 电子发烧友App
电子发烧友App


现在,人们需要采用一种创新型架构来管理数百Gbps的系统性能,以实现全线速下的智能处理能力,并扩展至Tb级性能和每秒10亿次浮点运算水平。实现上述要求的必要条件并非仅仅是改善每个晶体管或系统模块的性能,或者增加系统模块数量这么简单,而是要从根本上提高通信、时钟、关键路径以及互连性能,以满足行业新一代高性能应用(如下图所示)对海量数据流和智能数据包、DSP或图像处理等的要求。

UltraScale™ 架构通过在完全可编程的架构中应用最先进的ASIC 技术,可应对上述这些挑战。该架构能从20nm平面FET结构扩展至16nm鳍式FET晶体管技术甚至更高的技术,同时还能从单芯片扩展到3D IC。UltraScale架构不仅能解决系统总吞吐量扩展和时延方面的局限性,而且还能直接应对先进工艺节点上的头号系统性能瓶颈,即互连问题。

图2:ASIC级可编程架构的必备条件
UltraScale™架构具有无与伦比的高集成度、高容量和ASIC级系统性能,可满足最严苛应用的要求。UltraScale架构经过精调可提供大规模布线能力并且与Vivado®设计工具进行了协同优化,因此该架构的利用率达到了空前的高水平(超过90%),而且不会降低性能。
为您量身定做的新一代架构
赛灵思对UltraScale架构进行了数百项设计提升,并将这些改进实现有机结合,让设计团队能够打造出比以往功能更强、运行速度更快、单位功耗性能更高的系统。
UltraScale架构与Vivado™设计套件结合使用可提供如下这些新一代系统级功能:
· 针对宽总线进行优化的海量数据流,可支持数Tb级吞吐量和最低时延
· 高度优化的关键路径和内置高速存储器,级联后可消除DSP和包处理中的瓶颈
· 增强型DSP slice包含27x18位乘法器和双加法器,可以显著提高定点和IEEE 754标准浮点算法的性能与效率
· 第二代3D IC系统集成的晶片间带宽以及最新3D IC宽存储器优化接口均实现阶梯式增长
· 类似于ASIC的多区域时钟,提供具备超低时钟歪斜和高性能扩展能力的低功耗时钟网络
· 海量I/O和存储器带宽,用多个硬化的ASIC级100G以太网、Interlaken和PCIe® IP核优化,可支持新一代存储器接口功能并显著降低时延
· 电源管理可对各种功能元件进行宽范围的静态与动态电源门控,实现显著节能降耗
· 新一代安全策略,提供先进的AES比特流解密与认证方法、更多密钥模糊处理功能以及安全器件编程
· 通过与Vivado工具协同优化消除布线拥塞问题,实现了90%以上的器件利用率,同时不降低性能或增大时延
系统设计人员将这些系统级功能进行多种组合,以解决各种问题。下面的宽数据路径方框图可以很好地说明这一问题。
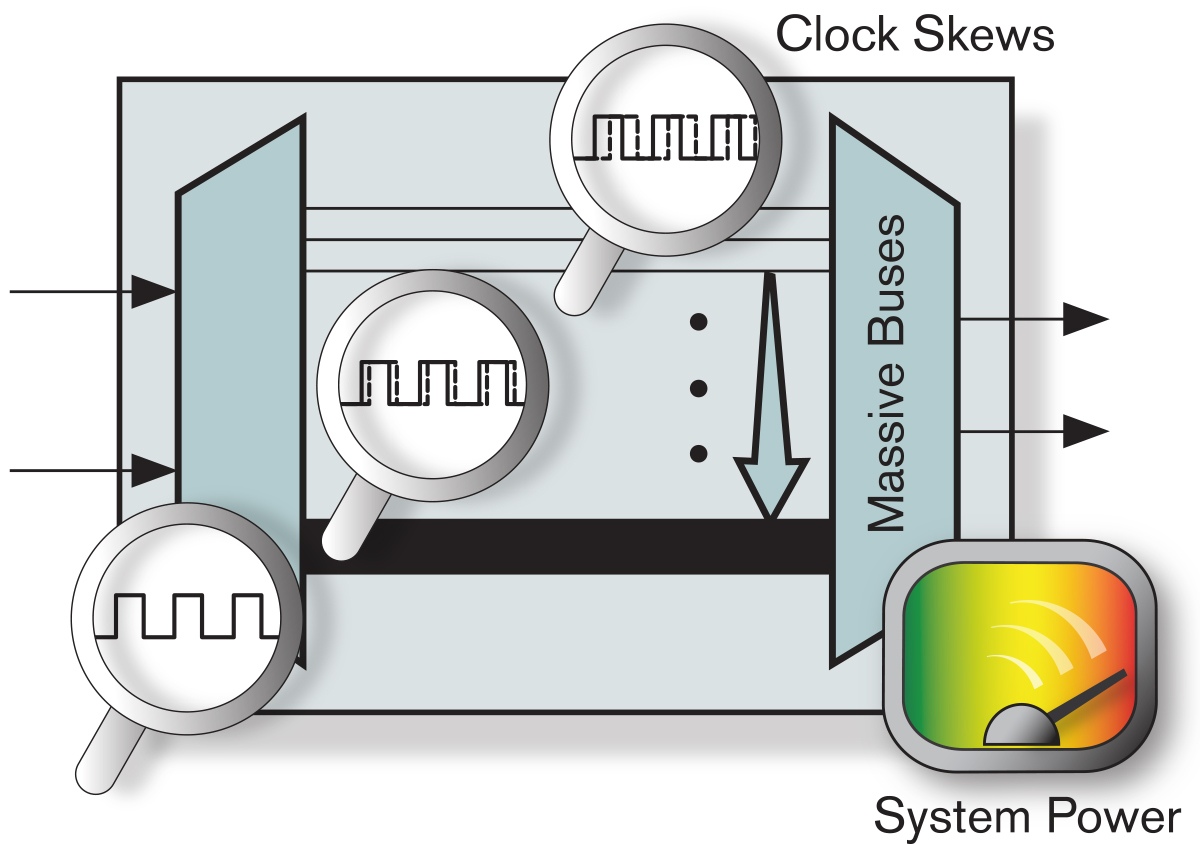
图3:海量数据流挑战
图中,高速数据流(Tbps级的汇聚速率)从左侧进入再从右侧流出。可通过运行速度为数Gbps的高速SerDes收发器进行I/O传输。一旦以数Gbps速度传输的串行数据流进入芯片,就必须扇出,以便与片上资源的数据流、路由和处理能力相匹配。新一代系统要求使用极高的数据速率,因此时钟歪斜、大量总线布置以及系统功耗管理方面的挑战会达到令人生畏的程度。
UltraScale架构提供类似ASIC时钟功能
多亏UltraScale 架构提供类似ASIC的多区域时钟功能,使得设计人员现在可以将系统级时钟放在整个晶片的任何最佳位置上,从而使系统级时钟歪斜降低多达50%。将时钟驱动的节点放在功能模块的几何中心并且平衡不同叶节点时钟单元(leaf clock cell)的时钟歪斜,这样可以打破阻碍实现多Gb系统级性能的一个最大瓶颈。UltraScale架构的类似ASIC时钟功能消除了时钟放置方面的一切限制并且能够在系统设计中实现大量独立的高性能低歪斜时钟资源,而这正是新一代设计的关键要求之一。这是与前几代可编程逻辑器件所采用的时钟方案的最大不同之处,而且实现了重大改进。
新一代路由:从容应对海量数据流挑战
UltraScale架构的新一代互连功能与Vivado软件工具进行了协同优化,在可编程逻辑布线方面取得了真正的突破。赛灵思将精力重点放在了解和满足新一代应用对于海量数据流、多Gb智能包处理、多Tb吞吐量以及低时延方面的要求。通过分析我们得出一个结论,那就是在这些数据速率下,互连问题已成为影响系统性能的头号瓶颈。
我们来做个类比。位于市中心的一个繁忙十字路口,交通流量的方向是从北到南,从南到北,从东到西,从西到东,有些车辆正试图掉头,所有交通车辆试图同时移动。这样通常就会造成大堵车。现在考虑一下将这一十字路口精心设计为现代化高速公路或主干道,情况又会如何。道路设计人员设计出了专用坡道(快行道),用以将交通流量从主要高速路口的一端顺畅地疏导至另一端。交通流量可以从高速路的一端全速移动到另一端,不存在堵车现象。下面的两幅图说明了这一观点:

赛灵思为UltraScale架构加入了类似的快速通道。这些新增的快速通道可供附近的逻辑单元之间传输数据,尽管这些单元并不一定相邻,但它们仍通过特定的设计实现了逻辑上的连接。这样,UltraScale架构所能管理的数据量就会呈指数级上升,如下图所示。
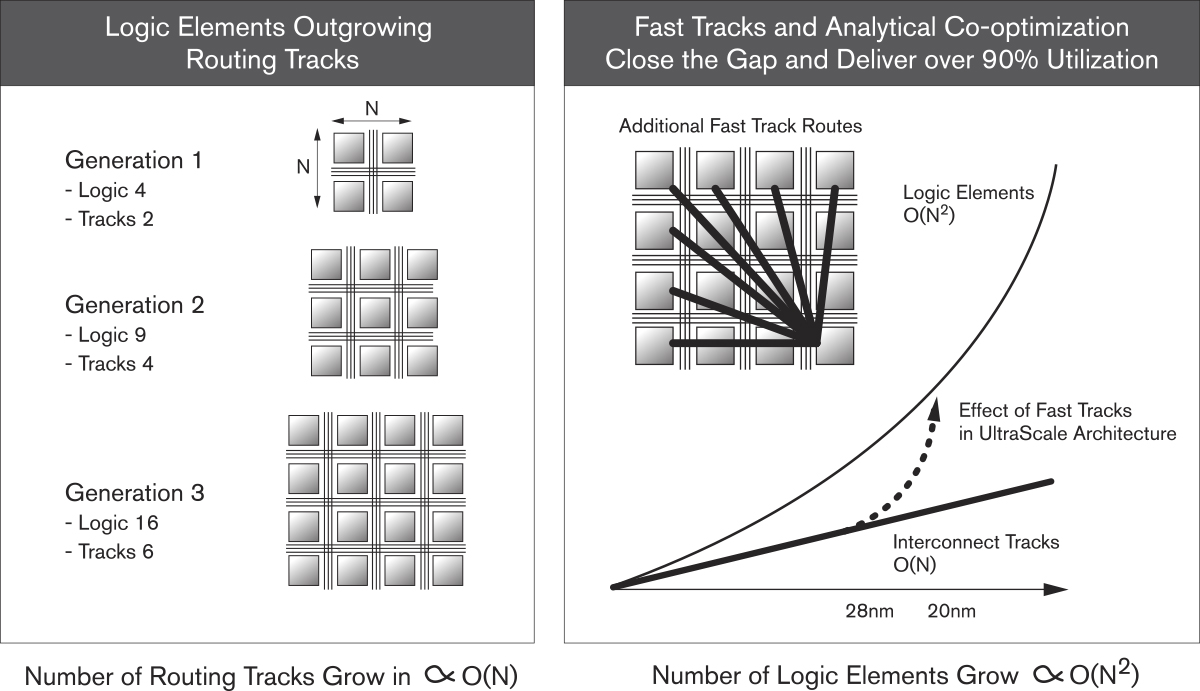
通过UltraScale架构提供的高布线效率从根本上完全消除了布线拥塞问题。结果很简单:只要设计合适,布局布线就没有问题。这样也使器件利用率达到90%以上,且不降低性能或增加系统时延。
下面的这两幅图显示出UltraScale架构以及Vivado设计套件的相应改进对于系统性能和器件利用率的改善效果。与竞争产品PLD 架构相比,UltraScale架构将利用率和性能提升到了全新的高度,无需像PLD架构那样为了实现设计目标,不得不在利用率、性能、时延和延长布局布线时间等方面进行权衡取舍。
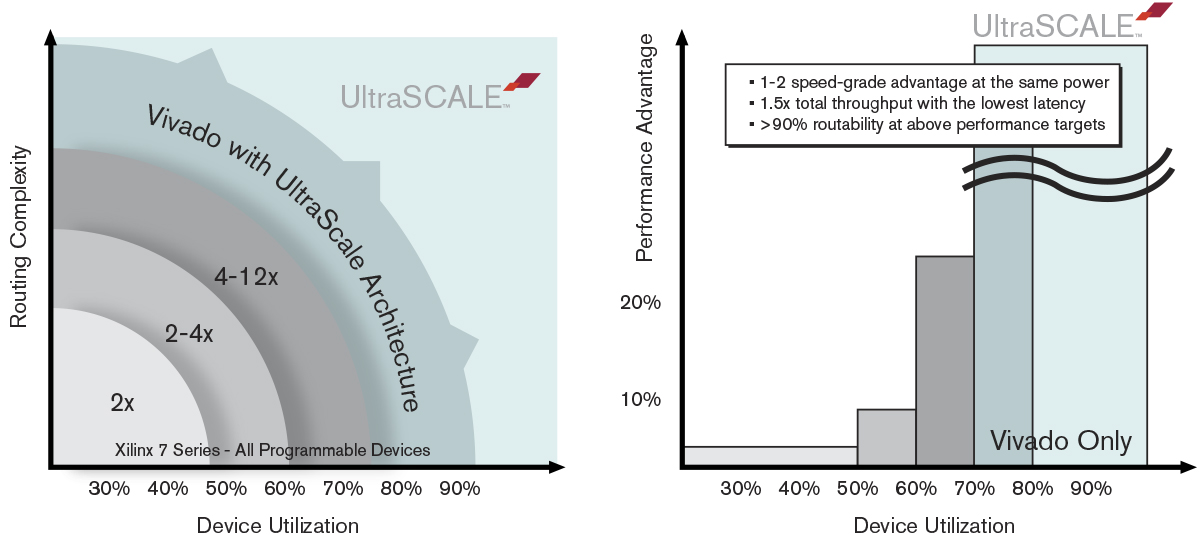
图4 :UltraScale架构在不降低性能的前提下提供高利用率
图4中左图的蓝绿色区域表示:如果系统设计适合使用UltraScale器件,那么就可以布线,而且不受设计复杂性和器件利用率方面的制约。左图中的灰色区域表明Vivado设计套件在任何利用率水平下的运行速度都比竞争设计工具快2至12倍。两幅图的蓝绿色区域都表明Vivado 设计套件是唯一可以在高器件利用率条件下对大型复杂系统设计进行布局布线的工具。同时,右图的灰色区域显示采用Vivado设计套件创建出设计的速度在任何利用率等级下都比竞争产品快25%。UltraScale架构可支持海量数据流与布线,Vivado设计套件与之结合使用,能够在竞争产品无法企及的设计空间内提供更高的系统性能。
UltraScale架构3D集成可增强所有功能
最新Virtex® UltraScale和Kintex® UltraScale系列成员产品能使赛灵思第二代3D IC架构中的连接功能资源数量及相关晶片间带宽实现阶梯式增长。布线、带宽和最新3D IC大容量存储器优化接口容量的显著增加能确保新一代应用在极高的利用率水平下实现目标性能。
实现快速、智能处理
从噪声中提取更多信号,创建更加逼真的画面,以及应对无止境的数据包流量增长,所有这些都在对智能处理性能提出更高要求。与此同时,还要将成本控制在规定的预算范围内,这样就给设计带来了诸多实际限制。简言之,市场需要以更少的成本实现更高的系统性能,这是大多数电子产业永恒不变的趋势。而赛灵思的UltraScale器件非常适合满足这些多元化的设计要求。
最新的27x18位乘法器和双加法器以及关键路径优化功能显著提升了定点和IEEE 754标准浮点算法的性能与效率。UltraScale架构能够让双精度浮点运算的资源利用率实现1.5倍的效率提升,并具有更多的DSP资源数量,因此可以满足新一代应用在TMAC处理性能和集成方面的要求,并实现最优价格点。
UltraScale架构经过专门优化,可解决以数百Gbps速率运行的包处理功能有关的关键路径瓶颈问题,这些功能包括:误差校正与控制(ECC)、循环冗余校验(CRC)以及前向纠错(FEC)。增强型DSP子系统,与硬化的100 GbE MAC和Interlaken接口以及赛灵思SmartCore 包处理与流量管理IP完美结合在一起,采用最佳封装,能够实现线速高达数百Gbps的包处理功能。
提供海量I/O和存储器带宽
UltraScale架构能在显著增强高速SerDes收发器性能的同时大幅降低其功耗。Virtex UltraScale器件采用可支持5 Tbps以上串行系统带宽的新一代SerDes(收发器)。ASIC级SerDes的灵活性要高于早期器件中的SerDes,同时保留了前代产品可靠的自适应均衡功能(自动增益控制、连续时间线性均衡、判定反馈均衡以及sliding 滑动DFE)。赛灵思的自适应均衡功能可将误码率维持在无法察觉的水平(<1017)并允许UltraScale SerDes直接驱动每秒高达数GHz的高速背板。
赛灵思UltraScale架构集成了多个DDR3/4-SDRAM存储控制器以及硬化的DDR物理层(PHY)片上模块,从而将存储器接口功能推向一个全新高度。UltraScale器件包含:
· 更多SDRAM控制器
· 更广泛的SDRAM端口
· 更快的存储器端口
硬化的SDRAM PHY模块与软核PHY相比能够将读取时延降低30%,同时它具有控制DDR4 SDRAM的能力,可将外部存储器功耗降低20%以上。
片上模块RAM(BRAM)经重新构建后可与系统中其它可编程模块性能相匹配并降低功耗。利用新的架构特性,设计人员无需使用其它片上布线或逻辑资源就能高效创建出大规模快速RAM阵列和FIFO。
UltraScale架构满足新一代系统的系统级功耗要求
每一代All Programmable逻辑器件系列都能显著降低系统级功耗,UltraScale架构正是建立在这一传统优势之上。低功耗半导体工艺以及通过芯片与软件技术实现的宽范围静态与动态电源门控可将系统总功耗降低至赛灵思7系列FPGA(业界最低功耗的All Programmable器件)的一半。

图5:采用UltraScale架构实现最低总功耗
降低功耗对设计人员来说意味着两件事:(1)更低的功耗预算和散热管理要求;(2)更高的速度。这两点对满足新一代应用不断提高的要求极为重要。
UltraScale的IP保护与防篡改安全功能
赛灵思的安全解决方案与创新产品已经历了五代以上的发展,UltraScale All Programmable架构在这一基础上引入了多种增强型安全特性,可对载入器件内的IP提供更强的保护并实现防篡改功能,继续保持着延续赛灵思在安全解决方案领域的领先地位。UltraScale 架构在安全性方面的改进包括:更强大更先进的AES比特流解密与认证方案;更多密钥模糊处理功能;确保在编程过程中无法对加密密钥进行外部访问。这样就能得到稳定可靠的业界领先解决方案,满足不断变化的新一代安全要求。
UltraScale与Vivado协同优化 = 成功保障
要为最严苛的应用提供前所未有的集成度、容量和ASIC级系统性能,并实现90%以上的空前器件利用率且不降低性能,这就需要采用业界独有的SoC增强型设计环境。
Vivado设计套件是一款全新的SoC增强型设计环境,最初针对赛灵思7系列器件推出,主要用于未来十年的All Programmable器件(例如UltraScale架构)。Vivado能解决可编程系统集成与实现方面的关键设计瓶颈,其生产力相对同类竞争开发环境提高了四倍。
要实现新一代设计提出的超高性能、集成度以及结果质量目标,就需要采用全新的器件布局布线方案。传统FPGA布局布线工具依靠模拟退火作为主要的布局优化算法,无法顾及拥塞程度或总导线长度等全局设计指标。要实现具备多Tb性能的设计,需要采用宽总线而且要求时钟歪斜几乎为零。因此,采用模拟退火这种不考虑总体导线长度和拥塞情况的布局布线算法是绝对不可行的。
Vivado设计套件利用多变量成本函数找出最优布局方案,这样,设计人员就可以快速确定布线方案,并使器件利用率达到90%以上且不降低性能。与采用其他解决方案相比,这种方式的运行时间更短而且结果的变化程度也更小,这样实现设计收敛所需的迭代次数就更少,并且性能和器件利用率都达到了业界前所未有的高水平。
UltraScale架构与工艺技术
工艺技术在任何芯片架构中都是一个重要的考虑因素,赛灵思UltraScale架构可以支持多种工艺技术。赛灵思与台积(TSMC)合作推出的28nm HPL(低功耗高性能)工艺技术是赛灵思7系列All Programmable器件能够取得巨大成功的主要因素。凭借之前合作所取得的经验,赛灵思与台积又开发出了20nm 20SoC平面工艺技术,用以支持预计将于2013年推出的第一代赛灵思UltraScale All Programmable器件。
然而,赛灵思设计UltraScale架构还有另一个目的,那就是充分利用继20SoC之后的工艺节点16FinFET所提供的更高的性能、容量和节电性能。 另外,在赛灵思“FinFast”开发计划(该计划汇集了赛灵思和台积的优秀工程设计人才)的支持下,赛灵思UltraScale架构和Vivado 设计套件针对台积 16FinFET工艺技术进行了协同优化。这样,赛灵思与台积将于2014年推出第二代UltraScale All Programmable器件芯片。
结论
为了实现数百Gbps的系统级性能,实现全线速智能处理,并扩展至Tbps和每秒10亿次的浮点运算水平,我们需要采用一种全新的架构方案。赛灵思根据新一代高性能系统需求已经开发出了新一代UltraScale 架构和Vivado设计套件。UltraScale架构能提供ASIC级的系统性能,满足最严苛的新一代应用要求:即实现海量I/O和存储器带宽、海量数据流、极高的DSP与包处理性能,并在不影响性能的前提下实现超过90%的前所未有的器件利用率。
UltraScale是业内首款在All Programmable架构中应用最前沿ASIC架构增强功能的产品,能够从20nm平面FET扩展到16nm 鳍式FET,甚至更先进的技术,此外还能从单芯片电路扩展至3D IC。 通过整合台积的先进技术并与Vivado新一代设计套件实现协同优化,赛灵思提前一年实现同类竞争产品1.5倍至2倍的系统级性能与集成度。这相当于我们比竞争对手领先整整一代。












 工商网监
工商网监
评论