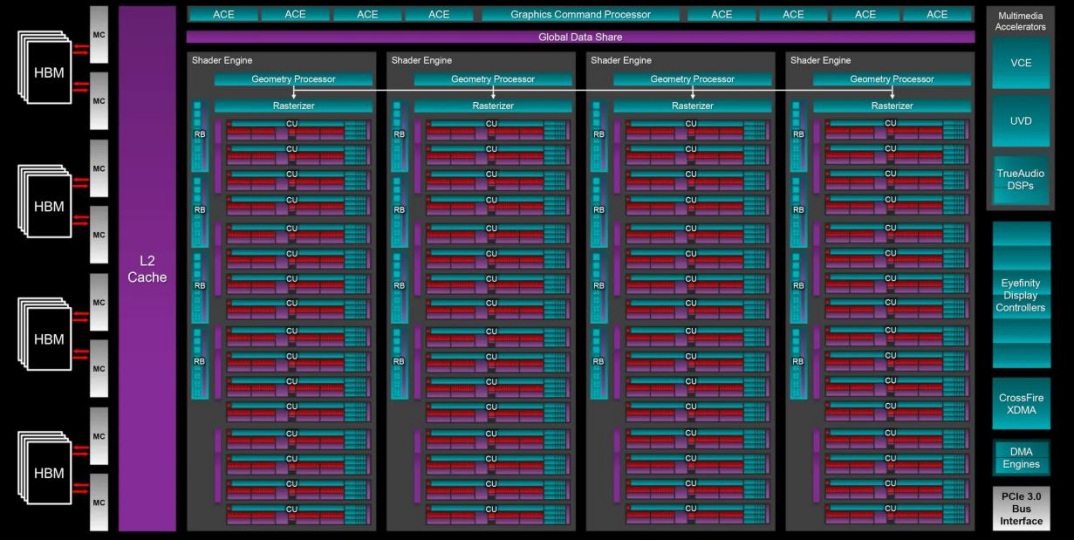
基于GCN的GPU基本上可以将队列分成三种不同的类型(分别用于图形命令、计算工作和数据事务),然后相应地对它们进行调度。然而,当时Direct3D API对该系统没有太多支持,尽管2015年Direct3D 12发布后,异步着色就风靡一时。AMD利用了这一点,使GCN更加专注于计算。
这一点从AMD在高端游戏显卡市场推出的最新产品——售价700美元的Radeon VII(见下图)中可以明显看出。它在4096位宽总线上拥有60个cu(完整芯片有64个cu)和16gb HBM2内存,绝对是一个GPU怪物。
与同样售价700美元的GeForce RTX 2080相比,它在某些游戏中可能会更快,但大多数基准测试结果表明,该架构并不适合现代3D游戏世界。
GCN 5.1主要用于专业工作站卡,Radeon VII本质上只不过是一款权宜之计的产品,专为游戏爱好者而设计,而下一代GPU正准备亮相。
仅仅四个月后,AMD发布了长期运行的GPU架构的继任者RDNA。通过这一新设计,AMD成功解决了GCN的大部分故障,第一款采用这种架构的显卡Radeon RX 5700 XT清楚地突显了它比GCN更适合游戏。
GPU的“一小步”
2017年推出Ryzen系列CPU时,采用了新的Zen设计,买家得到了全新的架构,从头开始重新构建。RDNA的情况并非如此,因为基本概念在本质上仍然类似于GCN。然而,几乎所有内部的东西都经过了调整,使游戏开发者更容易从GPU中获得最大可能的性能。

每个CU的SIMD计数从4个切换到2个,每个CU现在处理32个数据点,而不是16个。调度单元现在可以以32或64的批处理线程,在前者的情况下,SIMD单元现在可以被发出,并在每个周期处理一条指令。
仅这两个变化就使开发人员更容易让GPU保持忙碌,尽管这确实意味着编译器在选择正确的波大小进行处理时需要做更多的工作。AMD为计算和几何着色器选择了32,为像素着色器选择了64,尽管这并不是一成不变的。
CU现在是成对分组的(称为工作组处理器,WGP),而不是四元组,虽然指令和标量缓存仍然是共享的,但它们现在只需要为两个CU提供服务。最初的16kB L1缓存被调整并重新标记为L0,而新的128kB L1现在为四个WGP提供服务——两个WGP都具有128字节大小的缓存线(有助于提高内部带宽利用率)。
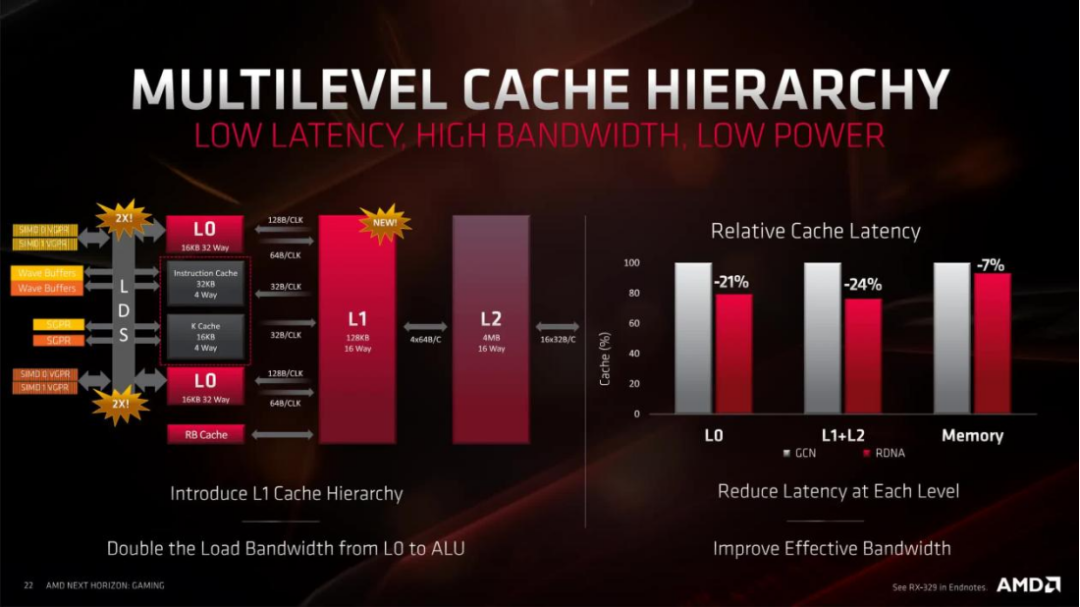
现在,GPU的每个部分都使用了无损数据压缩,全面降低了延迟,甚至更新了纹理寻址单元。所有这些更改都有助于减少移动数据、刷新缓存等所浪费的时间。
但也许RDNA第一个版本最令人惊讶的方面不是架构上的变化,而是它的第一次迭代是在中端、中等价位的显卡上。Radeon RX 5700 XT中的Navi 10芯片并不是一块巨大的硅片,里面装有计算单元,而是只有251平方毫米的大小和40个CU。它与Radeon VII中的Vega 20 GPU在同一台积电N7工艺节点上制造,体积小24%,这对晶圆产量来说非常好。
然而,它的CU也减少了38%,尽管就晶体管数量而言,人们不可能指望所有额外的更新和缓存都是免费的。但在游戏中测试时,它的平均速度仅比Radeon VII慢9%,最重要的是,它便宜了300美元。
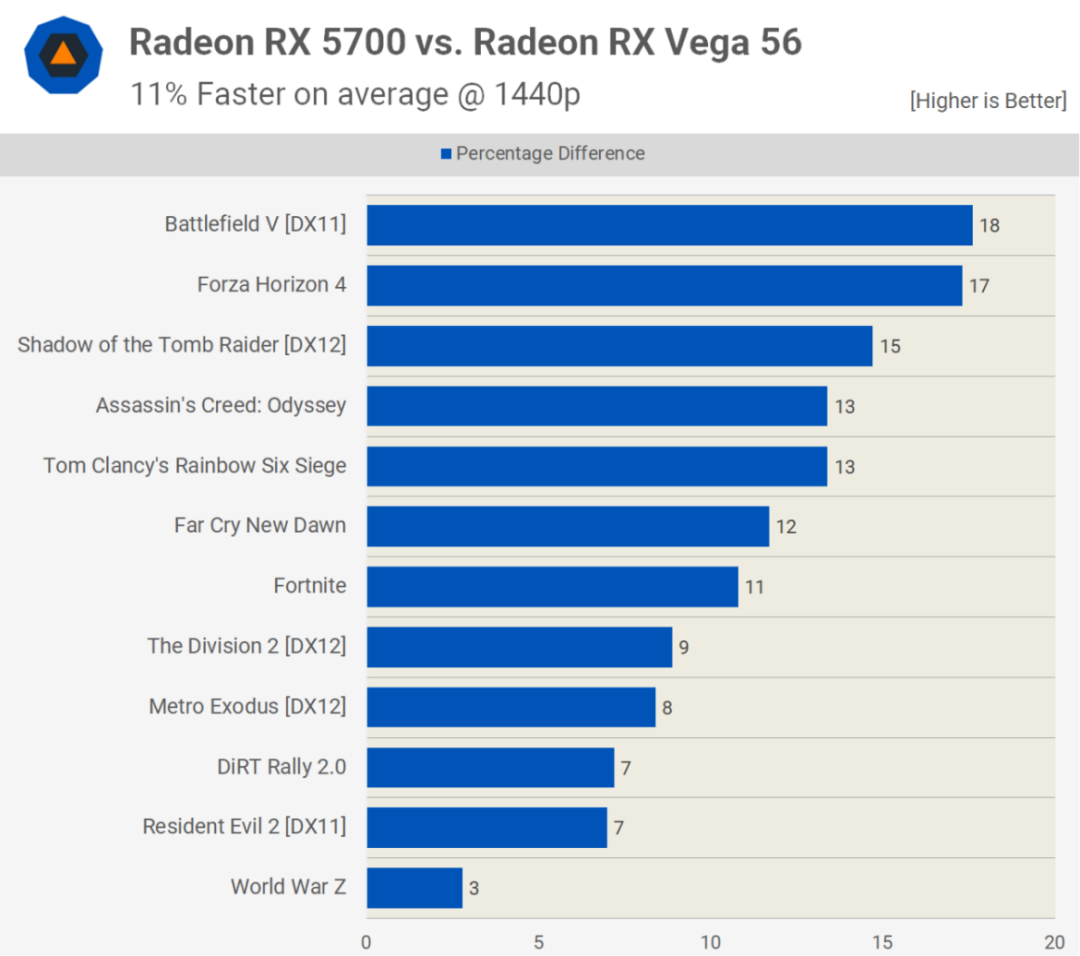
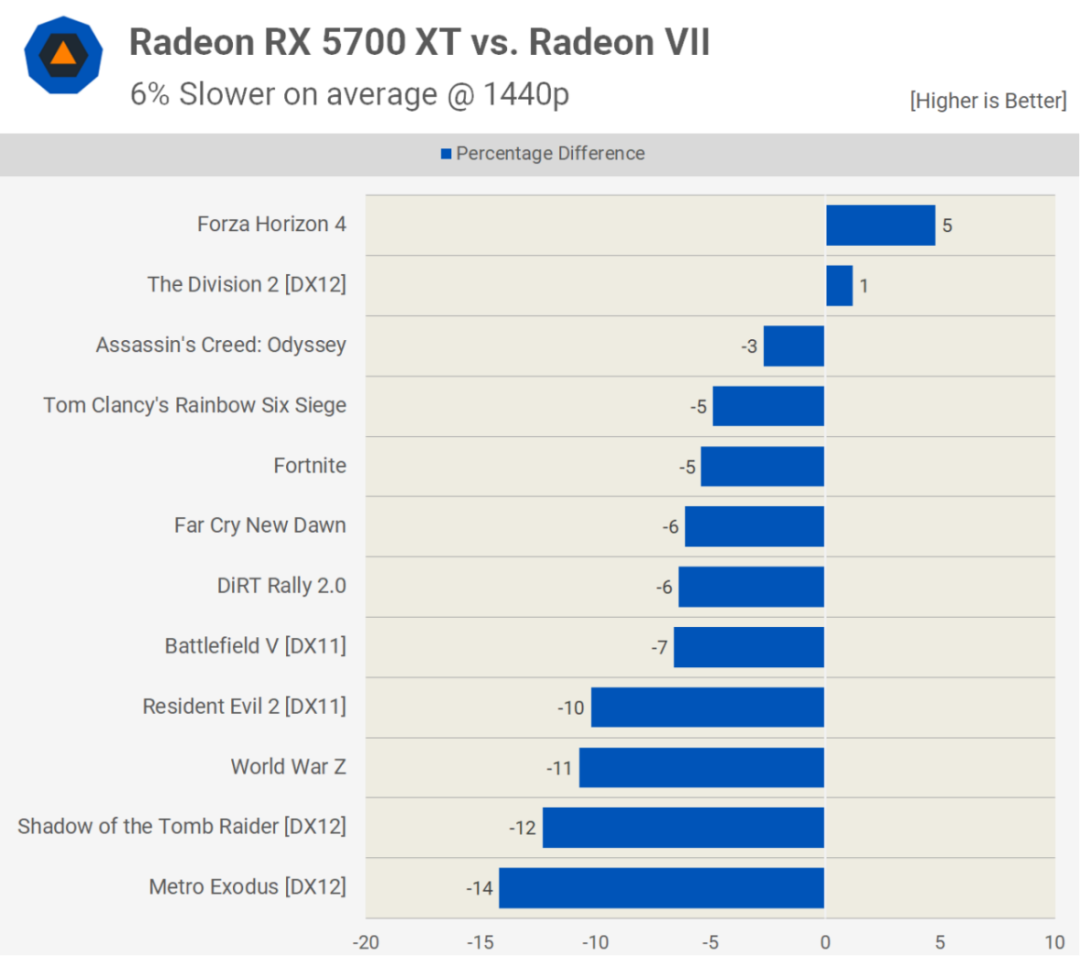
总的来说,它是新架构的一个有希望的入口,因为RDNA是朝着正确方向迈出的一步,尽管有点小。由于其性能介于Radeon RX Vega 56和Radeon VII之间,它在速度、功耗和零售价格之间取得了良好的平衡。
不过,新GPU的推出并非没有问题,尽管RDNA在近30种不同的产品中找到了归宿(通过三种芯片设计变体),但一些人对AMD没有更强大的产品可供销售感到失望。
幸运的是,他们不用等太久这一问题就能被解决。
RDNA第二轮
Radeon RX 5700 XT发布一年多后,当世界正在与全球疫情作斗争时,AMD发布了RDNA 2。从表面上看,除了两个新的东西之外,几乎没有什么变化——纹理单元被升级,以便它们可以执行光线三角形相交测试,并且添加了额外的最后一级缓存(LLC)。
前者是一个具有成本效益的补充,使GPU能够以最少的额外晶体管数量处理光线跟踪,但后者并不是零碎的产品,因为它远不止几MB。在GPU历史上,6MB的LLC被认为是“大”的,所以当AMD在第一个RDNA 2芯片Navi 21中硬塞进128MB时,它不仅震惊了GPU爱好者,而且永远改变了图形处理器的发展方向。

虽然由于芯片制造方法的改进,处理器变得越来越快,能力也越来越强,但DRAM却很难跟上。要使数十亿个微小的电容器收缩而不出现问题要困难得多。不幸的是,GPU越强大,就需要越多的内存带宽来保持数据。
英伟达选择采用美光的GDDR6X技术,并在GPU上添加大量内存接口来解决这个问题。然而,这种RAM比标准GDDR6更贵,额外的接口只会使芯片尺寸更大。AMD的方法是利用其CPU部门的缓存技术,并在其RDNA2芯片中注入大量LLC。
通过这样做,对容纳快速RAM的宽内存总线的需求显著减少,所有这些都有助于控制GPU芯片尺寸和显卡价格。芯片尺寸在这里很重要,因为Navi 21本质上是两个Navi 10(总共80个CU),都被一堵缓存墙包围。
后者由103亿个晶体管组成,而新芯片容纳了这个数字的两倍多——268亿个。额外的62亿美元主要用于所谓的无限缓存,尽管还有其他变化。AMD对整个架构进行了重新调整和精简,使RDNA 2芯片能够以比其前身更高的时钟速率运行。
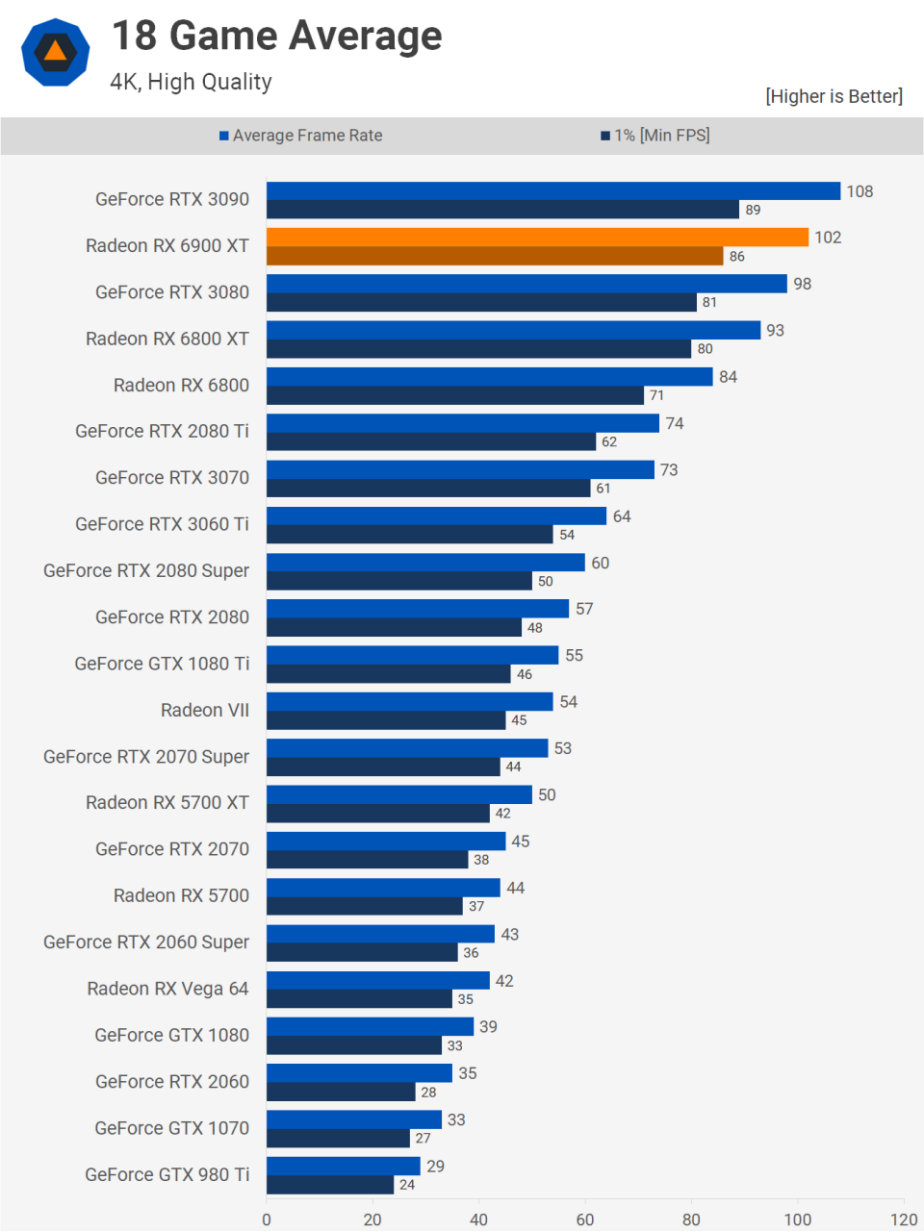
当然,如果最终产品不好,这些都无关紧要。尽管Radeon RX 6900 XT的售价为1000美元,但它提供了GeForce RTX 3090级别的性能,价格比它低500美元。它并不总是处于平均水平,根据所使用的游戏和分辨率,700美元的GeForce RTX 3080也一样快。
在这个价位,AMD的Radeon RX 6800 XT和RX 6800分别比RTX 3080低50美元和120美元。6800和RTX 3090的性能相差近30%,但价格相差63%。AMD可能没有赢得性能桂冠,但不可否认,在GPU价格无处不在的时候,这些产品仍然非常强大,物有所值。
但与此相反的是光线追踪性能。简言之,它远不如英伟达的Ampere GPU所实现的好,尽管考虑到这是AMD首次涉足物理正确光建模领域,其功能并不令人惊讶。

英伟达选择设计和实现两个大型定制ASIC(专用集成电路),用于处理射线三角形相交和BVH(边界体积层次结构)遍历计算,AMD选择了一种更温和的方法。对于后者,将没有专门的硬件,通过计算单元处理例程。
这个决定是基于保持模具尺寸尽可能小。Navi 21芯片相当大,面积为521平方毫米,虽然英伟达很乐意提供更大的处理器(RTX 3090中的GA102面积为628平方毫米),但增加定制单元会使该领域更加突出。

同年11月,微软和索尼发布了他们的新Xbox和PlayStation游戏机,这两款游戏机都采用了定制的AMD GPU(CPU和GPU在同一个芯片中),它使用RDNA 2来处理图形方面的问题,不包括Infinity Cache。由于需要保持这些芯片尽可能小,AMD选择这一特定路线的原因变得非常清楚。
这一切都是为了改善其图形部门的财务状况。
资金和利润很重要
在2021年下半年之前,AMD仅将其收入和营业收入数据分为两个部门:处理器和显卡,以及企业、嵌入式和半定制。笔记本电脑中显卡和独立GPU的销售收入流入前者,而Xbox和PlayStation主机的APU销售收入流入后者。
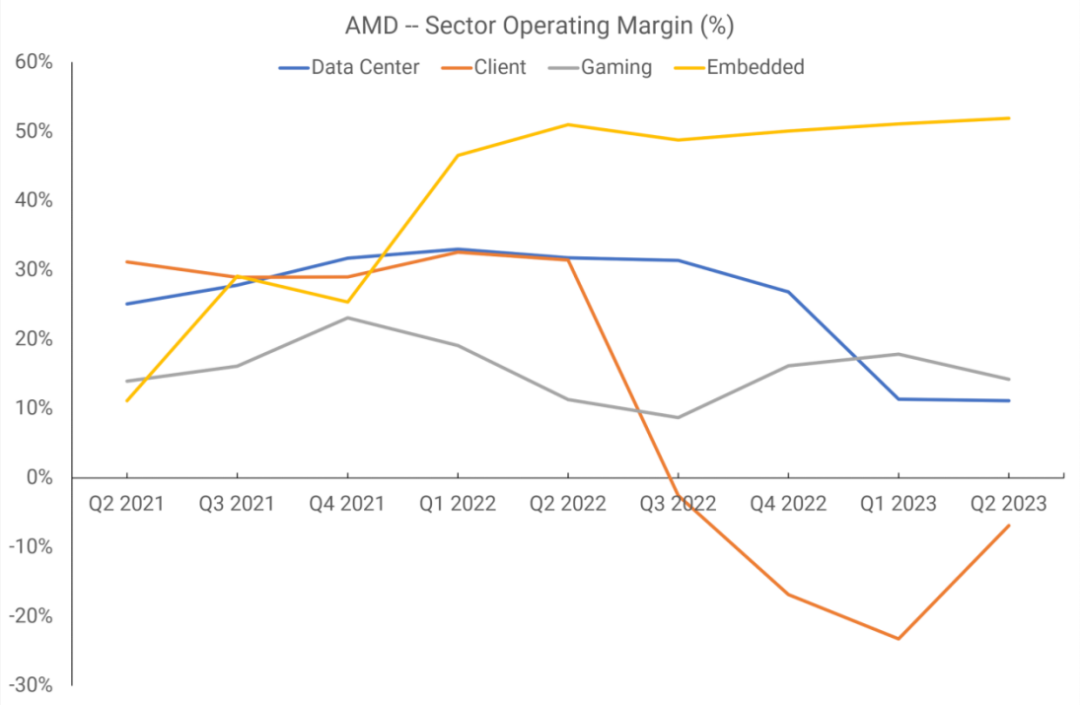
下图是2018年第一季度到2021年第一季度的营业利润率情况。
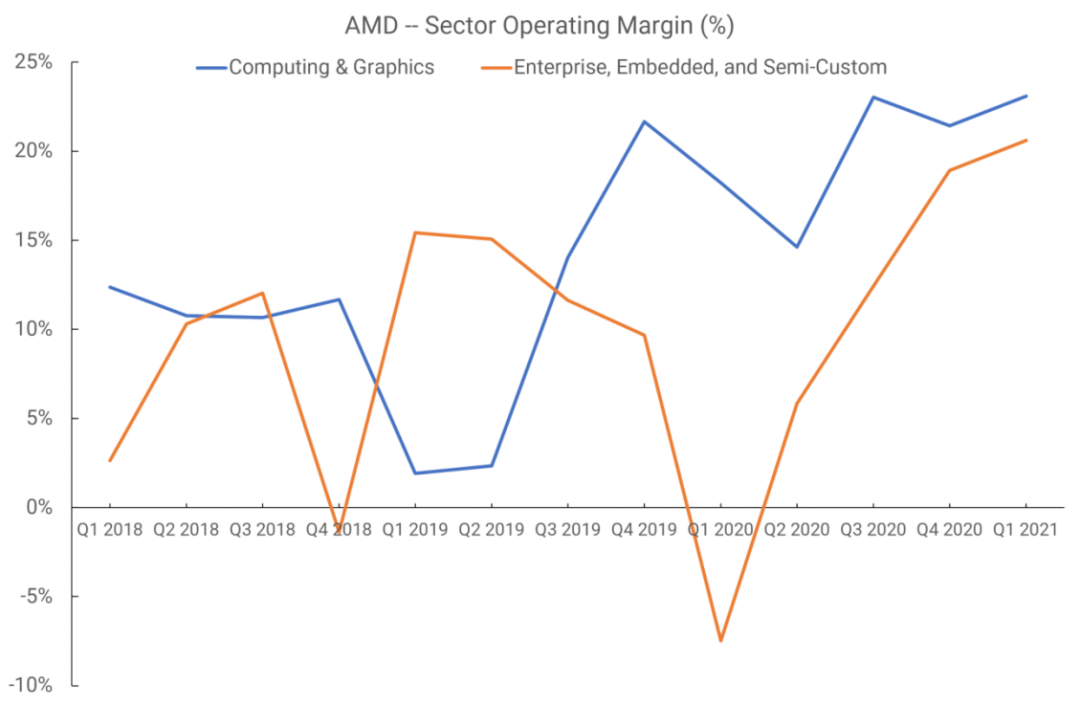
RDNA于2019年第二季度推出,但这种销售的收入要到下个季度才会真正开始显现,因为只有两种型号的显卡安装了这种新芯片。我们无法判断运营利润率的增长是否得益于GPU架构,因为这些数据还包括CPU销售。
然而,从2021年第二季度开始,AMD将报告部门重新划分为四个部门:数据中心、客户端、游戏和嵌入式。第三个部门涵盖了所有与GPU相关的内容,包括最终出现在主机中的APU,并且画面更加清晰。
现在可以看到,AMD的显卡部门的利润是四个部门中最弱的。AMD曾表示,在2022财年,仅一家客户就贡献了该公司全部收入的六分之一,其他人猜测这家客户就是索尼。如果情况确实如此,那么PlayStation 5 APU的销售额就占了游戏行业收入的50%以上。
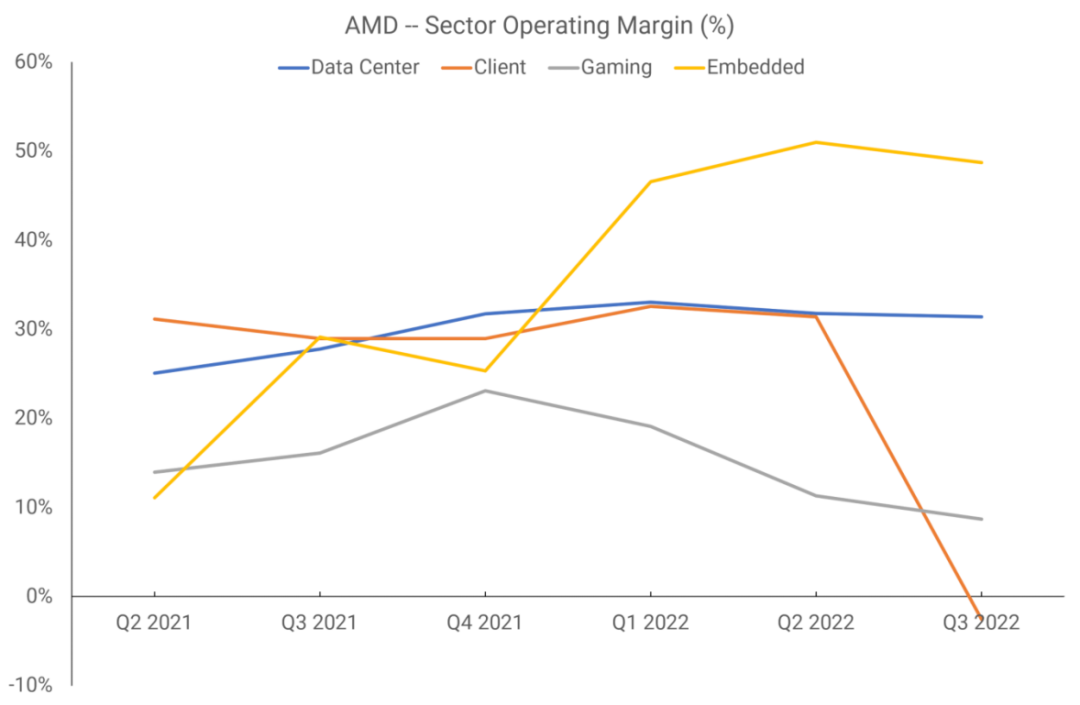
在那个财政年度,独立显卡的发货量急剧下降,毫无疑问,该部门的运营利润率是由游戏机销售保持的。AMD使用台积电制造绝大部分芯片,但订单必须提前几个月下——如果处理器在制造后没有很快售出,它们必须留在配送中心,这损害了这段时间的利润率。
目前还没有足够的信息来判断AMD在RDNA上的投资是否盈利,因为不可能将对Zen的投资与数据中心和游戏的利润分开。但收入数据显示,在以上6个季度中,平均16亿美元的收入导致了平均15%的营业利润率——只有客户端部门低于这个数字,这主要是由于个人电脑销售的下滑。
与此同时,在同一时期,英伟达的图形部门(包括台式机、笔记本电脑、工作站和汽车等的图形处理器)平均每季度收入约为36亿美元,平均营业利润率为43%。这家绿色巨头在独立GPU市场上的市场份额比AMD大,所以更高的收入数字并不令人惊讶,但营业利润率却令人大开眼界。

大部分PS5的APU是一个RDNA2 GPU。来源:Fritzchen Fritz
但值得考虑的是,AMD卖给微软和索尼的APU不会有很大的利润,因为如果他们有,你就不可能花400美元买到一台最新的游戏机了。一体机芯片的大规模生产有利于增加收入,但对直接利润的影响不大。
如果去掉主机芯片带来的收入,假设它们产生10%的利润,这就意味着RDNA产生了相当多的利润——运营利润率可能高达20%。虽然比不上英伟达,但我们都知道为什么这家公司的利润率如此之高。
Chiplets与计算
对于AMD来说,RDNA 2无疑是一个工程上的成功,该设计在近50种不同的产品中得到了应用。然而,从财务角度来看,与其他领域相比,GPU一直处于次优地位。与此同时,AMD发布了对RDNA的首次更新,该公司还宣布了一种新的仅用于计算的架构,称为CDNA。
这是GCN的哥斯拉,第一个使用该设计的芯片(Arcturus)拥有128个CU,在750 mm2的芯片中。计算单元已经升级为专用矩阵单元(类似于英伟达的Tensor),在接下来的一年里,AMD将两个巨大的处理器装进了一个724平方毫米的芯片中。它的代号为Alderbaran(下图),很快成为许多超级计算机项目的首选GPU。
回到游戏图形领域,AMD希望更多地利用其CPU专长。RDNA 2中的无限缓存是由于为其Zen处理器开发高密度L3缓存和无限Fabric互连系统而产生的。
因此,对于RDNA 3来说,很自然地,它将使用另一个CPU成功:chiplets。
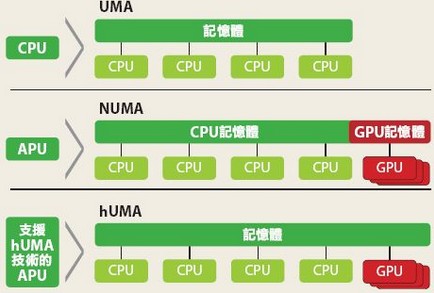
但是怎么做呢?在中央处理器中物理分离内核要容易得多,因为它们完全独立运行。在绝大多数AMD的台式PC、工作站和服务器cpu中,你会发现至少有两个所谓的chiplets:一个容纳核心(核心复杂芯片,CCD),另一个容纳所有输入/输出结构(IOD)。它们之间的主要区别是CCD的数量。
在GPU中做这样的事情是一项艰巨得多的任务。Navi 21 GPU是一个由四个独立处理器组成的大块,每个处理器包含10个WGP、光栅化器、渲染后端和L1缓存。有人可能会认为这些将是分离成离散chiplets的理想选择,但是大量数据事务所需的互连系统将抵消任何成本节约,并增加了许多不必要的复杂性和功耗。
对于RDNA 3, AMD采取了一种更慎重的方法,一种产生于越来越小的工艺节点所面临的限制。当台积电等公司宣布一种新的制造工艺时,通常会提出更高的性能、更低的功耗和更高的晶体管密度。
然而,后者是一个整体数字——晶体管和其他与逻辑和处理相关的电路当然在继续缩小,但与信号和存储器有关的任何东西都没有缩小。SRAM使用一组晶体管作为易失性存储器的一种形式,但这种排列不能像逻辑那样被压缩。
随着USB、DRAM等的信号传输速度不断提高,将这些电路更紧密地封装在一起会导致各种干扰问题。台积电的N5工艺节点的逻辑密度可能比N7高20%,但SRAM和IO电路只好几个百分点。
这就是为什么AMD选择将VRAM接口和L3无限缓存推到一个芯片中,而将GPU的其余部分推到另一个芯片中。前者可以用更便宜、更不先进的工艺制造,而后者可以利用更好的东西。
2022年11月,AMD以Navi 31 GPU的形式推出了RDNA 3。主芯片(称为图形计算芯片,GCD)是在台积电的N5工艺节点上制造的,包含96个计算单元,芯片面积仅为150平方毫米。围绕它的是6个内存缓存芯片(MCD),每个芯片只有31mm2的硅,包括16MB的无限缓存,两个32位GDDR6接口和一个无限链接系统。
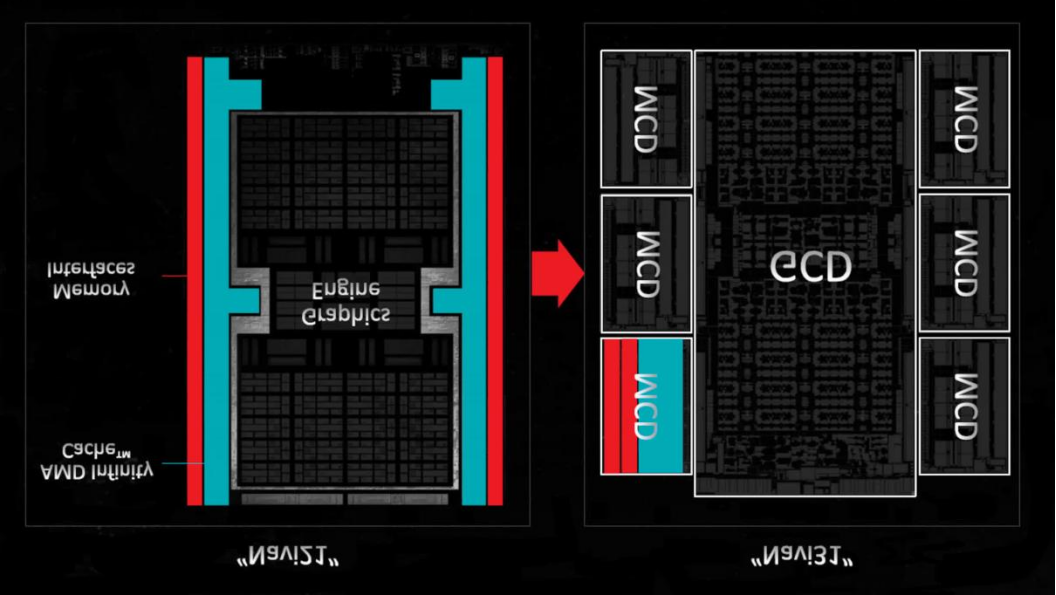
如果AMD在Navi 31上坚持采用单片方法,那么整个芯片的尺寸可能只有500到540平方毫米左右,并且不需要在所有chiplets之间建立复杂的连接网络,那么将它们全部封装起来也会更便宜。
AMD已经为这一切计划了很多年,所以它显然在盈利方面做得很好。这一切都源于晶圆产量和芯片制造成本的增加。让我们用一些估计的价格来强调这一点——用于制造MCD的单个N6晶圆可能是12,000美元,但它可以产生超过1,500个这样的芯片(每个芯片8美元)。一块1.6万美元的N5晶圆可能生产150块GCD,每个晶圆的价格为107美元。
将一张GCD与6张MCD组合在一起,在你需要将它们包装在一起的成本加进去之前,你需要花费154美元左右。另一方面,来自N5晶圆的单个540 mm2芯片的成本可能在250美元左右,因此使用chiplets的成本效益是显而易见的。
前沿与保守变革
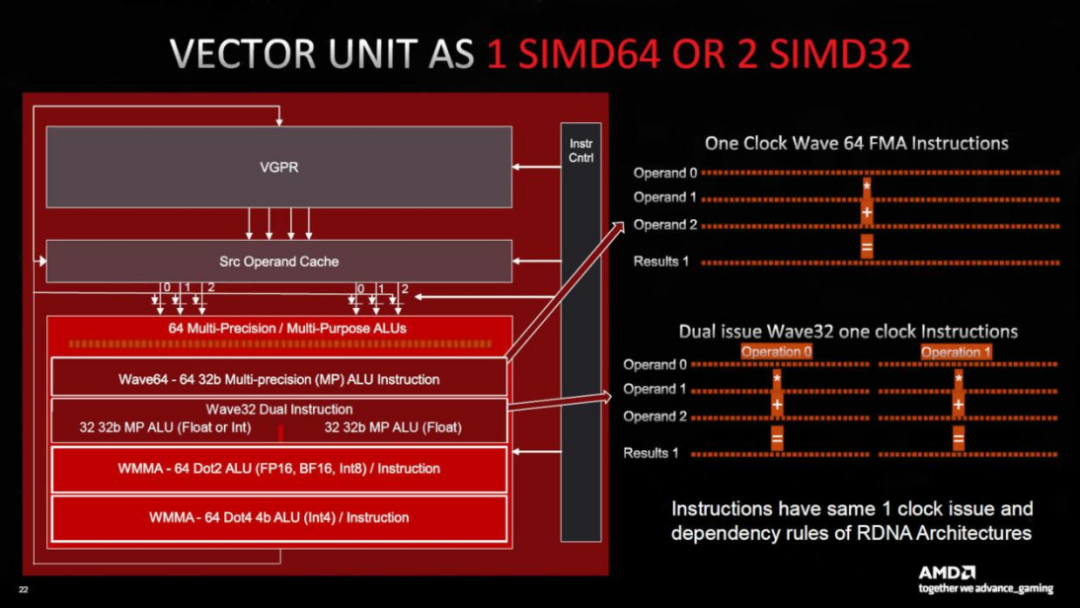
与RDNA 3小片段的使用一样大胆,其余的更新则更为保守。寄存器文件以及L0、L1和L2缓存的大小都增加了,但是L3无限缓存的大小减小了。每个SIMD单元扩展到同时处理64个数据点,因此wave64处理现在是单周期的。
光线追踪性能得到了适度的提升,通过调整单元来提高光线三角形相交的吞吐量,但在这方面没有其他专门的硬件。CDNA的矩阵单元也没有被复制到RDNA上——这样的操作仍然由计算单元处理,尽管RDNA 3确实有一个“人工智能加速器”(AMD对这个单元的功能几乎没有说)。
新设计的处理性能引起了相当大的轰动,“双重问题”一词被广为流传。当使用时,它允许SIMD单元同时评估两条指令,AMD的营销部门通过声明RDNA 2的峰值FP32吞吐量加倍来证明这一点。
唯一的问题是,执行双重指令的能力严重依赖于编译器(将程序代码转换为GPU操作的驱动程序中的程序)能够发现何时可能发生这种情况。编译器在这方面做得并不好,通常需要训练有素的人眼输入才能获得最佳结果。
搭载RNDA 3芯片的最强大显卡是Radeon RX 7900 XTX,它一上市就受到了好评,价格为1000美元。虽然通常不如英伟达的GeForce RTX 4090快,但它肯定可以与RTX 4080相媲美,从那以后的几个月里,AMD的降价使它成为一个更好的选择。
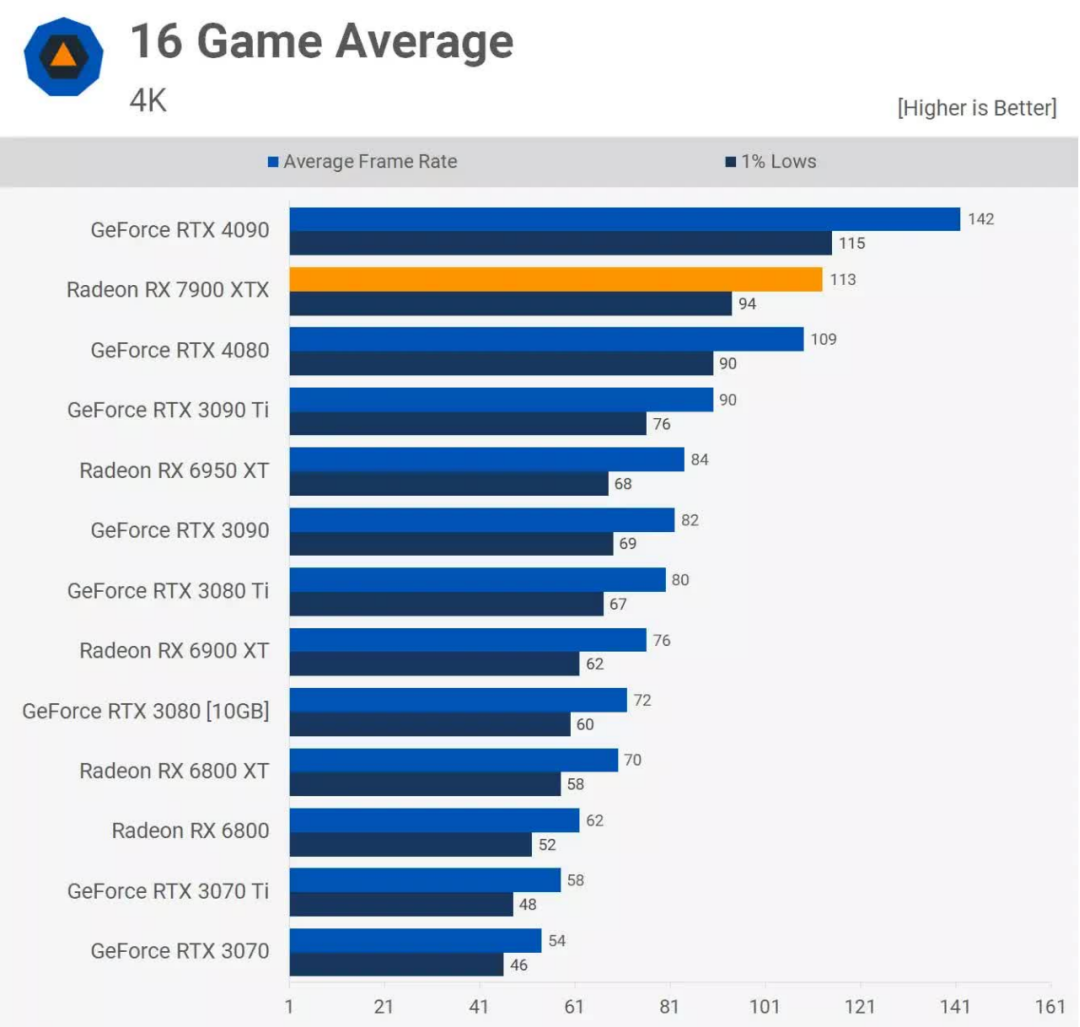
光线追踪再一次不是一个优势,尽管声称提高了电源效率,但许多人对Navi 31所需的电量感到惊讶,尤其是在空闲时。虽然它确实比以前的Navi 21需要更少的功率,但对Infinity Link系统的需求部分抵消了使用更好的处理节点所带来的好处。
与RDNA 2相比,另一个不足之处是产品范围的广度。在撰写本文时,RDNA 3可以在18个不同的产品中找到,尽管市场状况可能迫使AMD在这件事上采取行动。
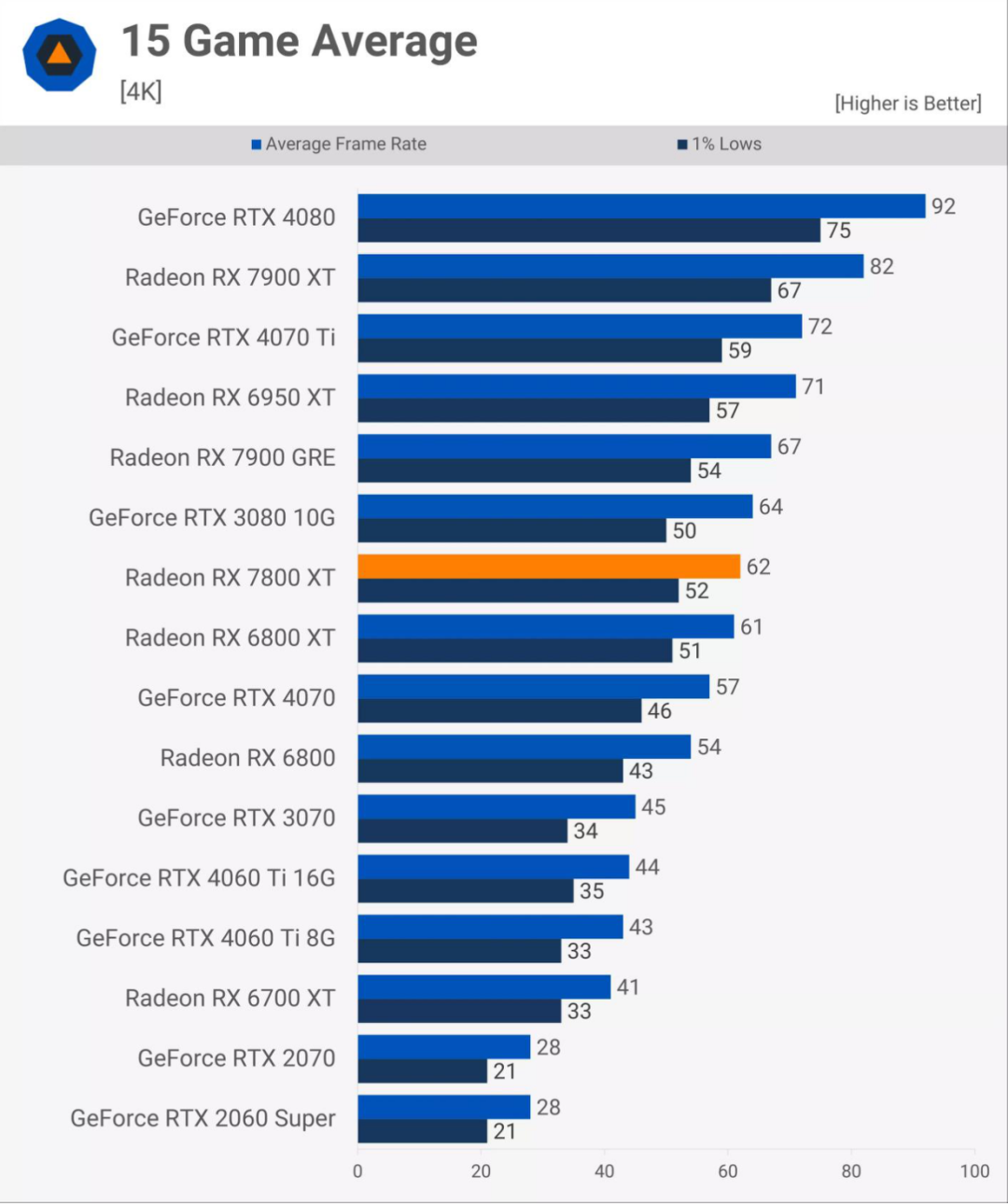
对一些人来说,更糟糕的是,当中低端RDNA 3显卡最终出现时,它们相对于旧设计的性能改进有些被低估了——以Radeon RX 7800 XT为例,它只比即将推出的RX 6800 XT快了几个百分点。
chiplets的使用似乎并没有给AMD的营业利润率带来多少好处。在RDNA 3出现后的三个季度中,游戏部门的收入和利润率基本保持不变。当然,新的GPU实际上有可能有所改善,因为如果控制台APU销量下降,那么财务状况保持不变的唯一途径似乎是GPU变得更有利可图。
然而,AMD不再只向微软和索尼销售APU。掌上电脑,如Valve的Steam Deck,越来越受欢迎,由于所有这些电脑都配备了AMD芯片,这些销售额将为游戏部门的银行余额做出贡献。
RDNA的未来
如果盘点一下AMD在四年时间里通过RDNA所取得的成就,并评估这些变化的总体成功,最终结果将从Bulldozer和Zen之间得出。前者最初对该公司来说是一场近乎灾难性的产品,但多年来因制造成本低廉而挽回了自己。另一方面,Zen从一开始就表现出色,并迫使整个CPU市场发生了翻天覆地的变化。
在这段时间里,AMD在独立GPU领域的市场份额略有波动,有时会超过英伟达,有时会失去,但总的来说,它保持不变。
自成立以来,游戏部门已经获得了少量但稳定的利润,尽管利润率目前似乎在下降,但没有迹象表明厄运即将来临。事实上,仅就利润率而言,这是AMD第二好的部门。即使不是这样,AMD从嵌入式业务中赚取的现金(多亏了收购赛灵思)也绰绰有余,足以避免任何短期的整体亏损。
但AMD接下来将走向何方?
只有三种前进的道路:第一种是保持目前的小架构更新进程,继续积累微薄的利润,并保持整个GPU市场的一小部分。第二种是放弃高端桌面GPU领域,完全专注于主导预算和低端市场,专注于进一步缩chiplet尺寸和提高晶圆产量的技术。
第三条路线与第二条截然相反——忘记“物有所值”和拥有一个可以扩展到所有可能级别的架构,并尽一切努力确保它是Radeon显卡,而不是GeForce显卡,在每个性能图表中都名列前茅。
英伟达在RTX 4090上实现了这一点,因为它使用了台积电最好的工艺节点,就着色单元而言,它是能买到的最大的消费级GPU。没有什么花哨的把戏——这是一种蛮力的方法,而且效果很好。RTX 4080中的整个AD103芯片仅比Navi 31中的GCD大20%,并且具有相当相似的性能。
然而,RDNA一直致力于最大限度地利用现有的处理能力。RDNA 2/3中缓存系统的复杂性证明了这一点,因为英特尔和英伟达在他们的GPU中使用了更简单的结构。
说到缓存,决定将大量的最后一级缓存插入RDNA GPU以抵消对超高速VRAM的需求,并提高光线追踪性能,几乎可以肯定是英伟达在Ada Lovelace架构上做同样事情的灵感。
现在正处于GPU发展的一个阶段,不同厂商设计图形处理器的差异相对较小,仅从架构设计就能看到性能的巨大改进的日子已经一去不复返了。
未来的RDNA GPU会像英特尔的Ponte Vecchio一样多的芯片吗?
如果AMD想要独占鳌头,它就需要推出一款拥有比我们目前看到的更多计算单元的RDNA GPU。或者只是更有能力的—RDNA 3中SIMD单元的变化可能是一个信号,表明在下一个版本中,我们可能会看到CU使用四个SIMD而不是两个,以消除所有的双重发行限制。
但即便如此,AMD仍需要拥有更多的CU,而实现这一目标的唯一途径是拥有更大的GCD,这意味着接受更低的产量或将芯片转移到更好的工艺节点上。当然,这两项都会影响利润率,而且与英伟达不同,AMD似乎不愿将GPU价格推高。
它也不太可能采取第二条路线,因为一旦完成了这一点,就几乎没有机会回来了。GPU的历史上有很多公司尝试过,失败过,一旦他们停止了在高端市场的竞争,就永远消失了。
这就剩下了一个选择——继续当前的行动方针。在架构方面,英伟达已经对其着色器内核进行了多年的重制,只有过去两代才显示出许多相似之处。它还在开发和营销机器学习和光线追踪功能方面投入了大量资源,前者与GeForce品牌有着独特的联系。
AMD多年来开发了许多技术,但在RDNA时代,它们都没有特别要求Radeon显卡来使用它们。凭借其Zen架构和其他CPU发明,AMD将计算世界带入了未来,迫使英特尔提高其游戏水平。它为大众带来了高能效的多线程处理——不是通过成为英特尔的廉价替代品,而是通过竞争。胜利,迎头而上。
不可否认,RDNA是一个成功的设计,因为它的使用是如此广泛,但它肯定不是Zen。如果游戏行业想要发展的话,仅仅做到物有所值或者以开源方式获得社区的喜爱是不够的。AMD似乎拥有实现这一目标的所有工程技术和诀窍;他们是否会冒险完全是另一回事。
俗话说,幸运眷顾勇者。
编辑:黄飞















 工商网监
工商网监
评论