 电子发烧友App
电子发烧友App


2.5 创建 LeNet5 卷积神经网络
下面我们将开始构建更多层的神经网络。例如LeNet5卷积神经网络。
LeNet5 CNN架构最早是在1998年由Yann Lecun(见论文)提出的。它是最早的CNN之一,专门用于对手写数字进行分类。尽管它在由大小为28 x 28的灰度图像组成的MNIST数据集上运行良好,但是如果用于其他包含更多图片、更大分辨率以及更多类别的数据集时,它的性能会低很多。对于这些较大的数据集,更深的ConvNets(如AlexNet、VGGNet或ResNet)会表现得更好。
但由于LeNet5架构仅由5个层构成,因此,学习如何构建CNN是一个很好的起点。
Lenet5架构如下图所示:
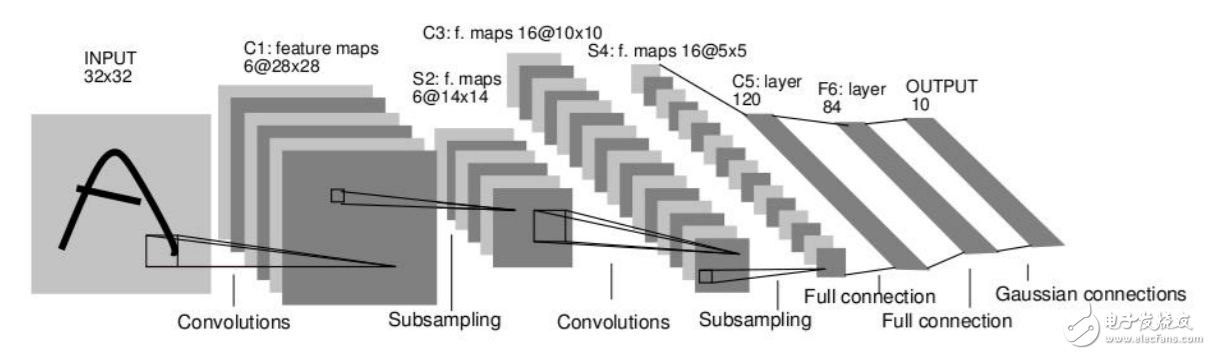
我们可以看到,它由5个层组成:
第1层:卷积层,包含S型激活函数,然后是平均池层。
第2层:卷积层,包含S型激活函数,然后是平均池层。
第3层:一个完全连接的网络(S型激活)
第4层:一个完全连接的网络(S型激活)
第5层:输出层
这意味着我们需要创建5个权重和偏差矩阵,我们的模型将由12行代码组成(5个层 + 2个池 + 4个激活函数 + 1个扁平层)。
由于这个还是有一些代码量的,因此最好在图之外的一个单独函数中定义这些代码。
LENET5_BATCH_SIZE = 32
LENET5_PATCH_SIZE = 5
LENET5_PATCH_DEPTH_1 = 6
LENET5_PATCH_DEPTH_2 = 16
LENET5_NUM_HIDDEN_1 = 120
LENET5_NUM_HIDDEN_2 = 84
def variables_lenet5(patch_size = LENET5_PATCH_SIZE, patch_depth1 = LENET5_PATCH_DEPTH_1,
patch_depth2 = LENET5_PATCH_DEPTH_2,
num_hidden1 = LENET5_NUM_HIDDEN_1, num_hidden2 = LENET5_NUM_HIDDEN_2,
image_depth = 1, num_labels = 10):
w1 = tf.Variable(tf.truncated_normal([patch_size, patch_size, image_depth, patch_depth1], stddev=0.1))
b1 = tf.Variable(tf.zeros([patch_depth1]))
w2 = tf.Variable(tf.truncated_normal([patch_size, patch_size, patch_depth1, patch_depth2], stddev=0.1))
b2 = tf.Variable(tf.constant(1.0, shape=[patch_depth2]))
w3 = tf.Variable(tf.truncated_normal([55patch_depth2, num_hidden1], stddev=0.1))
b3 = tf.Variable(tf.constant(1.0, shape = [num_hidden1]))
w4 = tf.Variable(tf.truncated_normal([num_hidden1, num_hidden2], stddev=0.1))
b4 = tf.Variable(tf.constant(1.0, shape = [num_hidden2]))
w5 = tf.Variable(tf.truncated_normal([num_hidden2, num_labels], stddev=0.1))
b5 = tf.Variable(tf.constant(1.0, shape = [num_labels]))
variables = {
'w1': w1, 'w2': w2, 'w3': w3, 'w4': w4, 'w5': w5,
'b1': b1, 'b2': b2, 'b3': b3, 'b4': b4, 'b5': b5
}
return variables
def model_lenet5(data, variables):
layer1_conv = tf.nn.conv2d(data, variables['w1'], [1, 1, 1, 1], padding='SAME')
layer1_actv = tf.sigmoid(layer1_conv + variables['b1'])
layer1_pool = tf.nn.avg_pool(layer1_actv, [1, 2, 2, 1], [1, 2, 2, 1], padding='SAME')
layer2_conv = tf.nn.conv2d(layer1_pool, variables['w2'], [1, 1, 1, 1], padding='VALID')
layer2_actv = tf.sigmoid(layer2_conv + variables['b2'])
layer2_pool = tf.nn.avg_pool(layer2_actv, [1, 2, 2, 1], [1, 2, 2, 1], padding='SAME')
flat_layer = flatten_tf_array(layer2_pool)
layer3_fccd = tf.matmul(flat_layer, variables['w3']) + variables['b3']
layer3_actv = tf.nn.sigmoid(layer3_fccd)
layer4_fccd = tf.matmul(layer3_actv, variables['w4']) + variables['b4']
layer4_actv = tf.nn.sigmoid(layer4_fccd)
logits = tf.matmul(layer4_actv, variables['w5']) + variables['b5']
return logits
由于变量和模型是单独定义的,我们可以稍稍调整一下图,以便让它使用这些权重和模型,而不是以前的完全连接的NN:
#parameters determining the model size
image_size = mnist_image_size
num_labels = mnist_num_labels
#the datasets
train_dataset = mnist_train_dataset
train_labels = mnist_train_labels
test_dataset = mnist_test_dataset
test_labels = mnist_test_labels
#number of iterations and learning rate
num_steps = 10001
display_step = 1000
learning_rate = 0.001
graph = tf.Graph()
with graph.as_default():
#1) First we put the input data in a Tensorflow friendly form.
tf_train_dataset = tf.placeholder(tf.float32, shape=(batch_size, image_width, image_height, image_depth))
tf_train_labels = tf.placeholder(tf.float32, shape = (batch_size, num_labels))
tf_test_dataset = tf.constant(test_dataset, tf.float32)
#2) Then, the weight matrices and bias vectors are initialized
variables = variables_lenet5(image_depth = image_depth, num_labels = num_labels)
#3. The model used to calculate the logits (predicted labels)
model = model_lenet5
logits = model(tf_train_dataset, variables)
#4. then we compute the softmax cross entropy between the logits and the (actual) labels
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=tf_train_labels))
#5. The optimizer is used to calculate the gradients of the loss function
optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss)
# Predictions for the training, validation, and test data.
train_prediction = tf.nn.softmax(logits)
test_prediction = tf.nn.softmax(model(tf_test_dataset, variables))
with tf.Session(graph=graph) as session:
tf.global_variables_initializer().run()
print('Initialized with learning_rate', learning_rate)
for step in range(num_steps):
#Since we are using stochastic gradient descent, we are selecting small batches from the training dataset,
#and training the convolutional neural network each time with a batch.
offset = (step * batch_size) % (train_labels.shape[0] - batch_size)
batch_data = train_dataset[offset:(offset + batch_size), :, :, :]
batch_labels = train_labels[offset:(offset + batch_size), :]
feed_dict = {tf_train_dataset : batch_data, tf_train_labels : batch_labels}
_, l, predictions = session.run([optimizer, loss, train_prediction], feed_dict=feed_dict)
if step % display_step == 0:
train_accuracy = accuracy(predictions, batch_labels)
test_accuracy = accuracy(test_prediction.eval(), test_labels)
message = "step {:04d} : loss is {:06.2f}, accuracy on training set {:02.2f} %, accuracy on test set {:02.2f} %".format(step, l, train_accuracy, test_accuracy)
print(message)
>>> Initialized with learning_rate 0.1
>>> step 0000 : loss is 002.49, accuracy on training set 3.12 %, accuracy on test set 10.09 %
>>> step 1000 : loss is 002.29, accuracy on training set 21.88 %, accuracy on test set 9.58 %
>>> step 2000 : loss is 000.73, accuracy on training set 75.00 %, accuracy on test set 78.20 %
>>> step 3000 : loss is 000.41, accuracy on training set 81.25 %, accuracy on test set 86.87 %
>>> step 4000 : loss is 000.26, accuracy on training set 93.75 %, accuracy on test set 90.49 %
>>> step 5000 : loss is 000.28, accuracy on training set 87.50 %, accuracy on test set 92.79 %
>>> step 6000 : loss is 000.23, accuracy on training set 96.88 %, accuracy on test set 93.64 %
>>> step 7000 : loss is 000.18, accuracy on training set 90.62 %, accuracy on test set 95.14 %
>>> step 8000 : loss is 000.14, accuracy on training set 96.88 %, accuracy on test set 95.80 %
>>> step 9000 : loss is 000.35, accuracy on training set 90.62 %, accuracy on test set 96.33 %
>>> step 10000 : loss is 000.12, accuracy on training set 93.75 %, accuracy on test set 96.76 %
我们可以看到,LeNet5架构在MNIST数据集上的表现比简单的完全连接的NN更好。
2.6 影响层输出大小的参数
一般来说,神经网络的层数越多越好。我们可以添加更多的层、修改激活函数和池层,修改学习速率,以看看每个步骤是如何影响性能的。由于i层的输入是i-1层的输出,我们需要知道不同的参数是如何影响i-1层的输出大小的。
要了解这一点,可以看看conv2d()函数。
它有四个参数:
输入图像,维度为[batch size, image_width, image_height, image_depth]的4D张量
权重矩阵,维度为[filter_size, filter_size, image_depth, filter_depth]的4D张量
每个维度的步幅数。
填充(='SAME'http://xilinx.eetrend.com/'VALID')
这四个参数决定了输出图像的大小。
前两个参数分别是包含一批输入图像的4D张量和包含卷积滤波器权重的4D张量。
第三个参数是卷积的步幅,即卷积滤波器在四维的每一个维度中应该跳过多少个位置。这四个维度中的第一个维度表示图像批次中的图像编号,由于我们不想跳过任何图像,因此始终为1。最后一个维度表示图像深度(不是色彩的通道数;灰度为1,RGB为3),由于我们不想跳过任何颜色通道,所以这个也总是为1。第二和第三维度表示X和Y方向上的步幅(图像宽度和高度)。如果要应用步幅,则这些是过滤器应跳过的位置的维度。因此,对于步幅为1,我们必须将步幅参数设置为[1, 1, 1, 1],如果我们希望步幅为2,则将其设置为[1,2,2,1]。以此类推。
最后一个参数表示Tensorflow是否应该对图像用零进行填充,以确保对于步幅为1的输出尺寸不会改变。如果 padding = 'SAME',则图像用零填充(并且输出大小不会改变),如果 padding = 'VALID',则不填充。
下面我们可以看到通过图像(大小为28 x 28)扫描的卷积滤波器(滤波器大小为5 x 5)的两个示例。
在左侧,填充参数设置为“SAME”,图像用零填充,最后4行/列包含在输出图像中。
在右侧,填充参数设置为“VALID”,图像不用零填充,最后4行/列不包括在输出图像中。
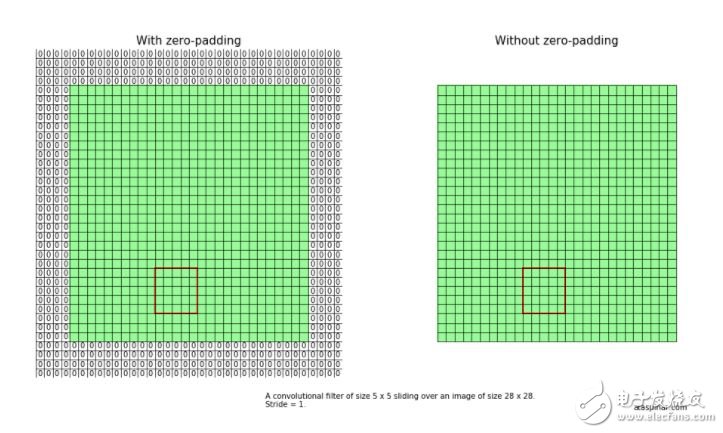
我们可以看到,如果没有用零填充,则不包括最后四个单元格,因为卷积滤波器已经到达(非零填充)图像的末尾。这意味着,对于28 x 28的输入大小,输出大小变为24 x 24 。如果 padding = 'SAME',则输出大小为28 x 28。
如果在扫描图像时记下过滤器在图像上的位置(为简单起见,只有X方向),那么这一点就变得更加清晰了。如果步幅为1,则X位置为0-5、1-6、2-7,等等。如果步幅为2,则X位置为0-5、2-7、4-9,等等。
如果图像大小为28 x 28,滤镜大小为5 x 5,并且步长1到4,那么我们可以得到下面这个表:
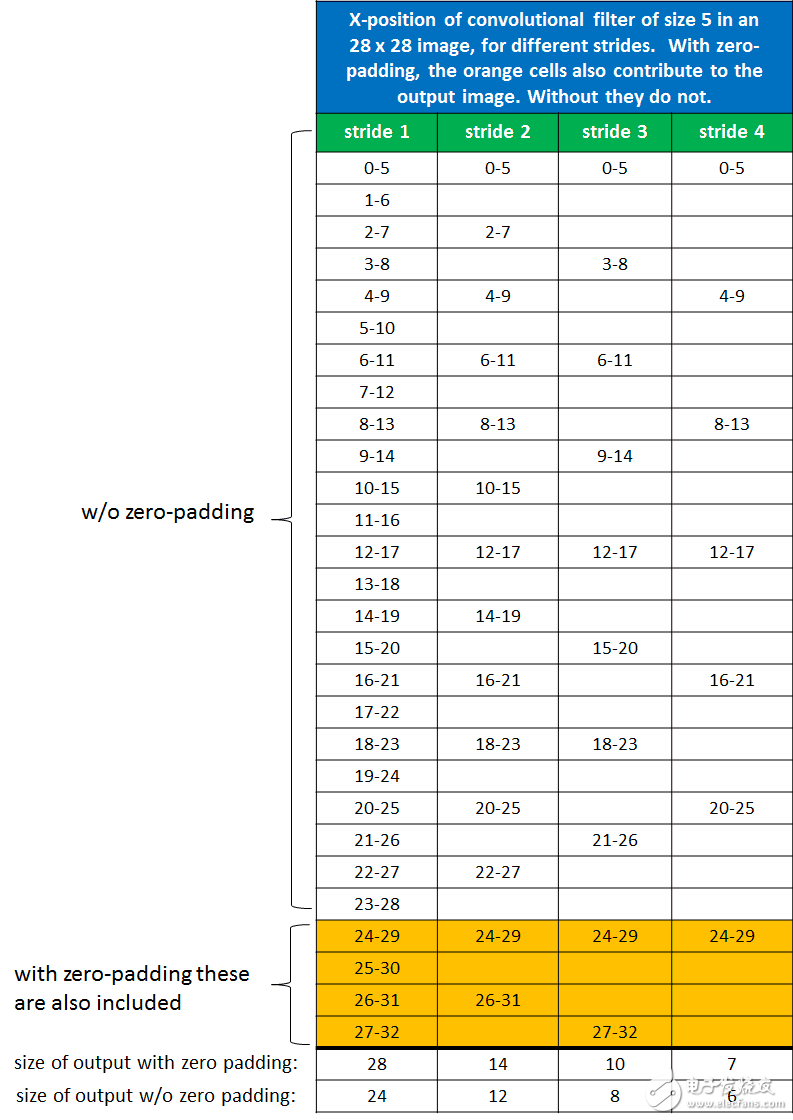
可以看到,对于步幅为1,零填充输出图像大小为28 x 28。如果非零填充,则输出图像大小变为24 x 24。对于步幅为2的过滤器,这几个数字分别为 14 x 14 和 12 x 12,对于步幅为3的过滤器,分别为 10 x 10 和 8 x 8。以此类推。
对于任意一个步幅S,滤波器尺寸K,图像尺寸W和填充尺寸P,输出尺寸将为
如果在Tensorflow中 padding = “SAME”,则分子加起来恒等于1,输出大小仅由步幅S决定。
2.7 调整 LeNet5 的架构
在原始论文中,LeNet5架构使用了S形激活函数和平均池。 然而,现在,使用relu激活函数则更为常见。 所以,我们来稍稍修改一下LeNet5 CNN,看看是否能够提高准确性。我们将称之为类LeNet5架构:
LENET5_LIKE_BATCH_SIZE = 32
LENET5_LIKE_FILTER_SIZE = 5
LENET5_LIKE_FILTER_DEPTH = 16
LENET5_LIKE_NUM_HIDDEN = 120
def variables_lenet5_like(filter_size = LENET5_LIKE_FILTER_SIZE,
filter_depth = LENET5_LIKE_FILTER_DEPTH,
num_hidden = LENET5_LIKE_NUM_HIDDEN,
image_width = 28, image_depth = 1, num_labels = 10):
w1 = tf.Variable(tf.truncated_normal([filter_size, filter_size, image_depth, filter_depth], stddev=0.1))
b1 = tf.Variable(tf.zeros([filter_depth]))
w2 = tf.Variable(tf.truncated_normal([filter_size, filter_size, filter_depth, filter_depth], stddev=0.1))
b2 = tf.Variable(tf.constant(1.0, shape=[filter_depth]))
w3 = tf.Variable(tf.truncated_normal([(image_width // 4)(image_width // 4)filter_depth , num_hidden], stddev=0.1))
b3 = tf.Variable(tf.constant(1.0, shape = [num_hidden]))
w4 = tf.Variable(tf.truncated_normal([num_hidden, num_hidden], stddev=0.1))
b4 = tf.Variable(tf.constant(1.0, shape = [num_hidden]))
w5 = tf.Variable(tf.truncated_normal([num_hidden, num_labels], stddev=0.1))
b5 = tf.Variable(tf.constant(1.0, shape = [num_labels]))
variables = {
'w1': w1, 'w2': w2, 'w3': w3, 'w4': w4, 'w5': w5,
'b1': b1, 'b2': b2, 'b3': b3, 'b4': b4, 'b5': b5
}
return variables
def model_lenet5_like(data, variables):
layer1_conv = tf.nn.conv2d(data, variables['w1'], [1, 1, 1, 1], padding='SAME')
layer1_actv = tf.nn.relu(layer1_conv + variables['b1'])
layer1_pool = tf.nn.avg_pool(layer1_actv, [1, 2, 2, 1], [1, 2, 2, 1], padding='SAME')
layer2_conv = tf.nn.conv2d(layer1_pool, variables['w2'], [1, 1, 1, 1], padding='SAME')
layer2_actv = tf.nn.relu(layer2_conv + variables['b2'])
layer2_pool = tf.nn.avg_pool(layer2_actv, [1, 2, 2, 1], [1, 2, 2, 1], padding='SAME')
flat_layer = flatten_tf_array(layer2_pool)
layer3_fccd = tf.matmul(flat_layer, variables['w3']) + variables['b3']
layer3_actv = tf.nn.relu(layer3_fccd)
#layer3_drop = tf.nn.dropout(layer3_actv, 0.5)
layer4_fccd = tf.matmul(layer3_actv, variables['w4']) + variables['b4']
layer4_actv = tf.nn.relu(layer4_fccd)
#layer4_drop = tf.nn.dropout(layer4_actv, 0.5)
logits = tf.matmul(layer4_actv, variables['w5']) + variables['b5']
return logits
主要区别是我们使用了relu激活函数而不是S形激活函数。
除了激活函数,我们还可以改变使用的优化器,看看不同的优化器对精度的影响。
2.8 学习速率和优化器的影响
让我们来看看这些CNN在MNIST和CIFAR-10数据集上的表现。
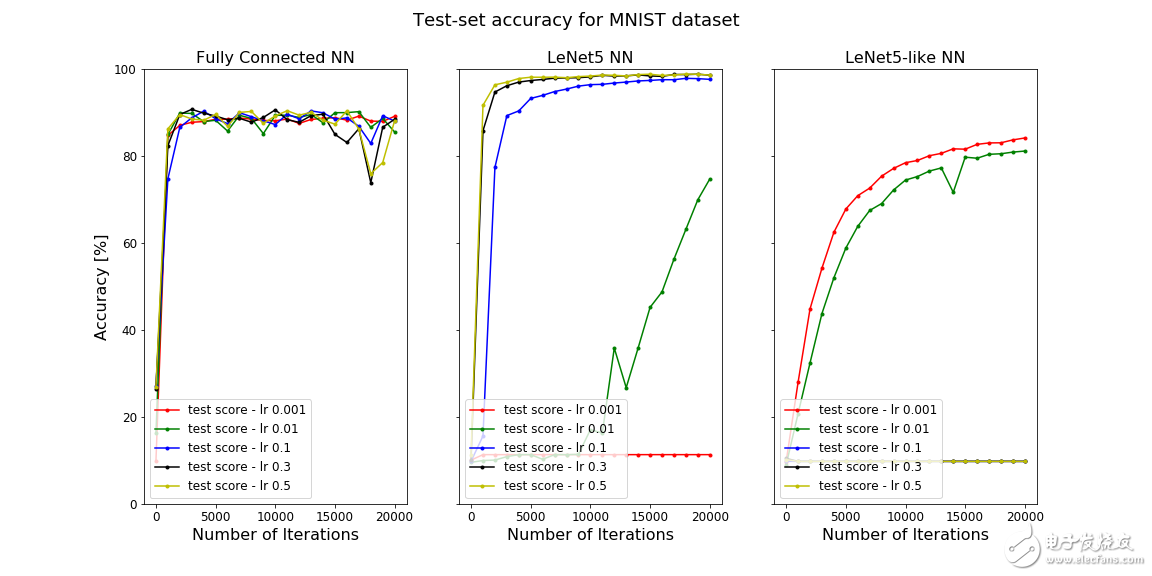
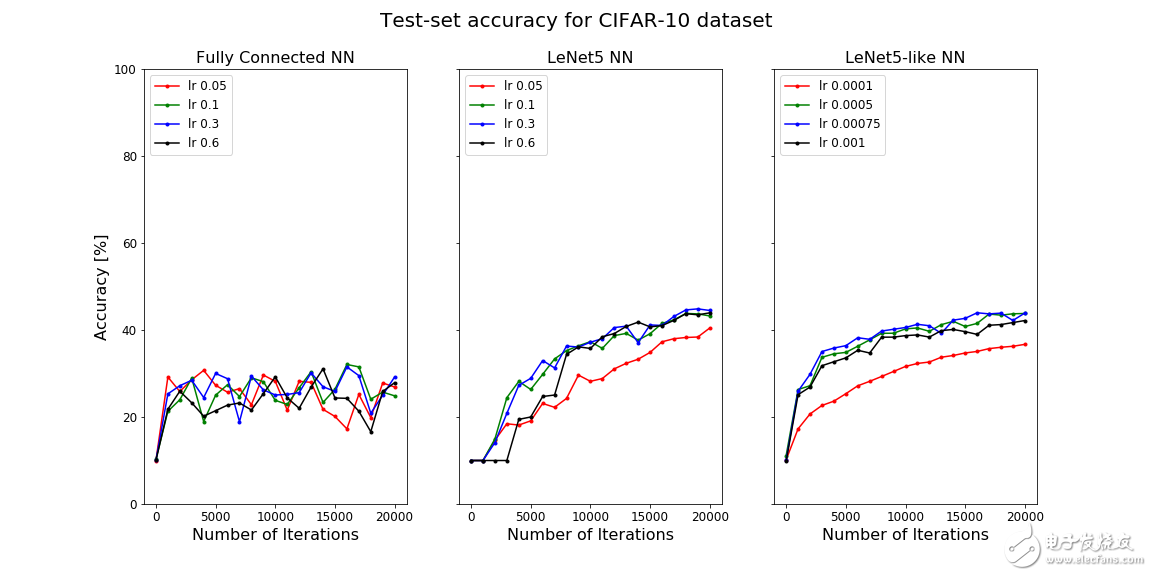
在上面的图中,测试集的精度是迭代次数的函数。左侧为一层完全连接的NN,中间为LeNet5 NN,右侧为类LeNet5 NN。
可以看到,LeNet5 CNN在MNIST数据集上表现得非常好。这并不是一个大惊喜,因为它专门就是为分类手写数字而设计的。MNIST数据集很小,并没有太大的挑战性,所以即使是一个完全连接的网络也表现的很好。
然而,在CIFAR-10数据集上,LeNet5 NN的性能显着下降,精度下降到了40%左右。
为了提高精度,我们可以通过应用正则化或学习速率衰减来改变优化器,或者微调神经网络。
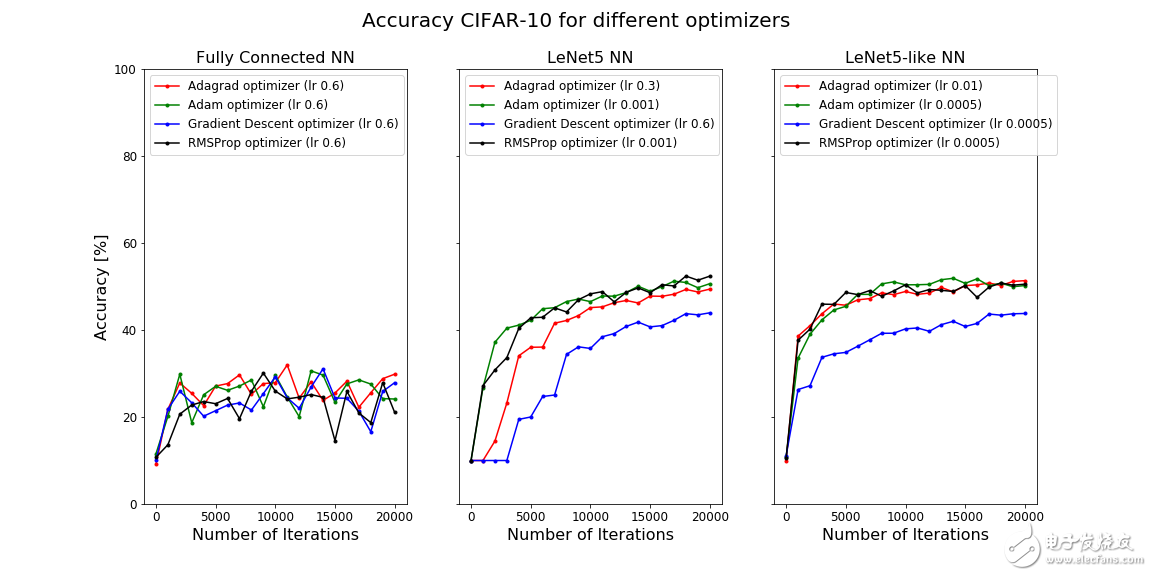
可以看到,AdagradOptimizer、AdamOptimizer和RMSPropOptimizer的性能比GradientDescentOptimizer更好。这些都是自适应优化器,其性能通常比GradientDescentOptimizer更好,但需要更多的计算能力。
通过L2正则化或指数速率衰减,我们可能会得到更搞的准确性,但是要获得更好的结果,我们需要进一步研究。










 工商网监
工商网监
评论