 电子发烧友App
电子发烧友App


虽然FPGA一直在数十亿美元的小众市场行走,在整个千亿元级IC大盘中只占据一隅,但并不妨碍它的追逐之梦,而AI、自动驾驶、5G等浪潮兴起为它的梦想插上了翅膀。就像1984年发明FPGA成为开创者一样,赛灵思 ACAP(自适应计算加速平台)首款产品系列Versal 的正式面世,使FPGA完成了从器件到平台的蝶变,也因而赛灵思将直面英特尔、英伟达的竞争,面对规模高出数倍乃至数十倍的竞争对手,Versal能否让赛灵思开启涅槃之旅。
一直在与自己赛跑的FPGA独行侠——赛灵思(Xilinx),在其2018开发者大会(XDF)上重磅发布了业界7nm自适应计算加速平台 (ACAP)首款产品——Versal。赛灵思总裁及CEO Victor Peng在解释Versal名称意义时说,Versal寓意Versatile (多样化的)+ Universal(通用的), 代表集多样性和通用性一体,是一款可面向所有应用、面向所有开发者的平台级产品。而Versal的面世表明赛灵思已不再是单纯的FPGA公司,而转变成平台公司。这也意味着赛灵思将不再囿于FPGA做文章,而将染指CPU、GPU等占领的市场,直面与英特尔、英伟达的竞争,Versal凭何给予赛灵思这样的勇气?
为何开发ACAP平台?
或许这是大势使然。
“随着摩尔定律的放缓以及大数据、AI、5G、自动驾驶等的发展,对于计算能力和带宽提出了前所未有的要求,同时新的算法新的框架层出不穷,要应对这一变化就需要灵活应变的架构,而传统芯片设计的周期已经无法跟上创新的步伐。” Victor Peng强调,“就像自然界的适者生存一样,在数字世界灵活应变的系统才是最可持续的。”
而这一灵活应变的架构就是异构计算。赛灵思产品及技术营销高级技术总监Kirk Saban认为,一种架构已无法独自完成大量的数据处理,需要异构计算。而从过去多年IC发展来看,计算引擎CPU单纯采用“工艺缩放scaling”技术发展的道路遇到了很大的挑战,难以通过等量的计算提升换取等量的性能提升,迫使计算引擎变成并行趋势。
为此,赛灵思启动代号为“Evest(珠穆朗玛)”的计划,意在打造一个具有灵活应变能力的自适应异构计算加速平台,支持所有类型的开发者通过优化的软硬件来为应用加速,同时具备灵活的应变能力,Victor Peng笑言Versal是在业界需求最迫切的时刻雪中送炭。
当然Versal要具备上述“魔力”,赛灵思也投入巨大,数十亿美元、上千名工程师、历时 4 年终才出手。 赛灵思软件及IP产品执行副总裁Salil Raje 对此表示,在开发过程中,Versal要解决诸多挑战,不只是硬件如处理器、AI引擎、收发器等整合,还有软件、7纳米FinFET工艺等,是一个非常大的系统工程。赛灵思花了几千小时的人工来确保软件工具的简单易用,对所有架构进行了重新布置,确保这一平台能够自上而下的软件可编程,也进一步提升了准入门槛。
而在这一过程中,FPGA从最初的逻辑门到SoC、MPSoC、RFSoC芯片再进化到ACAP,如在28纳米时集成了编解码处理器,在16纳米级别加入了GPU之后,完成了从FPGA器件到平台ACAP的蝶变,也将开启赛灵思的新征程。
Versal的功力
被寄与厚望的Versal平台究竟有何“功力”担当重任?
先来看其硬件。赛灵思产品及技术营销高级技术总监Kirk Saban指出,异构计算平台必须要有多个不同类型的处理引擎,以应对不同的工作负载。Versal平台整合了三种类型的可编程处理器即标量引擎双Arm Cortex-A72和Cortex-R5处理器、自适应引擎PL、智能引擎即AI引擎和DSP引擎,以及前沿的存储器、高速收发器和多种接口技术等。
这些引擎形成一个紧密集成的异构计算平台,并且各司其职。Kirk Saban介绍,Arm处理器通常用于控制应用、操作系统、通信接口等;PL执行数据操作和传输、非基于向量的计算和连接;AI引擎为基于向量的算法提供了高达五倍的计算密度。同时,这一切与片上网络 (NoC) 连通,提供对所有三种处理单元类型的存储器映射访问,从而比任何一种单独架构都支持更高的定制和性能提升。
值得一提的是,赛灵思独创的AI引擎是一种新型硬件模块,包括用于定点和浮点运算的向量处理器、标量处理器、专用程序和数据存储器、专用AXI 数据移动通道以及 DMA 和锁止。它针对计算和DSP进行了优化,可满足高吞吐量和高性能计算要求。相对于业界领先的GPU,AI 推断性能预计能提升3-8倍,功耗降低 50%。
在软件层面,Kirk Saban提到,Versal平台引入革新性的软件堆栈即NoC平台管理控制器,提供了无缝连接的功能,可直接通过软件进行编程和配置。同时,符合业界标准设计流程的一系列工具、软件、库、IP等助力,使得Versal ACAP 的硬件和软件均可由开发者进行编程和优化,而这在赛灵思的历史上也是绝无仅有的。
由此,硬件和软件的共同创新成就了Versal ACAP 这一颠覆性的异构计算平台,实现了显著的性能提升。Kirk Saban举出了具体数字,其速度超过当前最高速的FPGA 20倍、比当今最快的CPU快100倍,同时可实现低于2ms的时延,相信数据中心、有线网络、5G无线和ADAS等应用将乐见其成。
据悉,Versal平台组合包括Versal基础系列(Versal Prime)、Versal旗舰系列(Versal Premium)和HBM系列,提供不同的性能、连接性、带宽和集成功能。此外,还包括Versal AI系列,包括AI核心(AI Core)系列、AI边缘系列和AI射频系列。Versal Prime 系列和AI Core 系列将于2019年下半年上市。前者具广泛的适用性,用于在线加速和各种工作负载;后者提供高计算性能和最低时延,实现突破性的 AI 推断吞吐量和性能。
同时,赛灵思还公布了发展路线图,2020年将推出Premium和AI边缘系列,下半年将上市AI射频系列,而HBM将于2021年下半年面世。
其他架构自求多福?
Versal横空出世,其它选手如CPU、ASIC等如何应对?
毕竟它们各有“苦衷”。Kirk Saban认为,标量处理单元(例如 CPU)在具有不同决策树和广泛库的复杂算法中非常有效,但在性能扩展方面受到限制。而在先进制程后摩尔定律已经不再有效,CPU已无法适应最先进的应用了。
而矢量处理单元(如GPU)在并行计算上效率更高,但由于存储器层级结构不灵活,它们会受时延和效率的影响。它们可能在某一个功能领域的加速性能不错,但灵活度不够,无法适应创新的速度。
并且,通用AI芯片不是正确的方向。Kirk Saban分析说,ASIC针对某个CNN、DNN来优化形成固定功能,一旦有新的算法或者框架就需要重新设计,在目前发展态势下对于变量少的行业ASIC相对适用,如果变化快ASIC很快就会过时,实际上连谷歌的TPU也概莫能外。
虽然GPU等有着相对完善的生态系统,但Versal作为新兴势力,在生态的构建上也在大张旗鼓,一方面Versal可软硬件编辑,开发便利;另一方面,在着力与合作伙伴一起互惠共赢。 “Versal不会取代所有的GPU,但肯定会有越来越多的应用采用灵活应变的平台。”这是Victor Peng的判断也是寄望。
为何着重AI推断?
需要指出的是,Versal看重的是AI推断市场。
Salil Raje指出,AI有训练和推断两大阶段。对于训练来说海量数据非常重要,但延迟和功耗都不那么重要。而无论是在边缘端还是云端的推断,数据量很少,实时响应的性能非常重要,对延迟要求极高,而且对功耗也极为看重。
“AI训练和推断的要求是不一的,不能把训练的解决方案直接应用到推断上。在过去几年,全球关注的主要是AI训练,这是因为众多新的AI应用需要应用AI模型,但今后AI模型将大量应用在云端和边缘端,因而未来的模式更多的是AI推断,而不是训练。”
由此亦带来了新的挑战。Salil Raje指出,挑战在于一是AI创新的速度,就像要追随移动的靶子一样。二是需要低时延、高带宽和高性能,最大的挑战是功耗。三是要实现整体的应用加速,而不仅是机器学习的加速。
当然,AI训练也是非常重要的市场。Salil Raje表示,赛灵思也在研发训练用FPGA方案,不排除进入这一市场的可能性。
中国AI初创企业不应热衷于造芯
Versal平台染指AI应用,也预示着赛灵思要直面国内火爆的AI造芯厂商的竞争,对于这一点,赛灵思也有自己的见解。
“中国有大量AI初创企业,也有很多厂商在投入造芯,但赛灵思认为他们其实不一定要热衷于造芯。因为设计AI芯片目前要采用16纳米甚至7纳米的工艺,所需的投入是巨大的,风险也很大。” Victor Peng提出了建议,“其实他们可在算法和框架方面深入研究,从这些层面来创造更多的价值;或者采用Versal平台开发具体应用,而不是投资几亿元去做芯片。”
“就像深鉴科技,两年前就基于赛灵思产品做AI方面的开发,因此在被收购后其成果可迅速应用到Versal平台上,深鉴科技最为核心的就是DPU及神经网络压缩编译技术,应用此技术的Versal平台可适应不同精度不同位宽,并且时延大幅降低。”Salil Raje提及。
而对于华为、阿里都在打造属于自有AI芯片的情形,Victor Peng表示,这表明目前正处于AI革命的早期,大家都在寻找不同的解决方案,这带来了众多机遇。可能有一些领域是适用于固定功能的芯片,但绝大多数应用还将使用灵活平台作为解决方案。
为何还要推出加速器卡?
除了打造Versal平台之外,赛灵思也意识到在云端和数据中心的服务器中,FPGA作为一种服务即FaaS的部署正在加快。Victor Peng介绍说,FaaS最初是从亚马逊开始部署,现已有8个国家在采用,今年赛灵思已培训超过14000名的开发者,实现了36个应用。在XDF大会上,亚马逊就面向中国开发者宣布AWS F1覆盖区域数量翻番,并正式落地中国。
与之相呼应的是,据分析,全球加速器卡的市场将达到120亿美元,而中国市场占据半壁江山。
为此,赛灵思还推出了功能强大的加速器卡——Alveo,它的优势在于客户可对硬件进行重配置,针对工作负载、新标准和新算法进行调整和优化,并且更加易用,同时性能更加出色。
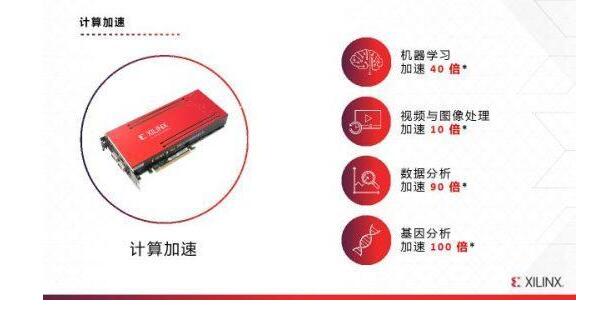
就机器学习而言,Alveo U250实时推断吞吐量比高端 CPU高出20 倍,相对于高端GPU等,能让2毫秒以下的低时延应用性能提升4倍以上,堪称全球最快的数据中心加速卡。
而且,目前Alveo得到了合作伙伴和 OEM 厂商生态系统的广泛支持,有14 家合作伙伴开发完成的应用可立即投入部署,国内如华为、阿里云、浪潮等都已在合作,推出基于赛灵思的加速方案。此外,部分OEM芯片厂商将和赛灵思进入更深入合作,认证采用Alveo加速器卡的多个服务器SKU,包括Dell EMC、Fujitsu和IBM等。这些关键应用涵盖AI/ML、视频转码、数据分析、金融风险建模、安全和基因组学等。
阿里云FPGA异构计算研发总监张振祥宣称,阿里集团采用Faas提升发效率,节省了成本,阿里集团X项目每千片FPGA三年节约TCO成本40%。华为IT智能计算产品线副总裁张小华也提到,华为云与赛灵思紧密合作,实现了线上线下协同的FPGA加速解决方案,以视频编解码为例,在在线视频广播业务场景下可节约40%的带宽和存储空间,为客户带来了极大的价值。














 工商网监
工商网监
评论