 电子发烧友App
电子发烧友App


UltraFast是Xilinx在2013年底推出的一套设计方法学指导,旨在指引用户最大限度地利用现有资源,提升系统性能,降低风险,实现更快速且可预期的设计。面向Vivado的UltraFast方法学的主体是UG949文档,配合相应的Checklist,随Vivado版本同时更新,用户可以在Xilinx的主页上免费下载。目前,针对Vivado设计套件的UltraFast中文版也已经上市,另外一套全新的针对嵌入式可编程设计的UltraFast嵌入式设计方法指南UG1046也已经在Xilinx官网上开放下载。
尽管UltraFast这个字眼经常在网上看到,不论官方还是其他媒体上说起Vivado设计套件时也常常提到,但很多用户仍然对这个概念十分模糊,有不少人下载文档后看到300页的PDF顿时也失去了深入学习和了解的兴趣。
适逢《Vivado使用误区与进阶》系列连载半年多,大部分预先列好的主题也都已经按照计划完成,我们准备把这些短文集结为一本电子书,方便更多读者随手翻阅或是必要时用作设计参考。借此机会,套用在Xilinx内部被誉为 “Vivado之父”的产品营销总监 Greg Daughtry在去年第一届Club Vivado中所提出的 “时序收敛十大准则” 的概念,试着用十分钟的篇幅来概括一下什么是UltraFast,以及怎样利用UItraFast真正帮助我们的FPGA设计。
时序设计的十大准则,基本上也涵盖了UltraFast设计方法指南的基本要点。UG949中将FPGA设计分为设计创建、设计实现和设计收敛几大部分来讨论,除了介绍所有可用的设计方法和资源,更多的是一些高级方法学技巧,这些技巧基本上都跟时序收敛有关或是以时序收敛为目标,有些通用的方法和技巧甚至脱离了具体选用的FPGA器件的限制,适用于更广泛意义上的时序收敛。
最宝贵的是,所有这些UltraFast设计方法学技巧都来自一线技术支持人员的经验以及客户的反馈,是业界第一本真正意义上完全面向用户的指南,这一点只要你试着读过一两节UG949就会有明显感觉,所有其中提到的技巧和方法都具有很高的可操作性,可以带来立竿见影的效果。
接下来我们就由这十大准则展开,带领各位读者在十分钟内理清UltraFast方法学的脉络,一探其究竟。
准则一:合适的代码风格
理想环境下,源代码可以独立于最终用于实现的器件,带来最佳的可移植性和可复用性。但是,底层器件各自独特的结构,决定了通用代码的效率不佳,要最大化发挥硬件的性能,必然需要为实现工具和器件量身定制代码。
关于Xilinx器件和Vivado适用的代码风格,我们有以下建议:
准则二:精准的时序约束
精准的时序约束是设计实现的基础,对时序驱动工具Vivado来说,约束就是最高指示,是其努力实现的目标。很多时候我们发现,约是有经验的工程师约是喜欢用一些旧有经验套用在Vivado上,例如很多人偏爱用过约束的方式来追求更高的性能,但实际上对Vivado来说,大部分的过约束只会阻碍时序收敛。
简要概括而言,精简而准确的约束是时序收敛的必要条件,而UltraFast中提出的Baseline基线方法则是充分条件。
具体的约束方法我们在《XDC约束技巧》中有详细讨论,除了保证语法正确,还要注意设置XDC约束的顺序,通常第一次运行时只需要约束所有时钟,然后在内部路径基本满足时序约束的情况下加入关键I/O的约束,其次再考虑必要的时序例外约束。
所有这些约束都必须遵循精简而准确的原则,且可以借助Vivado中的XDC Templates以及Timing Constraint Wizard的帮助来进行。
Baseline基线方法可以说是UltraFast的灵魂部分,强烈建议所有Vivado的用户都能精读UG949中的这部分内容,并将之应用在具体的设计中。有机会我会深入展开一篇专门介绍Baseline方法的短文,这里先将其核心的概念做一个总结。
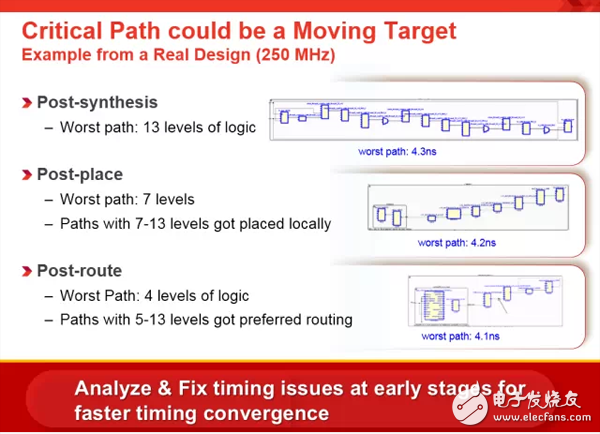
上图展示了同一个设计在三个不同阶段用同样的命令报告时序所得到的最差路径,可以清晰的看出,即使不做任何源代码上的改动,设计中真正最差的路径已经不会作为最差路径出现在布局布线后的报告中。这正是因为Vivado时序驱动的天性决定了其在设计实现的每一步都是以开始时读到的设计输入和约束为依据,尽量将最好的资源用在最差的路径上,从而尽最大可能实现时序收敛。
这便是Baseline理论的基础,除了按顺序设置精准的时序约束,在设计实现的每一步,用户都需要关注时序报告,并以其为依据来调整设计源代码或是应用其他必要的约束和选项来优化设计。保证每一阶段之后的时序报告都满足约束或是仅余300ps以内的时序违例,再进入下一阶段的设计实现过程,否则,应该继续在当前阶段或是退回到上一阶段调整后重跑设计,直到满足要求再继续。
越早发现和定位问题,越是可以通过少量的努力来达到更大范围的改进。
准则三:管理高扇出网络
高扇出网络几乎是限制FPGA设计实现更高性能的第一大障碍,所以我们需要很严肃地对待设计中的高扇出网络。
很多人会陷入一个误区,反复纠结到底多大的扇出值算是大?其实这一点不是绝对的,在资源充裕时序要求不高的情况下几千甚至上万都不算大,反之在局部关键路径上仅有几十的扇出也可能需要进一步降低。
在Vivado中,我们除了关注时序报告,尤其是布局后布线前的报告来定位关键路径上影响时序的高扇出网络外,还有一个专门的命令report_high_fanout_nets ,在给其加上 -timing的选项后,可以在报告高扇出路径的同时报告出这条路径的Slack,帮助用户直观了解当前路径的时序裕量。此外,这个命令在报告中还会指出高扇出网络的驱动类型,是FF或是LUT等。
找到目标后,可以利用max_fanout来限定其扇出值,让工具在实现过程中复制驱动端寄存器来优化。如果高扇出网络并不是由同步逻辑来驱动,则可能需要修改代码。还有一些工具层面上的降扇出方法,比如选择更强更有针对性的策略,或是允许多次物理优化phys_opt_design,甚至是通过我们在《用Tcl定制Vivado设计实现流程》中提到的“钩子”脚本等方式来进行局部降扇出的物理优化等等。
但有一点需要注意,Vivado综合选项中的全局扇出限定要慎用 ,不要将其设置的过低以免综合出的网表过于庞大,带来资源上的浪费,并可能导致局部拥塞。
准则四:层次化设计结构
随着设计规模的不断扩大,以及SoC设计的兴起,越来越多的IP被整合到大设计中,曾经为高性能设计而生,便于统一管理和控制的自顶向下的设计流程变得不再适用,FPGA设计也跟大规模SoC设计一样,需要采用层次化的设计流程,即自底向上的流程。这也要求设计者在源代码阶段就考虑到最终的实现,处理好模块的层次边界。
Vivado中的IP设计是原生的自底向上流程,用户可以将IP生成独立的DCP再加入到顶层设计中去。我们也鼓励用户将某些相对固定或独立的模块综合成DCP后加入顶层设计,这么做除了加快设计迭代外,也更利于设计开始阶段的调试和问题的定位。
Vivado中的OOC模式甚至还支持完全层次化的设计,即将底层模块的布局布线结果也进行复用,这么做虽然流程复杂,却带来了更全面的控制性,也是部分可重配置技术的实现基础。
准则五:处理跨时钟域设计
FPGA设计中通常都带有跨时钟域的路径,如何处理这些CDC路径非常重要。由于Vivado支持的约束标准XDC在处理CDC路径上与上一代ISE中支持的UCF约束有本质区别,如何约束以及怎样从设计上保证CDC路径的可靠性就成了重中之重。
《XDC约束技巧之CDC篇》中对Vivado中的跨时钟域设计有详细描述,UG949中也有不少篇幅用来讨论CDC路径的各种设计技巧和约束方法。建议用户深入学习和了解这部分的内容,其中有不少概念并不仅仅局限于FPGA设计中的跨时钟域设计,放在其他IC设计上也一样有效。
需要提醒大家的是,一定要利用好Vivado中的各种报告功能,例如report_cdc和DRC报告中的methodology_checks来检测设计中的CDC结构问题,并作出具体的设计调整或是补全CDC约束。另外要注意各种不同的CDC路径处理方法之间的优劣,选择最适合自己设计的方式,配合相应的约束来保证跨时钟域路径的安全。
准则六:少而精的物理约束
不同于对时序约束尤其是时钟约束之全面而精准的要求,Vivado对物理约束的要求只有一个字:少。这里的物理约束更多强调的是除了I/O引脚位置这些必要项之外的约束,例如对RAMB和DSP48的位置约束,还有局部的floorplan计划。
很多资深工程师非常喜欢画floorplan,因为其对设计的数据流和资源使用情况了如指掌,根据自己理解画出的floorplan通常也算合理。但是,floorplan在Vivado中的重要性远低于以往在ISE上的作用。根据客户的实际经验反馈,绝大多数的设计中都无需任何floorplan(某些时序要求较高的SSI芯片设计上可能需要),因为算法的改进,Vivado在布局上比上一代ISE更聪明,没有任何物理约束(除了IO引脚位置约束)的设计反而能在更短的时间内更好地满足时序要求。
在确实需要锁定某些宏单元以及进行floorplan的设计中,一般我们会推荐先不加任何物理约束来跑设计,在其他诸如改进源代码,设置约束和选项,改变策略等办法都试过后,再尝试物理约束。而且,最好只在少量关键的设计区域进行floorplan,切忌过度约束,不要创建资源利用率过高的pblocks,同时避免重叠的pblocks区域。
顺便提一下,Vivado IDE中的Device视图可以通过设置不同颜色来高亮显示不同模块,用户可以根据当前设计的布局结果配合时序报告和关键路径来创建和调整floorplan,操作非常便捷。
准则七:选择实现策略
从ISE升级到Vivado后,很多用户发现SmartXplorer功能不见了,当设计进行到后期,假如不能遍历种子,常让人感到无所适从,甚至怀疑到了这一步Vivado便无计可施。那么事实到底如何呢?
严格来讲,Cost Table 其实是一种无奈之举,说明工具只能通过随机种子的改变来“撞大运”般筛选出一个最佳结果,这也解释了为何改变Cost Table的结果是随机的,一次满足时序,并不代表一直可以满足。
因为更高级算法的引入,Vivado中的设计实现变得更加可靠,而且是真正意义上的可预计的结果。但这并不代表在Vivado中对同一个设计进行布局布线只能有一种结果。我们可以通过“策略”来控制实现过程中的算法侧重,从而可以产生更优化的结果。
策略(Strategy)是一组工具选项和各个阶段指示(Directive)的组合,Vivado IDE中内置了几十种可供用户直接选用,但如果穷尽各种组合,整个实现过程大约有上千种策略。当然,我们没必要遍历每种策略。而且因为策略是一种可预计可重现的实现方法,所以对同一个设计,可以在选择几种有侧重点的策略后挑选出效果最好的那个,只要设计后期没有大的改动,便可一直延用同样的策略。
具体策略的特性,请参考UG949和UG904等文档,也可以在Vivado中通过help菜单了解。更多时候,选择怎样的策略是一种经验的体现,另外,即使找到了最佳实现策略,也仍旧有可能不满足时序要求,这时候我们还可以参考《用Tcl定制Vivado设计实现流程》中所述,对设计实现的流程进行进一步的个性化定制。
另外要强调一点,修改策略来提升性能必须放在调整代码、约束和选项等更直接高效的优化方法之后进行,其能带来的性能提升比起前述优化方法来说也更加局限。
准则八:共享控制信号
共享控制信号这一点充分体现了设计必须考虑到用于底层实现的芯片结构的重要性,在Xilinx的芯片上,时钟、置位/复位和时钟使能等信号通称为Control Set,进入同一个SLICE的Control Set必须统一。换句话说,不同Control Set控制下的FFs不能被Vivado放进同一个SLICE。
为了提升SLICE的利用率,获得更高效的布局方案,提升时序性能,我们必须控制一个设计中Control Set的总数,尽量共享控制信号。具体做法包括:
尽量整合频率相同的时钟和时钟使能信号;
在生成IP时选择“共享逻辑”功能,则可以在不同IP间尽可能的共享时钟资源;
遵循Xilinx建议的复位准则:
尽量少使用复位
必须复位时采用同步复位
确保使用高电平有效的复位
避免异步复位(RAMB和DSP48模块中不支持异步复位)
Xilinx的复位准则必须严格遵守,根据现场支持的经验来看,很多设计性能的瓶颈就在于设计源代码时没有考虑底层实现器件的硬件结构特点,尤其以复位信号的实现问题最为突出。
准则九:读懂日志和报告
任何一个工具的日志和报告都是衡量其性能最重要的一环,正因为有了完备的日志与报告,用户才可以通过其中显示的信息,定位设计中可能的问题,决定优化方向。
Vivado日志中将信息显示为三大类,分别为Error、Critical Warning和一般Warning/Notes等。Error会导致工具直接中断,其他警告不会中断工具运行,但所有的Critical Warning都需要用户逐一检查并通过修改设计、增加约束或设置选项之类的办法来修复。
Vivado的报告功能很强大,除了《读懂用好Timing Report》中描述的时序分析报告,还有很多重要的报告,小到检查设计中的特定时序元件和链路,大到各种预置和自定义的DRC检查,不仅提供给了用户多样的选择,也进一步保证了设计的可靠性。
Vivado也一直在增强和更新报告的种类,比如2014.3之后还增加了一个设计分析报告report_design_analysis,用来报告关键路径上的潜在问题以及设计的拥塞程度。完整的report命令和功能可以在UG835中查询。
准则十:发挥Tcl的作用
Tcl在Vivado中的作用不容小觑,不仅设计流程和报告全面支持Tcl脚本,就连XDC约束根本上也来自于Tcl,用户甚至可以直接把包含有循环等功能的高级约束以Tcl的形式读入Vivado中用来指引整个实现流程。
《Vivado使用误区与进阶》系列中有三篇关于Tcl在Vivado中的应用文章,详细描述了如何使用Tcl创建和应用约束,查找目标和定位问题;如何用Tcl来定制Vivado的设计实现流程,为图形化界面提供更多扩展支持;以及如何用Tcl实现ECO流程。Tcl所带来的强大的可扩展性决定了其在版本控制、设计自动化流程等方面具有图形化界面不能比拟的优势,也解释了为何高端FPGA用户和熟练的Vivado用户都更偏爱Tcl脚本。
另外,随着Xilinx Tcl Store的推出,用户可以像在App Store中下载使用app一样下载使用Tcl脚本,简化了Tcl在Vivado上应用的同时,进一步扩展了Tcl的深入、精细化使用。最重要的是,Tcl Store是一个基于GitHub的完全开源的环境,当然也欢迎大家上传自己手中有用的Tcl脚本,对其进行补充。
小结
关于UltraFast的要点总结基本可以概括在上述十点,这也可以看作是对《Vivado使用误区与进阶》系列短文的一个串烧。说实话,八九页的篇幅要将整个UltraFast讲透基本没有可能,对于正在使用Vivado做设计或是有兴趣试用的读者们,强烈建议各位在Xilinx官网络下载完整的UltraFast指南并通读。
这篇短文和这本电子书旨在帮助大家尽快上手Vivado和XDC,宝剑在手,再加上盖世神功傍身,行走江湖岂不快哉。衷心祝福大家在FPGA设计之路上收获更多喜悦,让Xilinx和Vivado为您的成功助力。








 工商网监
工商网监
评论