 电子发烧友App
电子发烧友App


0 引言
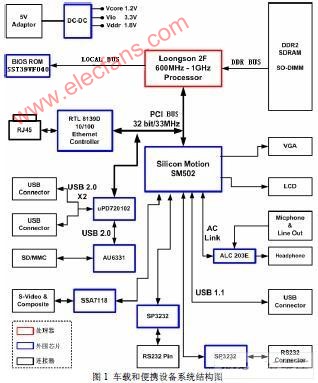
龙芯2F是中国科学院计算技术研究所研制的高性能通用处理器,具有低功耗、低成本以及自主安全的特点,已应用于高性能计算和日常生活领域。
龙芯2F以开源的Linux作为操作系统。Glibe库是Linux系统最底层的运行库,为其上的应用程序提供系统接口以及其它功能函数。此外,它还是以 C语言构建开发程序时使用的基本函数库。本文基于龙芯2F体系结构对Glibc库进行优化,对于提升龙芯2F的平台性能与用户体验有重要意义。
1 Glibc库介绍
Glibc库是GNU发布的C运行库,它封装了Linux操作系统提供的系统服务,除此之外,还提供了其它必要的功能服务实现。Glibc库是Li- nux系统最底层的函数库,是除了操作系统核心以外,所有应用程序赖以执行的基础环境。Linux系统上的其它函数库都需要直接或间接依赖于Glibc 库。
Glibc库包含两类函数,一种是与核心沟通的系统函数,它们封装了系统调用,对传入参数进行预处理之后就转到系统调用来完成功能,其目的是使得用户可以方便地使用操作系统核心提供的服务。系统调用接口与Linux操作系统相关,大部分流程固定,没有太大优化余地,对
其不做处理。
C库中的另一类函数提供常见的通用功能实现,包括标准输入输出控制,字符串处理,正则表达式,字符串加密,查找与排序等。它们提供基本的、与操作系统无关的功能,其中的部分函数有一定的计算量,是优化工作关注的部分。
Glibc库的版本在不断更新,本文以当前最新的Glibc2.11版本为基础进行优化。
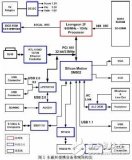
2 龙芯2F体系结构
龙芯2F处理器实现了64位的MIPSⅢ指令集,整数寄存器和浮点寄存器均为64位,支持o32/n32和n64的ABI类型。除了 MIPS标准指令外,龙芯2F还提供了特有的整型计算和浮点计算指令。整型指令包括单条指令对3个寄存器进行操作的乘法、除法以及求模运算,浮点指令包括
乘加、开平方等运算。
龙芯2F包含两级Cache结构,L1 Cache数据和指令独立,均为64kB;L2 Cache数据和指令共享,为512kB。L1 cache和L2 cache都采用四路组相联结构,组内采用随机替换策略,cache行大小均为32字节。
3 Glibc库的优化
根据对Glibc库组成的分析,文章对其中的字符串与内存处理,数据转换,哈希表查找以及加密函数进行了优化,以下各节分别介绍其优化方法和优化效果。
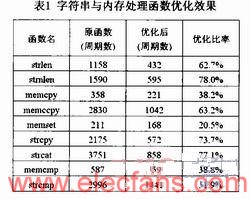
3.1 字符串与内存处理函数
字符串与内存处理函数组提供了较为丰富的函数来完成各种操作,包括字符串与内存的移动、比较和查找等。两者的操作通常一一对应,因为C语言中的字符串即用一段连续的内存来表示,区别在于字符串用空字符NULL来表示结尾,而内存块的结尾由其大小确定。
对本组函数进行分析可知,部分函数之间的实现流程类似,如strlen和strnlen,memcpy和memccpy等。此外某些函数可通过调用其它函数来完成,如strcpy可由strlen与memcpy函数完成。
由于这一特点,字符串与内存处理函数组的优化方法可以相互借鉴,使用的优化方法主要包括以下几种:
优化访存指令。本组函数的处理流程一般是从一个或两个内存地址开始读取内存并进行相应的操作。在读取过程中考虑内存地址的对齐情况及读取单位,分别使用不同格式的访存指令。
分块处理。根据龙芯2F处理器的寄存器个数将待处理的字符串或内存分块,以充分利用寄存器进行循环展开。
汇编实现。本组函数包含了一些使用频繁且对系统性能影响较大的函数,如内存拷贝memcpy函数等,对此类函数我们使用汇编或内嵌汇编来实现,以避免编译器可能生成低效的代码。
表l是本组函数中主要函数的优化效果,以字符串规模或内存大小512B作为输入。
3.2 数据转换函数
数据转换函数包括字符串转换为整数和浮点数。文章分别在每类函数中取一个例子说明优化过程。
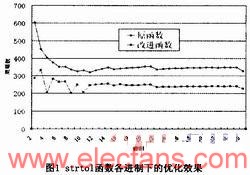
字符串转换为整数包括strtol、strtoul、strtoll等函数,它们分别解析不同的整数类型,支持从2到36的转换进制。各函数实现上不同的地方仅在于不同类型的整数大小范围不同,处理流程类似。下面以strtol函数为例介绍优化过程,它的功能为将字符串转换为long型整数。
Glibc库中strtol的实现使用普通的逐字节读取并计算的方式。我们首先对转换进制分情况处理,对于2的幂次方的进制,如2、4、8、16、32,字符串中的每个数字在二进制位上没有关联。可以将它们逐个转换成二进制位后填入返回值的相应位置,具有较快的转换速度。其次十进制转换是一种常用的情况,也将其单独列出,可以省去对字母进行判断。
给定进制后,在该进制下整数至多有多少位就可以确定。当字符串中的合法数字个数超过位数限制时,直接返回该类型下的最大值即可。当字符串中的合法数字小于位数限制时,可知解析后的结果绝对不会超过该整数类型的表示范围,此时我们将字符串进行分段并对解析进程进行循环展开。如果合法数字个数恰好等于位数限制,此时解析结果有超过该类型下最大值的可能性,首先将小于位数限制的部分解析完成后,再考虑最后一位数字。提前确定解析结果的范围可以避免每次循环内都要对是否超出该类型的最大值进行判断。
取进制从2到36,字符串的长度从1到该进制下的最大值进行测试,得到各进制下的优化效果如图1所示,各进制的平均优化比率为30.9%。
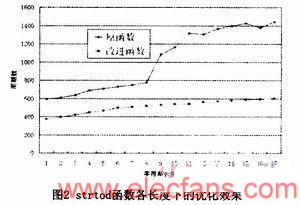
strtod、strtof、strtold等函数将字符串转换为浮点数。我们以strtod函数为例进行介绍,它将字符串转换为double型浮点数。
Glibc库中strtod的实现使用高精度计算。首先遍历整个字符串,找出其中的整数、小数和指数部分,各个部分分别使用高精度计算解析,再将结果合并。对于一般的实现来说,各个部分的取值不会太大,此时使用高精度计算时间消耗较大,改进的实现将每个部分再进行分
块,对每个分块使用整数进行解析,实现方式与strtol相同。各个部分的分块解析完成后,使用一个long double类型作为临时变量合并解析结果以避免精度丢失,最后将该变量转换为doulble类型返回。对于strtof函数,使用double类型作为临时变量。而对于strtold函数,使用上述方法无法保证精度,仍采用原始的实现。
由于双精度浮点数的有效位数为16至17位,对字符串长度从1到17进行测试,得到各长度下的优化效果如图2所示,各长度的平均优化比率为49.8%。
3.3 哈希表查找函数
Glibc库中哈希表所包含的关键字和数据分别为字符串和内存块,其相关的函数包括hcreate,hdestory以及hsearch,分别完成哈希表的创建,销毁和查找。创建与销毁操作都是一次性的,我们对查找操作进行优化。
hsearch函数读入字符串关键字作为参数,首先将其映射为整数关键值,接着使用双重散列逐个取出元素进行判断。
Glibc库中字符串映射为整数的实现方法为,首先求得字符串的长度作为初值,接着将其不断左移4位并从末尾到头部逐个与字符串中的字符相加。该方法需要对字符串进行两次遍历,并且当字符串较长时,字符串的长度和进行累加的前几个字符会被移出而不影响最终的映射值。例如对32位的整型数来说,只有字符串的前8个字符对映射值有影响。
我们使用ELF哈希算法来替换原有的映射实现,此算法不先对字符串求长,仅进行移位和累加操作的循环,为了避免原始实现的缺点,每次循环中都会判断移位是否超出范围,如果超出,则把中间结果的高八位异或到低八位上。该哈希函数只需对字符串遍历一遍,并且考虑了移位越界,避免了只有前几个字符影响映射值的缺陷。
3.4 加密函数
Glibc库中的加密函数为crypt函数,该函数单向加密给定的字符串,支持的算法包括MD5、SHA以及DES算法。由于MD5与DES算法的实现流程固定且做了较充分的展开,因此我们主要考虑SHA算法。针对该算法有设计硬件结构进行的优化,而我们的工作从代码实现角度进行。下面以SHA-256为例说明优化过程,其它SHA算法与之类似。
由于龙芯2F只支持小尾端的字符序,因此SHA算法首先将进行运算的字转换为大尾端。原始实现中使用表达式x=((n<<24)| ((n&0xff00)<<8)|((n>>8)&0xff00)|(n>>24))进行转换,其中n为无符号的 32位整数。该转换操作总共需要两次与,四次移位与三次或运算,我们对其
进行改进,采用二分方的思想,使用表达式n1=(n<<16)|(n>>16)和x=(((n1&0xff00ff00)& gt;>8)|(n1&0xff00ff)<<8))。其中计算n1的表达式可以由编译器编译为一条循环移位指令,这样改进的实现共需要两次与,三次移位与一次或运算,省去了一次移位与两次或运算。
算法接下来的操作是消息扩散与迭代计算,计算公式分别如图3和图4所示。

我们对其计算过程进行层数为2的循环展开。对于迭代计算过程,循环展开之后还可以继续进行赋值传递优化,减少运算量和迭代次数。循环展开层数增加时,循环次数减小,但增加了循环内的计算量,寄存器的数目满足不了中间结果的保存,需要读写内存,反而造成性能的下降。经过实验确定,层数为2是一个较好的选择。
表2是改进前后SHA256算法的性能对比,取数据大小从64B到2kB倍增。

4 总结
Glibc库是Linux系统最底层的运行库,是所有应用程序赖以执行的基础环境。本文基于龙芯2F平台对Glibc库中的字符串与内存处理函数、数据转换函数、哈希表查找函数以及加密函数进行了代码优化,大部分函数的优化比率达到30%以上,对龙芯2F平台的整体运行性能提升具有重要意义。













 工商网监
工商网监
评论