 电子发烧友App
电子发烧友App


1 引言
利用数字信号处理器(DSP)来进行模拟信号的处理同时具有很大的优越性,其主要表现有精度高,灵活性大,可靠性好等方面。它不但可以广泛应用于通信系统、图形/图像处理、雷达声纳、医学信号处理等实时信号处理领域。而且随着人们对实时信号处理要求的不断提高和大规模集成电路技术的迅速发展,数字信号处理器也发生着日新月异的变革。就AD公司而言,继16-bit定点ADSP21xx和32-bit浮点ADSP21xxx系列之后,日前又推出了ADSP Tiger SHARC系列的新型器件。这种Tiger SHARC系列器件是基于AD2106x的下一代高性能芯片,其内部集成有更大容量的RAM,它可以在单周期内执行4条指令,且可以很方便地实现多片并行处理系统的扩展,这些新添的特性更增加了高速实时信号处理的可行性。本文将介绍该系列中的TS101S芯片,以及利用该芯片实现FBLMS?Frequency-domain Block LMS?算法的自适应预测滤波的设计方法。此外,笔者还在EZ-KIT开发板上测试通过并验证了该算法抑制同频窄带信号对雷达干扰的有效性。

2 TS101S系统器件的结构性能
2.1 结构特点
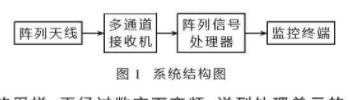
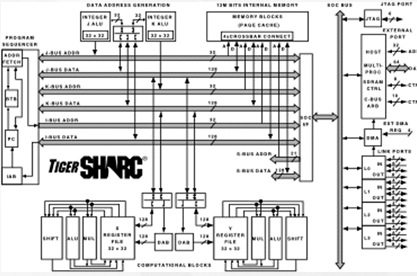
TS101S的系统结构逻辑框图如图1所示。TS101S依旧采用超级哈佛结构(SHARC),并运用流水线技术,目前可以达到8级流水线(3级取指5级执行),其结构特点如下:
●具有特殊的指令集和较长的指令字,一个指令字可以同时控制芯片内多个功能单元的操作;
●片内集成有可由用户自己定义的6Mbit大容量SRAM存储器;
●具有2个独立的计算单元,每个单元都有算术逻辑单元、乘法器、移位器、寄存器组及相关的数据对齐缓冲器,并可通过加速器支持Trellis解码?如,Viterbi和Turbo解码?和复数相关运算;
●带有两个Integer ALU,每个IALU含有两个通用寄存器组,因而具有强大的地址产生能力,可支持环形缓冲和位反序寻址;
●支持SIMD操作。

2.2 主要性能
TS101S具有极高的处理能力,它采用静态超标量结构,既有超标量处理器所具备的大容量指令缓冲池和指令跳转预测功能,又可以在程序执行前就对指令级进行并行操作并用编译器预测出来。TS101S的其它重要性能指标如下:
●指令周期为4ns(主频250MHz)?运算能力达到250MIPS;
●DSP每周期能执行4条指令,具有24个16-bit定点运算和6个浮点运算能力,能提供1500MIPS或6.0GOPS的性能;
●每周期可实现8×16 bit乘与40 bit累加或者2×16 bit乘与80 bit累加;
●支持32 bit IEEE浮点数据和8 bit/16 bit/32 bit/64 bit定点数据格式。
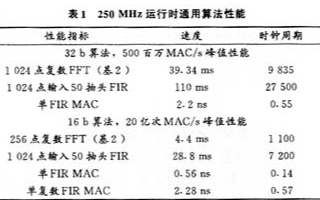
TS101的其它典型性能指标如表1所列。
表1 250M运行时通用算法性能
| 性能指村 | 速 度 | 时钟周期 |
| 32-bit处,500百万MACs/s峰值性能 | ||
| 1024点复数FFT(基2) | 39.34μs | 9835 |
| 1024点输入50抽头FIR | 110μs | 27500 |
| 单FIR MAC | 2.2ns | 0.55 |
| 16-bit算法,20亿次MACs/s峰值性能 | ||
| 256点复数FFT(基2) | 4.4μs | 1100 |
| 1024点输入50抽头FIR | 28.8μs | 7200 |
| 单FIR MAC | 0.56ns | 0.14 |
| 单复数FIR MAC | 2.28ns | 0.57 |
雷达信号处理一般需要很高的实时性,比如在干扰抑制算法处理时,必须在一个回波脉冲周期内完成相关算法。由上述分析可知,TS101S可以满足高速实时数字信号处理的要求。下面以TS101S实现FBLMS自适应算法抑制同频窄带信号对雷达的干扰为例进一步介绍该芯片。
3 FBLMS算法分析与实现
自适应过程一般采用典型LMS自适应算法,但当滤波器的输入信号为有色随机过程时,特别是当输入信号为高度相关时,这种算法收敛速度要下降许多,这主要是因为输入信号的自相关矩阵特征值的分散程度加剧将导致算法收敛性能的恶化和稳态误差的增大。此时若采用变换域算法可以增加算法收敛速度。变换域算法的基本思想是:先对输入信号进行一次正交变换以去除或衰减其相关性,然后将变换后的信号加到自适应滤波器以实现滤波处理,从而改善相关矩阵的条件数。因为离散傅立叶变换?DFT?本身具有近似正交性,加之有FFT快速算法,故频域分块LMS?FBLMS?算法被广泛应用。
FBLMS算法本质上是以频域来实现时域分块LMS算法的,即将时域数据分组构成N个点的数据块,且在每块上滤波权系数保持不变。其原理框图如图2所示。FBLMS算法在频域内可以用数字信号处理中的重叠保留法来实现,其计算量比时域法大为减少,也可以用重叠相加法来计算,但这种算法比重叠保留法需要较大的计算量。块数据的任何重叠比例都是可行的,但以50%的重叠计算效率为最高。对FBLMS算法和典型LMS算法的运算量做了比较,并从理论上讨论了两个算法中乘法部分的运算量。本文从实际工程出发,详细分析了两个算法中乘法和加法的总运算量,其结果为:
复杂度之比=FBLMS实数乘加次数/LMS实数乘加次数=(25Nlog2N+2N-4)/[2N(2N-1)]?
采用ADSP的C语言来实现FBLMS算法的程序如下:
for(i=0;i<=30;i++)
{for(j=0;j<=n-1;j++)
{in[j]=input[i×N+j;]
rfft(in,tin,nf,wfft,wst,n);
rfft(w,tw,wf,wfft,wst,n);
cvecvmlt(inf,wf,inw,n);
ifft(inw,t,O,wfft,wst,n);
for(j=0,j<=N-1;j++)
{y[i×N+j]=O[N+j].re;
e[i×N+j]=refere[i×N+j]-y[i×N+j];
temp[N+j]=e[i×N+j;}
rfft(temp,t,E,wfft,wst,n);
for(j=0;j<=n-1;j++)
{inf_conj[j]=conjf(inf[j]);}???
cvecvmlt(E,inf_conj,Ein,n);
ifft(Ein,t,Ein,wfft,wst,n);
for(j=0;j<=N-1;j++)
{OO[j]=Ein[j].re;
w[j]=w[j]+2*u*OO[j];}??
}
在EZ-KIT测试板中,笔者用汇编语言和C语言程序分别测试了典型LMS算法的运行速度,并与FBLMS算法的C语言运行速度进行了比较,表2所列是其比较结果,从表2可以看出滤波器阶数为64时,即使是用C语言编写的FBLMS算法也比用汇编编写的LMS算法速度快20%以上,如果滤波器的阶数更大,则速度会提高更多。
表2 FBLMS和LMS算法在运行速度比较
| 算 法 | 条 件 | 时钟周期 | 速度 |
| LMS-ASM | 1024点实数据,64阶 | 1257493 | 5.030ms |
| LMS-C | 1024点实数据,64阶 | 8394862 | 33.579ms |
| FBLMS-C | 1024点实数据,64阶 | 986524 | 3.946ms |











 工商网监
工商网监
评论