 电子发烧友App
电子发烧友App


01 术 语
CPU/GPU/NPU 等等都是硬件芯片,简单来说,晶体管既可以用来实现逻辑控制单元, 也可以用来实现运算单元(算力)。在芯片总面积一定的情况下,就看控制和算力怎么分。
CPU:通用目的处理器,重逻辑控制;
GPU:通用目的并行处理器(GPGPU),图形处理器;
NPU:专用处理器,相比 CPU/GPU,擅长执行更具体的计算任务。
CPU
大部分芯片面积都用在了逻辑单元,因此逻辑控制能力强,算力弱(相对)。
GPU
大部分芯片面积用在了计算单元,因此并行计算能力强,但逻辑控制弱。适合图像渲染、矩阵计算之类的并行计算场景。作为协处理器, 需要在 CPU 的指挥下工作。
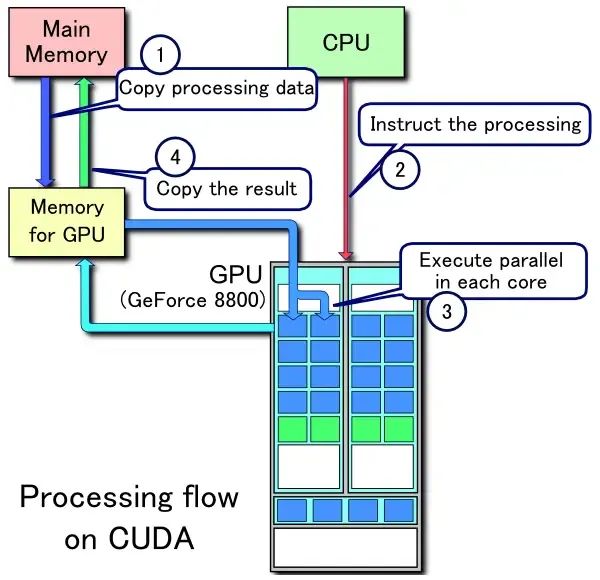
Image Source [8]
NPU / TPU
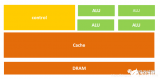
也是协处理器。在 wikipedia 中没有专门的 NPU (Neural Processing Unit) 页面,而是归到 AI Processors 大类里面, 指的是一类特殊目的硬件加速器,更接近 ASIC,硬件实现神经网络运算, 比如张量运算、卷积、点积、激活函数、多维矩阵运算等等[7]。 如果还不清楚什么是神经网络,可以看看 以图像识别为例,关于卷积神经网络(CNN)的直观解释(2016)。 在这些特殊任务上,比 CPU/GPU 这种通用处理器效率更高,功耗更小,响应更快 (比如一个时钟周期内可以完成几十万个乘法运算), 因此适合用在手机、边缘计算、物联网等等场景。 TPU:这里特制 Google 的 Tensor Processing Unit,目的跟 NPU 差不多。[11] 对 TPU 和 GPU 的使用场景区别有一个非常形象的比喻: 如果外面下雨了,你其实并不需要知道每秒到底有多少滴雨, 而只要知道雨是大还是小。与此类似,神经网络通常不需要 16/32bit 浮点数做精确计算,可能 8bit 整型预测的精度就足以满足需求了。
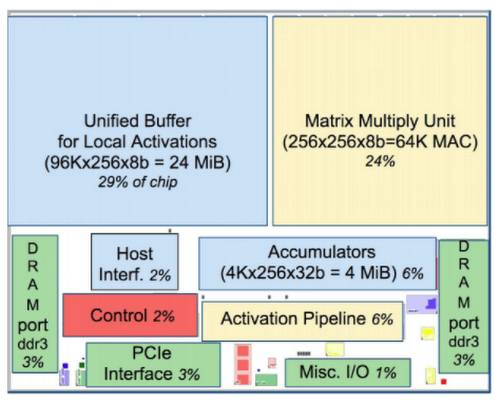
Floor Plan of Google TPU die(yellow = compute, blue = data, green = I/O, red = control) [11]
小 结
GPU 已经从最初的图像渲染和通用并行计算,逐步引入越来越多的神经网络功能 (比如 Tensor Cores、Transformer);另一方面,NPU 也在神经网络的基础上,开始引入越来越强大的通用计算功能, 所以这俩有双向奔赴的趋势。 02 华为 DaVinci 架构:一种方案覆盖所有算力场景
场景、算力需求和解决方案
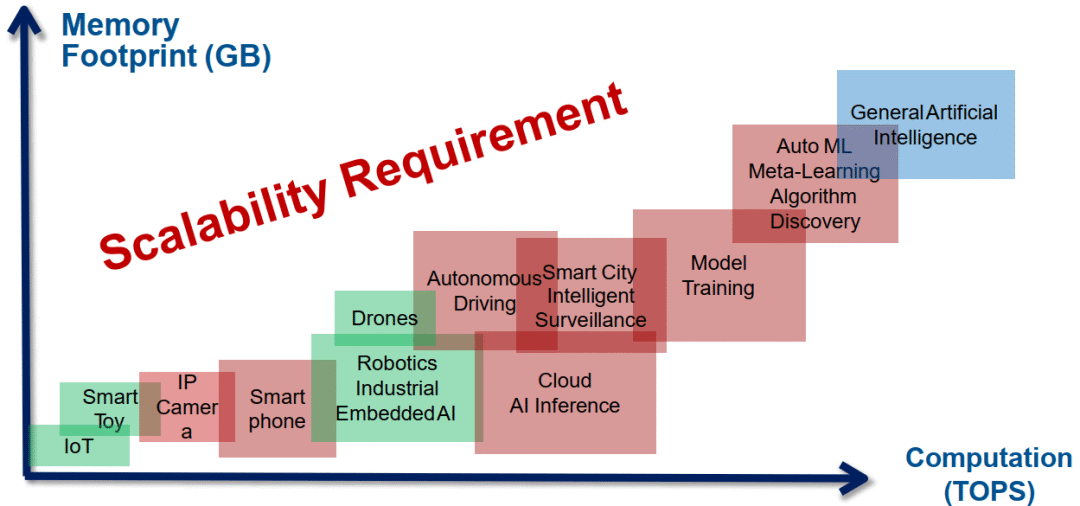
不同算力场景下,算力需求(TFLOPS)和内存大小(GB)的对应关系 [1]
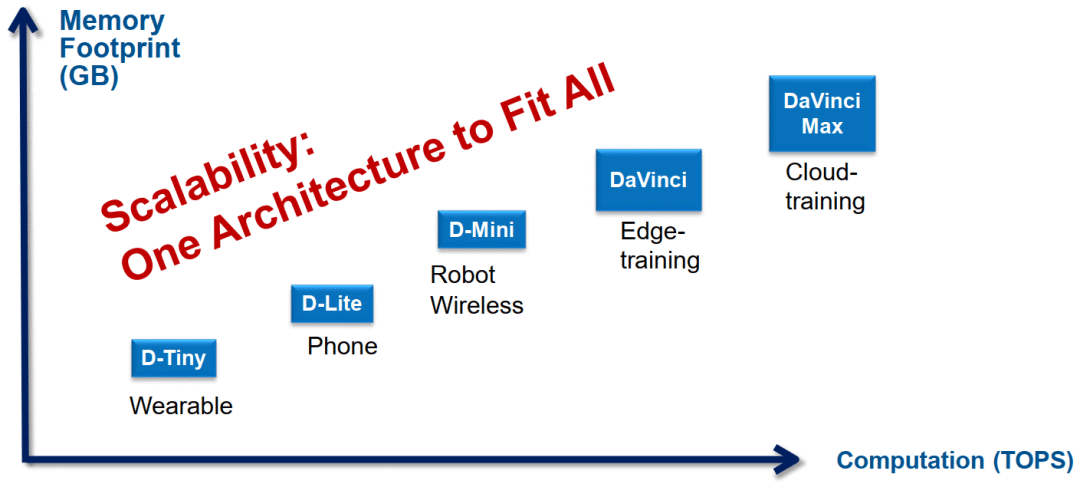
华为的解决方案:一种架构(DaVinci),覆盖所有场景 [1] 用在几个不同产品方向上,手机处理器,自动驾驶芯片等等,专门的 AI 处理器,使用场景类似于 GPU。
Ascend NPU 设计
2017 年发布了自己的 NPU 架构,[2] 详细介绍了 DaVinci 架构的设计。除了支持传统标量运算、矢量运行,还引入了 3D Cube 来加速矩阵运算。
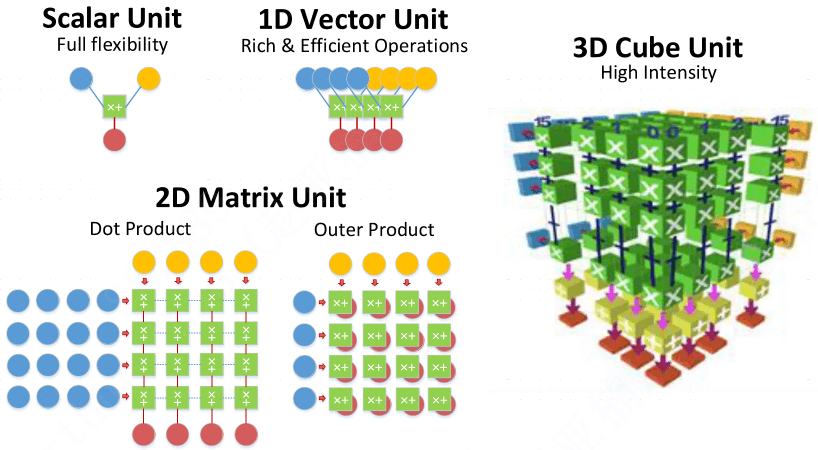
Image Source [2] 单位芯片面积或者单位功耗下,性能比 CPU/GPU 大幅提升:
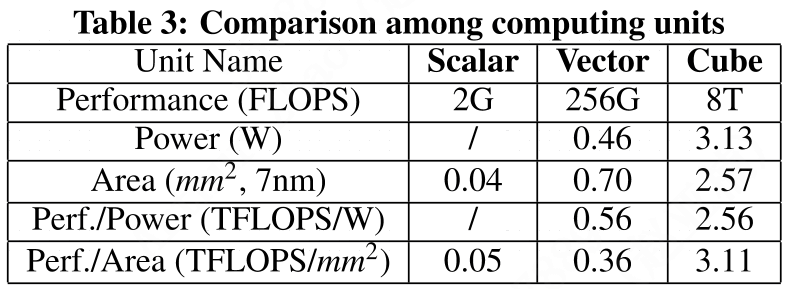
Image Source [2] 下面看看实际使用场景和产品系列。 03 路线一:NPU 用在手机芯片(Mobile AP SoC) 现代手机芯片不再是单功能处理器,而是集成了多种芯片的一个 片上系统(SoC), 华为 NPU 芯片就集成到麒麟手机芯片内部,随着华为 Mate 系列高端手机迭代。
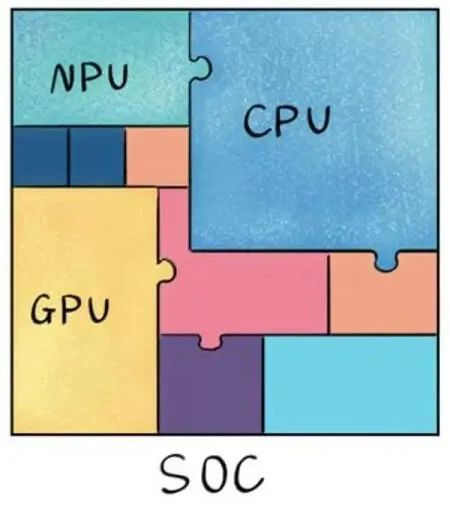
Image Source [7] 比如,一些典型的功能划分 [7]:
CPU 主处理器,运行 app;
GPU 渲染、游戏等;
NPU 图像识别、AI 应用加速。
Mate 系列手机基本上是跟 Kirin 系列芯片一起成长的,早期的手机不是叫 “Mate XX”, 而是 “Ascend Mate XX”,从中也可以看出跟昇腾(Ascend)的渊源。
Kirin 970,2017, Mate 10 系列手机
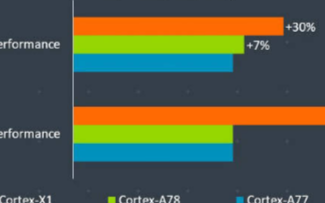
据称是第一个手机内置的 AI 处理器(NPU)[3]。在 AI 任务上(比如手机上输入文字搜图片,涉及大批量图片识别)比 CPU 快 25~50 倍。
10nm,台积电代工
CPU 8-core with a clockspeed of uP to 2.4GHz i.e. 4 x Cortex A73 at 2.4GHz + 4 x Cortex 53 at 1.8GHz
GPU 12-core Mali G72MP12 ARM GPU
NPU 1.92 TFLOPs FP16
Kirin 990 5G,2019, Mate 30 系列手机
Kirin 990 包含了 D-lite 版本的 NPU [1]:
World’s st 5G SoC Poweed by 7nm+ EUV
World’s 1st 5G NSA & SA Flagship SoC
Wolrd’s 1st 16-Core Mali-G76 GPU
World’s 1st Big-Tiny Core Architechture NPU
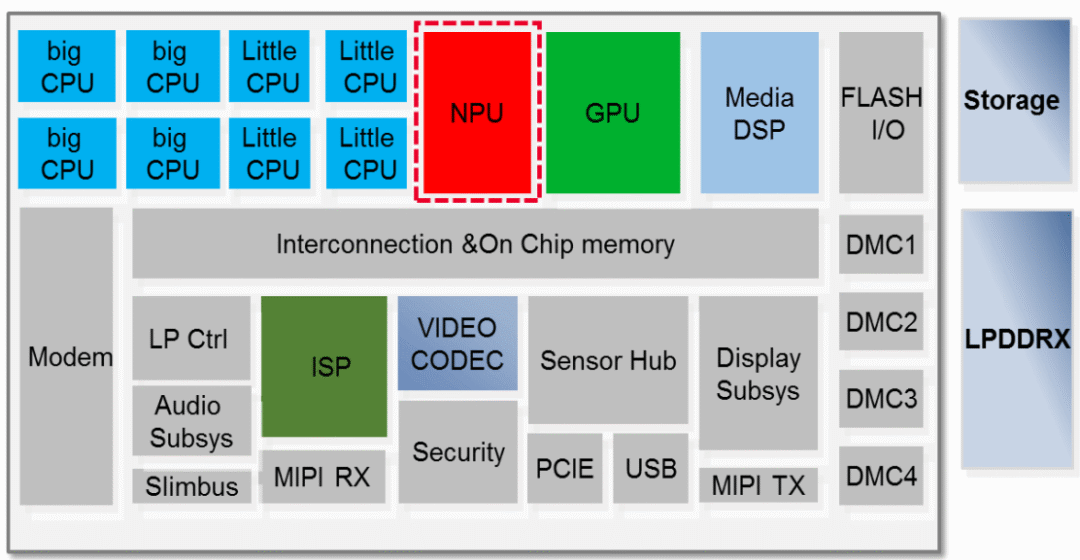
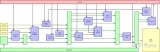
麒麟 990 5G 芯片逻辑拓扑 [1] 一些硬件参数 [1,4]:
台积电 7nm+ 工艺
CPU 8-Core
NPU 2+1 Core
GPU 16-core Mali-G76(ARM GPU)
GPU 16-core Mali-G76 (ARM GPU)
NPU
——HUAWEI Da Vinci Architecture, ——2x Ascend Lite + 1x Ascend Tiny
2G/3G/4G/5G Modem
LPDDR 4X
4K HDR Video
Kirin 9000 5G,2020,Mate 40 系列手机

Image Source
台积电 5nm 工艺
GPU 24-core Mali-G78, Kirin Gaming+ 3.0
NPU
——HUAWEI Da Vinci Architecture 2.0 第二代架构 ——2x Ascend Lite + 1x Ascend Tiny 这个是台积电 5nm 工艺 [5],然后就被***了。所以 Mate 50 系列用的高通处理器,Mate 60 系列重新回归麒麟处理器。
Kirin 9000s,2023,Mate 60 系列手机
王者低调回归,官网没有资料。 据各路媒体分析,是中芯国际 7+nm 工艺,比上一代 9000 落后一些, 毕竟制程有差距,看看国外媒体的副标题 [6]: It's tough to beat a 5nm processor with a 7nm chip. Wikipedia 提供的参数 [10]:
SMIC 7nm FinFET
CPU HiSilicon Taishan microarchitecture Cortex-A510
GPU Maleoon 910 MP4
NPU 有,但是没提
小 结
手机芯片系列先到这里,接下来看看作为独立卡使用的 NPU 系列。 04 路线二:NPU 用作推理/训练芯片(Ascend AI Processor)

两个产品:301 低功耗;910 高算力。 设计见 paper [2]。
产品:加速卡 Atlas 系列
型号 Atlas 200/300/500/…,包括了 NPU 在内的 SoC,用于 AI 推理和训练。
Ascend 310,2019,推理
>Spec 用的是 D-mini version:
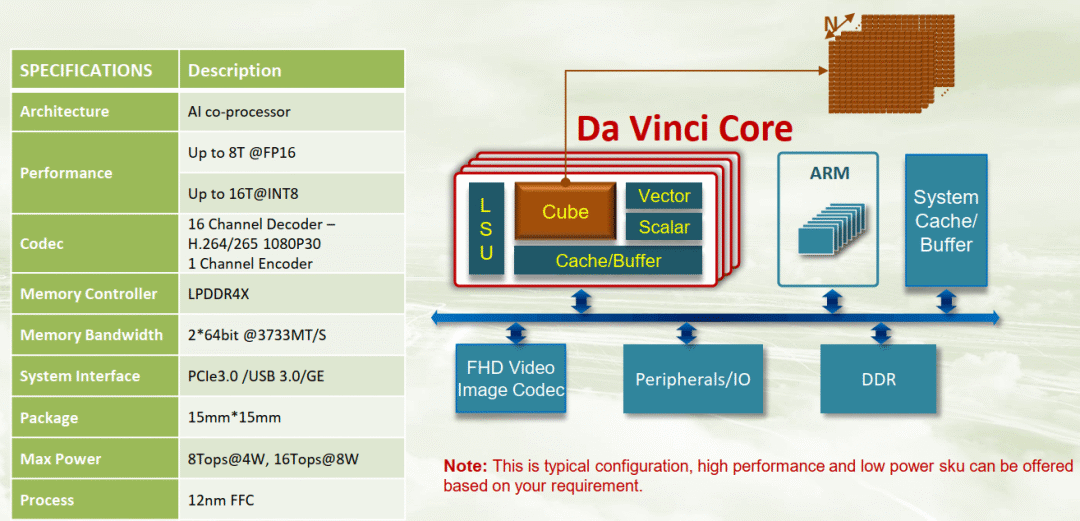
纸面算力基本对标 NVIDIA T4 [9]。
Ascend 910, 2019,训练
>Spec & Performance, vs. Google TPU
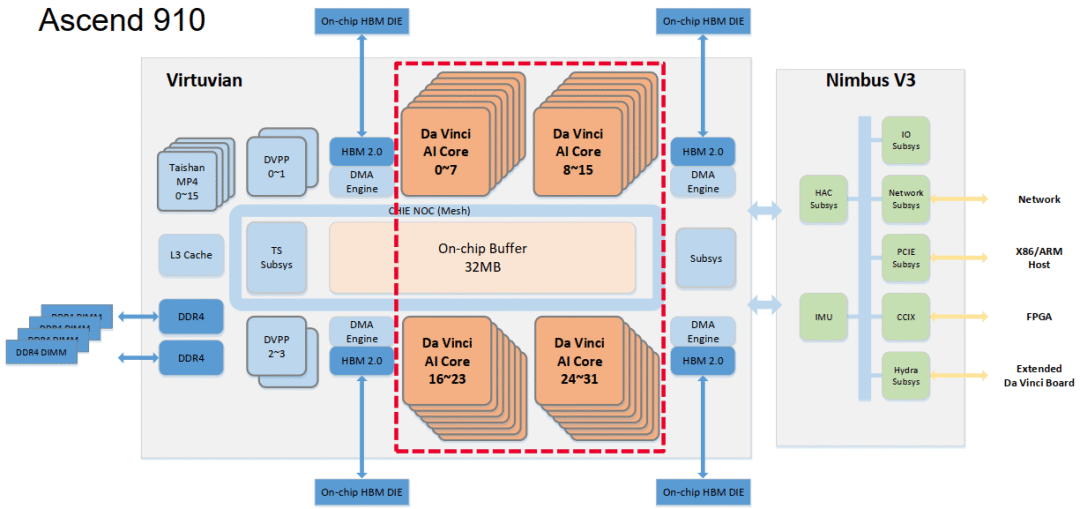
Image Source [1]

Image Source [1] >计算集群
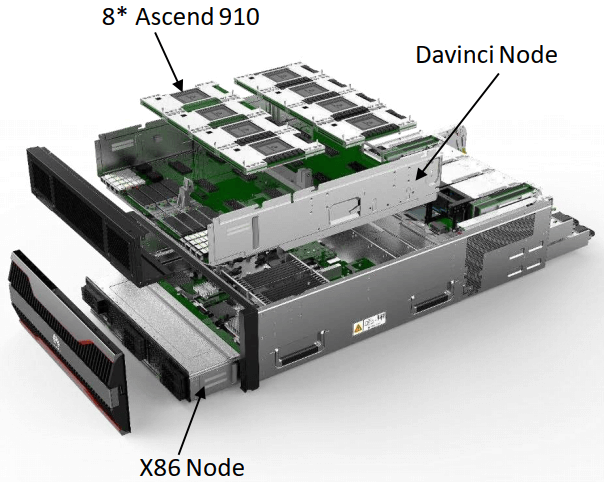
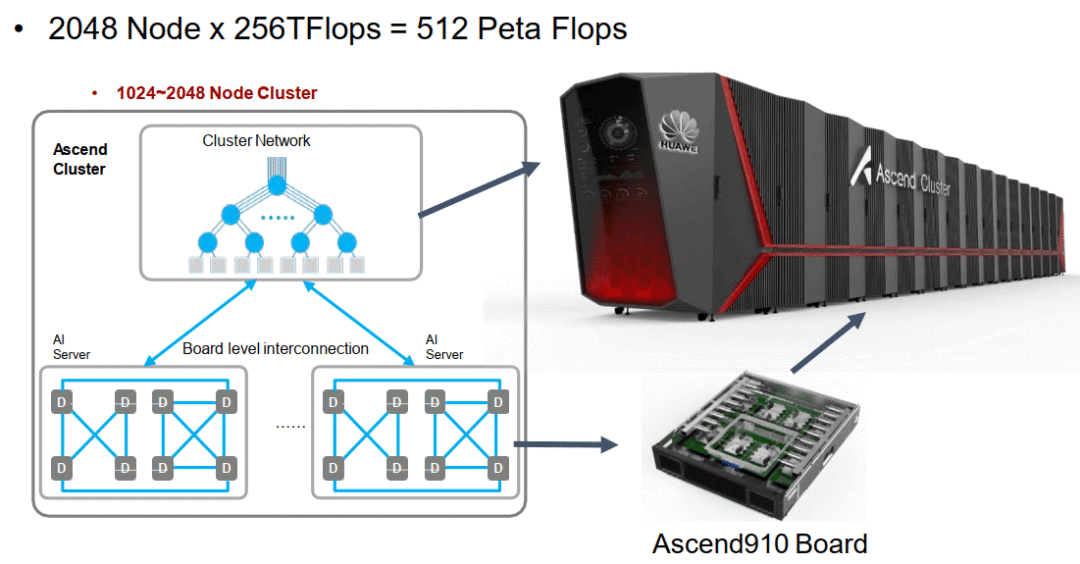
Image Source [1]
审核编辑:黄飞















 工商网监
工商网监
评论