 电子发烧友App
电子发烧友App


摘 要: 如今FFT卷积广泛应用于数字信号处理,并且过去几年证实了异构多核可编程系统(HMPS)的发展。另外,HMPS已经成为DSP领域的主流趋势。因此,研究基于HMPS大点FFT卷积的高效地实现显得非常重要。基于重叠相加FFT卷积方法,设计一款针对输入数据流的高效流水重叠相加滤波器。介绍了基于HMPS的大点FFT卷积实现,获得了高精度的滤波效果。此外,采用流水技术的滤波器设计,提高系统处理速度、数据吞吐率和任务并行度。基于Xilinx XC7V2000T FPGA开发板上的实验表明,参与运算的采样点越大,系统的任务并行度、处理速度和数据吞吐率就会越高。当采样点达到1M时,系统的平均任务平行度达到了5.33,消耗了2.745×106个系统时钟周期数,并且绝对误差精度达到10-4。
0 引言
在数字信号处理领域,长冲激响应的数据流卷积运算广泛地应用在雷达接收匹配滤波器、数字通信、图像处理和信号接收带通滤波器等中。FFT卷积方法将线性卷积转换到频域,通过使用有效的FFT处理器,对于数据流处理是有效算法,具有很高数据处理速度,但数据吞吐率很低。为了使用FFT卷积方法处理数据流,FFT处理器必须多路复用,以保持处理速度和吞吐率同步。
随着半导体技术的高速发展,HMPS已经成为IC主流趋势,并且在很多应用领域成为最具有发展前景的硬件处理技术[1,2]。因此,在处理零点填充数据流,大点FFT卷积运算中,HMPS成为这种数据密集型和计算密集型任务的最佳解决方法。为了获得高吞吐率和处理速度,研究基于NoC[3]互联的HMPS,充分利用其并行计算处理能力,具有良好的可拓展性和低功耗等。
大点FFT卷积实现需要大量复杂计算,成为滤波器设计的瓶颈。本文首先介绍并总结大点FFT卷积运算原理以及推导方法;其次,展示HMPS系统架构和详细的算法映射方案;最后,给出系统性能参数,包括结果误差比较、系统任务并行度、硬件资源消耗和针对系统性能的改进目标和方向等[4,5]。
1 重叠相加算法原理
如图1所示,重叠相加FFT卷积方法是将采样序列划分成具有L等长度的数据片段。假设抽头系数h(n)长度为N,采样序列x(n)为无限长,将x(n)序列等分成长为L的数据片段,如式(1)所示:

那么,序列h(n)和x(n)的FFT卷积为滤波结果,定义如下:
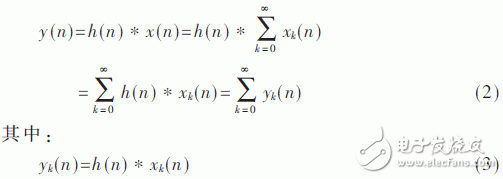
由式(2)和式(3)推导可知,当计算大点FFT卷积时,首先,计算分段片段的线性卷积yk(n),然后将分段片段的卷积结果重叠部分相加,则为最终滤波结果y(n)。
为了避免混叠效应,对于长度为M的滤波冲激响应,将各个分段序列后追加M-1个0,同时将时域卷积转换成频域相乘,在采样序列为N的DFT中,其中N≥L+M-1,由式(4)可得频域滤波结果:
其中H(k)为滤波器的频域响应,X(k)和Y(k)分别代表采样序列和滤波结果的频域响应。在零点填充的冲激响应序列和分段序列转换成频域相乘之后,将各分段滤波结果求逆FFT运算,最后在时域中,将上一份段的后M-1点与下一分段的前M-1点重叠相加即为最终滤波结果。
2 基于NoC平台的HMPS
异构多核可编程系统HMPS主要应用在高密度计算中,该系统设计不仅能满足某些特殊类型操作,而且还具有一定的通用性。
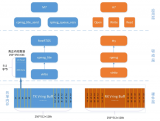
如图2所示,基于7×6 2D mesh网络结构的HMPS系统架构具有22个资源节点,所有的操作数和状态控制信息等通过该通信网络进行传递。同时,该多核系统集成的资源节点类型主要有:Flash簇、主控制器簇(Main Controller Cluster)、以太网口簇(Ethernet Port Cluster)、三层网络、4GB的DDR3簇以及3种浮点运算单元簇。该系统的32 bit浮点运算单元主要有协处理器簇(COP Cluster)、可重构运算单元簇(RCU Cluster)和FFT/IFFT簇,满足IEEE-754单精度浮点标准。在NoC平台下的每个资源节点分别具有转发状态请求包的状态网络、下发配置信息的配置网络和数据传输的包电路交换网络(PCC)。在任务运行时,所有的资源节点必须满足片上网络通信机制和主控制器任务调度管理来协同处理,发挥系统高性能优势。
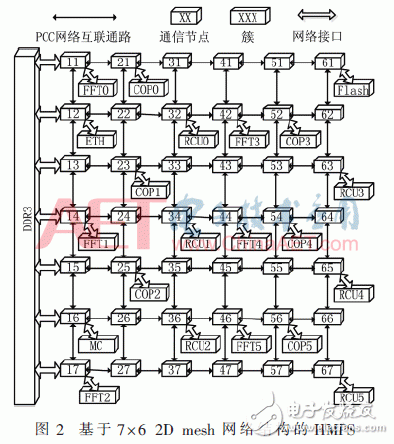
2.1 Flash簇
系统进行上电复位之后,由Flash簇中固化的配置引导信息完成HMPS系统任务初始化工作。
2.2 主控制器簇
通过向DDR请求配置信息,对参与任务的簇配置,转发数据请求/应答信息,接收DDR发出的任务切换信息,进行任务切换, 完成系统任务调度。
2.3 以太网口簇
实现上位机软件与FPGA芯片之间的数据交换,下发系统任务运算的配置信息和原数据以及回传运算结果数据,网口簇是HMPS调试的必要手段。
2.4 三层网络
由PCC网络、配置网络和状态网络组成7×6 2D mesh网络结构,完成系统中的数据以及控制信息传输。数据传输网由PCC路由节点连接而成的PCC网络,是数据传输的唯一路径。配置网络是下发配置信息和转发数据请求的唯一路径。状态网络是上传数据请求/应答信息的唯一路径。
2.5 DDR3簇
DDR3控制器能够同时处理资源节点的读写控制请求,并且将参与系统任务的相关配置信息、原始数据、中间立即数和结果数据等存储在4 GB DDR3中。
2.6 FFT/IFFT簇
32 bit浮点运算能力的FFT/IFFT簇能够支持16K点FFT和逆FFT,具有两个蝶形运算器的特殊架构设计能够同时运算,因此,16K点FFT和逆FFT仅需要56.3K系统时钟周期。
2.7 RCU簇
32 bit浮点运算能力的RCU簇主要处理复数和实数的规整运算,主要包括复、实数间的批量乘法、加法和减法等[6]。该处理单元由两个乘法器和两个加法器构成,具有可重构特性,因此能够处理大批量的数据运算。同时,能够支持两种数据运算模式:存储模式和流模式。
2.8 COP簇
满足IEEE-754单精度浮点运算标准的COP簇主要通过软件编程来控制无规律的浮点复、实数操作运算,主要包括复、实数间的加法、减法、乘法、除法、开方运算等[7]。基于SIMD架构的协处理器采用Micro blaze作为控制单元,通过FSL总线控制硬件浮点协处理器IP。参与系统任务的COP簇主要通过SDK软件编程来控制数据接收、相关运算以及传送结果到相应的处理单元中。
3 大点FFT卷积算法映射
本文采用抽头系数1K+1点的h(n)和采样点数为16K点的x(n)为例来验证零点填充和重叠相加方法,如图3所示。
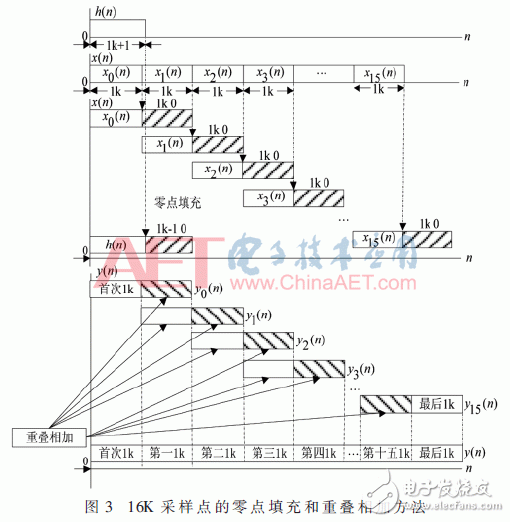
通过零点填充和流水重叠相加方法,将16K采样点划分成16组1K等长的分段,为了避免混叠效应,将所有的分段片段和抽头系数分别追加1K和1K-1点的零序列,转换成具有2K统一长度,由系统资源节点来完成各个分段片段的FFT卷积运算。为了提高处理速度和充分利用HMPS高性能优势,将所有的采样点通过时域到频域再到时域的转换,使得系统所有运算簇能够参与流水并行运算,提高系统任务并行度。
如图4(a)、图4(b)和图4(c)所示,16K采样点FFT卷积算法映射成4个子任务(Task0、Task1、Task2和Task3)。在如下的数据流图(DFG)中,系统的18个浮点运算单元参与任务执行。
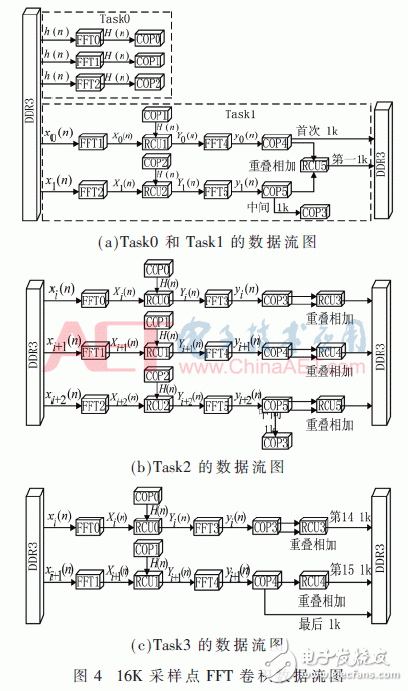
如图4(a)所示,特殊任务Task0通过FFT0、FFT1和FFT2簇来计算抽头系数的频率响应,并存储在COP0、COP1和COP2簇的片上存储单元中。在接下来的任务中,分别发送给RCU0、RCU1和RCU2簇,与零点添加分段片段序列在频域上做批量乘法运算。
Task1主要计算前2K采样点,得到前2K点滤波结果,COP3簇的片上存储单元存储来自COP5簇的中间1K滤波结果来进行接下来流水重叠相加运算。
如图4(b)所示,Task2采用了4次并行循环运算流水架构,所有的资源节点均参与任务执行,达到理论上最大值。FFT0、FFT1和FFT2簇分别计算每次流水各2K点的频域响应,RCU0、RCU1和RCU2簇分别实现抽头系数和各采样点在频域上的批量乘运算,FFT3、FFT4和FFT5簇通过逆FFT运算将频域滤波结果转换成时域,分别发送给COP3、COP4和COP5簇,最后通过RCU3、RCU4和RCU5簇实现前后两个分段片段滤波结果的1K点重叠相加,得到最终滤波结果,并且存储在DDR3簇中。
在最后一个任务Task3中,主要实现最后2K采样点滤波,将3K滤波结果写入DDR3簇中去,如图4(c)所示。至此,通过4个任务在HMPS中实现了16K点的FFT卷积运算。
在以上的算法映射方案中,通过DDR3簇来存储了参与任务执行的配置信息、原始采样数据和滤波结果,节点FFT和RCU簇参与过程计算,利用COP0、COP1和COP2簇的片上存储单元存储滤波系数的频域响应,利用COP3、COP4和COP5簇来接收和发送中间结果数据到相应的RCU3、RCU4和RCU5簇实现重叠相加。由DFG可以看出,参与任务执行的COP簇仅仅用来实现中间数据的接收和发送,并不参与实际任务运算,而所有的FFT和RCU簇参与整个任务的相关运算,因此,系统理论上最大的任务并行度为12。
根据片上网络的通信机制和HMPS中的高效浮点运算簇,该系统的大点FFT卷积映射方案比传统的设计架构更加方便,灵活而且运算效率更高。
4 实验结果和系统性能分析
在Xilinx XC7V2000T FPGA开发板上,将系统时钟频率设置为100 MHz,进行测试验证,并且通过网口簇和上位机软件将结果数据传回至本地PC。
通过将MATLAB软件的计算结果与HMPS处理结果进行误差比较可知,由于大点FFT卷积的累加运算,相对误差趋近于0,因此,给出系统的绝对误差方法,如式(5)所示:
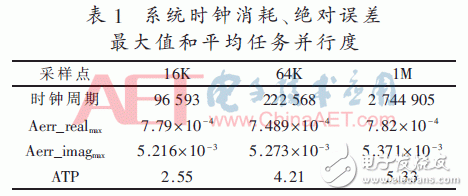
表1给出了采样点为64 K和1 M时,相应的系统时钟消耗和系统平均任务并行度,其中,Aerr_imagmax和Aerr_realmax分别代表虚部和实部的绝对误差最大值。平均任务并行度计算方法如下:
式中,clusters表示并行度,Tclusters表示在并行度clusters下的时钟消耗,T表示整个任务的时钟消耗。
在以上的映射方案中,64K和1M采样点仅需要改变Task2的循环次数,其他保持不变。零点填充和重叠相加的16K点 FFT卷积平均需要5次流水循环运算,而64K和1M采用点分别需要21次和341次流水循环运算。
从表1实验结果可以推导出,参与系统运算的采样点越大,系统平均任务并行度就越高,而且最大绝对误差接近10-4,相较于文献[8]中的异构多核处理单元的10-3相对误差,本系统具有更高的计算精度。与文献[9]中的异构多核SoC相比(其ATP最大达到3.88),本设计能达到5.33,因而具有更高的处理速度和系统平均任务并行度,采样点数越大,效果越明显。
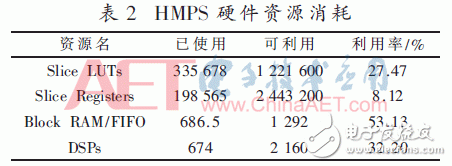
HMPS在Xilinx XC7V2000T开发板上的硬件资源消耗如表2所示。
5 结论
在很多应用领域,大点FFT卷积实现是一个需要突破的技术瓶颈,减少运算时间,提高运算效率和滤波结果正确性等具有重要意义。本文实现了基于HMPS的大点FFT卷积高效映射方案,对于2M、4M,甚至更大的采样点都可以很容易地通过以上映射方法增加流水循环次数进行实现,而且不需要增加额外的硬件资源消耗。
另外需要注意的是,系统性能和任务并行度的提高需要同一时刻所有运算簇参与任务计算。本文实现了抽头系数为1K+1点,也可以采用其他合适长度的抽头系数。作为通用目的处理器系统,HMPS主要运用在高密度计算领域,也可以实现其它复杂计算。
通过实验分析可知,系统性能有很大的提升空间,为了获得更高的数据吞吐率、处理速度和任务并行度,可以通过改善片上网络来减少通信时间和增加DDR的有效带宽来提高数据吞吐量等,具有十分重要的意义。










 工商网监
工商网监
评论