 电子发烧友App
电子发烧友App


只要有网络的地方,你很难不看到路由器的身影,各种低、中、高端的,种类繁多,所具备的功能和内部实现不完全一样。
要知道,路由器不断的在吞吐通信数据,就像鱼吐泡泡一样,通信数据像是路由器的“食物”。
那么,路由器“吃”进去的数据,上哪去了呢?
“鱼儿”吃进去的“食物”,有的会被吸收了,进入血液,最终转换成能量或变为身体的一部分;没被吸收的经过肠道排泄到体外。
“鱼儿”吞进去的大部分是水,这些水基本都吐出来了,并没有被吸收。
同样的,进入路由器的数据,大部分从一个接口进去,从另一个接口出来,它们只是“过路”的业务报文,也有人称之为“过路”报文。
有一小部分数据被“吸收”了,被上送CPU处理,或者因为各种原因中途被丢弃。
今天,就和你分享一篇关于报文在路由器中的处理全过程,帮助你更好的了解路由器内部的原理。
01
在路由器中
报文度过了怎样的一生?
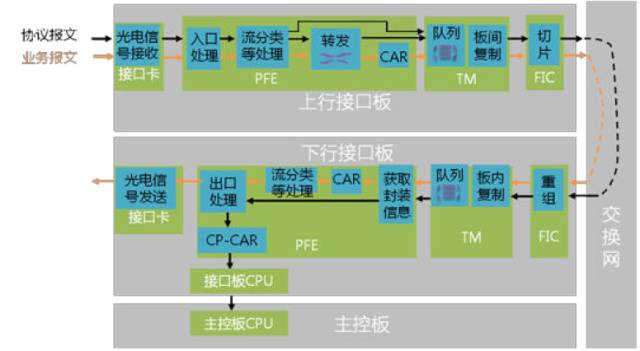
这张图,是路由器收到的业务报文和协议报文在转发层面的处理流程。
这张图,是路由器CPU发送的协议报文的在转发层面的处理流程。
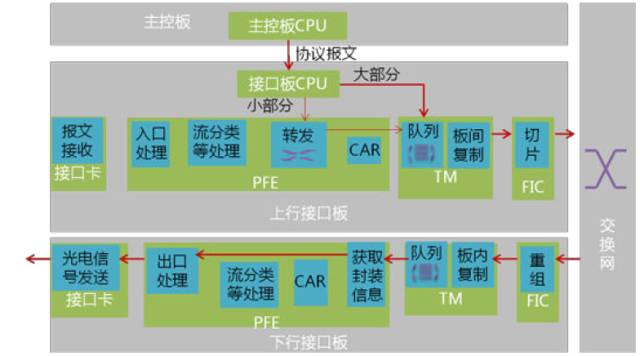
是不是觉得上图太复杂、概念太多,看不懂?
上述图片只是给一个总的概念,以便下面更好的理解。
下面我们先从“交换”谈起:
数据。是通过接口板接收和发送,通信线缆都要插接到接口板的接口上。
那么,把某一个接口来的数据包送到另一个接口发出去,这两个接口需要连起来。
但实际上,数据包可能从任意接口进来,从任意接口出去,都这么点到点连接的话,则需要N*(N-1)/2根线互联,太多了。
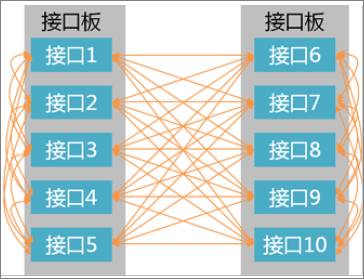
为了解决这种大量连接的问题,接口板和接口板之间需要通过交换网(Switch Fabric)板衔接起来,接口板只要通过若干连线跟交换网板连接,就能完成任意接口的互通。
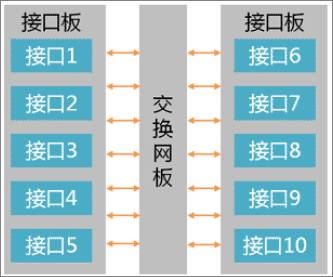
交换网属于“三无”部件,即与设备配置无关、与协议无关、与数据包类型无关。交换网专注于在入接口和出接口之间建立连接,完成数据的交换。
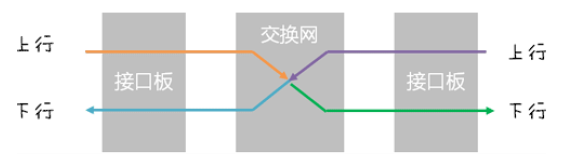
01 上行和下行
以交换网为中心,可将报文在路由器的行程一分为二,前半程称为“上行”,下半程称为“下行”。
02 寻址转发
可能有人会问,报文从一个接口进来,经过“交换”,从另一个接口出去,这个交换机也会做啊,何必用路由器?
是的,交换机也有交换功能。但是,在互联网中,从一个节点到另一个节点,有许许多多的路径。
路由器可以选择通畅的最短的路径,从而提高通信速度,减轻网络负荷,节约网络资源,这是交换机所不具备的能力。
为数据包选择一条合适的(通常指最短的)传输路径,然后从对应的接口发送,这个过程就称为“寻址转发”。
路由器所在的网络几乎都是遵循TCP/IP体系的,路由器是工作在该体系的第三层,即网络层。
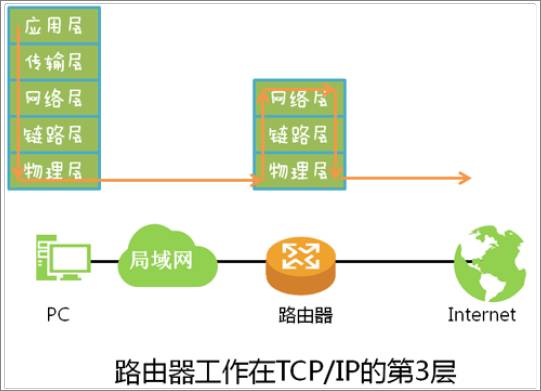
所以,刚才提到的“寻址”的”址“是指根据数据包的网络层地址——IP地址。为了寻址,路由器需要一张“地图”,以目的IP地址为索引的“地图”,也就是路由表。每个路由器中都有一张路由表。
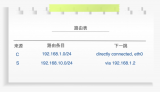
03 路由表长什么样?
这张图是一张实际的地铁出口地图。

实际的路由表跟上图有些相似。
路由表的索引是目的IP地址/掩码,每个表项中都有对应的下一跳IP地址和出接口信息,如下图。
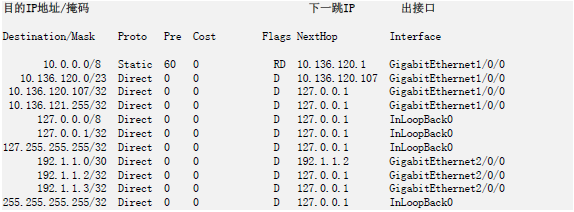
有了这张表,路由器接在收到数据包时就能做到心中有数了。
比如,收到一个目的地址为10.0.0.1的报文,路由器就可以查表得知需要将该报文发送到GE1/0/0这个接口。
04 这个路由表怎么得来的?
一种办法是手工制作,对路由器进行手工设置固定的路由。但是这种路由不能对网络的改变作出反映,如果网络拓扑变化了,需要人工去修改设置。
还有一种办法,就是运行动态路由协议,让路由器之间相互传递路由信息,利用收集到的路由信息进行计算,生成路由表,这样就可以让路由表实时跟进网络拓扑的变化。
在实际应用中,这两个办法都用上了,当动态路由与静态路由发生冲突时,以静态路由为准。
当然,路由表还有一类路由,不是人工配置的,也不是路由协议的学习,而是由链路层协议发现的,称为直连路由。
05 路由表放在哪?
有了路由表,接下来要考虑的是,路由表放哪合适呢?
前面说过,数据包是从某个接口进来,经过交换网,再从另一个接口出去。
那路由表能不能放交换网?答案肯定不行,因为交换网要完成整个设备所有报文的交换,为了让交换网完成高速交换,不成为瓶颈,不能再让交换网去运行路由协议、维护路由表、做寻址转发。
那路由表能不能放下行接口板?
答案也是不行,交换网做交换的时候,就需要知道要送往哪块目的单板,所以寻址转发需要在上行完成。然而,如果把路由表放上行接口板,由于报文可能从任意接口板进来,那么所有的接口板都需要放一个路由表。其实,还有更好的办法,就是将路由表放在一个公共的地方,比如主控板上,由主控板的CPU运行路由协议,计算路由,生成和维护路由表。
06 转发表与路由表
如果路由器采用的是“硬转发”,业务报文不经过主控板CPU处理,不能直接用主控板上的路由表,接口板上也需要有供寻址转发的信息。
所以,主控板CPU生成路由表之后,还要将相关信息下发给各个接口板。
这些相关的信息就是转发信息,存放在各个接口板的转发信息表FIB(Forwarding Information Base)中。
各个接口板上的转发信息都是相同的,因为它们具有相同的来源,都来自主控板。
实际上,现代高性能路由器在架构上都是转发和控制分离:
把转发层面和控制层面分配在不同的组件,控制层面运行路由协议,维护路由表,并下发转发表FIB到转发层面,由转发层面负责数据包转发。
这样做的最基本的好处就是不会相互影响。
如果流量很高导致转发层面高负荷,但是其不会影响控制层面进行正常的路由学习;相反的,如果控制层面对路由信息的处理比较繁忙,也不会影响转发层面进行其高速的数据包转发。
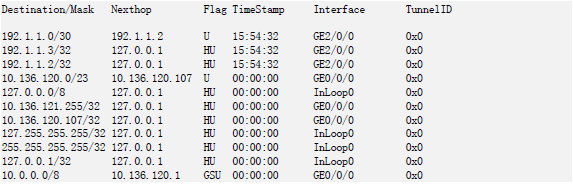
细心的读者会发现,路由表和转发表看起来差不多,都有目的IP地址/掩码、下一跳、出接口这三个信息。
实际上,转发表是根据路由表生成的。路由表中可能包含到达目的地址的多条路由,但是转发表里面只取其中的最优路由。
而且,路由表的下一跳是原始的下一跳,不一定是直接可达的,FIB是用于指导转发的,它的下一跳必须是直接可达。根据“原始下一跳”找到“直接下一跳”的过程就称为“路由迭代”。
路由器上电启动之后,就会运行路由协议学习网络拓扑,生成路由表,如果接口板注册成功,主控板就可以根据路由表生成转发表项并下发给接口板,这样路由器就可以根据转发表转发数据包了。
执行数据包转发的部件是位于接口板上的一个被称为包转发引擎PFE(Packet Forwarding Engine)部件,通常是NP或ASIC芯片。
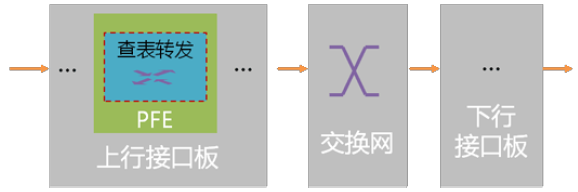
07 找不到路怎么办?
上述这种在转发报文前,提前准备好转发表,待收到报文时再查表转发的方式称为“预路由”,“先铺路,后通车”。现在路由器都采用这种方式进行IP单播转发。
在这种方式中,查表转发时,如果没有匹配上(如果有默认路由,最终会匹配上默认路由,默认路由不存在“不匹配”的情况),意味着这台路由器没有到这个目的地址的路由(或者还没有学习到这个路由),也就是找不到路,迷路了。
数据包迷路了怎么办,原路返回?
想象下,如果迷路了就被原路返回给源端,那源端重发的还是同样的目的地址,那这个报文还是会在同一个地方迷路,再原路返回,死循环了。
所以,数据包迷路了只能被丢弃。出于可维护方面的考虑,包转发引擎PFE会记录丢弃原因和统计丢弃的报文数。
08 预路由与流触发
刚才说到路由器都采用“先铺路,后通车”的预路由方式。相对的,“先通车,后铺路”的方式,被称为“流触发”。
流触发方式中,设备收到报文,查转发表,如果转发表中不存在对应的表项,就根据这个报文生成一个转发表项。
这样,该用户流的下一个报文就可以命中转发表进行转发了。
目前,路由器和交换机在进行二层转发时所使用的MAC表,就是采用MAC地址学习方式,类似于“流触发”方式。
从安全性角度上,流触发显然容易造成流量攻击,为攻击者提供了一个合理合法的攻击路径。
攻击者可以使用各种未知目的报文对系统进行遍历扫描攻击,形成对路由器的流量攻击。
所以,在高端路由器上,除了有MAC学习方式机制外,为了预防流量攻击,还提供了限制MAC地址学习的功能,即限制最多允许学习多少个MAC地址,并限制每次学习的时间间隔;
而且还允许去使能MAC地址学习,允许人们像配置静态路由一样去手工配置MAC表项。
编辑:黄飞










 工商网监
工商网监
评论