 电子发烧友App
电子发烧友App


一、 软件平台与硬件平台
软件平台:
1、操作系统:Windows-8.1
2、开发套件:ISE14.7
硬件平台:
1、 FPGA型号:Xilinx公司的XC6SLX45-2CSG324
2、 Flash型号:WinBond公司的W25Q128BV Qual SPI Flash存储器
二、 原理介绍
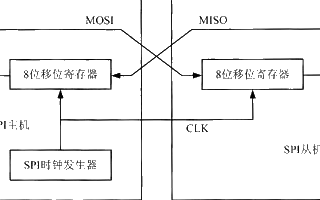
SPI(Serial Peripheral Interface,串行外围设备接口),是Motorola公司提出的一种同步串行接口技术,是一种高速、全双工、同步通信总线,在芯片中只占用四根管脚用来控制及数据传输,广泛用于EEPROM、Flash、RTC(实时时钟)、ADC(数模转换器)、DSP(数字信号处理器)以及数字信号解码器上。SPI通信的速度很容易达到好几兆bps,所以可以用SPI总线传输一些未压缩的音频以及压缩的视频。
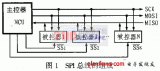
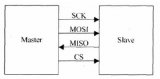
下图是只有2个chip利用SPI总线进行通信的结构图
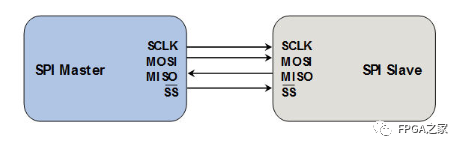
可知SPI总线传输只需要4根线就能完成,这四根线的作用分别如下:
SCK(Serial Clock):SCK是串行时钟线,作用是Master向Slave传输时钟信号,控制数据交换的时机和速率;
MOSI(Master Out Slave in):在SPI Master上也被称为Tx-channel,作用是SPI主机给SPI从机发送数据;
CS/SS(Chip Select/Slave Select):作用是SPI Master选择与哪一个SPI Slave通信,低电平表示从机被选中(低电平有效);
MISO(Master In Slave Out):在SPI Master上也被称为Rx-channel,作用是SPI主机接收SPI从机传输过来的数据;
SPI总线主要有以下几个特点:
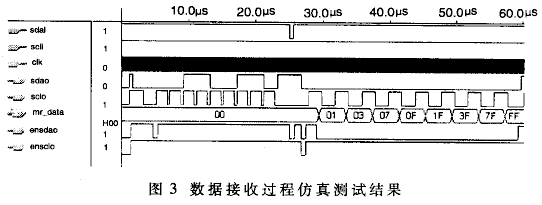
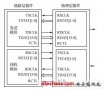
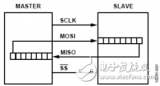
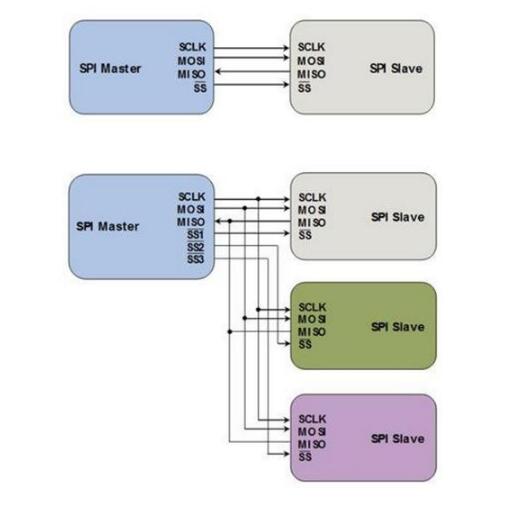
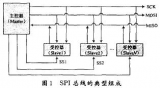
1、 采用主从模式(Master-Slave)的控制方式,支持单Master多Slave。SPI规定了两个SPI设备之间通信必须由主设备Master来控制从设备Slave。也就是说,如果FPGA是主机的情况下,不管是FPGA给芯片发送数据还是从芯片中接收数据,写Verilog逻辑的时候片选信号CS与串行时钟信号SCK必须由FPGA来产生。同时一个Master可以设置多个片选(Chip Select)来控制多个Slave。SPI协议还规定Slave设备的clock由Master通过SCK管脚提供给Slave,Slave本身不能产生或控制clock,没有clock则Slave不能正常工作。单Master多Slave的典型结构如下图所示
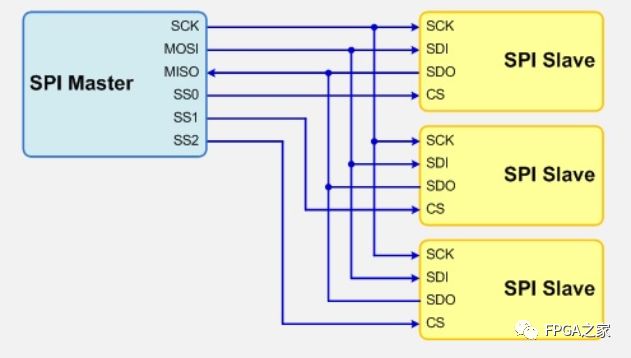
2、 SPI总线在传输数据的同时也传输了时钟信号,所以SPI协议是一种同步(Synchronous)传输协议。Master会根据将要交换的数据产生相应的时钟脉冲,组成时钟信号,时钟信号通过时钟极性(CPOL)和时钟相位(CPHA)控制两个SPI设备何时交换数据以及何时对接收数据进行采样,保证数据在两个设备之间是同步传输的。
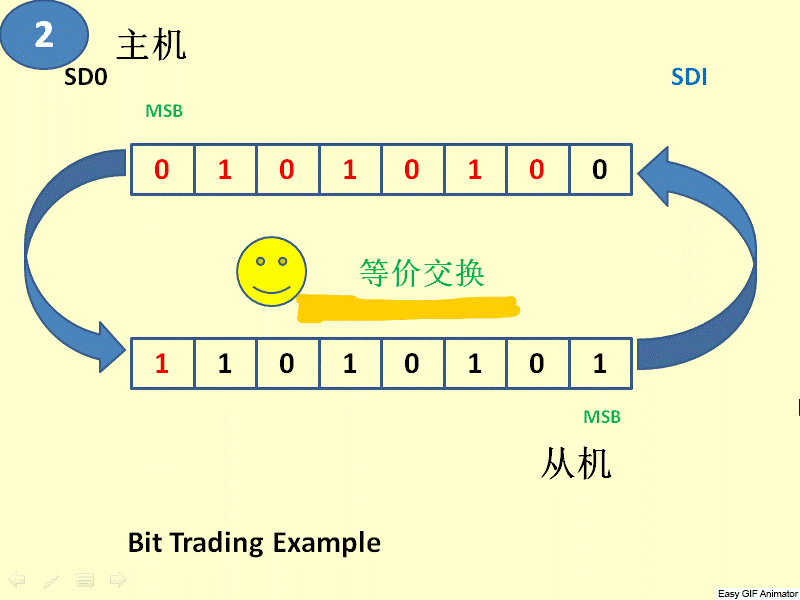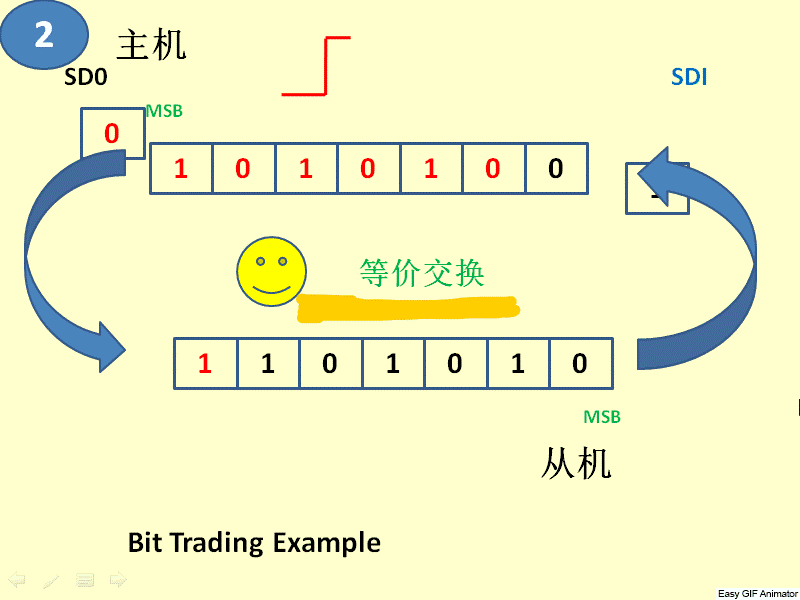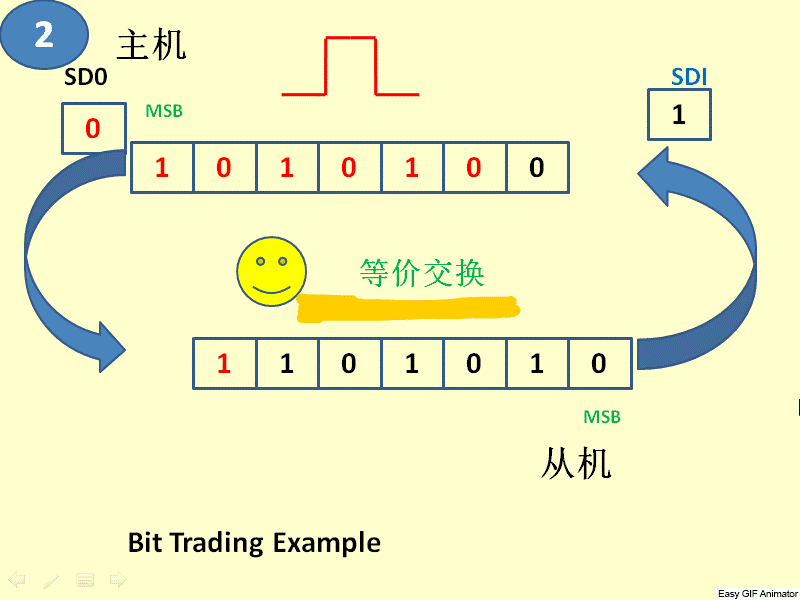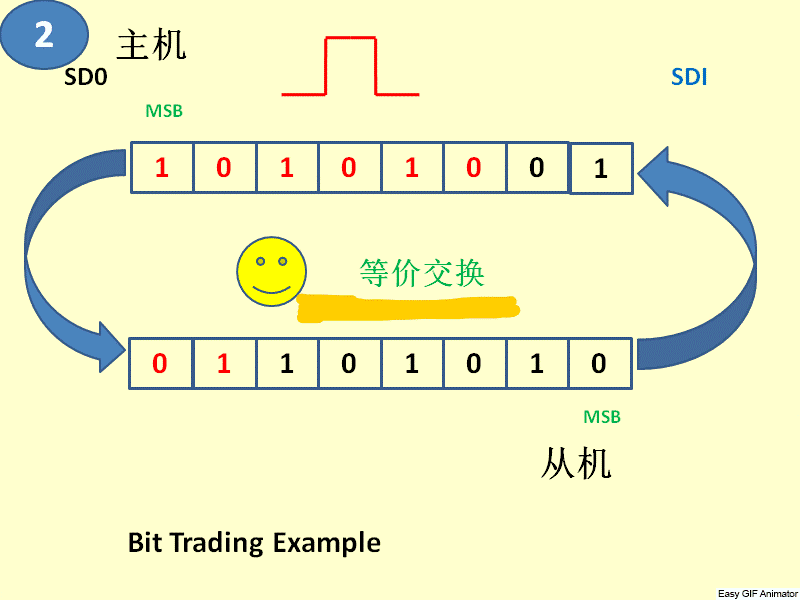
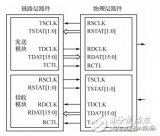
3、 SPI总线协议是一种全双工的串行通信协议,数据传输时高位在前,低位在后。SPI协议规定一个SPI设备不能在数据通信过程中仅仅充当一个发送者(Transmitter)或者接受者(Receiver)。在片选信号CS为0的情况下,每个clock周期内,SPI设备都会发送并接收1 bit数据,相当于有1 bit数据被交换了。数据传输高位在前,低位在后(MSB first)。SPI主从结构内部数据传输示意图如下图所示
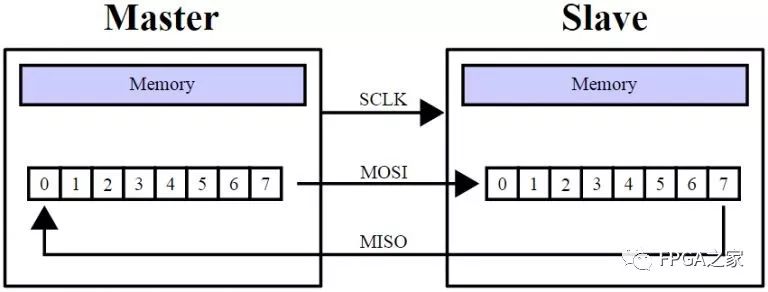
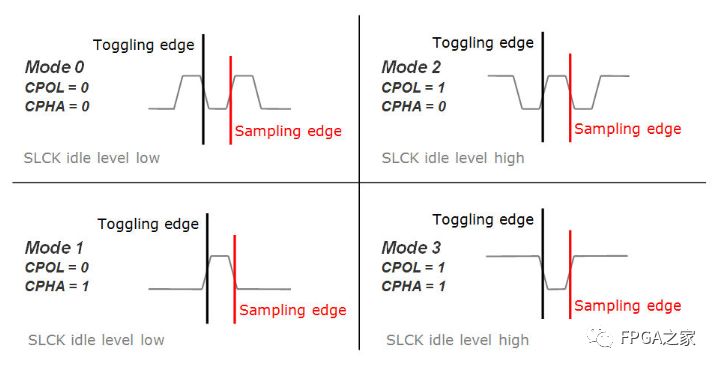
SPI总线传输的模式:
SPI总线传输一共有4中模式,这4种模式分别由时钟极性(CPOL,Clock Polarity)和时钟相位(CPHA,Clock Phase)来定义,其中CPOL参数规定了SCK时钟信号空闲状态的电平,CPHA规定了数据是在SCK时钟的上升沿被采样还是下降沿被采样。这四种模式的时序图如下图所示:
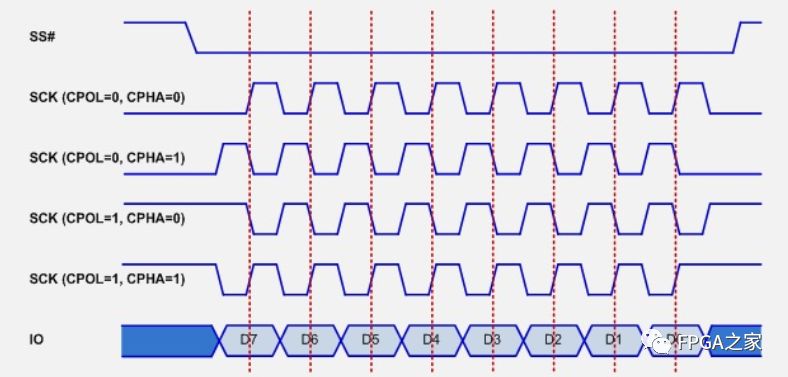
模式0:CPOL= 0,CPHA=0。SCK串行时钟线空闲是为低电平,数据在SCK时钟的上升沿被采样,数据在SCK时钟的下降沿切换
模式1:CPOL= 0,CPHA=1。SCK串行时钟线空闲是为低电平,数据在SCK时钟的下降沿被采样,数据在SCK时钟的上升沿切换
模式2:CPOL= 1,CPHA=0。SCK串行时钟线空闲是为高电平,数据在SCK时钟的下降沿被采样,数据在SCK时钟的上升沿切换
模式3:CPOL= 1,CPHA=1。SCK串行时钟线空闲是为高电平,数据在SCK时钟的上升沿被采样,数据在SCK时钟的下降沿切换
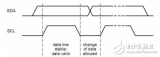
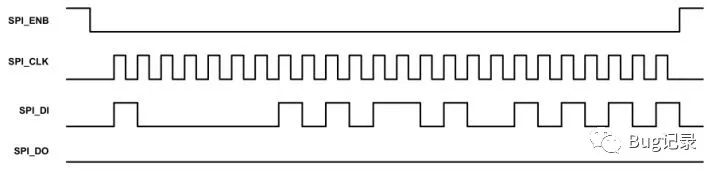
其中比较常用的模式是模式0和模式3。为了更清晰的描述SPI总线的时序,下面展现了模式0下的SPI时序图
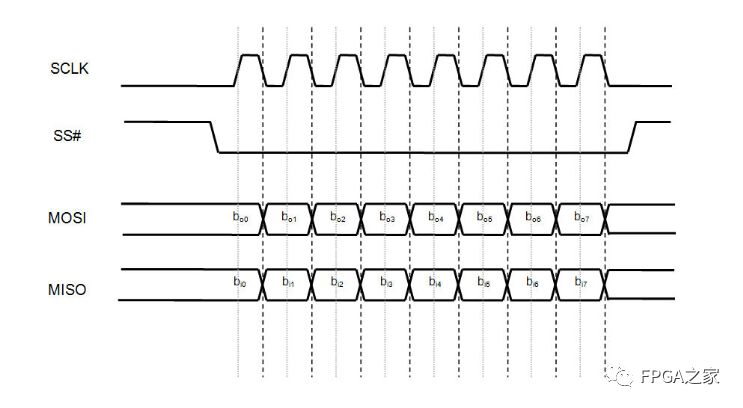
上图清晰的表明在模式0下,在空闲状态下,SCK串行时钟线为低电平,当SS被主机拉低以后,数据传输开始,数据线MOSI和MISO的数据切换(Toggling)发生在时钟的下降沿(上图的黑色虚线),而数据线MOSI和MISO的数据的采样(Sampling)发生在数据的正中间(上图中的灰色实线)。下图清晰的描述了其他三种模式数据线MOSI和MISO的数据切换(Toggling)位置和数据采样位置的关系图
下面我将以模式0为例用Verilog编写SPI通信的代码。
三、 目标任务
1、编写SPI通信的Verilog代码并利用ModelSim进行时序仿真
2、阅读Qual SPI的芯片手册,理解操作时序,并利用任务1编写的代码与Qual SPI进行SPI通信,读出Qual SPI Flash的Manufacturer/Device ID
3、用SPI总线把存放在ROM里面的数据发出去,这在实际项目中用来配置SPI外设芯片很有用
四、 设计思路与Verilog代码编写
4.1、 SPI模块的接口定义与整体设计
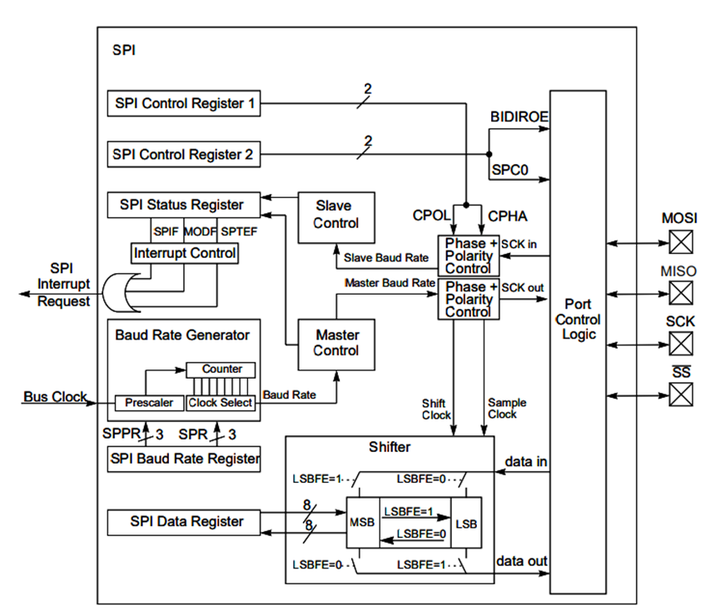
Verilog编写的SPI模块除了进行SPI通信的四根线以外还要包括一些时钟、复位、使能、并行的输入输出以及完成标志位。其框图如下所示
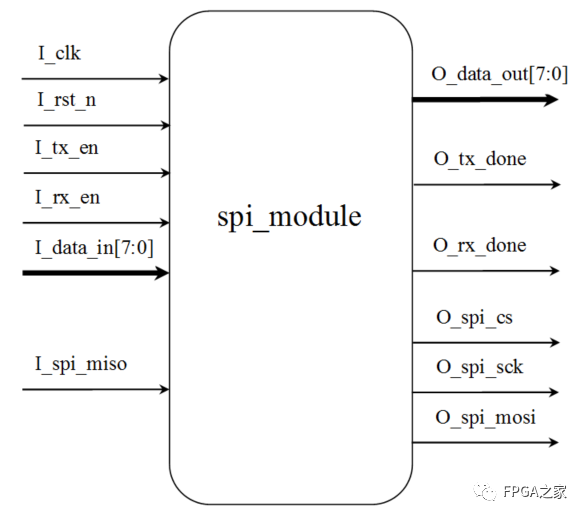
其中:
I_clk是系统时钟;
I_rst_n是系统复位;
I_tx_en是主机给从机发送数据的使能信号,当I_tx_en为1时主机才能给从机发送数据;
I_rx _en是主机从从机接收数据的使能信号,当I_rx_en为1时主机才能从从机接收数据;
I_data_in是主机要发送的并行数据;
O_data_out是把从机接收回来的串行数据并行化以后的并行数据;
O_tx_done是主机给从机发送数据完成的标志位,发送完成后会产生一个高脉冲;
O_rx_done是主机从从机接收数据完成的标志位,接收完成后会产生一个高脉冲;
I_spi_miso、O_spi_cs、O_spi_sck和O_spi_mosi是标准SPI总线协议规定的四根线;
要想实现上文模式0的时序,最简单的办法还是设计一个状态机。为了方便说明,这里把模式0的时序再在下面贴一遍
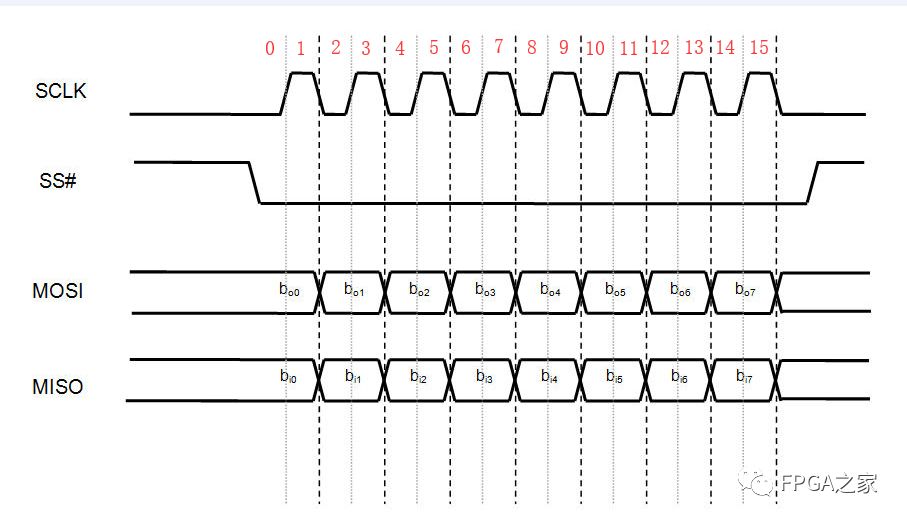
由于是要用FPGA去控制或读写QSPI Flash,所以FPGA是SPI主机,QSPI是SPI从机。
发送:当FPGA通过SPI总线往QSPI Flash中发送一个字节(8-bit)的数据时,首先FPGA把CS/SS片选信号设置为0,表示准备开始发送数据,整个发送数据过程其实可以分为16个状态:
状态0:SCK为0,MOSI为要发送的数据的最高位,即I_data_in[7]
状态1:SCK为1,MOSI保持不变
状态2:SCK为0,MOSI为要发送的数据的次高位,即I_data_in[6]
状态3:SCK为1,MOSI保持不变
状态4:SCK为0,MOSI为要发送的数据的下一位,即I_data_in[5]
状态5:SCK为1,MOSI保持不变
状态6:SCK为0,MOSI为要发送的数据的下一位,即I_data_in[4]
状态7:SCK为1,MOSI保持不变
状态8:SCK为0,MOSI为要发送的数据的下一位,即I_data_in[3]
状态9:SCK为1,MOSI保持不变
状态10:SCK为0,MOSI为要发送的数据的下一位,即I_data_in[2]
状态11:SCK为1,MOSI保持不变
状态12:SCK为0,MOSI为要发送的数据的下一位,即I_data_in[1]
状态13:SCK为1,MOSI保持不变
状态14:SCK为0,MOSI为要发送的数据的最低位,即I_data_in[0]
状态15:SCK为1,MOSI保持不变
一个字节数据发送完毕以后,产生一个发送完成标志位O_tx_done并把CS/SS信号拉高完成一次发送。通过观察上面的状态可以发现状态编号为奇数的状态要做的操作实际上是一模一样的,所以写代码的时候为了精简代码,可以把状态号为奇数的状态全部整合到一起。
接收:当FPGA通过SPI总线从QSPI Flash中接收一个字节(8-bit)的数据时,首先FPGA把CS/SS片选信号设置为0,表示准备开始接收数据,整个接收数据过程其实也可以分为16个状态,但是与发送过程不同的是,为了保证接收到的数据准确,必须在数据的正中间采样,也就是说模式0时序图中灰色实线的地方才是代码中锁存数据的地方,所以接收过程的每个状态执行的操作为:
状态0:SCK为0,不锁存MISO上的数据
状态1:SCK为1,锁存MISO上的数据,即把MISO上的数据赋值给O_data_out[7]
状态2:SCK为0,不锁存MISO上的数据
状态3:SCK为1,锁存MISO上的数据,即把MISO上的数据赋值给O_data_out[6]
状态4:SCK为0,不锁存MISO上的数据
状态5:SCK为1,锁存MISO上的数据,即把MISO上的数据赋值给O_data_out[5]
状态6:SCK为0,不锁存MISO上的数据
状态7:SCK为1,锁存MISO上的数据,即把MISO上的数据赋值给O_data_out[4]
状态8:SCK为0,不锁存MISO上的数据
状态9:SCK为1,锁存MISO上的数据,即把MISO上的数据赋值给O_data_out[3]
状态10:SCK为0,不锁存MISO上的数据
状态11:SCK为1,锁存MISO上的数据,即把MISO上的数据赋值给O_data_out[2]
状态12:SCK为0,不锁存MISO上的数据
状态13:SCK为1,锁存MISO上的数据,即把MISO上的数据赋值给O_data_out[1]
状态14:SCK为0,不锁存MISO上的数据
状态15:SCK为1,锁存MISO上的数据,即把MISO上的数据赋值给O_data_out[0]
一个字节数据接收完毕以后,产生一个接收完成标志位O_rx_done并把CS/SS信号拉高完成一次数据的接收。通过观察上面的状态可以发现状态编号为偶数的状态要做的操作实际上是一模一样的,所以写代码的时候为了精简代码,可以把状态号为偶数的状态全部整合到一起。而这一点刚好与发送过程的状态刚好相反。
思路理清楚以后就可以直接编写Verilog代码了,spi_module模块的代码如下:
module spi_module
(
input I_clk , // 全局时钟50MHz
input I_rst_n , // 复位信号,低电平有效
input I_rx_en , // 读使能信号
input I_tx_en , // 发送使能信号
input [7:0] I_data_in , // 要发送的数据
output reg [7:0] O_data_out , // 接收到的数据
output reg O_tx_done , // 发送一个字节完毕标志位
output reg O_rx_done , // 接收一个字节完毕标志位
// 四线标准SPI信号定义
input I_spi_miso , // SPI串行输入,用来接收从机的数据
output reg O_spi_sck , // SPI时钟
output reg O_spi_cs , // SPI片选信号
output reg O_spi_mosi // SPI输出,用来给从机发送数据
);
reg [3:0] R_tx_state ;
reg [3:0] R_rx_state ;
always @(posedge I_clk or negedge I_rst_n)
begin
if(!I_rst_n)
begin
R_tx_state <= 4'd0 ;
R_rx_state <= 4'd0 ;
O_spi_cs <= 1'b1 ;
O_spi_sck <= 1'b0 ;
O_spi_mosi <= 1'b0 ;
O_tx_done <= 1'b0 ;
O_rx_done <= 1'b0 ;
O_data_out <= 8'd0 ;
end
else if(I_tx_en) // 发送使能信号打开的情况下
begin
O_spi_cs <= 1'b0 ; // 把片选CS拉低
case(R_tx_state)
4'd1, 4'd3 , 4'd5 , 4'd7 ,
4'd9, 4'd11, 4'd13, 4'd15 : //整合奇数状态
begin
O_spi_sck <= 1'b1 ;
R_tx_state <= R_tx_state + 1'b1 ;
O_tx_done <= 1'b0 ;
end
4'd0: // 发送第7位
begin
O_spi_mosi <= I_data_in[7] ;
O_spi_sck <= 1'b0 ;
R_tx_state <= R_tx_state + 1'b1 ;
O_tx_done <= 1'b0 ;
end
4'd2: // 发送第6位
begin
O_spi_mosi <= I_data_in[6] ;
O_spi_sck <= 1'b0 ;
R_tx_state <= R_tx_state + 1'b1 ;
O_tx_done <= 1'b0 ;
end
4'd4: // 发送第5位
begin
O_spi_mosi <= I_data_in[5] ;
O_spi_sck <= 1'b0 ;
R_tx_state <= R_tx_state + 1'b1 ;
O_tx_done <= 1'b0 ;
end
4'd6: // 发送第4位
begin
O_spi_mosi <= I_data_in[4] ;
O_spi_sck <= 1'b0 ;
R_tx_state <= R_tx_state + 1'b1 ;
O_tx_done <= 1'b0 ;
end
4'd8: // 发送第3位
begin
O_spi_mosi <= I_data_in[3] ;
O_spi_sck <= 1'b0 ;
R_tx_state <= R_tx_state + 1'b1 ;
O_tx_done <= 1'b0 ;
end
4'd10: // 发送第2位
begin
O_spi_mosi <= I_data_in[2] ;
O_spi_sck <= 1'b0 ;
R_tx_state <= R_tx_state + 1'b1 ;
O_tx_done <= 1'b0 ;
end
4'd12: // 发送第1位
begin
O_spi_mosi <= I_data_in[1] ;
O_spi_sck <= 1'b0 ;
R_tx_state <= R_tx_state + 1'b1 ;
O_tx_done <= 1'b0 ;
end
4'd14: // 发送第0位
begin
O_spi_mosi <= I_data_in[0] ;
O_spi_sck <= 1'b0 ;
R_tx_state <= R_tx_state + 1'b1 ;
O_tx_done <= 1'b1 ;
end
default:R_tx_state <= 4'd0 ;
endcase
end
else if(I_rx_en) // 接收使能信号打开的情况下
begin
O_spi_cs <= 1'b0 ; // 拉低片选信号CS
case(R_rx_state)
4'd0, 4'd2 , 4'd4 , 4'd6 ,
4'd8, 4'd10, 4'd12, 4'd14 : //整合偶数状态
begin
O_spi_sck <= 1'b0 ;
R_rx_state <= R_rx_state + 1'b1 ;
O_rx_done <= 1'b0 ;
end
4'd1: // 接收第7位
begin
O_spi_sck <= 1'b1 ;
R_rx_state <= R_rx_state + 1'b1 ;
O_rx_done <= 1'b0 ;
O_data_out[7] <= I_spi_miso ;
end
4'd3: // 接收第6位
begin
O_spi_sck <= 1'b1 ;
R_rx_state <= R_rx_state + 1'b1 ;
O_rx_done <= 1'b0 ;
O_data_out[6] <= I_spi_miso ;
end
4'd5: // 接收第5位
begin
O_spi_sck <= 1'b1 ;
R_rx_state <= R_rx_state + 1'b1 ;
O_rx_done <= 1'b0 ;
O_data_out[5] <= I_spi_miso ;
end
4'd7: // 接收第4位
begin
O_spi_sck <= 1'b1 ;
R_rx_state <= R_rx_state + 1'b1 ;
O_rx_done <= 1'b0 ;
O_data_out[4] <= I_spi_miso ;
end
4'd9: // 接收第3位
begin
O_spi_sck <= 1'b1 ;
R_rx_state <= R_rx_state + 1'b1 ;
O_rx_done <= 1'b0 ;
O_data_out[3] <= I_spi_miso ;
end
4'd11: // 接收第2位
begin
O_spi_sck <= 1'b1 ;
R_rx_state <= R_rx_state + 1'b1 ;
O_rx_done <= 1'b0 ;
O_data_out[2] <= I_spi_miso ;
end
4'd13: // 接收第1位
begin
O_spi_sck <= 1'b1 ;
R_rx_state <= R_rx_state + 1'b1 ;
O_rx_done <= 1'b0 ;
O_data_out[1] <= I_spi_miso ;
end
4'd15: // 接收第0位
begin
O_spi_sck <= 1'b1 ;
R_rx_state <= R_rx_state + 1'b1 ;
O_rx_done <= 1'b1 ;
O_data_out[0] <= I_spi_miso ;
end
default:R_rx_state <= 4'd0 ;
endcase
end
else
begin
R_tx_state <= 4'd0 ;
R_rx_state <= 4'd0 ;
O_tx_done <= 1'b0 ;
O_rx_done <= 1'b0 ;
O_spi_cs <= 1'b1 ;
O_spi_sck <= 1'b0 ;
O_spi_mosi <= 1'b0 ;
O_data_out <= 8'd0 ;
end
end
endmodule
整个代码的流程与之前分析的流程完全一致。接下来就对这个代码用ModelSim进行基本的仿真。由于接收部分不再硬件上不太好测,所以这里只对发送部分进行测试,接收部分等把代码下载到板子里面以后用ChipScope抓接收部分时序就一清二楚了。
发射部分的测试激励代码如下:
`timescale 1ns / 1ps module tb_spi_module; // Inputs reg I_clk; reg I_rst_n; reg I_rx_en; reg I_tx_en; reg [7:0] I_data_in; reg I_spi_miso; // Outputs wire [7:0] O_data_out; wire O_tx_done; wire O_rx_done; wire O_spi_sck; wire O_spi_cs; wire O_spi_mosi; // Instantiate the Unit Under Test (UUT) spi_module uut ( .I_clk (I_clk ), .I_rst_n (I_rst_n ), .I_rx_en (I_rx_en ), .I_tx_en (I_tx_en ), .I_data_in (I_data_in ), .O_data_out (O_data_out ), .O_tx_done (O_tx_done ), .O_rx_done (O_rx_done ), .I_spi_miso (I_spi_miso ), .O_spi_sck (O_spi_sck ), .O_spi_cs (O_spi_cs ), .O_spi_mosi (O_spi_mosi ) ); initial begin // Initialize Inputs I_clk = 0; I_rst_n = 0; I_rx_en = 0; I_tx_en = 1; I_data_in = 8'h00; I_spi_miso = 0; // Wait 100 ns for global reset to finish #100; I_rst_n = 1; end always #10 I_clk = ~I_clk ; always @(posedge I_clk or negedge I_rst_n) begin if(!I_rst_n) I_data_in <= 8'h00; else if(I_data_in == 8'hff) begin I_data_in <= 8'hff; I_tx_en <= 0; end else if(O_tx_done) I_data_in <= I_data_in + 1'b1 ; end endmodule
ModelSim的仿真图如下图所示:

由图可以看到仿真得到的时序与SPI模式0的时序完全一致。
4.2、 W25Q128BV Qual SPI Flash存储器时序分析
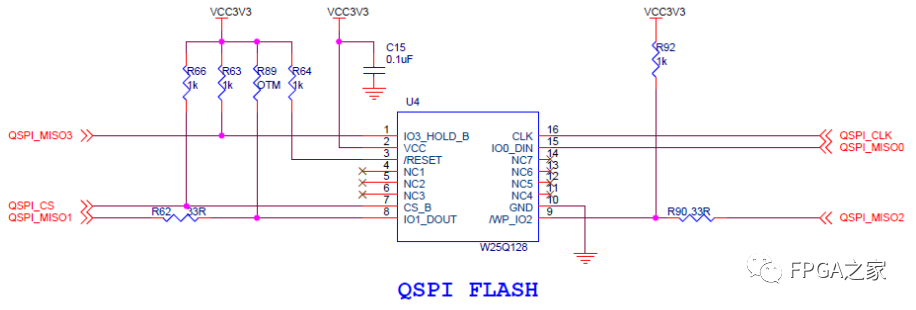
W25Q128BV,支持SPI, Dual SPI和Quad SPI接口方式。在Fast Read模式,接口的时钟速率最大可以达到 104Mhz。FLASH 的容量由 65536个256-byte的Page组成。W25Q128 的擦除方法有三种,一种为 Sector 擦除(16 个 page,共 4KB),一种为 Block 擦除(128 个 page,共 32KB), 另一种为 Chip 擦除(整个擦除)。为了简单起见,顺便测试一下上面写的代码,这里只使用W25Q128BV的标准SPI总线操作功能,并且只完成一个读取ID的操作,其他更高级的操作请看下一篇文章《QSPI Flash的原理与QSPI时序的Verilog实现》(链接:https://www.cnblogs.com/liujinggang/p/9651170.html)。我的开发板上W25Q128BV的硬件原理图如下图所示
由于我们的任务是利用标准四线SPI总线读取QSPI FLASH的Manufacturer/Device ID,所以先到W25Q128BV的芯片手册中找到它的读Manufacturer/Device ID的时序。时序如下图所示:
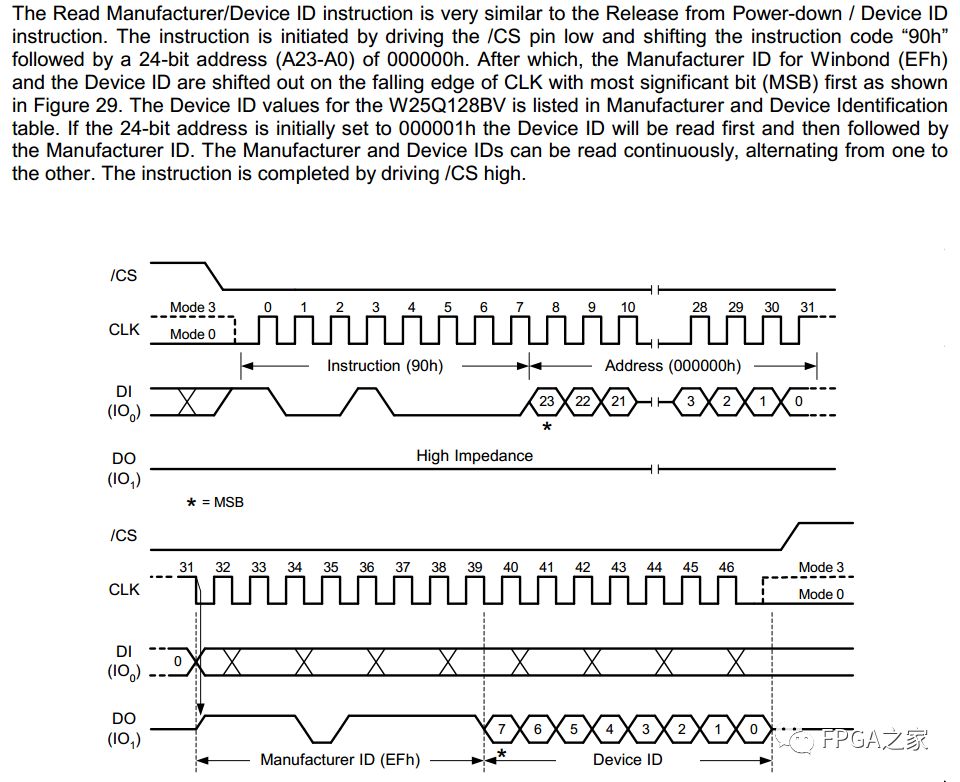
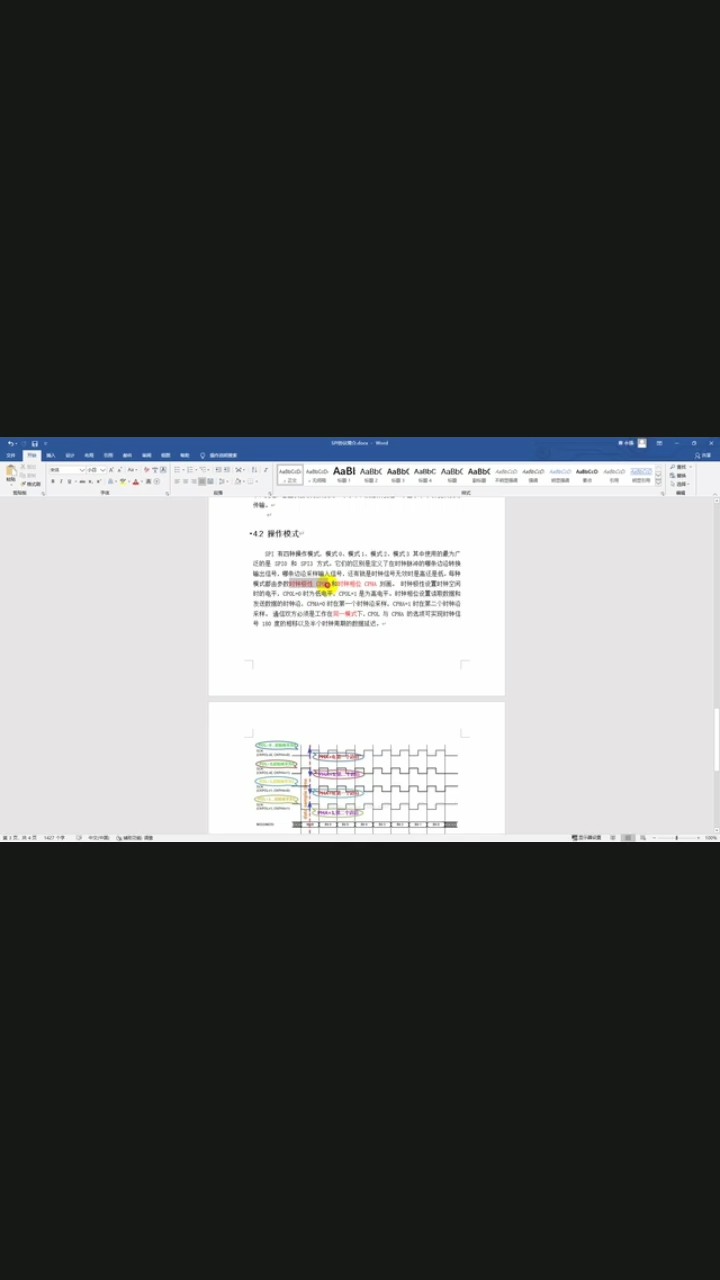
整个读QSPI FLASH的过程为:FPGA先拉低CS片选信号,然后通过SPI总线发送命令码90,命令码发完以后,发送24-bit的地址24’h000000,接着在第32个SCK的下降沿准备接收Manufacturer ID,Manufacturer ID接收完毕以后开始接收Device ID,最后把CS片选拉高,一次读取过程全部结束。这里既涉及到了SPI的写操作,也涉及到了SPI的读操作,刚好可以测试一下上面写的代码。
4.3、 构思状态机并用ChipScope抓读写时序
由时序图可以很轻松的分析出,用一个7个状态的状态机来实现读ID的过程,其中状态的跳变可通过发送完成标志O_tx_done与接收完成标志O_rx_done来切换,各个状态的功能如下:
状态0:打开spi_module的发送使能开关,并初始化命令字90,等O_tx_done标志为高后切换到下一状态并设置好下一次要发送的数据;
状态1:打开spi_module的发送使能开关,并设置低8位地址00,等O_tx_done标志为高后切换到下一状态并设置好下一次要发送的数据;
状态2:打开spi_module的发送使能开关,并设置中8位地址00,等O_tx_done标志为高后切换到下一状态并设置好下一次要发送的数据;
状态3:打开spi_module的发送使能开关,并设置高8位地址00,等O_tx_done标志为高后切换到下一状态并设置好下一次要发送的数据;
状态4:关闭spi_module的发送使能开关,打开spi_module的接收使能开关,等O_rx_done标志为高后切换到下一状态;
状态5:关闭spi_module的发送使能开关,打开spi_module的接收使能开关,等O_rx_done标志为高后切换到下一状态,并关闭spi_module所有使能开关;
状态6:结束状态,关闭spi_module所有使能开关;
读ID的完整代码如下:
`timescale 1ns / 1ps
module spi_read_id_top
(
input I_clk , // 全局时钟50MHz
input I_rst_n , // 复位信号,低电平有效
output [3:0] O_led_out ,
// 四线标准SPI信号定义
input I_spi_miso , // SPI串行输入,用来接收从机的数据
output O_spi_sck , // SPI时钟
output O_spi_cs , // SPI片选信号
output O_spi_mosi // SPI输出,用来给从机发送数据
);
wire W_rx_en ;
wire W_tx_en ;
wire [7:0] W_data_in ; // 要发送的数据
wire [7:0] W_data_out ; // 接收到的数据
wire W_tx_done ; // 发送最后一个bit标志位,在最后一个bit产生一个时钟的高电平
wire W_rx_done ; // 接收一个字节完毕(End of Receive)
reg R_rx_en ;
reg R_tx_en ;
reg [7:0] R_data_in ; // 要发送的数据
reg [2:0] R_state ;
reg [7:0] R_spi_pout ;
assign W_rx_en = R_rx_en ;
assign W_tx_en = R_tx_en ;
assign W_data_in = R_data_in ;
assign O_led_out = R_spi_pout[3:0] ;
always @(posedge I_clk or negedge I_rst_n)
begin
if(!I_rst_n)
begin
R_state <= 3'd0 ;
R_tx_en <= 1'b0 ;
R_rx_en <= 1'b0 ;
end
else
case(R_state)
3'd0: // 发送命令字90
begin
if(W_tx_done)
begin
R_state <= R_state + 1'b1 ;
R_data_in <= 8'h00 ; // 提前设定好下一次要发送的数据
end
else
begin
R_tx_en <= 1'b1 ;
R_data_in <= 8'h90 ;
end
end
3'd1,3'd2,3'd3: // 发送24位的地址信号
begin
if(W_tx_done)
begin
R_state <= R_state + 1'b1 ;
R_data_in <= 8'h00 ; // 提前设定好下一次要发送的数据
end
else
begin
R_tx_en <= 1'b1 ;
R_data_in <= 8'h00 ;
end
end
3'd4: // 接收ID EF
begin
if(W_rx_done)
begin
R_state <= R_state + 1'b1 ;
R_spi_pout <= W_data_out ;
end
else
begin
R_tx_en <= 1'b0 ;
R_rx_en <= 1'b1 ;
end
end
3'd5: // 接收ID 17
begin
if(W_rx_done)
begin
R_state <= R_state + 1'b1 ;
R_spi_pout <= W_data_out ;
R_tx_en <= 1'b0 ;
R_rx_en <= 1'b0 ;
end
else
begin
R_tx_en <= 1'b0 ;
R_rx_en <= 1'b1 ;
end
end
3'd6: //结束
begin
R_state <= R_state ;
R_tx_en <= 1'b0 ;
R_rx_en <= 1'b0 ;
end
endcase
end
spi_module U_spi_module
(
.I_clk (I_clk), // 全局时钟50MHz
.I_rst_n (I_rst_n), // 复位信号,低电平有效
.I_rx_en (W_rx_en), // 读使能信号
.I_tx_en (W_tx_en), // 发送使能信号
.I_data_in (W_data_in), // 要发送的数据
.O_data_out (W_data_out), // 接收到的数据
.O_tx_done (W_tx_done), // 发送最后一个bit标志位,在最后一个bit产生一个时钟的高电平
.O_rx_done (W_rx_done), // 接收一个字节完毕(End of Receive)
// 四线标准SPI信号定义
.I_spi_miso (I_spi_miso), // SPI串行输入,用来接收从机的数据
.O_spi_sck (O_spi_sck), // SPI时钟
.O_spi_cs (O_spi_cs), // SPI片选信号
.O_spi_mosi (O_spi_mosi) // SPI输出,用来给从机发送数据
);
//////// Debug //////////////////////////////////////////////////////////////
wire [35:0] CONTROL0 ;
wire [39:0] TRIG0 ;
icon icon (
.CONTROL0(CONTROL0) // INOUT BUS [35:0]
);
ila ila (
.CONTROL(CONTROL0), // INOUT BUS [35:0]
.CLK(I_clk), // IN
.TRIG0(TRIG0) // IN BUS [39:0]
);
assign TRIG0[0] = W_rx_en ;
assign TRIG0[1] = W_tx_en ;
assign TRIG0[9:2] = W_data_in ;
assign TRIG0[17:10] = W_data_out ;
assign TRIG0[18] = W_tx_done ;
assign TRIG0[19] = W_rx_done ;
assign TRIG0[27:20] = R_spi_pout ;
assign TRIG0[30:28] = R_state ;
assign TRIG0[31] = O_spi_sck ;
assign TRIG0[32] = O_spi_cs ;
assign TRIG0[33] = O_spi_mosi ;
assign TRIG0[34] = I_spi_miso ;
assign TRIG0[35] = I_rst_n ;
///////////////////////////////////////////////////////////////////////////////
endmodule
用ChipScope抓取的时序图如下图所示:
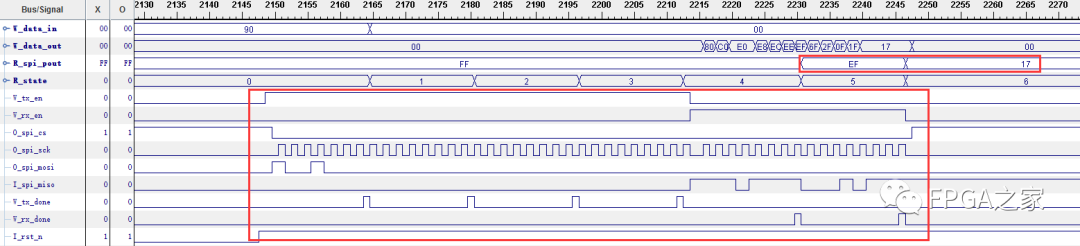
通过对比与芯片手册的时序图可以发现,每个节拍与芯片手册提供的读ID的时序完全一致。
4.4、 用FPGA通过SPI总线配置外设芯片
上文的例子已经包括了连续发送4个字节数据和连续接收2个字节数据,实际上在很多应用中只需要FPGA通过SPI总线给芯片发送相应寄存器的值就可以对芯片的功能进行配置了,而并不需要接收芯片返回的数据,大家可以依着葫芦画瓢把硬件工程师发过来的芯片寄存器表(实际上很多芯片都有配置软件,硬件工程师在配置软件中设定好参数以后可以自动生成寄存器表)通过像上文那样写一个状态机发出去来配置芯片的功能。
在寄存器数目比较少的情况下,比如就30~40个以下的寄存器需要配置的情况下,完全可以按照上面的思路写一个30~40个状态的状态机,每个状态通过SPI总线发送一个数据,这样做的好处是以后想要在其他地方移植这套代码或者做版本的维护与升级时只需要复制上一版本的代码就可以了,移植起来非常方便。但是如果需要配置的寄存器有好几百甚至上千个或者需要用SPI总线往一些显示设备(比如OLED屏,液晶显示屏)里面发送数据的话,如果去写一个上千个状态的状态机显然不是最好的选择,所以对于这种需要用SPI传输大量数据的情况,我比较推荐的方式是先把数据存放在ROM里面,然后通过上面的SPI代码发出去。
在做这件事情之前,在重复理解一下SPI发送过程的时序:
状态0:SCK为0,MOSI为要发送的数据的最高位,即I_data_in[7],拉低O_tx_done信号
状态1:SCK为1,MOSI保持不变,拉低O_tx_done信号
状态2:SCK为0,MOSI为要发送的数据的次高位,即I_data_in[6] ,拉低O_tx_done信号
状态3:SCK为1,MOSI保持不变,拉低O_tx_done信号
状态4:SCK为0,MOSI为要发送的数据的下一位,即I_data_in[5] ,拉低O_tx_done信号
状态5:SCK为1,MOSI保持不变,拉低O_tx_done信号
状态6:SCK为0,MOSI为要发送的数据的下一位,即I_data_in[4] ,拉低O_tx_done信号
状态7:SCK为1,MOSI保持不变,拉低O_tx_done信号
状态8:SCK为0,MOSI为要发送的数据的下一位,即I_data_in[3] ,拉低O_tx_done信号
状态9:SCK为1,MOSI保持不变,拉低O_tx_done信号
状态10:SCK为0,MOSI为要发送的数据的下一位,即I_data_in[2] ,拉低O_tx_done信号
状态11:SCK为1,MOSI保持不变,拉低O_tx_done信号
状态12:SCK为0,MOSI为要发送的数据的下一位,即I_data_in[1] ,拉低O_tx_done信号
状态13:SCK为1,MOSI保持不变,拉低O_tx_done信号
状态14:SCK为0,MOSI为要发送的数据的最低位,即I_data_in[0] ,拉高O_tx_done信号
状态15:SCK为1,MOSI保持不变,拉低O_tx_done信号
可以看出,每一个bit为实际上是占了2个时钟周期(这里的时钟周期指的是系统时钟I_clk),发送一个字节完成标志位O_tx_done信号是在第14个状态拉高的,也就是在最后一个bit的前时钟周期产生了一个高电平,我之所以这么做的目的一是为了更好的整合代码,把偶数状态全部归类到一起,二是为了在连续发送数据时,在检测到O_tx_done信号为高以后,可以提前把下一次要发送的数据准备好。大家可以在对照着下面时序图理解一下,下面这张图可以很清晰的看到,O_tx_done信号是在最后一个数据的前一个时钟周期拉高的。
现在我们的目的是想要把ROM里面的数据通过SPI总线发出来,但是由于ROM是更新了地址以后的下一个时钟周期才能读出新数据,也就是说,如果我们在检测到O_tx_done为高时更新ROM地址的话,新的数据其实并没有准备好,直接看代码和时序图。
在此之前先把ROM配置好,我配置的ROM非常简单,Read Width设置为8,Read Depth设置为10,
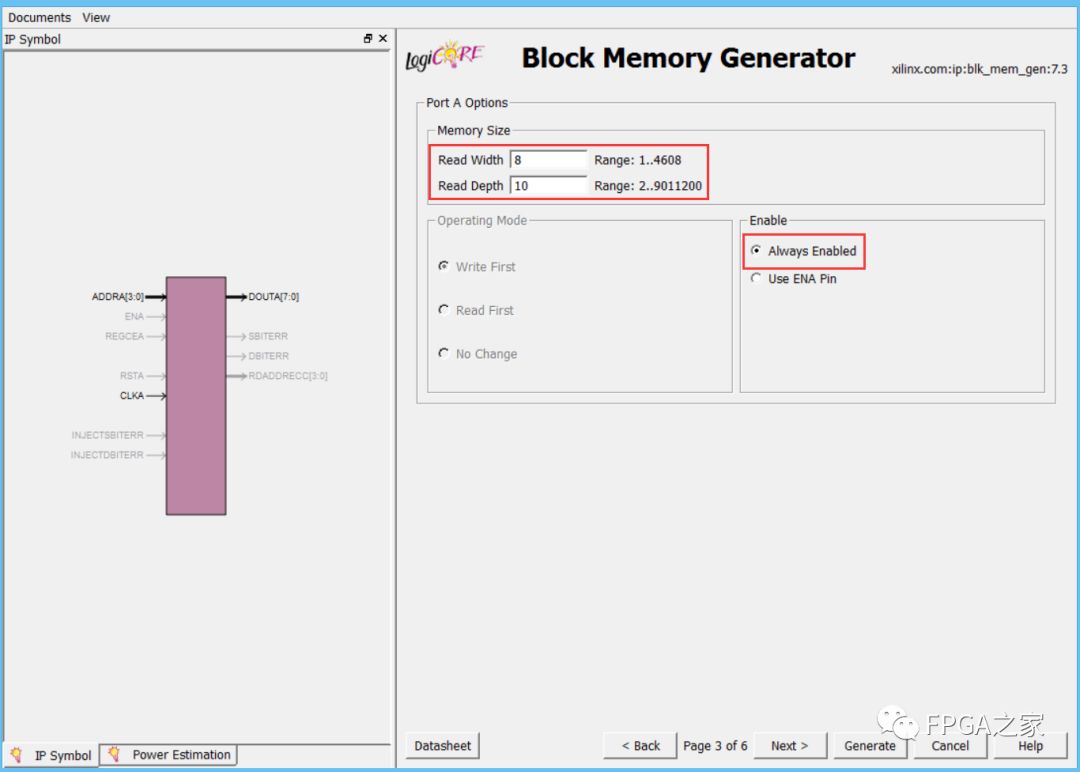
ROM的初始化数据.coe文件的内容如下所示:
MEMORY_INITIALIZATION_RADIX=16;
MEMORY_INITIALIZATION_VECTOR=
33,
24,
98,
24,
00,
47,
00,
ff,
a3,
49;
顶层代码如下所示:
`timescale 1ns / 1ps
module spi_reg_cfg
(
input I_clk , // 全局时钟50MHz
input I_rst_n , // 复位信号,低电平有效
// 四线标准SPI信号定义
input I_spi_miso , // SPI串行输入,用来接收从机的数据
output O_spi_sck , // SPI时钟
output O_spi_cs , // SPI片选信号
output O_spi_mosi // SPI输出,用来给从机发送数据
);
wire W_rx_en ;
wire W_tx_en ;
wire [7:0] W_data_out ; // 接收到的数据
wire W_tx_done ; // 发送最后一个bit标志位,在最后一个bit产生一个时钟的高电平
wire W_rx_done ; // 接收一个字节完毕
reg R_rx_en ;
reg R_tx_en ;
reg [2:0] R_state ;
assign W_rx_en = R_rx_en ;
assign W_tx_en = R_tx_en ;
parameter C_REG_NUM = 10 ; // 要配置的寄存器个数,也是ROM的深度
parameter C_IDLE = 3'd0 ,
C_SEND_DATA = 3'd1 ,
C_DONE = 3'd2 ;
reg [3:0] R_rom_addr ;
wire [7:0] W_rom_out ;
always @(posedge I_clk or negedge I_rst_n)
begin
if(!I_rst_n)
begin
R_state <= 3'd0 ;
R_tx_en <= 1'b0 ;
R_rx_en <= 1'b0 ;
R_rom_addr <= 4'd0 ;
end
else
case(R_state)
C_IDLE: // 空闲状态
begin
R_state <= C_SEND_DATA;
R_tx_en <= 1'b0 ;
R_rx_en <= 1'b0 ;
end
C_SEND_DATA: // 发送数据状态
begin
R_tx_en <= 1'b1 ;
if(R_rom_addr == C_REG_NUM)
begin
R_state <= C_DONE;
R_tx_en <= 1'b0 ;
R_rx_en <= 1'b0 ;
end
else if(W_tx_done)
R_rom_addr <= R_rom_addr + 1'b1 ;
else
R_rom_addr <= R_rom_addr ;
end
C_DONE:
begin
R_state <= C_DONE ;
R_tx_en <= 1'b0 ;
R_rx_en <= 1'b0 ;
end
endcase
end
rom_cfg rom_cfg_inst (
.clka (I_clk ), // input clka
.addra (R_rom_addr ), // input [3 : 0] addra
.douta (W_rom_out ) // output [7 : 0] douta
);
spi_module U_spi_module
(
.I_clk (I_clk), // 全局时钟50MHz
.I_rst_n (I_rst_n), // 复位信号,低电平有效
.I_rx_en (W_rx_en), // 读使能信号
.I_tx_en (W_tx_en), // 发送使能信号
.I_data_in (W_rom_out), // 要发送的数据
.O_data_out (W_data_out), // 接收到的数据
.O_tx_done (W_tx_done), // 发送最后一个bit标志位,在最后一个bit产生一个时钟的高电平
.O_rx_done (W_rx_done), // 接收一个字节完毕(End of Receive)
// 四线标准SPI信号定义
.I_spi_miso (I_spi_miso), // SPI串行输入,用来接收从机的数据
.O_spi_sck (O_spi_sck), // SPI时钟
.O_spi_cs (O_spi_cs), // SPI片选信号
.O_spi_mosi (O_spi_mosi) // SPI输出,用来给从机发送数据
);
//////// Debug //////////////////////////////////////////////////////////////
wire [35:0] CONTROL0 ;
wire [39:0] TRIG0 ;
icon icon (
.CONTROL0(CONTROL0) // INOUT BUS [35:0]
);
ila ila (
.CONTROL(CONTROL0), // INOUT BUS [35:0]
.CLK(I_clk), // IN
.TRIG0(TRIG0) // IN BUS [39:0]
);
assign TRIG0[0] = W_rx_en ;
assign TRIG0[1] = W_tx_en ;
assign TRIG0[9:2] = W_rom_out ;
assign TRIG0[17:10] = W_data_out ;
assign TRIG0[18] = W_tx_done ;
assign TRIG0[19] = W_rx_done ;
assign TRIG0[30:28] = R_state ;
assign TRIG0[31] = O_spi_sck ;
assign TRIG0[32] = O_spi_cs ;
assign TRIG0[33] = O_spi_mosi ;
assign TRIG0[34] = I_spi_miso ;
assign TRIG0[35] = I_rst_n ;
assign TRIG0[39:36] = R_rom_addr ;
///////////////////////////////////////////////////////////////////////////////
endmodule
时序图如下所示:

从上面的时序图可以很清楚的看出,当ROM的地址加1以后,ROM的数据是滞后了一个时钟才输出的,而ROM数据输出的时刻(这个时候ROM的输出数据并没有稳定)刚好是spi_module模块发送下个数据最高位的时刻,那么这就有可能导致数据发送错误,从以上时序图就可以看出8’h33和8’h24两个数据正确发送了,但是8’h98这个数据就发送错误了。
为了解决这个问题,其实只需要把spi_module模块的发送状态机在加一个冗余状态就行了,spi_module模块的发送状态机一共有0~15总共16个状态,那么我在加一个冗余状态,这个状态执行的操作和最后那个状态执行的操作完全相同,这样就预留了一个时钟的时间用来预先设置好要发送的数据,这样的效果是发送数据的最后一个bit实际上占用了3个时钟周期,其中第一个时钟周期把O_tx_done拉高,后两个时钟周期把O_tx_done拉低。修改后的spi_module模块的代码如下:

module spi_module
(
input I_clk , // 全局时钟50MHz
input I_rst_n , // 复位信号,低电平有效
input I_rx_en , // 读使能信号
input I_tx_en , // 发送使能信号
input [7:0] I_data_in , // 要发送的数据
output reg [7:0] O_data_out , // 接收到的数据
output reg O_tx_done , // 发送一个字节完毕标志位
output reg O_rx_done , // 接收一个字节完毕标志位
// 四线标准SPI信号定义
input I_spi_miso , // SPI串行输入,用来接收从机的数据
output reg O_spi_sck , // SPI时钟
output reg O_spi_cs , // SPI片选信号
output reg O_spi_mosi // SPI输出,用来给从机发送数据
);
reg [4:0] R_tx_state ;
reg [3:0] R_rx_state ;
always @(posedge I_clk or negedge I_rst_n)
begin
if(!I_rst_n)
begin
R_tx_state <= 5'd0 ;
R_rx_state <= 4'd0 ;
O_spi_cs <= 1'b1 ;
O_spi_sck <= 1'b0 ;
O_spi_mosi <= 1'b0 ;
O_tx_done <= 1'b0 ;
O_rx_done <= 1'b0 ;
O_data_out <= 8'd0 ;
end
else if(I_tx_en) // 发送使能信号打开的情况下
begin
O_spi_cs <= 1'b0 ; // 把片选CS拉低
case(R_tx_state)
5'd1, 5'd3 , 5'd5 , 5'd7 ,
5'd9, 5'd11, 5'd13, 5'd15 : //整合奇数状态
begin
O_spi_sck <= 1'b1 ;
R_tx_state <= R_tx_state + 1'b1 ;
O_tx_done <= 1'b0 ;
end
5'd0: // 发送第7位
begin
O_spi_mosi <= I_data_in[7] ;
O_spi_sck <= 1'b0 ;
R_tx_state <= R_tx_state + 1'b1 ;
O_tx_done <= 1'b0 ;
end
5'd2: // 发送第6位
begin
O_spi_mosi <= I_data_in[6] ;
O_spi_sck <= 1'b0 ;
R_tx_state <= R_tx_state + 1'b1 ;
O_tx_done <= 1'b0 ;
end
5'd4: // 发送第5位
begin
O_spi_mosi <= I_data_in[5] ;
O_spi_sck <= 1'b0 ;
R_tx_state <= R_tx_state + 1'b1 ;
O_tx_done <= 1'b0 ;
end
5'd6: // 发送第4位
begin
O_spi_mosi <= I_data_in[4] ;
O_spi_sck <= 1'b0 ;
R_tx_state <= R_tx_state + 1'b1 ;
O_tx_done <= 1'b0 ;
end
5'd8: // 发送第3位
begin
O_spi_mosi <= I_data_in[3] ;
O_spi_sck <= 1'b0 ;
R_tx_state <= R_tx_state + 1'b1 ;
O_tx_done <= 1'b0 ;
end
5'd10: // 发送第2位
begin
O_spi_mosi <= I_data_in[2] ;
O_spi_sck <= 1'b0 ;
R_tx_state <= R_tx_state + 1'b1 ;
O_tx_done <= 1'b0 ;
end
5'd12: // 发送第1位
begin
O_spi_mosi <= I_data_in[1] ;
O_spi_sck <= 1'b0 ;
R_tx_state <= R_tx_state + 1'b1 ;
O_tx_done <= 1'b0 ;
end
5'd14: // 发送第0位
begin
O_spi_mosi <= I_data_in[0] ;
O_spi_sck <= 1'b0 ;
R_tx_state <= R_tx_state + 1'b1 ;
O_tx_done <= 1'b1 ;
end
5'd16: // 增加一个冗余状态
begin
O_spi_sck <= 1'b0 ;
R_tx_state <= 5'd0 ;
O_tx_done <= 1'b0 ;
end
default:R_tx_state <= 5'd0 ;
endcase
end
else if(I_rx_en) // 接收使能信号打开的情况下
begin
O_spi_cs <= 1'b0 ; // 拉低片选信号CS
case(R_rx_state)
4'd0, 4'd2 , 4'd4 , 4'd6 ,
4'd8, 4'd10, 4'd12, 4'd14 : //整合偶数状态
begin
O_spi_sck <= 1'b0 ;
R_rx_state <= R_rx_state + 1'b1 ;
O_rx_done <= 1'b0 ;
end
4'd1: // 接收第7位
begin
O_spi_sck <= 1'b1 ;
R_rx_state <= R_rx_state + 1'b1 ;
O_rx_done <= 1'b0 ;
O_data_out[7] <= I_spi_miso ;
end
4'd3: // 接收第6位
begin
O_spi_sck <= 1'b1 ;
R_rx_state <= R_rx_state + 1'b1 ;
O_rx_done <= 1'b0 ;
O_data_out[6] <= I_spi_miso ;
end
4'd5: // 接收第5位
begin
O_spi_sck <= 1'b1 ;
R_rx_state <= R_rx_state + 1'b1 ;
O_rx_done <= 1'b0 ;
O_data_out[5] <= I_spi_miso ;
end
4'd7: // 接收第4位
begin
O_spi_sck <= 1'b1 ;
R_rx_state <= R_rx_state + 1'b1 ;
O_rx_done <= 1'b0 ;
O_data_out[4] <= I_spi_miso ;
end
4'd9: // 接收第3位
begin
O_spi_sck <= 1'b1 ;
R_rx_state <= R_rx_state + 1'b1 ;
O_rx_done <= 1'b0 ;
O_data_out[3] <= I_spi_miso ;
end
4'd11: // 接收第2位
begin
O_spi_sck <= 1'b1 ;
R_rx_state <= R_rx_state + 1'b1 ;
O_rx_done <= 1'b0 ;
O_data_out[2] <= I_spi_miso ;
end
4'd13: // 接收第1位
begin
O_spi_sck <= 1'b1 ;
R_rx_state <= R_rx_state + 1'b1 ;
O_rx_done <= 1'b0 ;
O_data_out[1] <= I_spi_miso ;
end
4'd15: // 接收第0位
begin
O_spi_sck <= 1'b1 ;
R_rx_state <= R_rx_state + 1'b1 ;
O_rx_done <= 1'b1 ;
O_data_out[0] <= I_spi_miso ;
end
default:R_rx_state <= 4'd0 ;
endcase
end
else
begin
R_tx_state <= 4'd0 ;
R_rx_state <= 4'd0 ;
O_tx_done <= 1'b0 ;
O_rx_done <= 1'b0 ;
O_spi_cs <= 1'b1 ;
O_spi_sck <= 1'b0 ;
O_spi_mosi <= 1'b0 ;
O_data_out <= 8'd0 ;
end
end
endmodule
时序图如下所示:
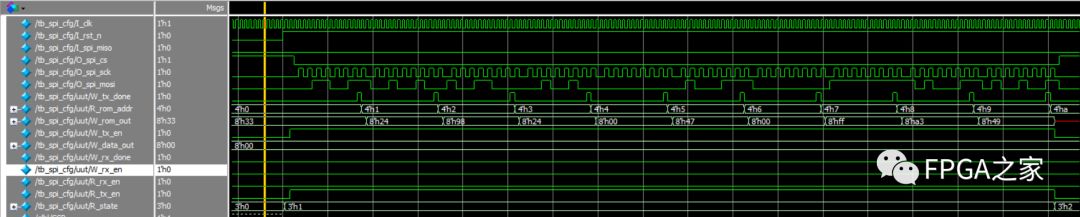
观察上面的时序图可以发现,增加冗余状态以后,ROM里面的10个数据全部发送正确了。最后把代码综合生成bit文件,下载到开发板里面用ChipScope抓出时序图如下所示
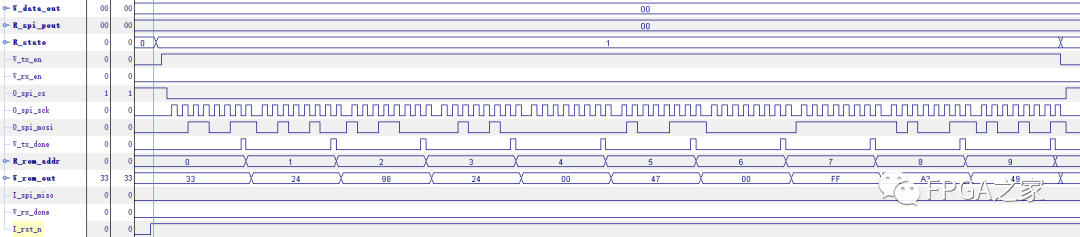
可以看出,时序和用ModelSim得到的一模一样。至此,整个用SPI总线传输ROM里面数据的实验全部结束。
五、 进一步思考
5.1、 如果外设芯片的数据位宽是16-bit或者32-bit怎么办?
上文已经完成了8-bit数据从ROM里面通过SPI发送出去的例子,16-bit和32-bit可以照着葫芦画瓢,无非就是多增加几个状态而已。
5.2、 发送数据的状态机和接收数据的状态机可以用移位的方式来做
事实上那个状态机的发送8-bit数据和接收8-bit数据的部分只有一行代码是不同的,所以也可以用移位的方法来做,然后把偶数状态也可以整合到一起,这样写的代码会更短更精炼。但出于理解更容易的角度,还是分开写较好。
审核编辑:刘清












 工商网监
工商网监
评论