 电子发烧友App
电子发烧友App


要做一些计算加速的工作,入手先要想好几个问题: 要加速的是什么应用,应用的瓶颈是什么,再针对这个瓶颈,参考前人工作选择合适的方案。过早地执着于fpga的技术细节容易护士许多的细节。现在software define network/flash/xxx,已然大势所趋。
WHEN?深度学习异构计算现状
随着互联网用户的快速增长,数据体量的急剧膨胀,数据中心对计算的需求也在迅猛上涨。同时,人工智能、高性能数据分析和金融分析等计算密集型领域的兴起,对计算能力的需求已远远超出了传统CPU处理器的能力所及。

异构计算被认为是现阶段解决此计算沟壑的关键技术,目前 “CPU+GPU”以及“CPU+FPGA” 是最受业界关注的异构计算平台。它们具有比传统CPU并行计算更高效率和更低延迟的计算性能优势。面对如此巨大的市场,科技行业大量企业投入了大量的资金和人力,异构编程的开发标准也在逐渐成熟,而主流的云服务商更是在积极布局。

WHY?通用CNN FPGA加速
业界可以看到诸如微软等巨头公司已经部署大批量的FPGA来做AI inference加速,FPGA相较于其他器件的优势是什么呢?
Flexibility:可编程性天然适配正在快速演进的ML算法
DNN、CNN、LSTM、MLP、reinforcement learning以及决策树等等
任意精度动态支持
模型压缩、稀疏网络、更快更好的网络
Performance:构建实时性AI服务能力
相较于GPU/CPU数量级提升的低延时预测能力
相较于GPU/CPU数量级提升的单瓦特性能能力
Scale
板卡间高速互联IO
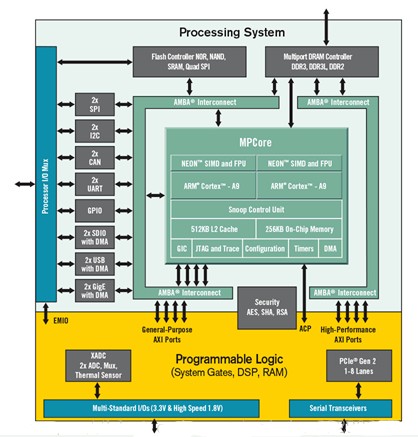
Intel CPU-FPGA构架
与此同时,FPGA的短板也非常的明显,FPGA使用HDL硬件描述语言来进行开发,开发周期长,入门门槛高。以单独的经典模型如Alexnet以及Googlenet为例,针对一个模型进行定制的加速开发,往往需要数月的时间。业务方以及FPGA加速团队需要兼顾算法迭代以及适配FPGA硬件加速,十分痛苦。
一方面需要FPGA提供相较于CPU/GPU有足够竞争力的低延时高性能服务,一方面需要FPGA的开发周期跟上深度学习算法的迭代周期,基于这两点我们设计开发了一款通用的CNN加速器。兼顾主流模型算子的通用设计,以编译器产生指令的方式来驱动模型加速,可以短时间内支持模型切换;同时,对于新兴的深度学习算法,在此通用基础版本上进行相关算子的快速开发迭代,模型加速开发时间从之前的数月降低到现在的一到两周之内。
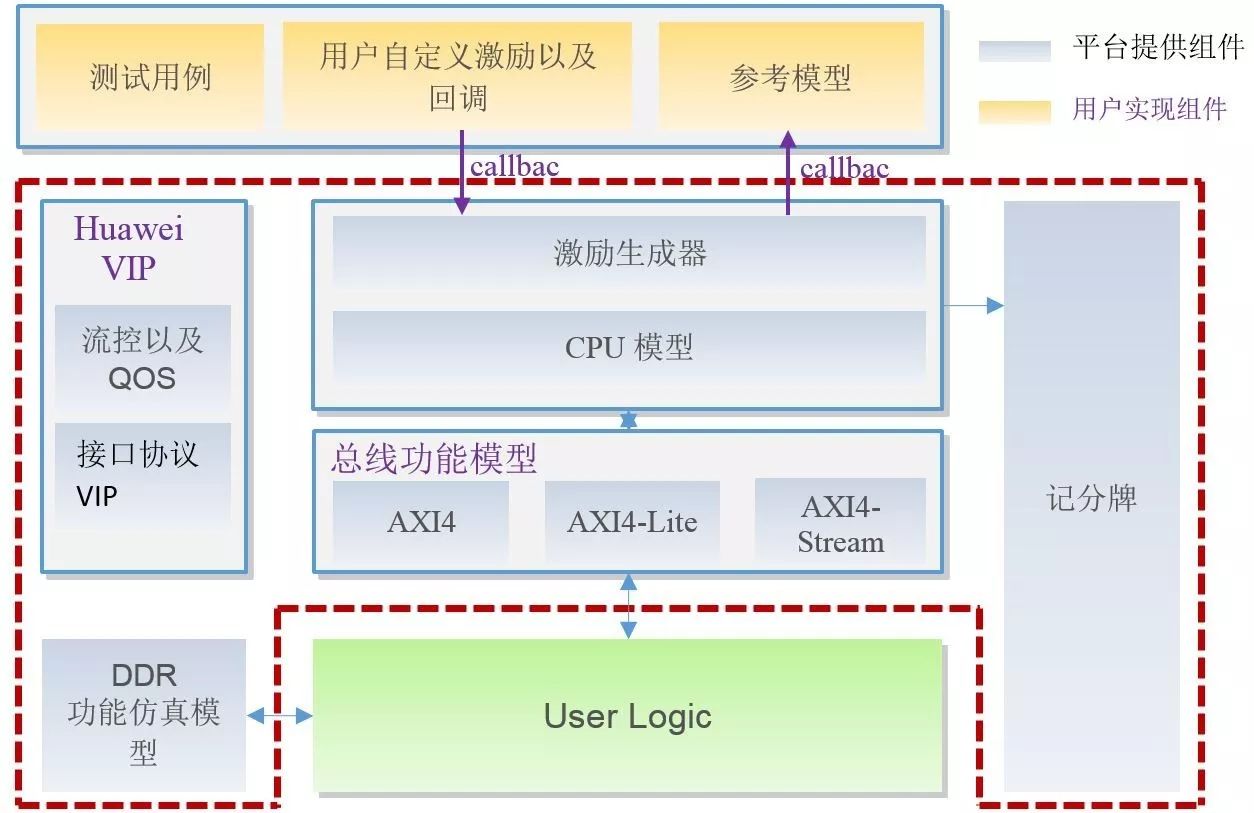
HOW?通用CNN FPGA架构
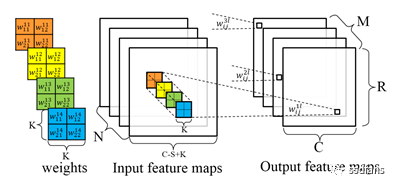
基于FPGA的通用CNN加速器整体框架如下,通过Caffe/Tensorflow/Mxnet等框架训练出来的CNN模型,通过编译器的一系列优化生成模型对应的指令;同时,图片数据和模型权重数据按照优化规则进行预处理以及压缩后通过PCIe下发到FPGA加速器中。FPGA加速器完全按照指令缓冲区中的指令集驱动工作,加速器执行一遍完整指令缓冲区中的指令则完成一张图片深度模型的计算加速工作。每个功能模块各自相对独立,只对每一次单独的模块计算请求负责。加速器与深度学习模型相抽离,各个layer的数据依赖以及前后执行关系均在指令集中进行控制。

简单而言,编译器的主要工作就是对模型结构进行分析优化,然后生成FPGA高效执行的指令集。编译器优化的指导思想是:更高的MAC dsp计算效率以及更少的内存访问需求。
接下来我们以Googlenet V1模型为例,对加速器的设计优化思路做简单的分析。Inception v1的网络,将1x1、3x3、5x5的conv和3x3的pooling stack在一起,一方面增加了网络的width,另一方面增加了网络对尺度的适应性。下图为模型中Inception的基本结构。

数据依赖关系分析
此部分主要分析挖掘模型中可流水化以及可并行化的计算。流水化的设计可以提高加速器中的计算单元利用率,并行化的计算可以在同一时刻利用尽量多的计算单元。
关于流水,分析部分包括数据从DDR加载到FPGA片上SRAM的操作与PE进行计算的流水,通过此项优化将内存访问的时间overlap;DSP计算整列的计算控制过程,保证DSP利用率的提升。
关于并行,需要重点分析PE计算阵列与激活、pooling以及归一化等“后处理”模块之间的并行关系,如何确定好数据依赖关系以及防止冲突是此处设计关键。在Inception中,可以从其网络结构中看到,branch a/b/c的1x1的卷积计算与branch d中的pooling是可以并行计算的,两者之间并不存在数据依赖关系。通过此处优化,3x3 max pooling layer的计算就可以被完全overlap。
模型优化
在设计中主要考虑两个方面:寻找模型结构优化以及支持动态精度调整的定点化。
FPGA是支持大量计算并行的器件,从模型结构上寻找更高维度的并行性,对于计算效率以及减少内存访问都十分有意义。在Inception V1中,我们可以看到branch a\ branch b\ branch c的第一层1x1卷积层,其输入数据完全一致,且卷积layer的stride以及pad均一致。那我们是否可以在output feature map维度上对齐进行叠加?叠加后对input data的访存需求就降低到了原来的1/3。
另一方面,为了充分发挥FPGA硬件加速的特性,模型的Inference过程需要对模型进行定点化操作。在fpga中,int8的性能可以做到int16的2倍,但是为了使公司内以及腾讯云上的客户可以无感知的部署其训练的浮点模型,而不需要retrain int8模型来控制精度损失,我们采用了支持动态精度调整的定点化int16方案。通过此种方法,用户训练好的模型可以直接通过编译器进行部署,而几乎无任何精度损失。
内存架构设计
带宽问题始终是计算机体系结构中制约性能的瓶颈之一,同时内存访问直接影响加速器件功耗效率。
为了最大化的减少模型计算过程中的DDR访存,我们设计了如下的内存架构:
Input buff以及output buffer ping-pong设计,最大化流水以及并行能力
支持Input buff和output buffer自身之间的inner-copy操作
Input buff和output buffer之间的cross-copy操作
通过这种架构,对于大多数目前主流模型,加速器可以做到将中间数据全部hold在FPGA片上,除了模型权重的加载外,中间无需消耗任何额外的内存操作。对于无法将中间层feature map完全存储在片上的模型,我们在设计上,在Channel维度上引入了slice分片的概念,在feature map维度上引入了part分片的概念。通过编译器将一次卷积或是pooling\Norm操作进行合理的拆分,将DDR访存操作与FPGA加速计算进行流水化操作,在优先保证DSP计算效率的前提下尽量减少了DDR的访存需求。

计算单元设计
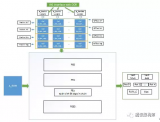
基于FPGA的通用CNN加速器的核心是其计算单元,本加速器当前版本基于Xilinx Ku115芯片设计,PE计算单元由4096个工作在500MHz的MAC dsp核心构成,理论峰值计算能力4Tflops。其基本组织框架如下图所示。

KU115芯片由两个DIE对堆叠而成,加速器平行放置了两组处理单元PE。每个PE由4组32x16=512的MAC计算DSP核心组成的XBAR构成,设计的关键在于提升设计中的数据复用降低带宽,实现模型权重复用和各layer feature map的复用,提升计算效率。
应用场景及性能对比
当前深度学习主流使用GPU做深度学习中的Training过程,而线上Inference部署时需综合考虑实时性、低成本以及低功耗特性选择加速平台。按深度学习落地场景分类,广告推荐、语音识别、图片/视频内容实时监测等属于实时性AI服务以及智慧交通、智能音箱以及无人驾驶等终端实时低功耗的场景,FPGA相较于GPU能够为业务提供强有力的实时高性能的支撑。
对于使用者而言,平台性能、开发周期以及易用性究竟如何呢?
加速性能
以实际googlenet v1模型为例,CPU测试环境:2个6核CPU(E5-2620v3),64G内存。
将整机CPU打满,单张基于KU115的加速器相较于CPU性能提升16倍,单张图片检测延时从250ms降低到4ms,TCO成本降低90%。
同时,FPGA预测性能略强于Nvidia的GPU P4,但延时上有一个数量级的优化。

开发周期
通用的CNN FPGA加速架构,能够支持业务快速迭代持续演进中的深度学习模型,包括Googlenet/VGG/Resnet/ShuffleNet/MobileNet等经典模型以及新的模型变种。
对于经典模型以及基于标准layer自研的算法变种,现有加速架构已经可以支持,可以在一天内通过编译器实现模型对应指令集,实现部署上线。
对于自研的特殊模型,例如不对称卷积算子和不对称pooling操作等,需要根据实际模型结构在本平台上进行相关算子迭代开发,开发周期可缩短在一到两周之内进行支持。
易用性
FPGA CNN加速器对底层加速过程进行封装,向上对加速平台的业务方提供易用SDK。业务方调用简单的API函数即可完成加速操作,对业务自身逻辑几乎无任何改动。
如果线上模型需要改动,只需调用模型初始化函数,将对应的模型指令集初始化FPGA即可,加速业务可以在几秒内进行切换。
结语
基于FPGA的通用CNN加速设计,可以大大缩短FPGA开发周期,支持业务深度学习算法快速迭代;提供与GPU相媲美的计算性能,但拥有相较于GPU数量级的延时优势。通用的RNN/DNN平台正在紧张研发过程中,FPGA加速器为业务构建最强劲的实时AI服务能力。
在云端,2017年初,我们在腾讯云首发了国内第一台FPGA公有云服务器,我们将会逐步把基础AI加速能力推出到公有云上。
AI异构加速的战场很大很精彩,为公司内及云上业务提供最优的解决方案是架平FPGA团队持续努力的方向。













 工商网监
工商网监
评论