 电子发烧友App
电子发烧友App


PCI-E Switch芯片,估计不少人已经听说过这个东西了。但是估计多数人对其基本功能知之甚少。PCI-E Switch作为最先进的生产力,已经被广泛应用在了传统存储系统,以及少量品牌/型号的服务器平台。
冬瓜哥作为拥有全球最领先PCI-E Switch产品的Microsemi公司的系统架构师,想在这里为大家普及一下PCI-E Switch的基本知识。
背景介绍
PCI-E大家都了解,主板上有PCI-E槽,里面的金手指就是一堆信号线,其直接被连接到了CPU内部的PCI-E控制器上。然而,当前的Intel平台CPU每颗最大支持40个通道(Lane),一般来讲万兆网卡使用8个通道即可,高端显卡需要x16通道因为在3D运算时需要的吞吐量巨大(冬瓜哥的PC使用了老主板来配了块GTX980显卡,只能运行在x8模式上,但是3D性能基本没什么变化,证明x8基本已经足够)。一般的存储卡也使用x8,但是后端12Gb/s SAS存储卡(HBA卡、Raid卡)普遍过渡到了x16。
但是,对于一些高端产品来讲,尤其是那些传统存储系统,每颗CPU提供x40个通道就显得不够用了。传统存储系统的一个特殊要求就是后端和前端HBA数量比较大,所以CPU自带的通道数量无法满足。另外,传统存储控制器之间需要做各种数据交换和同步,一般也是用PCI-E,这又增加了对通道数量的消耗。
对于一般的高端服务器,普遍都是双路、四路配置,双路下提供x80通道,理论上可连接10个x8的PCI-E设备,去掉一些用于管理、内部嵌入式PCI-E设备的通道占用之后,连接8个设备不在话下,可以覆盖几乎所有应用场景。
但是,**随着用户对融合、统一、效率、空间、能耗要求的不断提升,近年来出现了不少高密度模块化服务器平台,或者说,开放式刀片。这类服务器平台对PCI-E方面产生了一些特殊需求,比如Partition和MR-IOV。**下面,冬瓜哥就详细展开介绍这些知识。
基本功能
1.Fanout
Fanout(扩展、扩开、散开的意思)是PCI-E switch的基本功能,或者说,PCI-E标准体系一开始就是应对通道数量不够用才设计了PCI-E Switch这个角色。
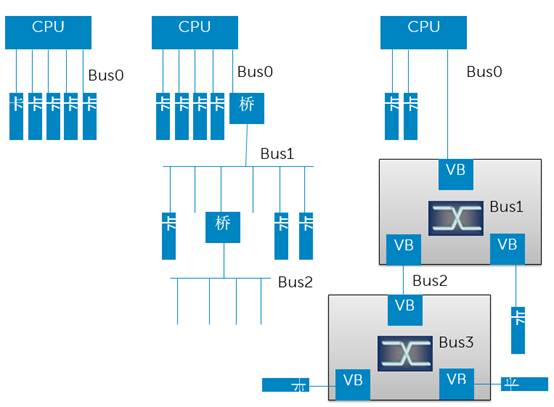
在PCI-E之前的一代标准是PCI-X,那时候并没有Switch的概念,Fanout采用的是桥接的形式,形成一个树形结构,如上图中间所示。**Switch的概念是在PCI-E时代引入的,其相对于桥最大的一个本质区别就是同一个Bus内部的多个角色之间采用的是Switch交换而不是Bus。**PCI-X时代真的是使用共享Bus传递数据,这就意味着仲裁,意味着低效率。
然而,PCI-E保留了PCI-X体系的基本概念,比如依然沿用“Bus”这个词,以及“桥/Bridge”这个词,但是这两个角色都成为了虚拟角色。一个Switch相当于一个虚拟桥+虚拟Bus的集合体,每个虚拟桥(VB)之下只能连接一个端点设备(也就是最终设备/卡,End Point/EP)或者级联另外一个Switch,而不能连接到一个Bus,因为物理Bus已经没了。这种Fanout形式依然必须遵循树形结构,因为树形结构最简单,没有环路,不需要考虑复杂路由。
2.Partition
分区功能相当于以太网Switch里的Vlan,相当于SAS Switch/Expander里的Zone。
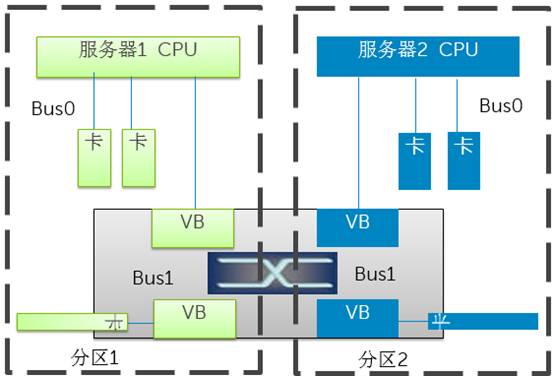
如上图所示,两台或者多台机器,可以连接到同一片PCI-E Switch,在Switch做分区配置,将某些EP设备分配给某个服务器。这样可以做到统一管理,灵活分配。每台服务器的BIOS或者OS在枚举PCI-E总线时只会发现分配给它的虚拟桥、虚拟BUS、和EP。多个分区之间互不干扰。
**多台独立服务器连接到同一片Switch上,如果不做Partition,是会出现问题的,**因为两个OS会分别枚举同一堆PCI-E总线内的角色,并为其分配访问地址,此时会出现冲突。
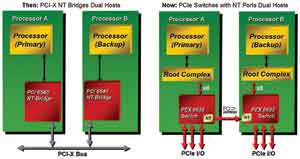
3.NTB
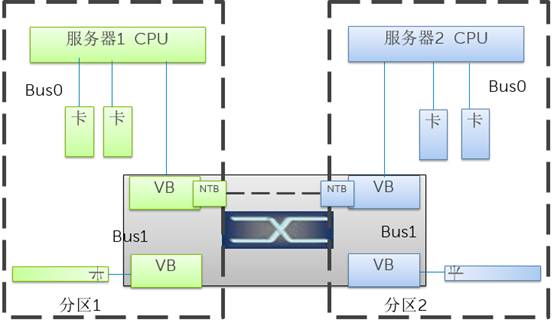
有些特殊场景下,比如传统存储系统中的多个控制器,它们之间需要同步很多数据和控制信息,希望使用PCI-E链路直接通信。问题是,图中的两台服务器并不可以直接通信,因为必须身处两个不同的分区中。为了满足这个需求,出现了NTB技术。其基本原理是地址翻译,因为两个不同的系统(术语System Image,SI)各有各的地址空间,是重叠的。那么只要在PCI-E Switch内部将对应的数据包进行地址映射翻译,便可以实现双方通信。这种带有地址翻译的桥接技术叫做None Transparent Bridge,非透明桥。
高级功能
1.Dynamic Partition
上文中的分区配置必须是静态配置,必须在BIOS启动之前,也就是CPU加电之前,对PCI-E Switch进行分区配置,可以使用BMC做配置。分区配置好之后,在系统运行期间,不能够动态改变。这就意味着,某个PCI-E卡如果被分配到了服务器A,则其不能在不影响服务器A和B的运行前提下,被动态重新分配到服务器B。
Microsemi公司Switchtec旗下的PCI-E Switch产品则支持动态分配。具体的实现手段冬瓜哥就不透露了。不过,对于内行开发者来讲,这些都不是问题,问题是对应的芯片内部的架构是否足够灵活可配置,这是限制高级功能设计的关键。
2.Fabric
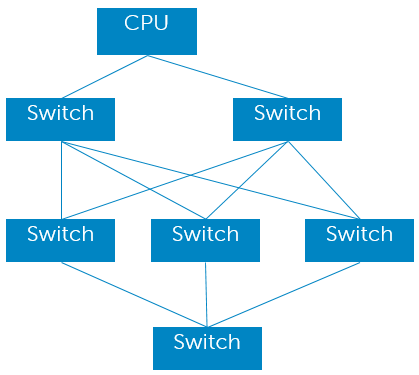
上文中说过,不管是PCI-X还是PCI-E体系标准内,只支持树形拓扑。树形拓扑的问题在于,路径过长,整个网络的直径太大。另外,无法实现冗余,一旦某个链路故障,链路后方的分支全部无法访问。
于是,**支持Fabric成了一个非常复杂的高级功能。这个场景目前还很少有人使用,对于整机架服务器比如天蝎等,其对这项功能兴趣则比较大。**然而,目前这个技术的实现还非常初级不完善,也没有形成标准。
3.IOV
SR-IOV,不少人都听说过,但却不知道里面具体的门道,Single Root IO Virtualization里的Root是什么意思?Single Root又何解?还有Multi Root IOV,这又是什么鬼?
SR-IOV,是指把插在一台服务器上的一块PCI-E卡虚拟成多块虚拟卡,给运行在这台服务器上的多个虚拟机用,每个虚拟机都识别到一个PCI-E卡,但是VM并不知道这个卡是虚拟出来的。
如果不虚拟成多块卡,多个VM怎么共享这个设备?答,必须通过Hypervisor提供的服务来使用该设备。Hypervisor会在VM内安装一个驱动程序,这个驱动会虚拟一个并不存在的设备,比如 “XXX牌以太网卡”,这个驱动会真的与OS协议栈挂接上,从而接收上层下发的数据包。但是这个驱动收到数据包之后,由于根本不存在实际的网卡,这个驱动其实是将这个包发送给了Hypervisor,或者有些虚拟机实现是使用一个domain 0特权VM来负责与真实硬件打交道,那么这个驱动会将数据发送给这个特权VM,Guest VM与特权VM之间通过进程间通信来传递数据,Hypervisor或者特权VM收到数据之后,再通过真实的驱动,比如“Intel xxx Ethernet card”将数据包发送给真实网卡。
这么一转发,就慢了,因为内存拷贝的代价比较高,吞吐量要求如果很大的话,这种方式就不行了。于是,SR-IOV出马解决了这个问题。SR-IOV需要直接在PCI-E卡的硬件里虚拟出多个子设备。如何做到?
首先,支持SR-IOV的PCI-E卡,需要向系统申请成倍的地址空间,想虚拟出几个设备,就需要按照SR-IOV的规范格式来声明相比原先几倍的地址空间。这个地址空间会在内核或者BIOS枚举PCI-E设备的时候被获取到,系统会将为该设备申请的地址空间段的基地址写入设备寄存器。比如某网卡虚拟出8个虚拟网卡来,然后由内核PCI-E管理模块向系统申报8个PCI-E设备。随后就是由Hypervisor将对应的设备映射给对应的VM,VM中加载对应的Host Driver。Hypervisor还需要执行地址翻译,或者硬件辅助的地址翻译。
只要PCI-E设备自身支持SR-IOV,PCI-E Switch不需要做任何额外处理即可原生支持。但是**MR-IOV则必须基于支持SR-IOV的板卡,加上在PCI-E switch上做额外处理才可以支持。**原因还是因为多个独立系统之间是互不沟通的,如果都尝试对PCI-E总线进行配置会冲突。PCI-E Switch针对MR-IOV的支持基本手段,还是靠增加一层地址映射管理来实现。
4. 组播(Multicast)
在传统双控或者多控存储系统中,缓存镜像是一个必须动作。缓存镜像有多种方式可以实现。第一种,某控制器将数据读入其自身内存,然后使用NTB方式将数据拷贝到对方的一个或者多个控制器内存从而实现镜像。拷贝过程可以采用programmed IO方式或者DMA方式(前提是对应的PCIE switch上提供DMA控制器)。另一种方式则是采用组播方式,底层程序员首先对整个PCIE switch域中的switch做配置,将某些端口后面的某些地址空间设置为同属于一个组播组,这样,凡是命中该组播组地址空间的写操作,均被PCIE switch广播写入到同组内的对应地址上。这种方式实现镜像的好处是不消耗任何Host端CPU资源。目前,PCIE Multicast这个功能,只有一家支持(支持Dynamic Partition的那家),并且只有Posted方式的返回数据才可以被组播。PCIE写操作都是Posted,读操作都是none posted。注意,Host读盘的过程底层其实是盘向Host主存的PCIE写事务,PCIE设备枚举过程中的配置读操作是真读。过于底层的细节冬瓜哥就不多介绍了。
Dell PowerEdge FX2平台对
PCI-E Switch的应用
Dell PowerEdge FX2是一款2U多节点服务器平台框架,其采用一个2U的Chassis机箱,最大可以容纳:
2个1U Server Sled
或者1个1U Server Sled+2个1U半宽存储Sled
或者1个1U半宽Server Sled+3个1U半宽存储Sled
或者4个1U半宽Server Sled
或者2个1U半宽Server Sled+2个1U半宽存储Sled
或者3个1U半宽Server Sled+1个1U半宽存储Sled
或者8个1U四分之一宽Server Sled
多种灵活组合都可实现。
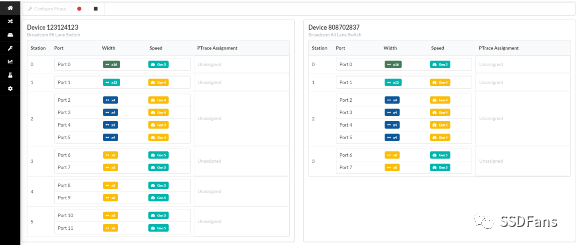
机箱背面有8个PCI-E槽位。
**这8个PCI-E槽位可以被灵活的分配给机箱正面的各种组合的Server Sled。这就得益于PCI-E Switch以及Partition功能的使用。**冬瓜哥画了一张示意图来向大家介绍一下其内部的导向路径。如下图所示,1/2号槽位所连接的端口与服务器Sled1所连接的端口处于红色分区之内,3/4槽位与服务器Sled2处于黄色分区。而5/6/7/8槽位、存储Sled、服务器Seld3则同处于蓝色分区内。意味着,服务器Sled3会识别到5/6/7/8槽位上的PCI-E卡(如有),同时识别到存储Sled上的RAID卡。
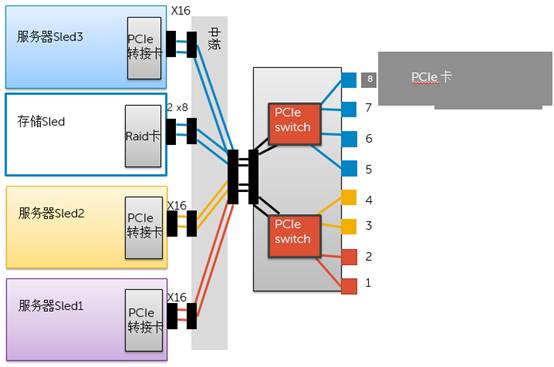
基于Web的配置界面,通过连接到BMC,可以对整个FX2平台所囊括的所有Sled进行全局配置,包括分配对应的PCI-E槽位,也就是底层的对PCI-E Switch的分区操作。
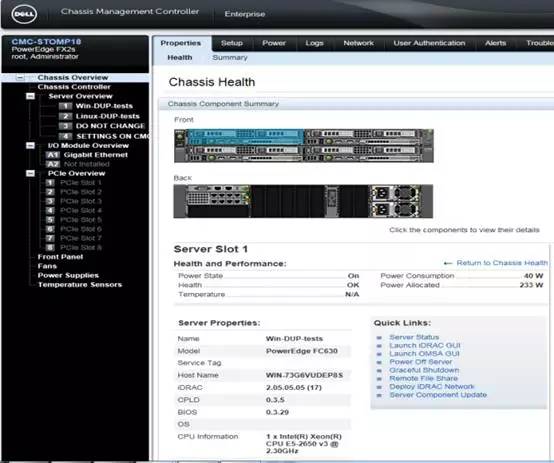
通过对PCI-E Switch分区功能的灵活运用,Dell PowerEdge FX2平台可以实现后面8个PCI-E设备的灵活分配,从而更好的适配日益灵活的应用场景和业务需求。
审核编辑:刘清














 工商网监
工商网监
评论