 电子发烧友App
电子发烧友App



作者 | 张俊怡
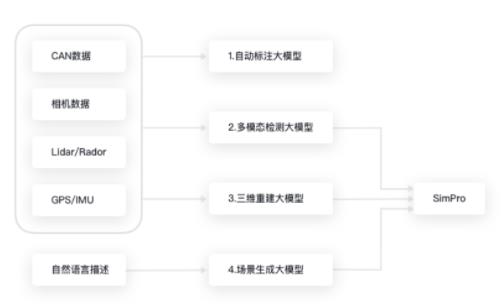
三维重建意义
三维重建作为环境感知的关键技术之一,可用于自动驾驶、虚拟现实、运动目标监测、行为分析、安防监控和重点人群监护等。现在每个人都在研究识别,但识别只是计算机视觉的一部分。真正意义上的计算机视觉要超越识别,感知三维环境。我们活在三维空间里,要做到交互和感知,就必须将世界恢复到三维。所以,在识别的基础上,计算机视觉下一步必须走向三维重建。本文笔者将带大家初步了解三维重建的相关内容以及算法。
三维重建定义
在计算机视觉中, 三维重建是指根据单视图或者多视图的图像重建三维信息的过程. 由于单视频的信息不完全,因此三维重建需要利用经验知识. 而多视图的三维重建(类似人的双目定位)相对比较容易, 其方法是先对摄像机进行标定, 即计算出摄像机的图象坐标系与世界坐标系的关系.然后利用多个二维图象中的信息重建出三维信息。
常见的三维重建表达方式
常规的3D shape representation有以下四种:深度图(depth)、点云(point cloud)、体素(voxel)、网格(mesh)。
深度图其每个像素值代表的是物体到相机xy平面的距离,单位为 mm。
体素是三维空间中的一个有大小的点,一个小方块,相当于是三维空间种的像素。
点云是某个坐标系下的点的数据集。点包含了丰富的信息,包括三维坐标X,Y,Z、颜色、分类值、强度值、时间等等。在我看来点云可以将现实世界原子化,通过高精度的点云数据可以还原现实世界。万物皆点云,获取方式可通过三维激光扫描等。

△三角网格、用三角网格重建
三角网格就是全部由三角形组成的多边形网格。多边形和三角网格在图形学和建模中广泛使用,用来模拟复杂物体的表面,如建筑、车辆、人体,当然还有茶壶等。任意多边形网格都能转换成三角网格。
三角网格需要存储三类信息:
顶点:每个三角形都有三个顶点,各顶点都有可能和其他三角形共享。.
边:连接两个顶点的边,每个三角形有三条边。
面:每个三角形对应一个面,我们可以用顶点或边列表表示面。
三维重建的分类
根据采集设备是否主动发射测量信号,分为两类:基于主动视觉理论和基于被动视觉的三维重建方法。
主动视觉三维重建方法:主要包括结构光法和激光扫描法。
被动视觉三维重建方法:被动视觉只使用摄像机采集三维场景得到其投影的二维图像,根据图像的纹理分布等信息恢复深度信息,进而实现三维重建。
其中,双目视觉和多目视觉理论上可精确恢复深度信息,但实际中,受拍摄条件的影响,精度无法得到保证。单目视觉只使用单一摄像机作为采集设备,具有低成本、易部署等优点,但其存在固有的问题:单张图像可能对应无数真实物理世界场景(病态),故使用单目视觉方法从图像中估计深度进而实现三维重建的难度较大。
近几年代表性论文回顾
-从单张图像恢复深度图

△Depth, NIPS 2014, Cited by 1011
这篇论文思路很简单,算是用深度学习做深度图估计的开山之作,网络分为全局粗估计和局部精估计,对深度由粗到精的估计,并且提出了一个尺度不变的损失函数。
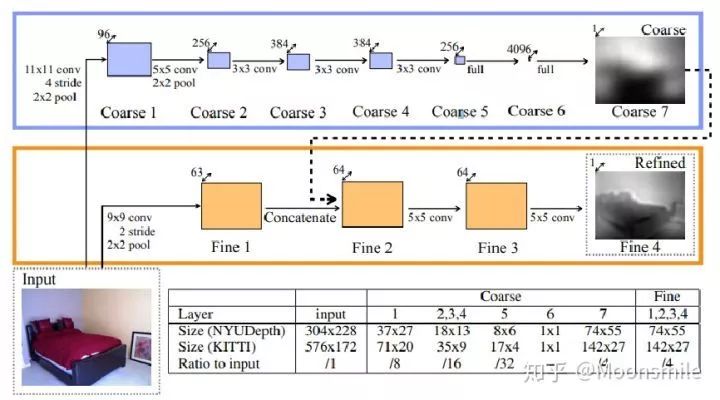
△主体网络

△Scale-invariant Mean Squared Error
本文总结
(1)提出了一个包含分为全局粗估计和局部精估计,可以由粗到精估计的网络。
(2)提出了一个尺度不变的损失函数。
-用体素来做单视图或多视图的三维重建

△Voxel, ECCV 2016, Cited by 342
这篇文章挺有意思,结合了LSTM来做,如果输入只有一张图像,则输入一张,输出也一个结果。如果是多视图的,则将多视图看作一个序列,输入到LSTM当中,输出多个结果。
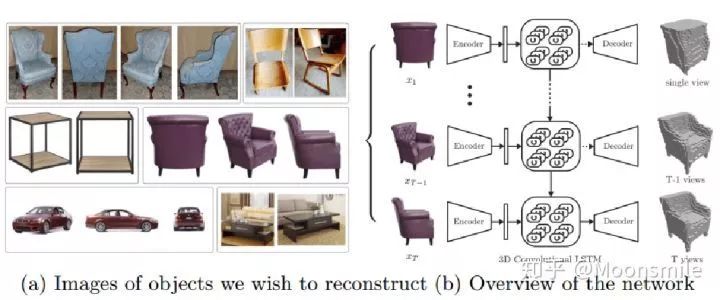
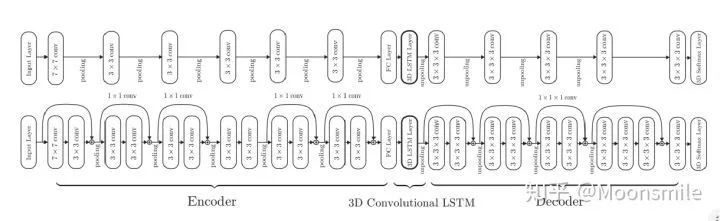
△Framework
如主框架所示,这篇文章采用深度学习从2D图像到其对应的3D voxel模型的映射:
首先利用一个标准的CNN结构对原始input image 进行编码;再利用一个标准 Deconvolution network 对其解码。中间用LSTM进行过渡连接, LSTM 单元排列成3D网格结构, 每个单元接收一个feature vector from Encoder and Hidden states of neighbors by convolution,并将他们输送到Decoder中. 这样每个LSTM单元重构output voxel的一部分。
总之,通过这样的Encoder-3DLSTM-Decoder 的网络结构就建立了2D images -to -3D voxel model 的映射。
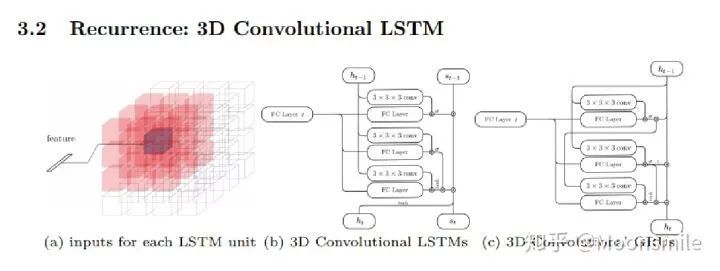
△3D LSTM 和 3D GRU
损失函数采用的是二分类的交叉熵损失,类似于在三维空间做分割,类别是两类,分别是占有或者不占有。

△损失函数
除了交叉熵loss可以用作评价指标,还可以把预测结果跟标签的IoU作为评价指标,如下图所示:

△IoU可作为评价指标

△Single Real-World Image Reconstruction

△Reconstructing From Different Views.
本文总结
(1)采用深度学习从2D图像到其对应的3D voxel模型的映射,模型设计为Encoder+3D LSTM + Decoder。
(2)既适用单视图,也适用多视图。
(3)以体素的表现形式做的三维重建。
(4)缺点是需要权衡体素分辨率大小(计算耗时)和精度大小。
-用点云来做单张RGB图像的三维重建

△Point Cloud, CVPR 2017, Cited by 274
大多数现存的工作都在使用深度网络进行3D 数据采用体积网格或图像集合(几何体的2D视图)。然而,这种表示导致采样分辨率和净效率之间的折衷。在这篇论文中,作者利用深度网络通过单张图像直接生成点云,解决了基于单个图片对象生成3D几何的问题。
点云是一种简单,统一的结构,更容易学习,点云可以在几何变换和变形时更容易操作,因为连接性不需要更新。该网络可以由输入图像确定的视角推断的3D物体中实际包含点的位置。

模型最终的目标是:给定一张单个的图片(RGB或RGB-D),重构出完整的3D形状,并将这个输出通过一种无序的表示——点云(Point cloud)来实现。点云中点的个数,文中设置为1024,作者认为这个个数已经足够表现大部分的几何形状。
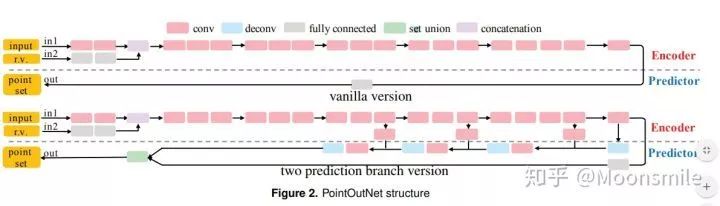
△主框架
鉴于这种非正统的网络输出,作者面临的挑战之一是如何在训练期间构造损失函数。因为相同的几何形状可能在相同的近似程度上可以用不同的点云来表示,因此与通常的L2型损失不同。
本文使用的 loss
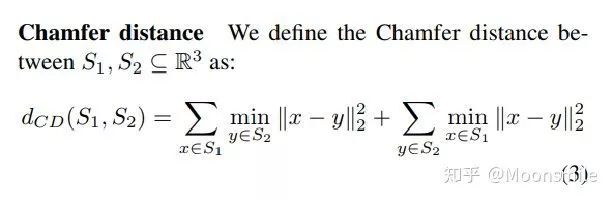
△倒角距离

△搬土距离
对于解决2D图片重构后可能的形状有很多种这个问题,作者构造了一个 Min-of-N loss (MoN) 损失函数。
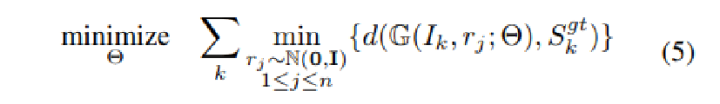
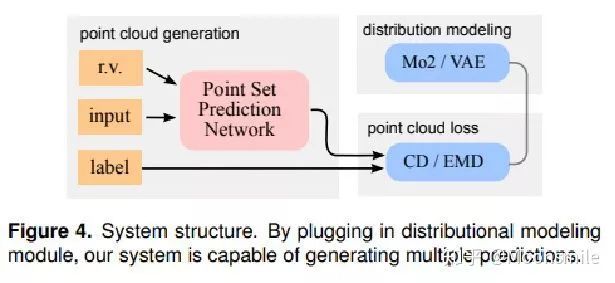
Min-of-N loss 的意思是,网络G通过n个不同的r扰动项进行n次预测,作者认为从直觉上来看,我们会相信n次中会至少有一次预测会非常接近真正的答案,因此可以认为这n次预测与真正的答案的距离的最小值应该要最小。


△实验可视化结果

△实验数值结果
本文总结
该文章的贡献可归纳如下:
(1)开创了点云生成的先例(单图像3D重建)。
(2)系统地探讨了体系结构中的问题点生成网络的损失函数设计。
(3)提出了一种基于单图像任务的三维重建的原理及公式和解决方案。
总体来说,该篇文章开创了单个2D视角用点云重构3D物体的先河,是一篇值得一看的文章。
-先中场休息一下,简单先分析一下:
根据各种不同的表示方法我们可以知道volume受到分辨率和表达能力的限制,会缺乏很多细节;point cloud 的点之间没有连接关系,会缺乏物体的表面信息。相比较而言mesh的表示方法具有轻量、形状细节丰富的特点。

△不同表现形式的对比
Mesh: 我不是针对谁,我是想说在座的各位都是垃圾(depth、volume、point cloud)
由于后边的内容使用了图卷积神经网络(GCN),这里简要介绍一下:

f(p,l), f(p,l+1)分别表示顶点p在卷积操作前后的特征向量;
N(p)指顶点p的邻居节点;
W1,W2表示待学习的参数;
-用三角网格来做单张RGB图像的三维重建

△Mesh, ECCV 2018, cited by 58
这篇文章提出的方法不需要借助点云、深度或者其他更加信息丰富的数据,而是直接从单张彩色图片直接得到 3D mesh。
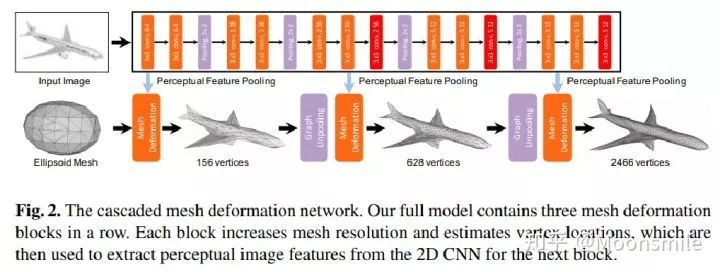
△主框架
1、给定一张输入图像:Input image
2、为任意的输入图像都初始化一个椭球体作为其初始三维形状:Ellipsoid Mesh
整个网络可以大概分成上下两个部分:
(1)上面部分负责用全卷积神经网络提取输入图像的特征;
(2)下面部分负责用图卷积神经网络来表示三维mesh,并对三维mesh不断进行形变,目标是得到最终的输出(最后边的飞机)。
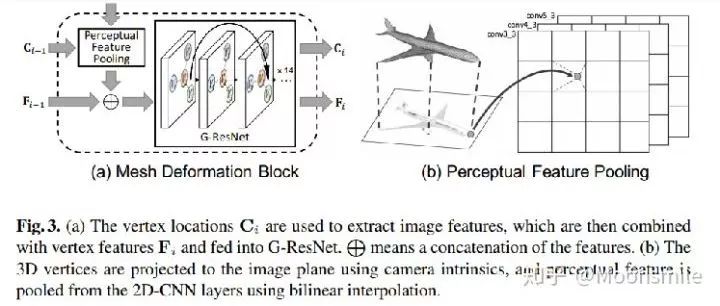
△主框架中的部分内容详细的解释
1、C表示三维顶点坐标,P表示图像特征,F表示三维顶点特征;
2、perceptual feature pooling层负责根据三维顶点坐标C(i-1)去图像特征P中提取对应的信息;
3、以上提取到的各个顶点特征再与上一时刻的顶点特征F(i-1)做融合,作为G-ResNet的输入;
4、G-ResNet(graph-based ResNet)产生的输出又做为mesh deformable block的输出,得到新的三维坐标C(i)和三维顶点特征F(i)。
除了刚刚提到的mesh deformation,下面这部分还有一个很关键的组成是graph uppooling。文章提出这个图上采样层是为了让图节点依次增加,从图中可以直接看到节点数是由156-->628-->2466变换的,这其实就是coarse-to-fine的体现,如下图:
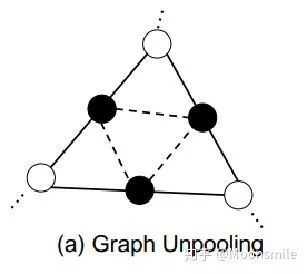
这篇文章定义了四种loss来约束网格更好的形变:


△loss
本文的实验结果


本文总结
该文章的贡献可归纳如下:
(1)文章实现用端到端的神经网络实现了从单张彩色图直接生成用mesh表示的物体三维信息;
(2)文章采用图卷积神经网络来表示3D mesh信息,利用从输入图像提到的特征逐渐对椭圆尽心变形从而产生正确的几何形状;
(3)为了让整个形变的过程更加稳定,文章还采用coarse-to-fine从粗粒度到细粒度的方式;
(4)文章为生成的mesh设计了几种不同的损失函数来让整个模型生成的效果更加好;
文章的核心思路就是给用一个椭球作为任意物体的初始形状,然后逐渐将这个形状变成目标物体。
接下来介绍2019年的相关研究
由于相关内容涉及到mask-rcnn,先回顾一下:
mask-rcnn是对 faster rcnn 的扩展或者说是改进,其增加了一个用于分割的分支,并且将RoIpooling 改成了 RoIAlign。
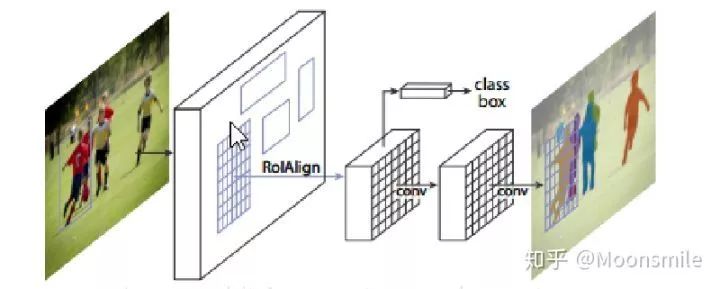
△mask rcnn
Mask RCNN可以看做是一个通用实例分割架构;。
Mask RCNN以Faster RCNN原型,增加了一个分支用于分割任务。
Mask RCNN比Faster RCNN速度慢一些,达到了5fps。
可用于人的姿态估计等其他任务;
-首先介绍一篇2019年做三维重建的文章
——Mesh R-CNN
这篇文章使用的正是mask rcnn 的框架,本篇文章提出了一种基于现实图片的物体检测系统,同时为每个检测物体生成三角网格给出完整三维形状。文中的系统mesh-rcnn是基于mask-rcnn的增强网络,添加了一个网格预测分支,通过先预测转化为物体的粗体素分布并转化为三角形网格表示,然后通过一系列的图卷积神经网络改进网格的边角输出具有不同拓扑结构的网格。

△基本的pipeline
模型目标:输入一个图像,检测图像中的所有对象,并输出所有对象的类别标签,边界框、分割掩码以及三维三角形网格。
模型主框架基于mask-rcnn,使用一个额外的网格预测器来获得三维形状,其中包括体素预测分支和网格细化分支。先由体素预测分支通过预选框对应的RoIAlign预测物体的粗体素分布,并将粗体素转化为初始的三角形网格,然后网格细化分支使用作用在网格顶点上的图卷积层调整这个初始网格的定点位置。总框架图如下所示:
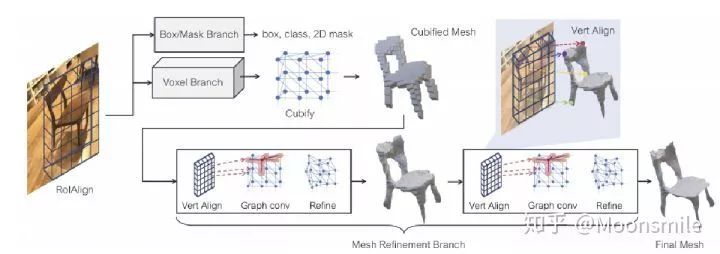
△总框架图
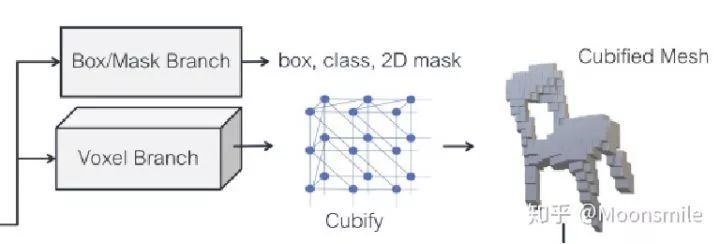
△分支细节
1、Box/Mask 分支: 和mask-rcnn中的两个分支一样。
2、体素预测分支:类似于mask-rcnn中的mask分支,输入是RoIAlign,将预选框假设位于一个分割成 G*G*G个粗体素的空间,然后预测分割出来的粗体素占用率。使用一个小的全卷积网络来保持输入特征和体素占用预测概率之间的对应关系。最后输出用G个通道生成G*G的特征图,为每个位置提供一列体素占用率分数。
3、体素占用转化为网格表示:将体素占用概率转化为二值化体素占用之后,将每个被占用的体素被替换为具有8个顶点、18个边和12个面的立方体三角形网格(如上图Cubify所示),然后合并相邻占用体元之间的共享顶点和边,消除共享内面就可以形成了一个拓扑结构依赖于体素预测的密集网格了。
网格细化分支
网格细化分支将初始的网格结构经过一系列精化阶段(在文中作者使用了三个阶段)来细化里面的顶点位置。每个精化阶段都是输入一个三角形网格),然后经过三个步骤获得更精细的网格结构:顶点对齐(获得顶点位置对应的图像特征);图卷积(沿着网格边缘传播信息);顶点细化(更新顶点位置)。网络的每一层都为网格的每个顶点维护一个三维坐标以及特征向量。
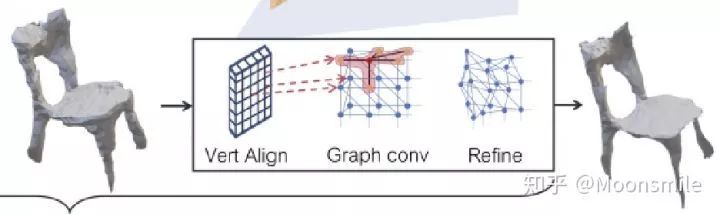
△网格细化分支
1、顶点对齐:利用摄像机的内在矩阵将每个顶点的三维坐标投影到图像平面上。
根据获取的RoIAlign,在每个投影的顶点位置上计算一个双线性插值图像特征来作为对应顶点的图像特征。
2、图卷积:图卷积用于沿着网格边缘传播顶点信息,公式定义如下:
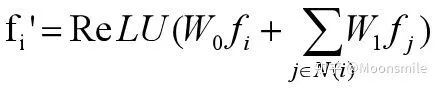
其中N(i)表示顶点i的邻点集合,使用多个图卷积层在局部网格区域上聚合信息。
3、顶点精化:使用2中更新后的顶点特征使用下面公式来更新顶点位置:
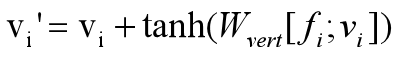
只更改顶点位置,不更改三角形平面。
模型损失函数

网格细化损失(从三个方面定义了三个损失函数)

论文实验
论文在两个数据集上验证模型:在ShapeNet数据集上对网格预测器进行了基准测试与最先进的方法进行比较并且对模型中的各个模块进行单独分析;在Pix3D数据集上测试完整Mesh R-Cnn模型在复杂背景下的物体三维网格预测结果。

在ShapeNet数据集:Mesh R-Cnn与其他的模型比较结果如图下:
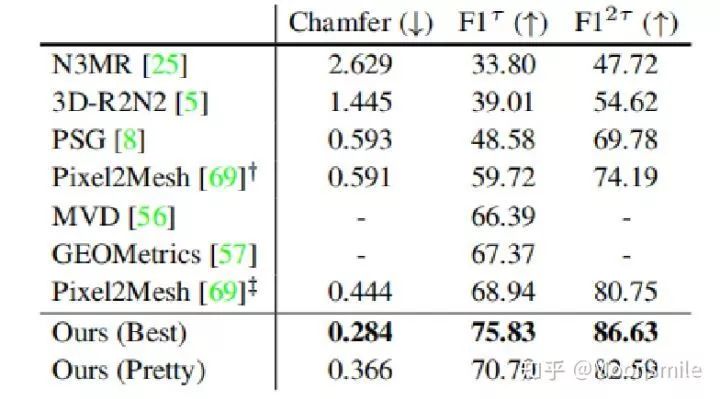
其中Ours(Best)表示去掉形状正则化损失后的结果,在后面的实验中可以发现,去掉形状正则化损失后尽管在标准度量上有好的表现,但是在视觉层面上生成的网格并不如加上后的结果(Ours(Pretty))。
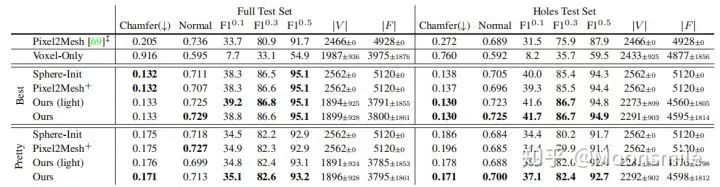
表格中比较了模型的完整版本以及不同去除模块版本的表现:
其中Full Test Set表示在完整测试集上的表现;
Holes Test Set表示在打孔对象测试集中的表现;
Voxel-Only表示不适用网格细化分支;
Best和Perry分别表示不使用形状正则化损失和使用形状正则化损失;
Ours(light)表示在网格细化分支中使用较轻量的非残差架构。
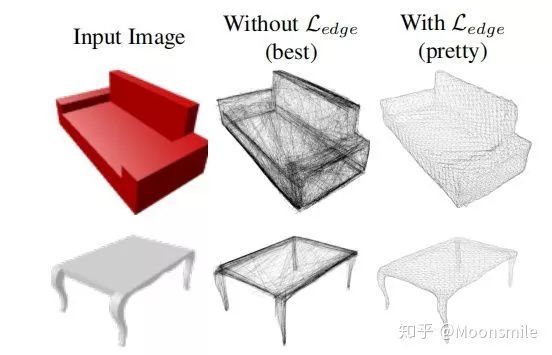
尽管不使用边长正则化器的训练结果在标准度量中有更好的表现,但是会产生退化的预测网格,会导致输出的网格出现许多重叠的面。

对比Pixel2Mesh模型,Pixel2Mesh模型的输出结果是从一个标准椭圆变形得到的,不能正确地建模有孔的物体。相反,Mesh R-Cnn可以对任意拓扑结构的物体进行建模。
Pix3D数据集


可视化结果


本文总结
该文章的贡献可归纳如下:
(1)借鉴mask rcnn 框架;
(2)由粗到细调整的思想;
(3)使用图卷积神经网络;
(4)使用多种损失来约束训练;
-最后介绍一篇论文,也是CVPR 2019的文章

△CVPR 2019, cited by 0
这篇文章同样是既可以对单视图,也可以对多视图进行重建,只不过这篇文章的重点不在这,而在于它可以对不可见部分(不确定性)进行建模。
基本思想就是,每个输入图像都可以预测出多个重建结果,然后取交集就是最终结果。

下图是主框架,左边是训练阶段,右边是测试阶段。
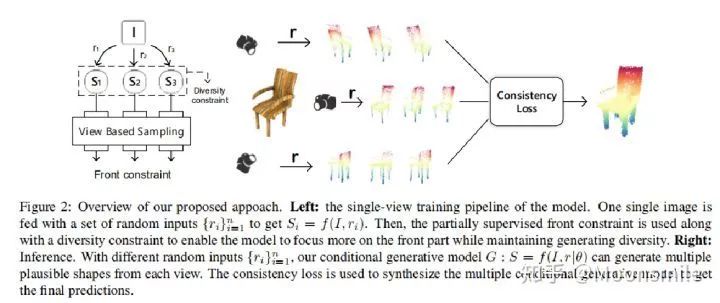
△主框架
左边训练阶段的意思是,输入一张图像 I,对其加入多个噪声(r),生成多个重建结果(S)(类似于条件生成模型)。对改模型的训练要加约束,这里提出了front constraint和diversity constraint。
右边是测试阶段,提出了一个一致性损失(consistency loss)来进行在线优化。
Distance Metric:
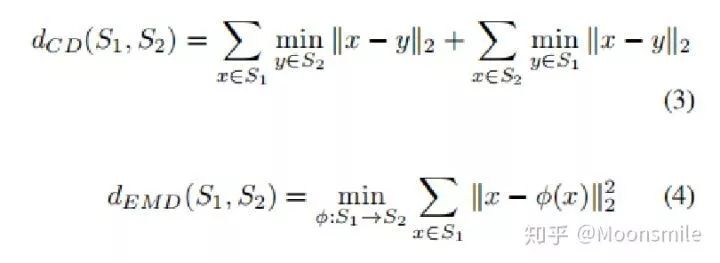
△度量距离(这篇文章是基于点云做的,所以需要用度量距离衡量两个点云集的距离)
Diversity Constraint: 目的是让条件生成器生成的重建结果更具有多样性。
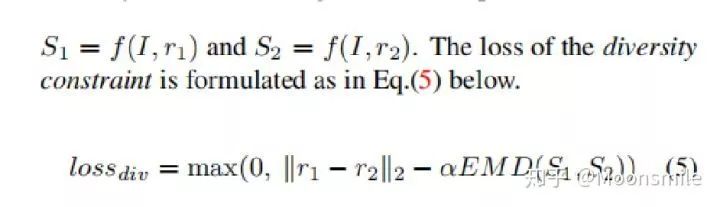
△Diversity Constraint:
Front Constraint: 对图像前边部分(部分点)有监督训练,所以这里有一个采样过程,具体内容如
下图所示:
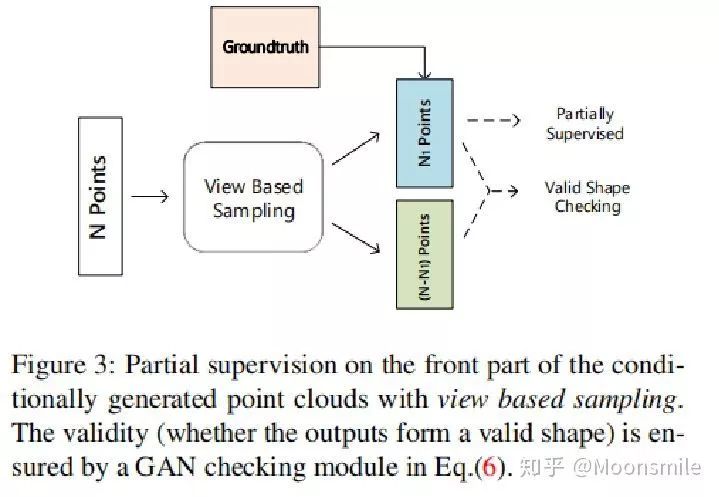

△Front Constraint、对Front Constraint采样部分解释
对于条件生成器生成的结果,用一个判别器去判断这个形状是否合理,公式如下:
Latent Space Discriminator(判别器是直接从WGAN-GP中拿来的)
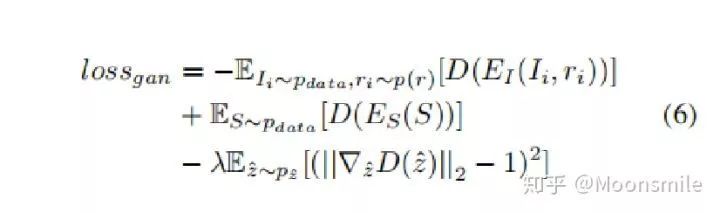
△判别器
训练总的损失:
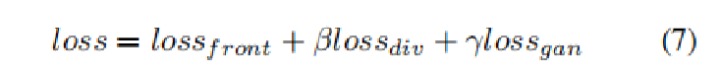
Inference (consistency constraint):
公式中Si 和 Sj 代表两个点云集合。
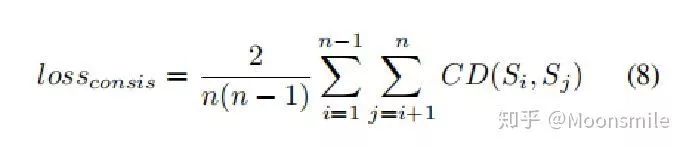
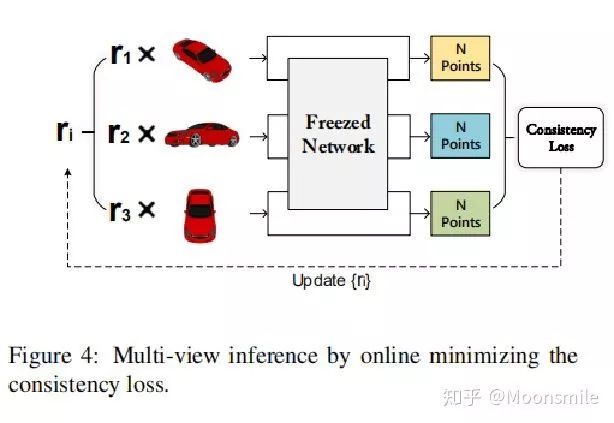
△consistency constraint
条件生成器的结构:
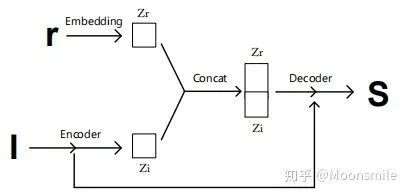
△简约版本
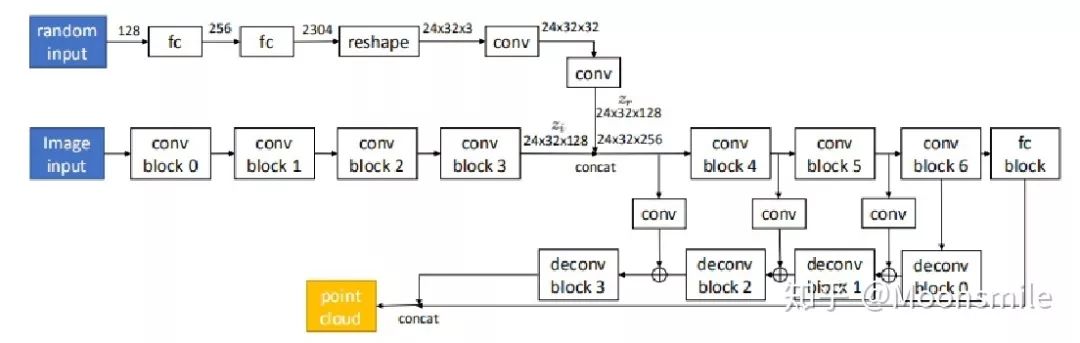
△详细版本
实验结果:




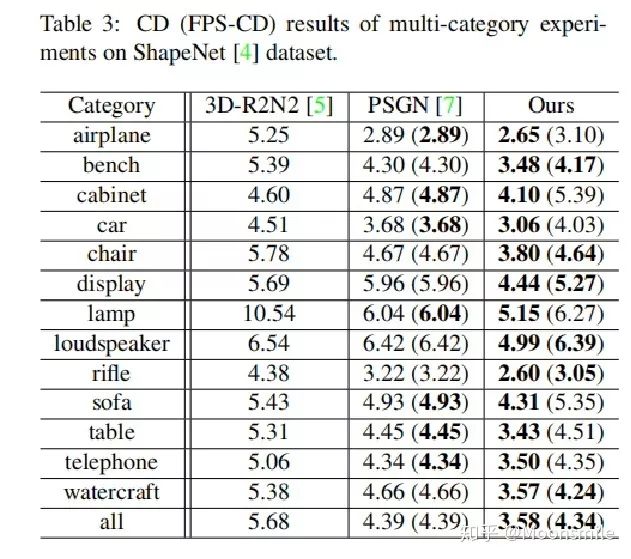
本文总结
该文章的贡献可归纳如下:
(1)提出对不可见部分的不确定性进行建模;
(2)使用了条件生成模型;
(3)提出了三种约束;
编辑:黄飞













 工商网监
工商网监
评论