 电子发烧友App
电子发烧友App


要想深入理解Verilog就必须正视Verilog语言同时具备硬件特性和软件特性。在当下的教学过程中,教师和教材都过于强调Verilog语言的硬件特性和可综合特性。将Verilog语言的行为级语法只作为语法设定来介绍,忽略了Verilog语言的软件特性和仿真特性。使得初学者无法理解Verilog语言在行为级语法(过程块、赋值和延迟)背后隐藏的设计思想。本文尝试从仿真器的角度对Verilog语言的语法规则进行一番解读。
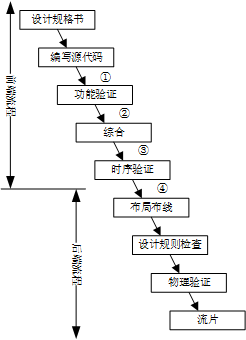
“精分”的Verilog语言 在集成电路的设计流程中,Verilog源文件有两个主要作用:综合和仿真。在图1中,数字①②③④标注的位置都可以使用Verilog作为设计的描述方法。- 综合工具读入源文件,通过综合算法将设计转化为网表,比如DC。能够综合的特性要求Verilog语言能够描述信号的各种状态(0,1,x,z)、信号和模块的连接(例化)以及模块的逻辑(赋值以及各种运算符)。
- 仿真器读入源文件,生成一个可执行程序用于仿真硬件的行为,比如VCS。能够仿真的特性要求Verilog语言又具有软件特性,对每一条语句的执行语义和顺序给出定义(延迟语句)。同时,软件特性使得Verilog语言更加灵活,具备了丰富的行为级仿真能力(条件分支、循环等)。
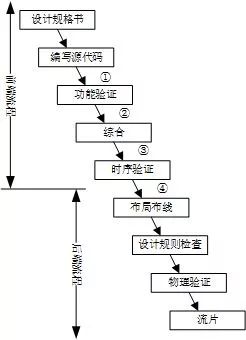 图1. 集成电路设计流程为了满足综合和仿真的双重要求,Verilog语言的语法规则必须要同时满足硬件和软件的特质。编写Verilog代码的时候,不仅需要从硬件的角度去思考这一段代码会转换为什么样的硬件电路,还要从软件的角度去思考这一段代码在仿真器如何表现。如此日复一日,隐隐有精神分裂之感。Verilog代码与硬件电路的关系已经在大量的书籍中得到了充分的论述。本文重点聊一聊从软件的角度如何理解Verilog。从软件的角度理解Verilog并不是要把Verilog看成一种可执行程序,试图去理解每一条语句对应的语义。如果这样做,就陷入更深的误区而不能自拔。很多的语句规则和规定也会变得混乱而不可理解。在试图从软件角度理解Verilog语言之前,必须要坚定Verilog是一种硬件描述语言的观点。从软件的角度理解Verilog的本质是理解Verilog语言在软件仿真器中的行为。Verilog语言本身是不能执行的。实际上,Verilog提供了一套描述硬件电路行为的规范。这套规范的设计与仿真器的设计是相互适应的。仿真器根据Verilog文件产生一个可执行的仿真程序。这个仿真程序才是真正的软件程序。在目前的教学过程中,Verilog的硬件特性得到了充分的强调。在开始学习Verilog的第一天,很多同学就会被老师们教育:Verilog描述的是硬件,Verilog不是软件。这般强调的目标是为了避免大家将Verilog语言与纯粹的软件语言(C,java,python等)混为一谈。但是同时也有些矫枉过正。对于Verilog的软件特性只介绍是什么而不介绍为什么,而且几乎不涉及仿真器的内容。在讲授Verilog语言的时候,也只能含糊地从语义的角度介绍Verilog的各种语法规则。不论是数字电路、集成电路设计等课程都不会给学生介绍仿真器的基本结构和运行机制。此外,国内长期不重视电子设计自动化(EDA)工具的研究,不重视设计方法学和设计流程的探索和演进,习惯拿来主义。最终导致我国严重缺乏EDA专业相关人才储备。任课教师普遍对工具背后的软件机制不清楚,也只有避免讲Verilog的软件属性,才能避免课堂上的尴尬。在这样的教学方式下,学生很难对Verilog语言甚至HDL语言建立起正确的理解和知识体系。
图1. 集成电路设计流程为了满足综合和仿真的双重要求,Verilog语言的语法规则必须要同时满足硬件和软件的特质。编写Verilog代码的时候,不仅需要从硬件的角度去思考这一段代码会转换为什么样的硬件电路,还要从软件的角度去思考这一段代码在仿真器如何表现。如此日复一日,隐隐有精神分裂之感。Verilog代码与硬件电路的关系已经在大量的书籍中得到了充分的论述。本文重点聊一聊从软件的角度如何理解Verilog。从软件的角度理解Verilog并不是要把Verilog看成一种可执行程序,试图去理解每一条语句对应的语义。如果这样做,就陷入更深的误区而不能自拔。很多的语句规则和规定也会变得混乱而不可理解。在试图从软件角度理解Verilog语言之前,必须要坚定Verilog是一种硬件描述语言的观点。从软件的角度理解Verilog的本质是理解Verilog语言在软件仿真器中的行为。Verilog语言本身是不能执行的。实际上,Verilog提供了一套描述硬件电路行为的规范。这套规范的设计与仿真器的设计是相互适应的。仿真器根据Verilog文件产生一个可执行的仿真程序。这个仿真程序才是真正的软件程序。在目前的教学过程中,Verilog的硬件特性得到了充分的强调。在开始学习Verilog的第一天,很多同学就会被老师们教育:Verilog描述的是硬件,Verilog不是软件。这般强调的目标是为了避免大家将Verilog语言与纯粹的软件语言(C,java,python等)混为一谈。但是同时也有些矫枉过正。对于Verilog的软件特性只介绍是什么而不介绍为什么,而且几乎不涉及仿真器的内容。在讲授Verilog语言的时候,也只能含糊地从语义的角度介绍Verilog的各种语法规则。不论是数字电路、集成电路设计等课程都不会给学生介绍仿真器的基本结构和运行机制。此外,国内长期不重视电子设计自动化(EDA)工具的研究,不重视设计方法学和设计流程的探索和演进,习惯拿来主义。最终导致我国严重缺乏EDA专业相关人才储备。任课教师普遍对工具背后的软件机制不清楚,也只有避免讲Verilog的软件属性,才能避免课堂上的尴尬。在这样的教学方式下,学生很难对Verilog语言甚至HDL语言建立起正确的理解和知识体系。仿真器基本架构
Verilog语言确实不是一种可执行语言。图2展示了利用Verilog源文件进行仿真的过程。绝大多数仿真器都遵循这一思路,比如VCS、iVerilog、ModelSim、Vivado和Quartus等。首先,准备Verilog源文件以及一些Verilog库文件(标准单元等)。仿真器接收这些Verilog文件并将其转化为可执行的仿真源文件(C/C++等)。在这一过程中,仿真器解析Verilog文件的语法结构,并且根据Verilog语法的规范,将语法结构转化为仿真器中的事件响应函数或代码段。这些函数和代码段与仿真器框架源文件一起成为可执行仿真程序的源文件。接下类这些源文件经过编译得到可执行的仿真程序。VCS和iVerilog可以看到生成的可执行文件。ModelSim、Vivado和Quartus使用GUI管理设计流程,从而将这个可执行文件屏蔽了,使其对于用户可透明。用户可以在工程中找到生成的可执行文件。最后,运行可执行的仿真程序,进行软件仿真。
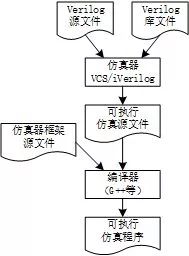 图2 从Verilog源文件到可执行仿真程序的流程
图2 从Verilog源文件到可执行仿真程序的流程可执行仿真源文件和仿真器框架源文件一般是不可见的。不过在开源软件(例如iVerilog)中可以找到生成可执行仿真源文件的代码。仿真程序通常采用基于事件的仿真架构。这种仿真架构的核心是事件队列。事件队列中按照事件的响应时间排列着一系列的事件。响应时间相同的事件之间不应该有决定性的事件依赖关系。如果需要确定这些事件之间的顺序,可以引入Δ时间。响应时间为t+Δ的事件必然晚于响应时间为t的事件。但是从仿真时间上,仍然表现为在相同时刻响应。事件队列按照时间先后顺序逐个响应事件队列中的事件。每一个事件,除了标注事件响应时间,还会标注事件类型以及其他需要的参数。通过事件类型,仿真引擎可以找到对应的响应函数。其他的参数则作为事件响应函数的输入参数。事件响应函数会产生新的事件。这些新的事件还会插入到事件队列中,并且按照其响应时间排序。
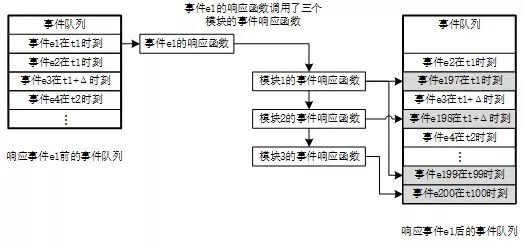 图3 事件队列仿真框架的示意图图3展示仿真引擎响应一个事件的过程。仿真引擎响应事件队列中的第一个事件e1。事件e1被从队列中移除。事件队列从事件e2开始。仿真引擎根据e1的类型找到了事件响应函数。这个响应函数又调用了3个模块中的事件响应函数。这些事件响应函数模拟硬件电路的行为,并且产生了新的事件。模块1产生了事件e197和e199,分别插入到t1时刻和t99时刻;模块2产生了事件e198,插入t1+Δ时刻;模块3产生了事件e200,插入t100时刻。通过“读出第一个事件-响应事件-插入新事件”的循环,事件队列可以一直运行下去,直到事件队列为空或者达到了仿真结束的时间。另一方面,在仿真开始的时候,必须向事件队列中插入起始事件,从而开始仿真循环。Verilog仿真器提供了仿真引擎(在图2中的仿真器框架源文件部分),所以大家在写Verilog的时候不用去自己“造轮子”。但是仿真引擎并不知道事件和响应函数的对应关系以及响应函数的具体功能。仿真器的工作就是将Verilog文件转化为仿真响应函数并且与仿真引擎进行连接。生成的可执行仿真源文件和仿真器框架文件一起构成了完整的仿真器。接下来,分析一下Verilog的语法结构(过程块、赋值和延迟)如何变成仿真器的源文件。
图3 事件队列仿真框架的示意图图3展示仿真引擎响应一个事件的过程。仿真引擎响应事件队列中的第一个事件e1。事件e1被从队列中移除。事件队列从事件e2开始。仿真引擎根据e1的类型找到了事件响应函数。这个响应函数又调用了3个模块中的事件响应函数。这些事件响应函数模拟硬件电路的行为,并且产生了新的事件。模块1产生了事件e197和e199,分别插入到t1时刻和t99时刻;模块2产生了事件e198,插入t1+Δ时刻;模块3产生了事件e200,插入t100时刻。通过“读出第一个事件-响应事件-插入新事件”的循环,事件队列可以一直运行下去,直到事件队列为空或者达到了仿真结束的时间。另一方面,在仿真开始的时候,必须向事件队列中插入起始事件,从而开始仿真循环。Verilog仿真器提供了仿真引擎(在图2中的仿真器框架源文件部分),所以大家在写Verilog的时候不用去自己“造轮子”。但是仿真引擎并不知道事件和响应函数的对应关系以及响应函数的具体功能。仿真器的工作就是将Verilog文件转化为仿真响应函数并且与仿真引擎进行连接。生成的可执行仿真源文件和仿真器框架文件一起构成了完整的仿真器。接下来,分析一下Verilog的语法结构(过程块、赋值和延迟)如何变成仿真器的源文件。
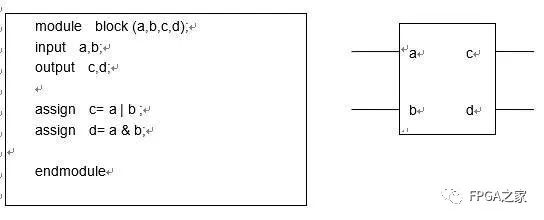
always @ (posedge clk) begin
q <= d;
end
经过仿真器的转换就变成为如下的响应函数:
function always_block1 :
q = d;
赋值语句
Verilog语言提供了阻塞赋值和非阻塞赋值两种赋值语句。
a = b; // 阻塞赋值
a <= b; // 非阻塞赋值
always @(a, b, c) begin : add_mux1
t = a + b;
d = t * c;
end
上述代码转化后的事件响应函数为
function add_mux1 :
t = a + b;
d = t * c;
always @(a, b, c) begin : add_mux2
t <= a + b;
d <= t * c;
end
上述代码转化后的事件响应函数为
function add_mux2 :
t_update = a + b;
d_update = t * c;
t = t_update;
d = d_update;
当阻塞赋值和非阻塞赋值混合的时候,也遵循同样的规则。例如
always @(a, b, c) begin : add_mux3
t <= a + b;
d = t * c;
end
上述代码转化后的事件响应函数为
function add_mux3 :
t_update = a + b;
d = t * c;
t = t_update;
延迟行为Verilog语言的延迟语句虽然不能综合,但是在仿真过程中应用得很多。延迟语句可以用在testbench中构建时钟信号和激励,也可以用在Verilog模块中模拟实际电路的延迟。延迟语句可以出现在两条赋值语句之间,也可以出现一条赋值语句中间。
#3 a = b; //延迟语句在赋值语句之间
a = #3 b; //延迟语句在赋值语句内部
always @(a, b, c) begin : add_mux4
t <= a + b;
#1 d = t * c;
end
上述代码转化后的事件响应函数为
function add_mux4_1 :
t_update = a + b;
t = t_update;
addEvent( curr_time + 1, add_mux4_2 );
function add_mux4_2 :
d = t * c;
Verilog文件中的1个过程块被转换为两个函数。第一个函数add_mux4_1对应于延迟语句之前的部分,第二个函数add_mux4_2对应于延迟语句之后的部分。
add_event是本文定义的一个原语,表示向事件队列中添加一个事件。第一个参数表示事件响应的时间,第二个参数表示响应事件需要调用的事件响应函数。从第三个参数开始,之后的参数会作为事件响应函数的参数,传递给事件响应函数。
add_event( curr_time + 1, add_mux4_2 )表示在当前时间(curr_time)后1个时间单位的时候响应这个事件。事件需要调用add_mux4_2函数。响应函数不需要额外的参数。在调用add_mux4_2时,信号t已经完成更新。
在赋值语句中间的延迟语句将评估和更新阶段分割到两个时刻进行。评估过程仍然在语句执行的时候进行,但是更新过程延后到延迟语句指定的时刻进行。延迟语句是否阻塞过程块的执行,取决于赋值语句本身。如果是阻塞赋值语句,赋值语句中间的延迟语句会阻塞过程块的执行;如果是非阻塞赋值,延迟语句不会阻塞过程块的执行。例如
always @(a, b, c) begin : add_mux5
t <= #1 a + b;
d = #2 t * c;
end
上述代码转化后的事件响应函数为
function add_mux5_1:
t_update = a + b; // 1
d_update = t * c; // 2
addEvent( curr_time + 1, update_t, t_update );
addEvent( curr_time + 2, add_mux5_2, d_update );
function update_t( t_update ) :
t = t_update; // 3
function add_mux5_2( d_update ) :
d = d_update; // 4
update_t。t_update作为事件响应函数的参数,在update_t中更新给信号t。由于第二个语句中的延迟语句,过程块被打断为两个部分,第二个函数需要在当前时刻之后2个时间单位时执行,即add_mux5_2。add_mux5_2需要使用d_update作为参数。理解到这一层,就可以处理更加复杂的波形了。例如下面这一段代码。module test;
reg x,y,z;
assign #25 a = 1;
always begin
#20;
x = #10 a;
#3 y = a;
#3 z = a;
#7;
end
endmodule
经过仿真器的转换,上面的Verilog语句会形成如下的事件响应函数。
function assign1 :
a = 1;
function always1_1 :
addEvent( curr_time + 20, always1_2 );
function always1_2 :
x_update = a;
addEvent( curr_time + 10, always1_3, x_update );
function always1_3( x_update ) :
x = x_update;
addEvent( curr_time + 3, always1_4 );
function always1_4 :
y = a;
addEvent( curr_time + 3, always1_5 );
function always1_5 :
z = a;
addEvent( curr_time + 7, always1_6 );
function always1_6 :
addEvent( curr_time + delta, always1_1 );
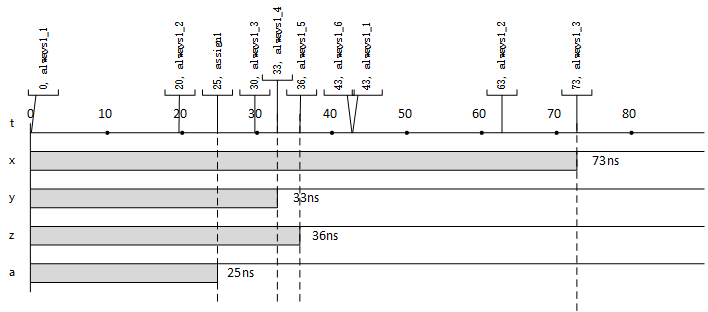
在仿真开始时候,首先向事件队列中添加两个事件,分别是在0+25时刻调用assign1,以及在0+0时刻调用always1_1。事件响应过程如图4所示。always过程块被延迟语句分割成了6个响应函数。每个部分都向事件队列添加能够触发下一个响应函数的事件。信号x的第1次评估发生在20时刻,而第1次更新发生在30时刻,所以信号x的第一次赋值仍为X。直到第2次评估时(63时刻)才能获得有效的信号1,并且在73时刻更新给信号x。
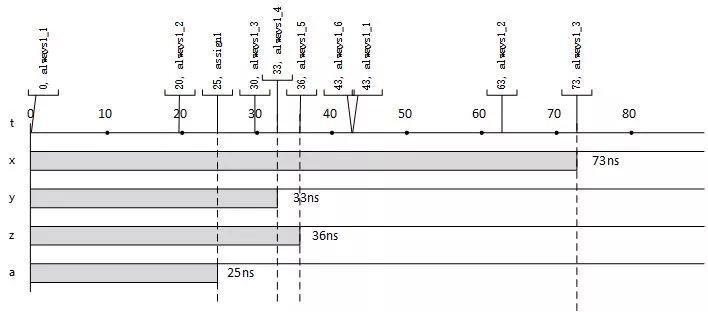 图4 示例过程的事件队列响应过程和波形图
图4 示例过程的事件队列响应过程和波形图需要说明的是,虽然本文提供了一种思路能够比较轻松地理解行为级描述的执行过程,但是仍然不建议大家在过程块中混用阻塞赋值和非阻塞赋值。混用赋值语句是危险的。
Assign赋值
前面介绍的侧重于过程块。对于Assign赋值语句,原理其实是也一样的。例如
assign a = #5 b & c;
这条assign语句同样可以看做一个事件响应函数。这个函数绑定的事件是信号b或信号c发生变化。延迟语句的效果也是一样的。延迟语句将评估和更新过程分开。当信号b或信号c发生变化时进行评估,并在事件队列中添加一个新的更新事件。5个时间单位之后,响应更新事件,将评估的值更新给信号a。
转换后的事件响应函数如下。
function assign1:
a_update = b & c;
addEvent( curr_time + 5, update_a, a_update );
function update_a( a_update ) :
a = a_update;
调试
Verilog仿真器普遍提供了Verilog代码的调试能力,比如断点和单步运行。在VCS、ModelSim、Vivado和Quartus中都能找到调试模式。断点和单步运行是典型的软件调试手段,是软件工程师的看家本领。但是对于硬件来说,断点和单步运行却是不可理解的,因为硬件是并行的。如果将断点理解为硬件电路在某一个时刻的状态,那么此时应该有多条语句被同时中断。硬件电路不会像软件一样在某个函数中中断并且单步执行,而且其他过程块或语句毫无影响。 前面已经介绍过,Verilog并不是可执行语言。真正的可执行仿真程序是由仿真器提供的仿真框架源代码和由Verilog语言转换而来的仿真程序源代码构成的。实际上,Verilog语言调试的断点并不是添加给硬件的或者Verilog源文件的,而是添加到可执行仿真程序中对应的事件响应函数的。单步调试的对象也是可执行仿真程序中的事件响应函数。所以,Verilog代码可以引入断点和单步调试。 在进一步解释Verilog调试器的机制之前,必须先解释一下软件调试器是如何调试程序的。为了使得可执行文件可调试,编译器会在可执行程序中添加调试信息。以C语言为例,编译器会在可执行文件中添加调试信息(如图5所示)。添加的位置是在对应于C语言语句的汇编代码段起始的位置。在进行软件调试的时候,软件调试器会在有调试信息的地方暂停(比如0x4005a5)。进行单步调试的时候,每一步也都是停在C语言语句开始的地方(比如0x4005bf)。
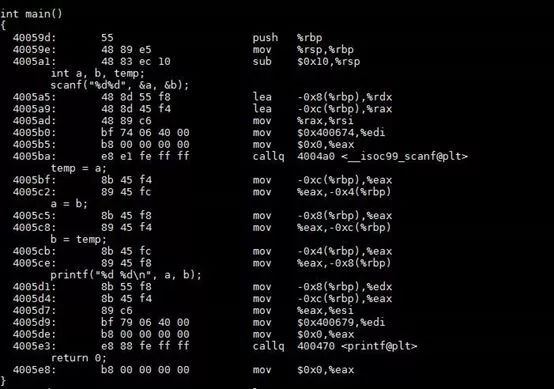 图5 可调试程序中添加的调试信息(利用objdump命令得到)
Verilog调试器的作用就是将可执行仿真程序和Verilog语言对应起来。一种思路是将编译器插入的调试信息与Verilog语言对应起来。编译器插入的调试信息是对应于可执行的仿真源文件,而这些源文件是由仿真器生成的。所以Verilog调试器可以获得调试信息与Verilog语句的对应关系。另一种思路是通过编译器直接给可执行仿真程序添加与Verilog语言对应的调试信息。这样Verilog调试器从可执行程序就可以获得必要的信息,而不需要额外的消息来源。
Verilog调试器只能对可以与Verilog语言对应的代码部分添加断点,也就是只能对事件响应函数添加断点。Verilog调试器不能调试由仿真器提供的仿真框架源代码。当单步调试遇到always块结束或者assign语句之后,调试器不会进入仿真引擎,而是直接跳转到下一个事件响应函数。此外,Verilog调试器还限制了断点和单步调试的粒度只能以Verilog语句为单位,而不能进一步缩小粒度到可执行仿真程序的语句甚至汇编层面。
图5 可调试程序中添加的调试信息(利用objdump命令得到)
Verilog调试器的作用就是将可执行仿真程序和Verilog语言对应起来。一种思路是将编译器插入的调试信息与Verilog语言对应起来。编译器插入的调试信息是对应于可执行的仿真源文件,而这些源文件是由仿真器生成的。所以Verilog调试器可以获得调试信息与Verilog语句的对应关系。另一种思路是通过编译器直接给可执行仿真程序添加与Verilog语言对应的调试信息。这样Verilog调试器从可执行程序就可以获得必要的信息,而不需要额外的消息来源。
Verilog调试器只能对可以与Verilog语言对应的代码部分添加断点,也就是只能对事件响应函数添加断点。Verilog调试器不能调试由仿真器提供的仿真框架源代码。当单步调试遇到always块结束或者assign语句之后,调试器不会进入仿真引擎,而是直接跳转到下一个事件响应函数。此外,Verilog调试器还限制了断点和单步调试的粒度只能以Verilog语句为单位,而不能进一步缩小粒度到可执行仿真程序的语句甚至汇编层面。
 图6 Verilog程序加断点的过程
以图6中的Verilog程序为例,经过Verilog仿真器得到右边所示的仿真源文件,再经过编译得到可执行程序。在左边Verilog程序中的一行设置了一个断点(图5中左边第7行),这个断点实际上是设置在右边的可执行程序的事件响应函数always1_4中的(图5中右边第2行)。每当仿真程序运行到always1_4时就触发中断,暂停程序执行。通过仿真器添加的调试提示信息,调试器能够知道中断的位置是Verilog语言的第7行,从而在图形界面上显示。
从断点的位置开始单步调试。从可执行仿真程序的层面来说应该在第3行暂停,并且呈现第3行执行后状态。但是,Verilog调试器会过滤仿真框架的程序,也就是过滤掉无法对应到Verilog程序的语句。所以,可执行程序不会在第3行之后暂停,而是继续执行。第3行结束后,程序从事件响应函数返回,进入仿真框架的部分。仿真器框架的代码也会被调试器忽略,直到仿真程序进入下一个事件响应函数。最终,程序进入always1_5。调试器会在第6行暂停,并且将中断的位置对应到Verilog软件的第8行。程序运行的标志会显示在图6中第8行的位置。
以上的过程对于用户来说都是不可见的。从用户的角度看来,只能看到程序指针从第7行跳到第8行,并且第7行语句的效果在波形图上展现了出来。这就是Verilog语言调试背后隐藏的过程,其核心仍然是软件调试。
图6 Verilog程序加断点的过程
以图6中的Verilog程序为例,经过Verilog仿真器得到右边所示的仿真源文件,再经过编译得到可执行程序。在左边Verilog程序中的一行设置了一个断点(图5中左边第7行),这个断点实际上是设置在右边的可执行程序的事件响应函数always1_4中的(图5中右边第2行)。每当仿真程序运行到always1_4时就触发中断,暂停程序执行。通过仿真器添加的调试提示信息,调试器能够知道中断的位置是Verilog语言的第7行,从而在图形界面上显示。
从断点的位置开始单步调试。从可执行仿真程序的层面来说应该在第3行暂停,并且呈现第3行执行后状态。但是,Verilog调试器会过滤仿真框架的程序,也就是过滤掉无法对应到Verilog程序的语句。所以,可执行程序不会在第3行之后暂停,而是继续执行。第3行结束后,程序从事件响应函数返回,进入仿真框架的部分。仿真器框架的代码也会被调试器忽略,直到仿真程序进入下一个事件响应函数。最终,程序进入always1_5。调试器会在第6行暂停,并且将中断的位置对应到Verilog软件的第8行。程序运行的标志会显示在图6中第8行的位置。
以上的过程对于用户来说都是不可见的。从用户的角度看来,只能看到程序指针从第7行跳到第8行,并且第7行语句的效果在波形图上展现了出来。这就是Verilog语言调试背后隐藏的过程,其核心仍然是软件调试。结语
本文的初衷是提供通过仿真器理解Verilog语言的思路。文中关于Verilog仿真器的描述采用了最简单、最直接的思路,当然也是效率最低的。实际的仿真器会通过各种软件技巧进行优化,提高仿真效率。文中使用的一些概念借鉴自SystemC,比如仿真阶段和“评估-更新”机制。电路仿真器的设计思路和概念都是类似的或者相通的,可以触类旁通。 如果有读者想进一步理解Verilog仿真器,不妨看一下开源Verilog仿真器iVerilog的源码。此外,SystemC也是一套很好的硬件电路仿真框架,建议学习SystemC标准。IEEE的SystemC标准会阐述SystemC需要的仿真引擎以及编程规范。 作者才疏学浅,挂一漏万,请大家多批评指正。
作者简介
作者:王君实
电子科技大学博士。主要研究方向为片上互联结构、计算机体系结构,已在IEEE Transactions on Computers (CCF A 类期刊)等高水平期刊和CODES+ISSS、ISCAS等顶级会议上发表高水平论文10 余篇,申请专利4项。长期从事片上系统建模和模型开发工作。博士期间主导开发了多核片上系统高层次建模与设计工具ESYSim。该系列的工具获得中国研究生电子设计大赛集成电路专项赛(也就是现在的中国研究生“创芯”大赛的前身)特等奖。现从事CPU性能建模和优化工作。
审核编辑 :李倩













 工商网监
工商网监
评论