 电子发烧友App
电子发烧友App


新的一年已经成为我们一段时间以来数据中心芯片领域最重要的一年。每个主要芯片公司都计划在未来 12 个月内更新其 CPU 和/或 GPU 产品线。
Nvidia 计划在 2024 年推出大量新的加速器、GPU 架构和网络套件。英特尔将与新的 Habana Gaudi AI 芯片一起推出可以说是多年来最引人注目的 Xeon。与此同时,AMD 凭借 MI300 系列的推出,计划将其第五代 Epyc 处理器推向市场。
让我们深入了解 2024 年我们关注的一些大型数据中心芯片的发布(排名不分先后)。
01. Nvidia 搭载 HBM3e 的 H200 AI 芯片到货
Nvidia 的 H200 加速器将是 2024 年首批投放市场的新芯片之一。GPU 本质上是久负盛名的 H100 的更新版。
您可能期望最新的芯片能够比老款芯片提供更高的性能提升,但事实并非如此。仔细阅读规格表,您会发现浮点性能与 H100 相同。相反,该部件的性能提升(Nvidia 声称 Llama 70B 等 LLM 的性能提升了一倍)取决于该芯片的 HBM3e 内存堆栈。
我们承诺 H200 将配备高达 141 GB 的 HBM3e 内存,可实现高达 4.8TB/s 的带宽。随着 LLM 的普及(例如 Meta 的 Llama 2、Falcon 40B、Stable Diffusion 等),内存容量和带宽对推理性能产生巨大影响,即单个加速器或服务器可以容纳多大的模型,以及您可以同时处理多少个请求。
正如我们最近在对 AMD 和 Nvidia 基准测试失败的分析中所探讨的那样,对于此类 AI 工作负载,FLOPS 并不像内存容量和带宽那么重要。
02. Hopper的继任者采用“Blackwell”架构
根据 2023 年的投资者演示,H200 将不会是我们在 2024 年看到的 Nvidia 唯一的 GPU。为了巩固其领导地位,Nvidia 正在转向每年发布新芯片和我们看到的第一个新部件的发布节奏。格林队将成为 B100。
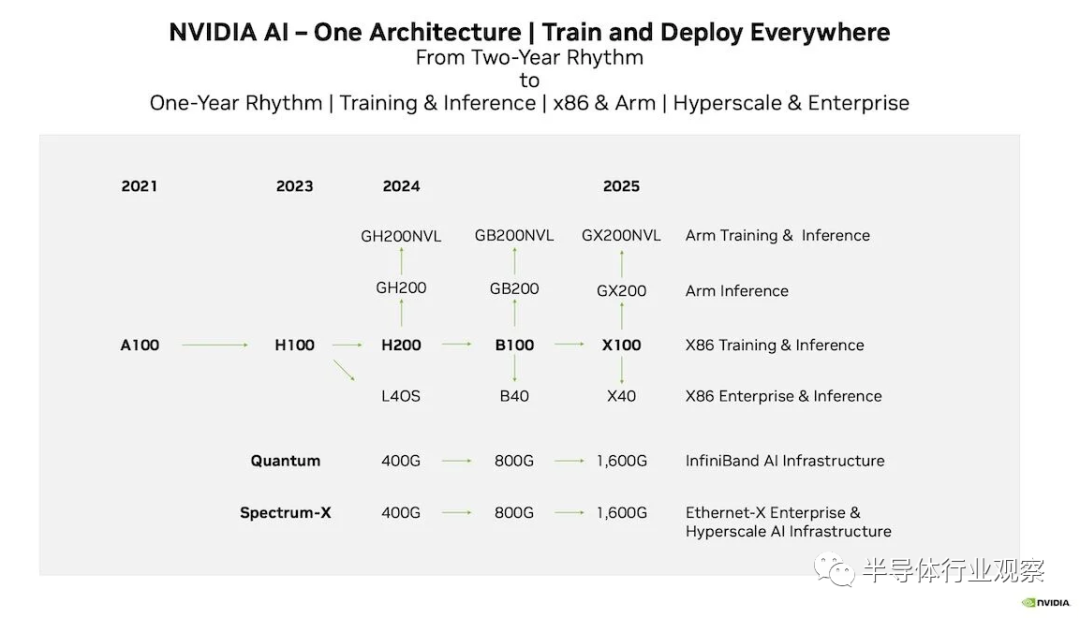
据我们了解,这里的“B”是微架构名称 Blackwell 的缩写,大概是对美国统计学家 David Blackwell 的致敬。除了 2024 年推出之外,我们对该部件的了解仍然不多。
就目前情况而言,AMD 新推出的 MI300X GPU 不仅比 H200 具有更高的 FLOPS,而且还具有更多、更快的启动内存。我们无法想象英伟达对此感到高兴,特别是考虑到这家美国巨头最近的防御性有多强。因此,我们完全期望 B100 能够提供更高的 FLOPS 和更多的 HBM3e 堆栈,从而将加速器的内存容量和带宽推向新的高度。
除了 GPU 本身之外,Nvidia 的路线图还包括更多 CPU-GPU 超级芯片,称为 GB200 和 GB200NVL。这些处理器是否会继续使用当前 Grace 和 Grace-Hopper 超级芯片中基于 Arm Neoverse V2 的 CPU 内核,或者是否会采用一些下一代内核,还有待观察。
然后是B40。从历史上看,此类卡针对的是可以在单个 GPU 中运行的较小企业工作负载。该部件将取代 L40 和 L40S,并将 Nvidia 的企业 GPU 系列整合到单一总体架构下。
可以说,英伟达加速路线图中最有趣的部分与网络有关。Nvidia 正在寻求与 Blackwell 实现 800Gb/s 连接,尽管正如我们之前探讨的那样,这带来了一些独特的挑战,因为 PCIe 5.0 的速度还远远不够,而 PCIe 6.0 仍然有一些距离。
当我们看到这些Blackwell仍然悬而未决时,但是,如果历史可以回顾的话,我们可能不必等待那么久。Nvidia 在加速器实际可供购买之前几个月(当然有时是几年)预先发布加速器的历史由来已久。
Nvidia 在 2022 年初预告了其 Grace-Hopper 超级芯片,但据我们了解,这些部件现在才进入客户手中。因此,我们最早可以在 GTC 上获得有关基于 Blackwell 的部件的更多详细信息。
03. 英特尔推出自己的全新加速器迎接新年
与加速器主题保持一致,英特尔计划于 2024 年某个时候发布其第三代 Gaudi AI 芯片。
这一部分意义重大,因为随着Ponte Vecchio后继者Rialto Bridge的取消,Habana Lab 的 Gaudi3 代表了英特尔提供的最好的人工智能训练和推理平台——至少在 Falcon Shores 于 2025 年到来之前是这样。
虽然英伟达和 AMD 几个月来一直习惯于调侃和炒作他们的产品发布,但英特尔却对此守口如瓶。到目前为止,我们看到的大部分内容都来自这张演示幻灯片,至少从9 月份的创新活动开始,它就一直在展示这张幻灯片:
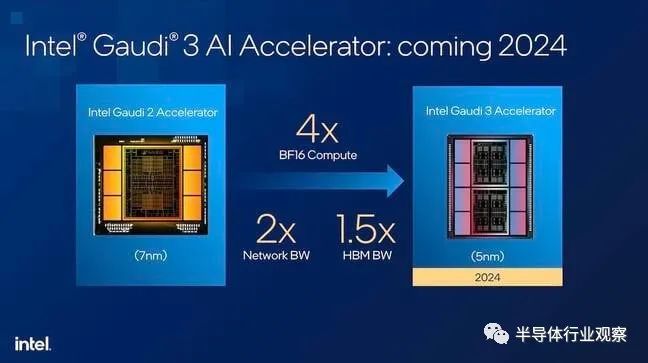
该幻灯片声称,5nm 芯片 Gaudi3 的 Brain Float 16 (BF16) 性能是 7nm 版本 2 的 4 倍,网络带宽是两倍,HBM 带宽是 1.5 倍。
通常这些数字可以为我们提供推断相对绩效数据的起点。不幸的是,要做到这一点,英特尔必须告诉我们 Gaudi2 的 BF16 性能实际上是什么。我们问过,他们不想谈论这个问题,尽管他们声称 Gaudi3 改进了 4 倍。相反,英特尔希望关注实际性能而不是基准比较。
坦率地说,这是一个令人困惑的营销决定,因为如果没有参考框架,这种说法基本上毫无意义。此外,从表面上看,x86 巨头这次使用了 8 个 HBM 堆栈,而不是 6 个。
除了 Gaudi3 之外,我们还获悉,Gaudi2 的版本将再次针对中国市场进行调低(以符合美国对中国的出口限制),英特尔声称它将在之前发货传闻中的Nvidia H20芯片已登陆大陆。
04. 英特尔与 Sierra Forest 携手加入云 CPU 队伍
与此同时,在 CPU 方面,英特尔计划在 2024 年推出一项双重功能,将使用其推迟已久的 Intel 3 处理技术。需要明确的是,英特尔并不是突然转向 3nm。多年来,该公司一直致力于这个节点(以前称为 7nm)。它最终被重新命名为 Intel 4 和 Intel 3,以使其在营销方面与竞争节点的晶体管密度更加一致。
我们将在 2024 年上半年推出首款基于 Intel-3 的 Xeon 处理器。该芯片代号为 Sierra Forest,可配备一对 144 核芯片,每个插槽总共有 288 个 CPU 核心。当然,这些核心与我们在过去的至强中看到的核心不同。它们是英特尔效率核心架构的演变,早在 2021 年,随着Alder Lake的推出,该架构就开始出现在 PC 和笔记本处理器中。
不过,虽然这些芯片通常配有一组性能核心,但 Sierra Forest 都是电子核心,旨在与 Ampere、AMD 以及 AWS 和微软等云提供商部署的大量定制 Arm CPU 竞争。
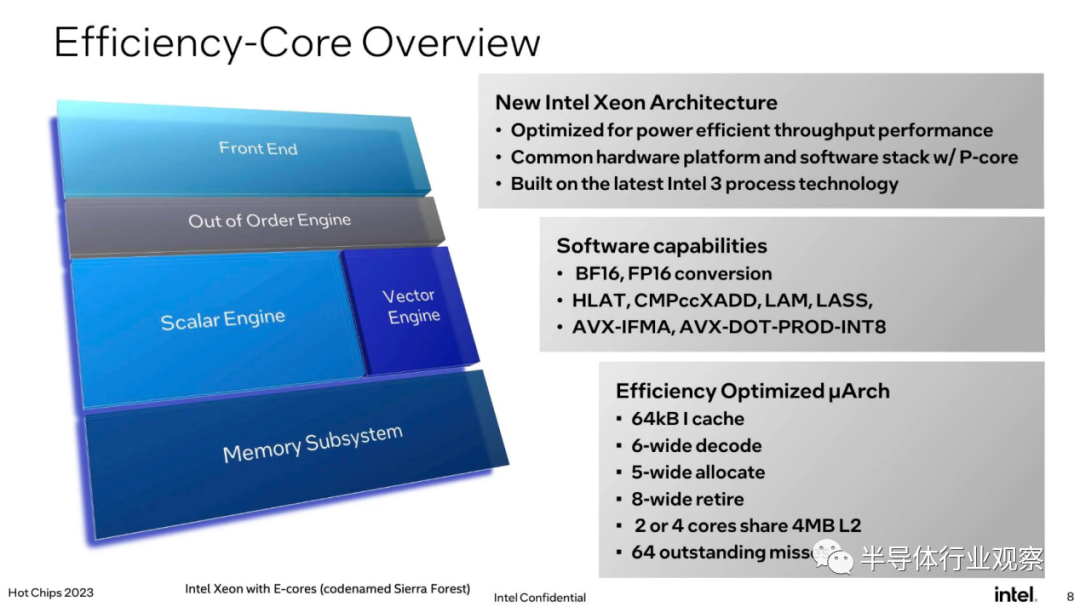
英特尔声称的优势在于,它可以在单个插槽或机箱中装入比其他任何产品更多的内核,同时保持与大多数 x86 二进制文件的兼容性。我们说“大多数”是因为 e-core 不具有与过去的 Xeon 相同的功能集。
两个最大的区别是完全缺乏 AVX512 和高级矩阵扩展 (AMX) 支持。这里的论点是,我们看到广泛部署在云中的许多工作负载(例如 Nginx)不一定受益于这些功能,因此,与其将大量的芯片空间专用于大型向量和矩阵计算,不如将该空间相反,可以用于将更多核心封装到每个芯片上。
然而,并非所有芯片公司都同意这种做法。AMD 于 2023 年春季推出的Bergamo Epycs 采用了截然不同的方法。这些服务器处理器使用 AMD Zen 4 核心的紧凑版本,称为 Zen 4c,以时钟速度换取更小的占地面积。这使得 AMD 能够将 128 个核心封装到每个处理器封装的 8 个计算芯片中,而无需牺牲功能。
两种方法都有优点。根据虚拟机管理程序的不同,缺乏某些 CPU 功能可能会导致将工作负载从一个机器迁移到另一个机器时出现问题。英特尔希望通过 AVX10 来克服这个问题,我们在今年夏天对其进行了深入研究。简而言之,它旨在向后移植许多更具吸引力的功能,例如从 AVX512 到 AVX2 的 FP16 和 BF16 支持。结果是您不太可能遇到这种迁移问题,除非您确实需要 512 位宽向量寄存器。
05. 英特尔与 Granite Rapids 脚踏实地
进入鲜为人知的领域,英特尔的 Granite Rapids Xeon 将于 2024 年晚些时候推出。虽然 Sierra Forest 优先考虑微型核心的负载,但 Granite Rapids 是围绕 x86 巨头的性能核心构建的更传统的Xeon 服务器处理器。
我们仍然不知道它将有多少个核心,也不知道顶级部件的时钟速度有多快,但我们被告知它将超过 Emerald Rapids。我们确实知道,该芯片将采用比 Sapphire 或 Emerald Rapids 更加模块化的小芯片架构,每个封装最多有五个芯片——三个计算芯片和两个 I/O。
根据 SKU 的不同,该芯片将配备更多或更少的计算芯片,使英特尔能够利用 AMD 多年来享有的模块化优势。此前,2023 年的 Xeon 要么在所谓的“极端核心数 (XCC) 芯片上配备一个大型中等核心数 (MCC) 芯片,要么在所谓的“极端核心数 (XCC) 芯片上配备两个大型 (Emerald) 或四个较小 (Sapphire) 计算芯片。
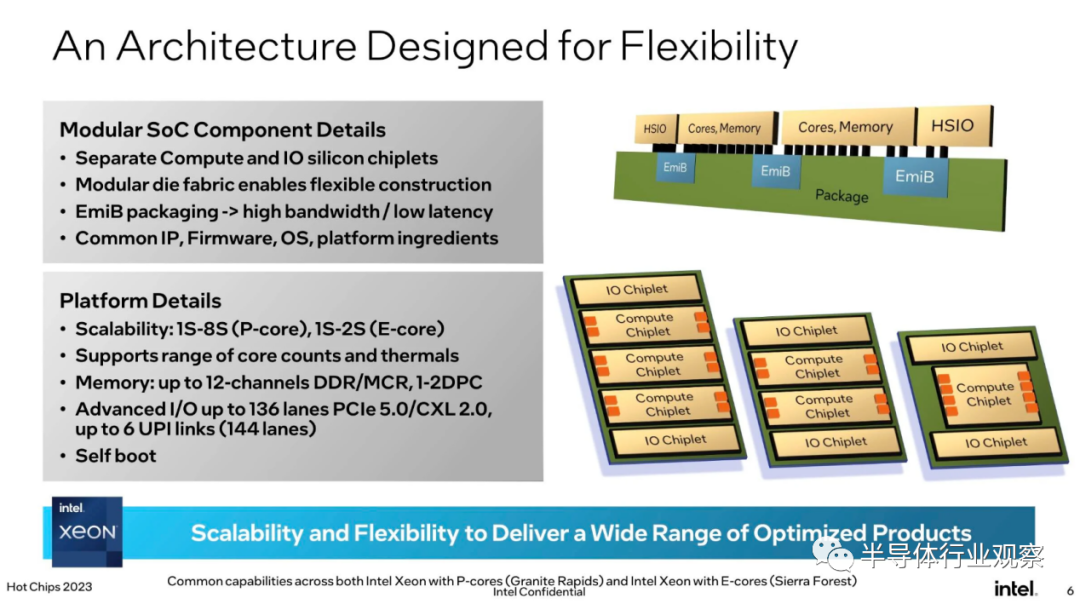
英特尔的下一代 Xeon 将 I/O 功能分解到一对三明治结构的芯片中。这些 I/O 芯片非常重要,因为它们有助于缩小与 AMD 的差距,AMD 不仅在过去五年中保持着核心数量优势,而且通常还提供更多、更快的 PCIe 通道和内存通道。
正如我们在 2023 年 Hot Chips 会议上了解到的那样,Granite Rapids 将具有 12 个内存通道(与 AMD 的 Epyc 4 相同),并将支持 8,800MT/s MCR DIMM。MCR 相当酷,因为它允许芯片向芯片提供 845GB/s 的内存带宽。这还达不到英特尔第 4 代 Xeon Max 部件通过板载 HBM所能达到的1TB/s速度,但 MCR DIMM 将接近并允许更高的容量。
该芯片系列还将支持多达 136 个 PCIe/CXL 通道,但仅支持 PCIe 5.0 速度。PCIe 6.0可能会在 2024 年推出,但对于英特尔的“下一代”Xeon 来说还来不及。
06. AMD Zen 5 来了
当然,AMD 将推出 Turin,这是其第五代 Epyc 服务器处理器,由新的 Zen 5 内核提供支持。目前,我们对这一部分没什么可说的,只能说它会在 2024 年的某个时候发布。
考虑到时间,我们可以做出一些假设。我们打赌该芯片将在其计算块中使用台积电的 4nm 或 3nm 工艺技术,但很难说 I/O 芯片是否会缩小工艺。
除此之外,我们只能指出最近通过 Xitter分享的泄密事件,这些泄密事件表明 AMD 可能会再次增加其产品线的核心数量。如果泄漏属实,我们可能会看到具有多达 128 个 Zen 5 核心或 192 个 Zen 5c 核心的 Epyc 处理器。
核心复合芯片 (CCD) 本身与Genoa和Bergamo相比似乎没有太大变化,每个小芯片分别有 8 个或 16 个核心。据报道,AMD 将在其通用用途上使用 16 个计算芯片,并在以云为中心的平台上使用 12 个计算芯片,以实现声称的核心数量。话虽如此,我们还得拭目以待,看看泄露的消息是否准确。
近年来,AMD 的 Eypc 产品线变得更加复杂,目前涵盖通用、高性能计算、云和边缘应用。AMD 传统上会在大约一年的时间内推出这些芯片。Epyc 4 于 2022 年 11 月推出,Bergamo 和 Genoa-X 于 2023 年 6 月推出,其专注于边缘的 Siena 部件直到 9 月份才出现。
07. 惊喜等待着您
需要绝对明确的是,这绝不是 2024 年即将推出的数据中心处理器的详尽列表。我们完全预计未来 12 个月将会出现更多惊喜,特别是随着人工智能炒作列车的速度加快以及云提供商继续拥抱定制硅。
微软最近涉足定制人工智能和 CPU 领域,而谷歌已经拥有几代张量处理单元,并且有传言称正在开发自己的 CPU。
我们还将关注 Arm 为推动其 Neoverse 核心架构和计算子系统 (CSS) IP 堆栈所做的努力。后者是我们所见过的 Arm 在现代最接近设计整个处理器的方式。
还有大量半导体S初创公司,如 Ampere、Graphcore、Cerebras、SambaNova、Groq 等,希望在人工智能新世界秩序中开辟一席之地。到 2024 年,如果看到这些供应商中的任何一家推出新芯片、产品和系统,我们都不会感到惊讶。
审核编辑:黄飞






















 工商网监
工商网监
评论