 电子发烧友App
电子发烧友App


Vivado HLS配合C语言等高级语言能帮助您在FPGA上快速实现算法。
高层次综合(HLS)是指自动综合最初用C、C++或SystemC语言描述的数字设计。工程师之所以对高层次综合如此感兴趣,不仅是因为它能让工程师在较高的抽象层面上工作,而且还因为它能方便地生成多种设计解决方案。利用HLS,您能探索各种可能性,分析面积和性能特点,最终确定一个方案在FPGA芯片上实现算法。举例来说,您能探索将存储器映射到Block RAM(BRAM)或分布式RAM上有什么不同的影响,或者分析回路展开以及其它回路相关优化有什么效果,而且不必手动生成不同的寄存器传输级(RTL)设计。您所要做的仅仅是在C/C++/SystemC设计中设置相关指令而已。
赛灵思在其最新发布的Vivado™工具套件中推出了HLS工具。Vivado HLS是AutoESL工具的品牌转型重塑,可提供众多技术帮助您优化C/C++/SystemC代码以实现目标性能。这样的HLS工具就能帮助您在FPGA上快速实现算法,无需借助基于Verilog和VHDL等硬件描述语言的非常耗时的RTL设计方法。
为了帮助用户了解Vivado HLS如何工作,我们不妨以矩阵乘法设计为例逐步剖析从设计描述(C/C++/SystemC)到FPGA实现整个端对端综合流程。矩阵乘法在许多应用中都很常见,并广泛用于图像和视频处理、科学计算和数字通信。本项目中的所有结果均使用Vivado HLS 2012.4生成,搭配使用赛灵思 ISE®软件(14.4版)进行物理综合和布局布线。此外,这一流程还采用了ModelSim和GCC-4.2.1-mingw32vc9进行RTL协同仿真。
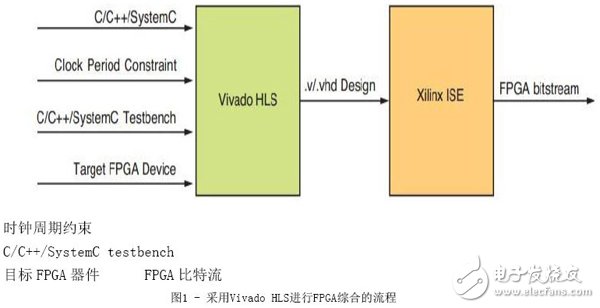
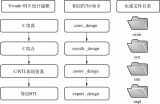
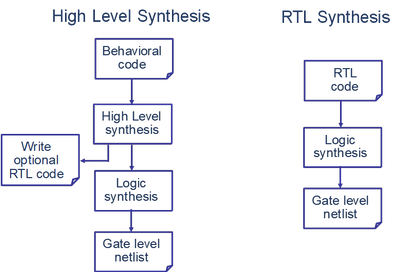
图1显示了简单的综合流程,从C/C++/SystemC设计开始。C/C++/SystemC testbench用于验证设计功能的正确性,同时还可用于RTL和C的协同仿真。协同仿真包括验证生成的RTL设计(.v或.vhd)功能,这要使用C/C++/SystemC测试平台而不是RTL测试平台或者采用e或Vera验证语言编写的测试平台。时钟周期约束设置了设计应该运行的目标时钟周期。设计将被映射到目标FPGA器件——赛灵思FPGA上。
C语言的矩阵乘法
为了充分利用我们的矩阵乘法实例,我们将探索矩阵乘法C语言实现方案的各种修订版本,从而展示它们对综合设计的影响。这一过程将凸显您在使用HLS进行原型设计和实际设计时需要注意的重要问题。我们将跳过创建工程的有关步骤,因为您能很方便地在工具文档中找到相关参考材料。我们将重点介绍设计和实现等方面。
在典型的Vivado HLS流程中,我们需要三个C/C++文件:源文件(包括待综合的C函数)、头文件和通过main()函数调用描述testbench的文件。
头文件不仅包括源文件中使用的函数的声明,也包括支持具有特定位宽的用户定义数据类型的指令。这也使得设计人员能够采用与C/C++所定义标准位宽不同的位宽。举例来说,整形数据类型(int)在C语言中通常为32位长,但是在Vivado HLS中您可指定用户定义的数据类型,例如只使用16位的“data”。
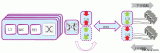
图2显示了用于矩阵乘法的简单C函数。两个矩阵mat1和mat2进行乘法。为了简单起见,两个矩阵大小一样,都是两行两列。

在HLS流程中执行的步骤如下:
• 第一步:创建工程
• 第二步:测试功能
• 第三步:综合
• 第四步:RTL协同仿真
• 第五步:导出RTL / RTL实现
第一步编译工程并在不同的设计文件中测试语法错误等。第二步测试待实现的函数(在源文件中)功能是否正确。在这一步骤中您将使用testbench执行函数调用,验证其功能是否正确。如果功能验证失败,您就需要返回来修改设计文件。
第三步进行综合,Vivado HLS综合源文件中定义的函数。这一步的输出包括C函数的Verilog和VHDL代码(RTL设计),也包括目标FPGA的资源利用率估算和时钟周期估算。此外,Vivado HLS还可生成latency估算和回路相关的度量指标等。
第四步是使用C testbench仿真生成的RTL。这一步叫做RTL协同仿真,因为工具采用的就是之前用于验证C源代码的testbench,现在则测试RTL的功能正确性。要成功完成这一步,您系统(Windows或Linux)中的PATH环境变量应包含ModelSim安装的路径。此外,您还应在ModelSim安装文件夹中包含GCC-4.2.1-mingw32vc9套件。
最后,第五步就要将RTL导出为IP模块,用于更大的设计中,并由其它赛灵思工具进行处理。您可将RTL导出为IP-XACT格式的IP模块,也可导出为System Generator IP模块或pcore格式的IP模块,进而用于赛灵思嵌入式设计套件。导出Vivado生成的RTL时,您可以选择工具的“评估”选项来评估布局布线后的性能并且运行RTL实现。在此情况下, Vivado HLS工具会调用赛灵思ISE工具。要实现这一目的,您的系统PATH环境变量需包括ISE安装路径,Vivado HLS将会搜索ISE安装。
当然,您也不一定非要将Vivado生成的RTL导出为以上三种格式之一的IP模块不可。导出的格式文件可放在三个不同路径下:此外,您也可在较大设计中使用Vivado生成的RTL,或者将其本身用作顶层设计。当较大设计中例化导出的RTL时,您应注意相关接口要求。
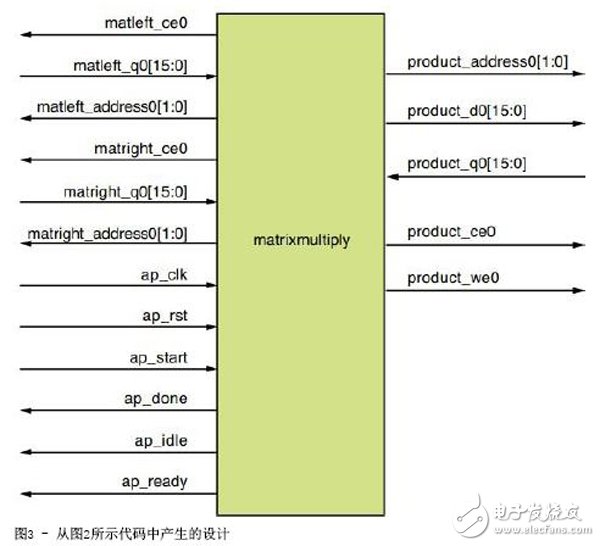
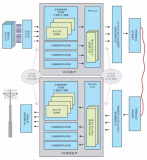
当综合图2中的C函数时,您将获得如图3所示的RTL级实现方案。您会发现,实现方案中的矩阵1和矩阵2的元素被读取到函数,并且积矩阵的元素被写出。这样,实现方案假定“矩阵乘法”实体以外的存储器能用来存储矩阵1、矩阵2和乘积矩阵的元素。表1介绍了信号描述,表2则介绍了设计度量指标。
表2:用于图3所示设计的设计度量指标
设计度量指标
器件:XC6VCX75TFF784-2
DSP48E
1
查找表
44触发器
61实现的最佳时钟周期(ns)
2.856时延
69吞吐量(初始间隔)
69表1:面向图3中设计的信号描述
信号
描述
matleft_ce0
矩阵1存储器的芯片使能
matleft_q0[15:0]
矩阵1的16位元素
matleft_address[1:0]
矩阵1存储器的读地址
matright_ce0
矩阵2存储器的芯片使能
matright_q0[15:0]
矩阵2的16位元素
matright_address[1:0]
矩阵2存储器的读地址
product_ce0
积矩阵的存储器的芯片使能
product_we0
积矩阵的存储器的写使能
product_d0[15:0]
积矩阵存储器的写数据
product_q0[15:0]
积矩阵存储器的读数据
product_address0[1:0]
积矩阵要读写数据的地址
ap_clk
设计的时钟信号
ap_rst
设计的高有效同步复位信号
ap_start
开始计算的开始信号
ap_done
计算结束和输出就绪的完成信号
ap_idle
表示实体(设计)空闲的空闲信号
ap_ready
表示设计为新输入数据做好准备,与ap_idle配合使用
在表1中,start、done和idle信号与设计中控制数据路径的有限状态机(FSM)有关。您会发现,Vivado HLS生成的Verilog假定运算始于start信号,并且输出数据在ap_done信号从低变高开始有效。Vivado HLS生成的Verilog/VHDL将始终保持至少三个基本信号:ap_start、ap_done和ap_idle,此外还有ap_clk信号。这意味着不管您使用Vivado HLS实现什么设计,设计latency都会限制您的流吞吐量。图2中的设计latency为69个时钟周期,目标时钟周期为3纳秒。这意味着在此特定案例中,所有积矩阵元素需要69个时钟周期可输出。这样,您在至少69个时钟周期前不能为设计提供新一组的输入矩阵。
图3中所示的实现方案现在可能并不是您在FPGA上实现矩阵乘法时所预想的结果。您或许希望一款实现方案能让您输入矩阵,并在内部进行存储和计算,随后读取积矩阵元素。这显然是图2所示实现方案无法做到的。该实现方案需要外部存储器提供矩阵数据的输入和输出。
调整代码
图4中的代码能够满足您的需求,它是源文件的一部分,应该属于C++文件而非此前的C文件。您应在头文件matrixmultiply.h中包含另外两个相关头文件:hls_stream.h和ap_int.h。请注意,在图2中,当源文件为C文件时,头文件包含了ap_cint.h。头文件ap_int.h和ap_cint.h有助于分别为C++和C源文件定义用户定义的任意位宽的数据类型。需要头文件hls_stream.h来充分利用流接口,并且只有在源文件为C++语言时才能使用。
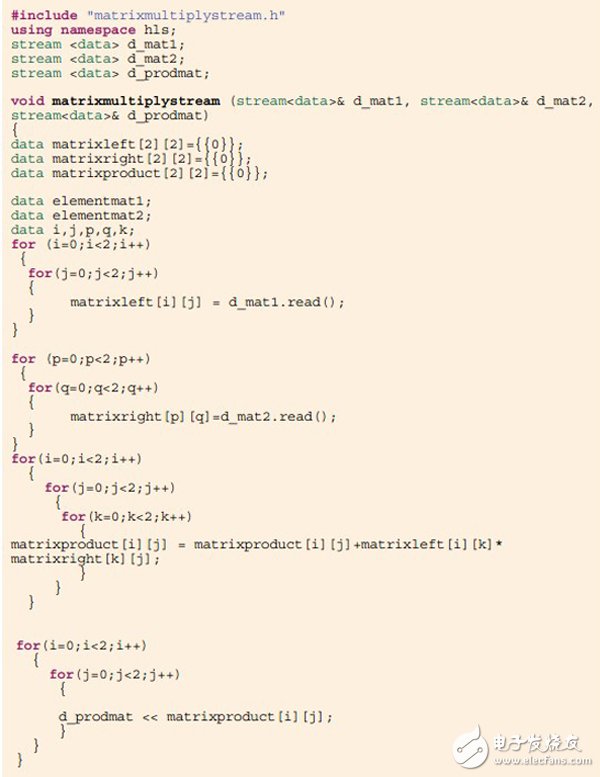
图4:用于矩阵乘法的重组源代码
为了让设计只接收输入矩阵流,并输出积矩阵流,您应在代码中实现读和写数据流。流接口就像FIFO。默认情况下这个FIFO的深度为1。
表3 - 图5中设计的信号描述
信号
描述
d_mat1_V_read
设计为矩阵1(左侧矩阵)输入做好准备时的信号
d_mat1_V_dout [15:0]
矩阵1的16位流元素
d_mat1_V_empty
通知设计矩阵1没有更多元素的信号
d_mat2_V_read
设计为矩阵2(右侧矩阵)输入做好准备时的信号
d_mat2_V_dout [15:0]
矩阵2的16位流元素
d_mat2_V_empty
通知设计矩阵2没有更多元素的信号
d_product_V_din [15:0]
积矩阵的16位输出元素
d_product_V_full_n
通知设计积矩阵应该被写入的信号
d_product_V_write
显示积矩阵正在被写入数据的信号
ap_clk
设计的时钟信号
ap_rst
设计的高有效同步复位信号
ap_start
开始计算的开始信号
ap_done
计算结束和准备好信号输出的完成信号
ap_idle
表明实体(设计)空闲的空闲信号
ap_ready
表示设计为新输入数据做好准备,与ap_idle配合使用
表4:图5所示设计的设计度量指标
器件:XC6VCX75TFF784-2
设计参数
无BRAM
或无分布式RAM存储矩阵
单端口BRAM存储矩阵
分布式RAM(LUT实现)存储矩阵
DSP48E
1
1
1
查询表
185
109
179
触发器
331
102
190
BRAM
0
3
0
实现的最佳时钟周期(纳秒)
2.886
3.216
2.952
时延
84
116
104
吞吐量(初始间隔)
84
116
104
为了让设计只接受输入矩阵流,并输出积矩阵流,您应在代码中实现读和写数据流。代码hls::stream<> stream_name用于为读和写数据流命名。这样,d_mat1和d_mat2为读取流而d_product为写入流。流接口就像FIFO那样工作。默认情况下,FIFO的深度为1。您应在Vivado HLS指令面板中通过选择定义的数据流设置深度。对于图4中的代码而言,每个数据流的深度都为4个数据单元。请注意,这里的(i,j)回路在(p,q)回路之前执行,这是C++代码的顺序特性使然。因此,d_mat2数据流会在d_mat1数据流之后填满。
完成数据流接口后,您可应用指令RESOURCE并通过指令面板选择一个核,从而选择将矩阵映射到BRAM。否则将用触发器和查找表(LUT)实现矩阵。请注意,指令面板只有当源文件在综合视图中保持有效时才是有效的。
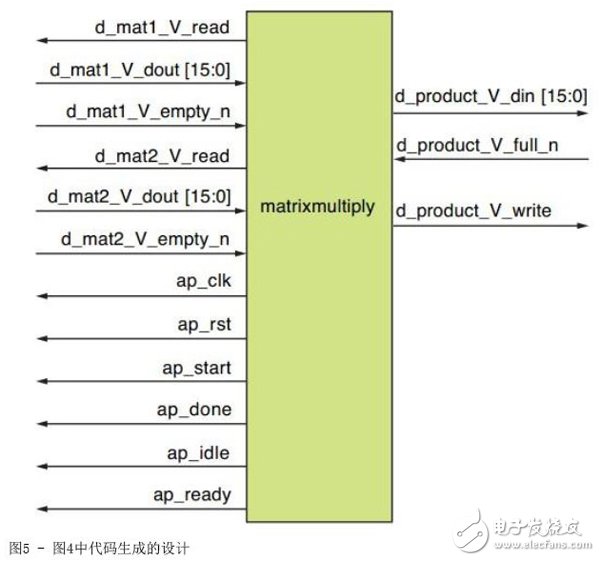
图5显示了图4中代码的设计实现情况。表3介绍了设计接口上可用的信号情况。在表3中,d_product_V_full_n是低有效信号,当需要通知内核积矩阵已满时该信号为低。但在实现方案中通常不需要这样。
表4显示了3纳秒时钟周期约束下布局布线后的不同设计度量指标,包含了矩阵阵列映射到BRAM或分布式RAM的情况和未映射的情况。您从表4中可以看到,矩阵映射到单端口BRAM时,设计无法满足3纳秒的时序约束。表中专门包含了这个结果,说明您可用这种方法生成具有不同面积—时序参数的各种设计。此外,您也可从表1看出,虽然图2中代码的时延为69个时钟周期,低于图4中调整后的代码的设计方案,但这种设计需要矩阵乘法实体以外的存储器,这一点我们在上面已经解释过了。
实现方案的精度
就这里显示的结果而言,我将“data”这种数据类型定义为16位宽。因此,所有矩阵元素(左、右和积矩阵)都为16位宽。矩阵乘法和加法运算不能实现全精度。您可选择在头文件中定义另一种32位宽的数据类型data_t1,积矩阵的所有元素都采用这种数据类型,因为16位数(左侧矩阵元素)乘以另一个16位数(右侧矩阵元素)最多得到32位宽。这样,资源利用率和时序结果将不同于表1和表4中的结果。
调整后的源代码显示出同样的源文件会带来多种不同设计解决方案。在本例中,一个设计解决方案采用BRAM,而另一个没有采用。在每个Vivado HLS工程目录中,您会看到Vivado HLS为不同的解决方案生成了不同的目录。在每个解决方案目录中都有一个名叫impl(也就是implementation,实现方案)的子目录。在这个子目录中,您会看到名为Verilog或VHDL的目录,具体取决于RTL实现阶段使用什么样的源代码。这个子目录中也包含赛灵思ISE工程文件(文件扩展名为.xise)。如果Vivado HLS生成的设计是您的顶层设计,那么您可以双击这个文件来启动赛灵思ISE运行这个解决方案,并生成用于门级时序和功能仿真的布局布线后模型。但您在Vivado HLS中不能做这种仿真。
在ISE中启动解决方案后,您应给设计分配I/O引脚。随后您可在ISE Project Navigator中选择“Generating Programming File”以生成比特流。
在这一练习中,我们一步步完成了Vivado HLS一个实际的端对端流程,并在FPGA上实现算法。对于Vivado HLS中的许多高级特性而言,您应了解您需要什么样的硬件架构,从而进行源代码的调整。如需了解更多详情,《Vivado高层次综合教程》(UG871; )和《Vivado设计套件用户指南》(UG002; )这两个技术文档对您大有裨益。











 工商网监
工商网监
评论