 电子发烧友App
电子发烧友App


从我们的直观感受来讲,对于任何服务,只要在中间增加了一层,肯定会对服务性能造成影响。那么到底会影响什么呢?在考察一个服务性能的时候,有两个最重要的指标,那就是吞吐和延迟。吞吐定义为服务端单位时间内能处理的请求数,延迟定义为客户端从发出请求到收到请求的耗时。中间环节的引入我们首先想到的就是那会增加处理时间,这就会增加服务的延迟,于是顺便我们也会认为吞吐也会下降。从单个用户的角度来讲,事实确实如此,我完成一个请求的时间增加了,那么我单位时间内所能完成的请求量必定就减少了。然而站在服务端的角度来看,虽然单个请求的处理时间增加了,但是总的吞吐就一定会减少吗?
接下来我们就来对redis来进行一系列的测试,利用redis自带的redis-benchmark,分别对set和get命令;单个发送和批量发送;直连redis和连接redis代理predixy。这样组合起来总共就是八种情况。redis-benchmark、redis是单线程的,predixy支持多线程,但是我们也只运行一个线程,这三个程序都运行在一台机器上。
项目 内容
CPU AMD Ryzen 7 1700X Eight-Core Processor 3.775GHz
内存 16GB DDR4 3000
OS x86_64 GNU/Linux 4.10.0-42-generic #46~16.04.1-Ubuntu
redis 版本3.2.9,端口7200
predixy 版本1.0.2,端口7600
八个测试命令
测试命令 命令行
redis set redis-benchmark -h xxx -p 7200 -t set -r 3000 -n 40000000
predixy set redis-benchmark -h xxx -p 7600 -t set -r 3000 -n 40000000
redis get redis-benchmark -h xxx -p 7200 -t get -r 3000 -n 40000000
predixy get redis-benchmark -h xxx -p 7600 -t get -r 3000 -n 40000000
redis 批量set redis-benchmark -h xxx -p 7200 -t set -r 3000 -n 180000000 -P 20
predixy 批量set redis-benchmark -h xxx -p 7600 -t set -r 3000 -n 180000000 -P 20
redis 批量get redis-benchmark -h xxx -p 7200 -t get -r 3000 -n 420000000 -P 20
predixy 批量get redis-benchmark -h xxx -p 7600 -t get -r 3000 -n 220000000 -P 20
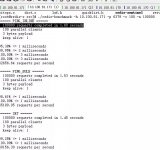
以上8条命令采取redis-benchmark默认的50个并发连接,数据大小为2字节,指定3000个key,批量测试时一次发送20个请求。依次间隔2分钟执行以上命令,每一个测试完成时间大约4分钟。最后得到下图的总体结果:
眼花缭乱是不是?左边的纵轴表示CPU使用率,右边的纵轴表示吞吐。其中redis used表示redis总的CPU使用率,redis user表示redis CPU用户态使用率,redis sys表示redis CPU内核态使用率,其它类推。先别担心分不清里面的内容,下面我们会一一标出数值来。在这图中总共可以看出有八个凸起,依次对应我们上面提到的八个测试命令。
1 redis set测试
2 predixy set测试
3 redis get测试
4 predixy get测试
5 redis 批量set测试
















 工商网监
工商网监
评论