对于基于锁存器的设计,静态时序分析会应用一个称为时间借用的概念。本篇博文解释了时间借用的概念,若您的设计中包含锁存器且时序报告中存在时间借用,即可适用此概念。
2025-12-31 15:25:51 4740
4740 
在电商领域,精准的销售预测直接影响库存管理、营销策略和资金周转效率。本文将介绍如何基于淘宝API数据构建销售预测模型,并通过代码实现全流程分析。 1. 数据采集与预处理 通过淘宝开放API获取
2025-12-31 09:46:3578 
这些API进行粉丝数据分析,并基于分析结果制定增强用户粘性的策略。 一、 拼多多用户API概览 拼多多开放平台提供了丰富的API接口,涵盖商品、交易、用户、物流等多个维度。对于粉丝数据分析,以下几个API尤为关键: 粉丝明细查询接口
2025-12-30 10:38:3441 大数据解决方案实施的难点在于以下几点: 1.很少有优质可用的数据 在数聚股份看来,这几年数据交易机构如雨后春笋,“数据变现”成为很多拥有数据积累的传统企业的新的生财法。目前,我国大数据需求端以
2025-12-25 18:22:29927 在竞争激烈的电商领域,数据已成为驱动增长的核心引擎。淘宝作为国内领先的电商平台,其开放的数据分析API为商家提供了强大的工具,能够深入挖掘用户行为,并基于这些洞察做出更精准、更有效的营销决策
2025-12-25 14:12:21105 在数聚股份看来,大数据可视化是进行各种大数据分析的最重要组成部分之一。 一旦原始数据流被以图像形式表示时,以此做决策就变得容易多了。 为了满足并超越客户的期望,大数据可视化工具应该具备这些特征
2025-12-24 17:05:03115 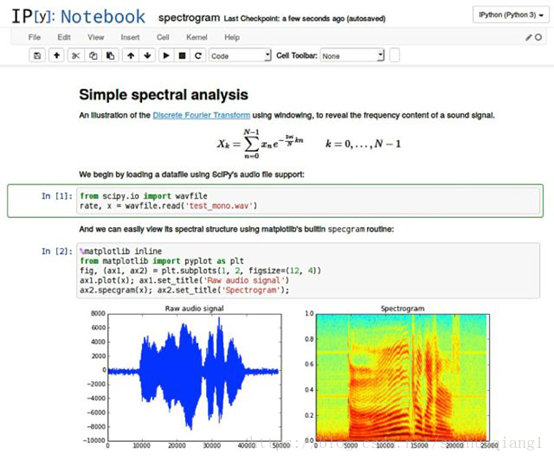
在数聚股份看来,越来越多的企业开始搭建自己的大数据平台体系,并倾注大量资源用于平台的迭代和运营。那么大数据平台作为越来越被关注的企业新兴价值点,它应该以何种方式看待,并且以什么样的方式去建设和运营
2025-12-23 16:07:2095 产品别称:电力气象灾害监测与预测预警系统、架空输电线路微气象监测装置、多维微气象监测装置、输电线路微气象数据分析系统一、行业动态:气象灾害成电网安全主要威胁近年来,随着全球气候变化加剧,极端天气
2025-12-10 11:18:41
在数聚股份看来,大数据变现是大数据热潮中最现实的话题之一。 西班牙电信、沃达丰电信、DHL等企业在大数据变现方面率先开始了探索,以下为大家呈现他们在这一领域的4种创意和途径。 西班牙电信:开发
2025-12-08 16:37:41327 在数聚股份看来,提起经营数据分析,大家往往会联想到一些密密麻麻的数字表格,或是高级的数据建模手法,再或是华丽的数据报表。其实,“ 分析 ”本身是每个人都具备的能力,对于业务决策者而言,则需要掌握一套
2025-12-05 16:31:52535 线缆、橡胶塑料行业)通常不标配软件,可将数据传输到计算机上进行存储,这样配置简单且降低成本,但钢铁行业或大直径产品检测对数据分析有较高的要求,则可增加工控机及测控软件,实现尺寸监控、超差报警(上超差
2025-12-03 14:10:40
京东商品评论API是京东开放平台提供的接口,允许开发者通过商品ID获取该商品的用户评论数据。这些数据对于电商数据分析、竞品调研和商品推荐系统构建具有重要价值。 一、接口概述 1.核心功能 评论获取
2025-11-21 10:29:58140 导语: 在电商数据分析和竞品研究领域,商品评论数据蕴藏着巨大的价值。对于淘宝这个国内领先的电商平台,如何高效、合规地获取其商品评论信息,是许多开发者和数据分析师关注的问题。本文将探讨几种可能
2025-11-07 14:09:20234 近日,数据分析领域被一则消息推上风口浪尖:一家老牌软件巨头将撤出中国。在此背景下,其旗下以灵活著称的数据分析软件,在中国市场的未来将面临极大的不确定性。
2025-11-07 10:39:06544 行业的高质量发展。 二、行业痛点 数据孤岛现象严重:纺织工厂内设备种类繁多,系统建设时间不一,导致数据分散在各个独立系统中,难以实现集中共享与分析。 数据分析能力不足:传统纺织工厂缺乏高效的数据分析工具与方法,难
2025-11-04 10:46:17212 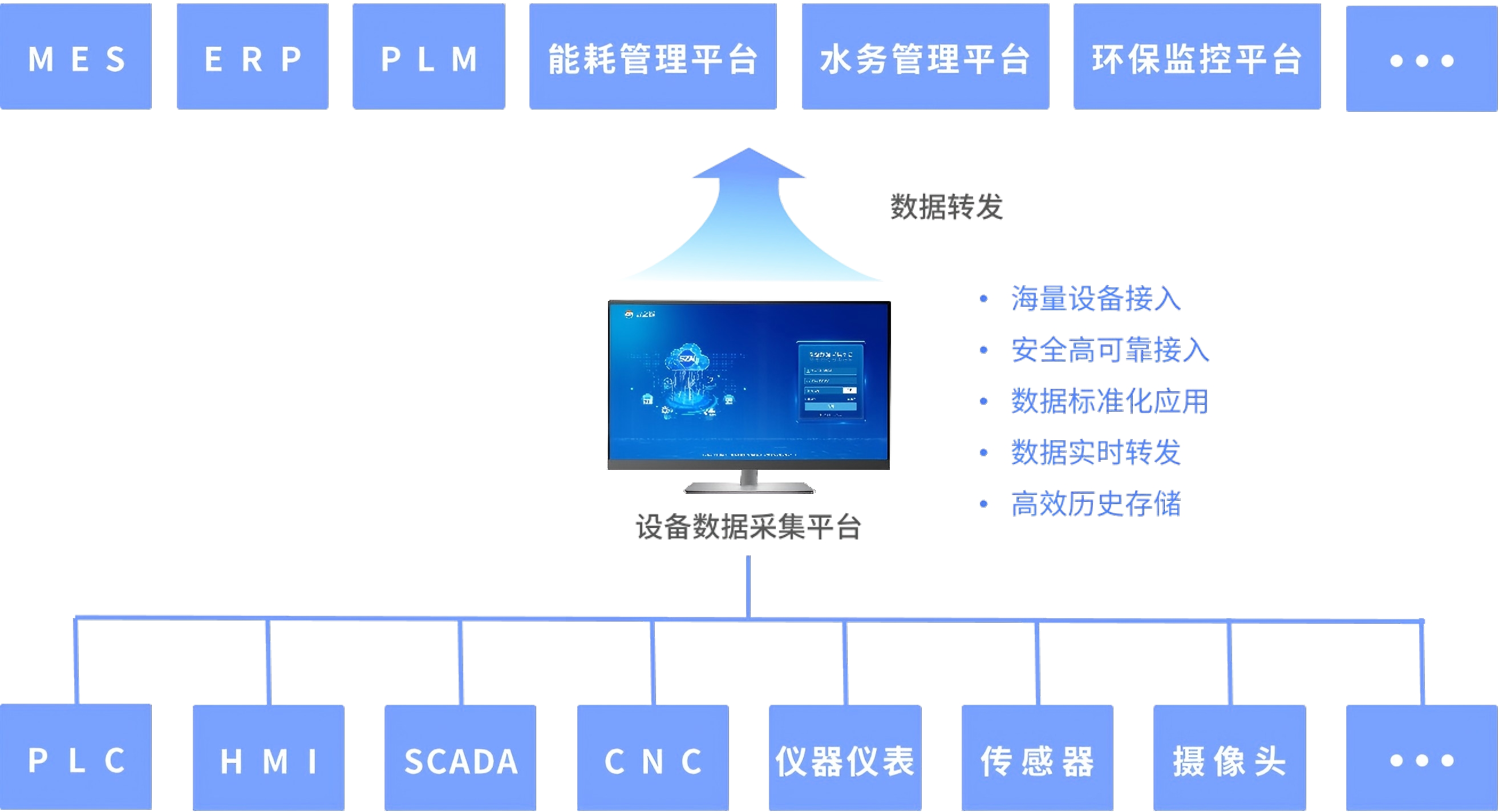
JSON或XML,支持OAuth 2.0认证机制以确保安全性。开发者通过这些接口可以编程式地访问淘宝的商品、订单、用户等核心数据和服务。以下从技术角度,分场景介绍其典型应用,每个场景包括技术实现细节和实际价值。 1. 商品数据获取与集成 应用场景 :第三方比价工具、数据分析平台或ERP系统需要实时获
2025-11-03 13:49:00233 近日,湖北大数据集团有限公司党委书记、董事长汪小波率队到访维智科技。双方围绕时空数据融合、公共数据授权运营及行业应用场景开发等议题展开深入探讨。
2025-11-03 10:02:28517 组态大数据平台是融合 组态技术 与 大数据处理能力 的综合性平台,通过图形化、可配置的方式实现数据采集、存储、分析、可视化及远程控制,适用于工业自动化、能源管理、楼宇监控等领域。其核心价值在于降低
2025-10-30 11:29:48147 
谐波源定位的核心是通过 “信号测量→特征分析→逻辑判断”,确定电网中产生谐波的具体设备、用户或区域,常用方法可按 “原理差异” 分为功率流向类、暂态对比类、阻抗分析类、相位判断类、数据驱动类五大类
2025-10-13 16:41:12608 一、引言
玻璃晶圆总厚度偏差(TTV)是衡量晶圆质量的关键指标,其精确分析对半导体制造、微流控芯片等领域至关重要 。传统 TTV 厚度数据分析方法依赖人工或简单算法,效率低且难以挖掘数据潜在规律
2025-10-11 13:32:41315 
电能质量分析软件通过对电力系统的实时数据采集和深度算法处理,可提供覆盖 “稳态指标评估、暂态事件溯源、故障预测诊断、合规性验证” 全链条的数据分析功能。以下结合行业标准与前沿工具(如福禄克、华盛昌
2025-10-10 17:12:10628 使用jQuery的常用方法与返回值分析
jQuery是一个轻量级的JavaScript库,旨在简化HTML文档遍历和操作、事件处理以及动画效果的创建。本文将介绍一些常用的jQuery方法及其返回值
2025-10-01 20:18:58
是“$”,在命令提示符后边输入命令即可和系统进行交互操作。ubuntu默认的Shell是Bash(Bourne Again Shell)。Linux命令有很多,功能比较强大,下节我们简单介绍一些常用的命令。常用
2025-09-28 09:05:43
在射频(RF)通信系统中,信号从发射器到接收器所经过的路径称为通信链路。在设计此类系统时,评估该路径上的信号强度、噪声水平,以及各种损耗的过程称为链路预算分析。
2025-09-23 11:13:554064 
秒级故障告警,结合云端大数据分析预测组件寿命与发电量损失等。通过科学化的技术应用,实现对光伏电站的全生命周期管理。 智能巡检是一个系统性过程,其具体是对光伏组件、支架、逆变器、电缆等设备进行自动化、实时化、精
2025-09-19 13:33:43546 
AltairRapidMiner赋能组织解锁数据洞察,运用数据分析和先进的人工智能自动化,提供可扩展的面向未来的解决方案。Altair数据分析和人工智能平台包括数据准备、数据科学、MLOps、编排
2025-09-18 17:56:45710 
北京华盛恒辉电磁兼容 (EMC) 大数据智能管理系统精简解析 在 EMC 大数据分析中,电磁兼容与电磁干扰(EMI)智能管理系统是保障设备稳定、提升系统可靠性的核心工具。系统整合 EMC/EMI
2025-09-17 14:58:25511 电磁兼容与电磁干扰在电磁兼容性大数据分析中的智能管理系统
2025-09-17 14:58:13435 
电磁兼容与电磁干扰在电磁兼容性大数据分析中的智能管理系统
2025-09-17 14:42:17688 
XKCON祥控输煤皮带智能机器人巡检系统通过智能机器人在皮带运行过程中对皮带的运行状态和环境状况进行实时检测,在应用过程中,不但提升了巡视周期频次,还通过大数据分析和深度学习算法,对监测数据进行挖掘分析,及时发现设备缺陷故障,为风险防控提供科学依据。
2025-09-15 11:22:20474 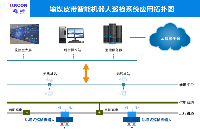
御控工业物联网推出排水设备远程监控与大数据统计系统,通过物联网、大数据、云计算等技术构建“感知-传输-分析-决策”闭环管理体系,助力排水行业数字化转型。
2025-09-12 10:04:05540 随着人工智能和大数据技术的快速发展,高光谱成像技术作为一种融合光谱信息与空间影像的新兴技术,正日益成为提升数据分析效率的重要工具。在农业监测、环境保护、矿产勘探等多个行业中,高光谱成像通过获取精准
2025-09-11 16:13:54666 
源仪电子的新能源测试系统以其精确的检测技术和强大的数据分析能力,为新能源产业的发展提供了有力支持。通过高精度的硬件配置、灵活的软件平台,ATE测试系统不仅能够提高新能源设备的性能和可靠性,还能助力
2025-09-11 10:48:42375 
在当今数据驱动的电商时代,精准分析销售大数据能帮助企业优化库存、提升营销策略。苏宁易购作为国内领先的电商平台,其家电销售数据蕴含着丰富洞察。本文将一步步指导您如何巧妙利用苏宁易购 API,高效
2025-08-29 10:54:39574 API,结合数据分析,实现精准量化种草效果。文章结构清晰,从基础概念到实践步骤,逐步指导您操作。所有方法基于真实电商场景,确保可靠性和可操作性。 一、抖音电商 API 简介与接入 抖音电商 API 是抖音官方提供的编程接口,允许开发者
2025-08-20 15:29:26918 ManufacturingAnalytics(M-A)是Exensio数据分析平台中的四个核心模块之一。M-A模块旨在帮助集成器件制造商(IDM)、代工厂(Foundry)和无晶圆厂半导体公司
2025-08-19 13:53:55883 
TestOperations是Exensio数据分析平台的四个主要模块之一。T-Ops模块旨在帮助集成器件制造商(IDM)、无晶圆厂半导体公司(Fabless)和外包半导体(产品)封测厂(OSAT
2025-08-19 13:53:32951 ProcessControl(E-PC)是Exensio数据分析平台的四大主要模块之一。作为一款在行业内处于领先地位的实时控制和分析工具,它为集成设备制造商(IDMs)、代工厂(Fab)、中段工艺
2025-08-19 13:53:16668 ExensioAssemblyOperations是Exensio数据分析平台的关键组成部分之一,它在先进封装和PCB组装中提供了单个器件级别的可追溯性,遵循SEMIE142标准,并且无需使用电
2025-08-19 13:52:351327 。目前Exensio数据分析平台已用于全球数百家企业,助力不同产业环节的企业提升运营效率和企业收益。本文将继续介绍Exensio在OSAT中的实际应用及其带来的实
2025-08-19 13:49:03510 在当今半导体行业,企业面临着海量数据的挑战与机遇,如何高效整合与分析这些数据,成为企业提升竞争力的关键。本文将继续介绍Exensio在IDM企业中的实际应用及其带来的实际效益。合作:普迪飞携手英特尔
2025-08-19 13:48:47806 通过数据分析识别设备故障模式,本质是从声振温等多维数据中提取故障特征,建立 “数据特征 - 故障类型” 的映射关系,核心可通过特征提取、模式匹配、趋势分析三步实现,精准定位故障根源与发展阶段。
2025-08-19 11:14:02631 
搭建Abaqus有限元模型时,经常需要设置多分析步。在设置Abaqus多分析步的常用方法为在仿真分析任务中设置多个“Step”,将整个仿真任务的求解时间划分为若干个Step(图1),用户可具体指定
2025-08-06 15:14:481179 
摘 要:以三相电压型逆变器为研究对象,介绍了多种空问矢量调制方法。该方法易于数字化,避免繁琐的计算。本文通过一种在标准正弦波的基础上,注入零序分量来统一给出这些调制方法。逆变器在这些调制方法下的输出
2025-07-25 14:03:25
底层捕获能力
最大吞吐量测试
目的:评估分析仪在无丢包情况下的最大数据捕获速率。
方法:
使用高速信号发生器(如Keysight 81150A)生成已知协议的连续数据流(如10Gbps以太网
2025-07-24 14:19:26
在电商业务中,数据是驱动决策的核心。随着数据量的增长,企业需要实时、灵活的分析工具来监控销售、用户行为和库存等指标。一个自定义电商数据分析API(应用程序接口)可以自动化数据提取和处理过程,提供
2025-07-17 14:44:12460 AI数据分析仪, 平板数据分析仪, 数据分析仪, AI边缘计算, 高带宽数据输入
2025-07-17 09:20:11580 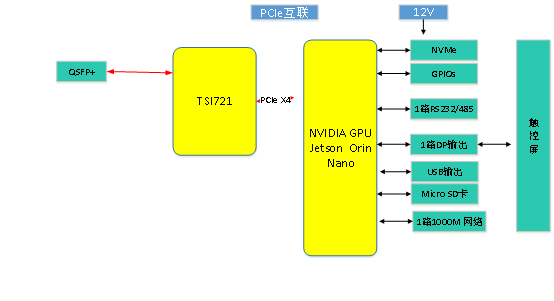
使用协议分析仪进行数据分析与可视化,需结合数据捕获、协议解码、统计分析及可视化工具,将原始数据转化为可解读的图表和报告。以下是详细步骤及关键方法,涵盖从数据采集到可视化的全流程:一、数据采集与预处理
2025-07-16 14:16:48
、安全运行。 运维管理的主要内容是通过设备运行监控、设备维护与检修,实现数据管理与决策支持、能源管理与优化。常用方法与工具是通过智能化监控系统、无人机巡检等来结合AI与大数据分析,实现光伏电站的有效管理。其中
2025-07-14 15:59:17579 
) 能否告诉我是否有用于接收大数据包数据的设置方法?
顺便说一下,在两台Windows笔记本电脑之间执行BLE通信时, CAN 接收512字节的通信没有任何问题。
谢谢
2025-07-07 07:33:06
横河IS8000集成软件平台,将功率分析仪的波形采集与示波器的波形数据分析融为一体,提高测试效率。下面我们将为您揭晓如何通过IS8000软件和WT5000的DS波形数据流功能轻松保存并分析相关波形数据。
2025-07-03 18:30:08494 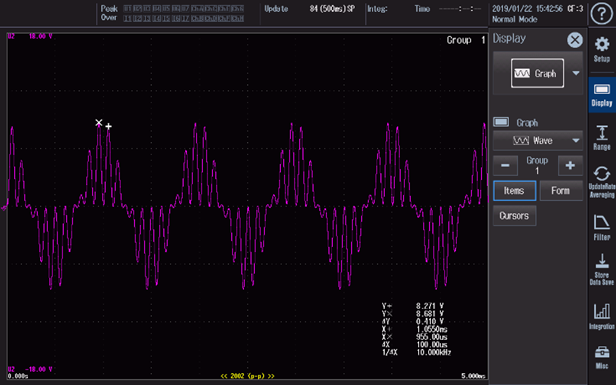
Keysight是德示波器在电子测量领域应用广泛,精准的触发设置与高效的波形分析方法对获取准确信号信息至关重要。以下为您介绍5个常用的触发设置及波形分析方法。 边沿触发设置 边沿触发是最基础且
2025-06-27 16:00:471134 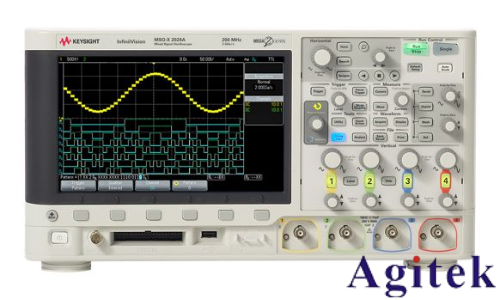
电子发烧友网站提供《常用电子元器件介绍.pptx》资料免费下载
2025-06-24 16:54:49 43
43 的集中化服务。 服务对象:主要面向企业、云服务提供商、政府机构等,支撑其业务系统、应用程序和数据分析需求。 典型应用:云计算、大数据分析、人工智能训练、企业IT系统托管等。 通信网络 核心功能:实现不同设备、系统或用
2025-06-12 09:57:51747 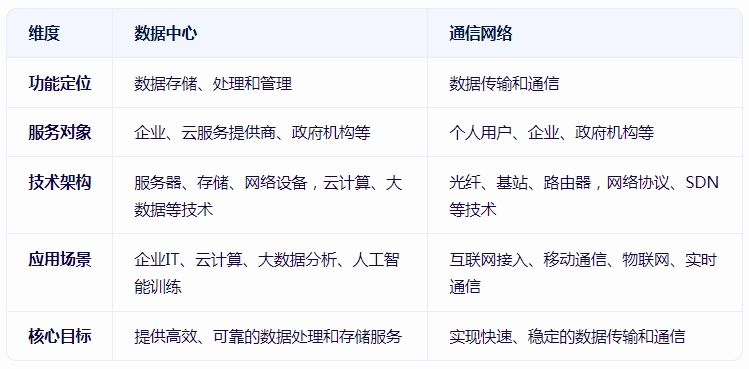
普源示波器(Rigol)作为国内知名的测试测量仪器品牌,广泛应用于电子工程、科研实验、教学等领域。为了进一步扩展其功能,用户常需将示波器与MATLAB等数据分析平台连接,实现自动化测试、实时信号处理
2025-05-29 09:34:58859 编程(verilog语言)有一定的基础。
另外,对AHB总线也需要有一定的了解。
这个章节分为两部分:
第一部分,展示联合编程中各种概念和操作流程;
第二部分,从具体案例出发,由浅到深来描述各种常用
2025-05-26 16:22:38
工业物联网平台是工业物联网(IIoT)的核心组件,是连接物理世界和数字世界的桥梁,通过将物联网、大数据、云计算、人工智能等新一代信息技术与工业生产深度融合,实现工业设备、系统、人员以及产品之间
2025-05-20 17:29:30792 将生产者 EP 端点描述符中的最大数据包大小从 1024 字节更改为 512 字节时,无法识别 USB 设备。
请告知如何解决这个问题。
2025-05-20 08:13:12
物流与采购联合会大数据分会正式授予深开鸿“副会长单位”称号,标志着国产数字底座在物流关键领域的深度应用迈入新阶段。会谈中,中国物流与采购联合会大数据分会介绍了20
2025-05-19 19:06:35655 
在工业、科研等众多领域,压力数据的精确记录和分析至关重要。想要测量压力数据,必然需要用到专业的工具,那就是压力数据记录仪。那么,压力数据记录仪的功能有哪些呢?今天就来给大家详细介绍一下。一、实时数据
2025-05-19 16:39:05
、常用元器件的特点与作用、电路图的画法规则和看图技巧、单元电路的分析方法、集成电路和数字电路的分析方法等,并通过具体电路实例详细讲授电路图的识读方法和分析技巧。
纯分享贴,有需要可以直接下载附件获取完整资料!
(如果内容有帮助可以关注、点赞、评论支持一下哦~)
2025-05-16 15:17:35
放电现象。这种放电虽初期难以察觉,却会持续侵蚀绝缘性能,最终导致短路、停电等重大事故。传统的定期巡检模式难以捕捉早期微弱放电,而环网柜局放大数据分析方案的出现,为
2025-05-07 10:07:27431 
长期可靠地工作,这一问题牵涉到许多有关系统抗干扰设计、故障自诊断、自恢复等有关可靠性的知识和技术。本文着重介绍与可靠性有关的一些概念和电机微机控制系统中常见放障的分析,并指出提高系统可靠性的途径及技术措施
2025-04-29 16:14:56
数据的采集和处理、试验报告的编写和性能数据分析等多方面内容进行了详细地介绍。本书既可作为从事电机试验人员的工具书,也可供具有中专以上从事电机设计、制造、维修的工程技术人员及电机专业教学人员的参考。
纯
2025-04-28 00:43:19
噪声。下图为此BUCK电路第一次测试EMI辐射的测试数据(测试标准:EN55032),可以看出,辐射超标,高出标准4.16dB。 为了方便分析,搭建一个BUCK仿真电路,通过电路仿真判断辐射杂波的产生
2025-04-27 15:44:03
1.6 单片机的C51基础知识介绍
1.6.1 利用C语言开发单片机的优点
1.6.2 C51中的基本数据类型
1.6.3 C51数据类型扩充定义
1.6.4 C51中常用的头文件
1.6.5 C51
2025-04-15 13:57:28
本资料介绍电子电路和器件的基本概念、原理及分析方法。内容从半导体器件到功能电路,从电路结构到故障诊断,从理论分析到实际应用。半导体器件包括:二极管、双极型晶体管、结型场效应管、MOS场效应管、晶闸管
2025-04-11 15:55:34
本资料共分两篇,第一篇为基础篇,主要介绍了电子元器件失效分析基本概念、程序、技术及仪器设备;第二篇为案例篇,主要介绍了九类元器件的失效特点、失效模式和失效机理以及有效的预防和控制措施,并给出九类
2025-04-10 17:43:54
、算力评估指标以及算力战略概念。基础概念算力(ComputingPower):是指计算机系统处理数据的能力。它通常用FLOPS(每秒浮点运算次数)来衡量,表示计算机
2025-04-07 11:21:031308 
引言:工业电机行业作为现代制造业的核心动力设备之一,具有广阔的发展前景和巨大的市场潜力。随着技术的不断进步和市场需求的持续增长,工业电机行业将迎来更多的发展机遇和挑战。以下是中研网通过大数据分析
2025-03-31 14:35:19
2025 年 3 月 26 日,涛思数据通过线上直播形式正式发布了其新一代时序数据分析 AI 智能体——TDgpt,并同步开源其核心代码。这一创新功能作为 TDengine 3.3.6.0 的重要
2025-03-27 10:30:23603 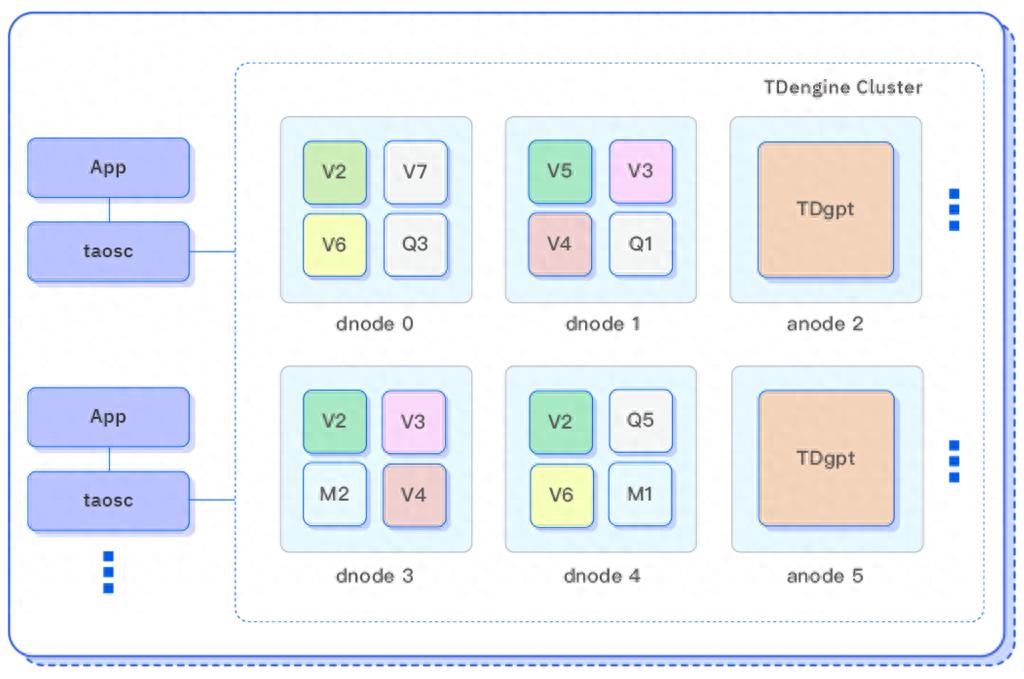
在当今数字化浪潮汹涌的时代,各行业大数据中心承载着海量的数据交互与运算,对网络传输设备的要求近乎苛刻。而汉源高科万兆光纤收发器HY5700-5211X-LC20,凭借其卓越性能,在众多行业大数据
2025-03-21 13:55:32
在数字化时代,大数据中心作为信息处理的核心枢纽,其网络传输设备的性能直接关系到数据处理的效率和质量。汉源高科万兆光纤收发器HY5700-5211X-LC20凭借其优异的性能和强大的功能,赢得了各行业大数据
2025-03-21 12:06:46
开盖检测(DecapsulationTest),即Decap,是一种在电子元器件检测领域中广泛应用的破坏性实验方法。这种检测方式在芯片的失效分析、真伪鉴定等多个关键领域发挥着不可或缺的作用,为保障
2025-03-20 11:18:231096 
工业物联网,简单来说,就是将物联网技术应用于工业领域,通过传感器、网络通信技术、大数据分析和人工智能等手段,实现工业生产过程中的设备互联、数据共享和智能控制。这一概念看似抽象,实则已经渗透到了工业生产的各个角落。
2025-03-17 21:21:25517 本文首先介绍了器件失效的定义、分类和失效机理的统计,然后详细介绍了封装失效分析的流程、方法及设备。
2025-03-13 14:45:411819 
TechWiz OLED 输出各种内部空间数据,例如:电场和磁场、光功率和光吸收。 它们提供有关所有光学模式的内部发射过程和吸收损耗信息的物理和直观信息。
仿真结构
2025-03-11 08:55:56
一、电机概念介绍 从广义上讲,电机是电能的变换装置,包括旋转电机和静止电机。旋转电机是根据电磁感应原理 实现电能与机械能之间相互转换的一种能量转换装置;静止电机是根据电磁感应定律和磁势平衡原理实
2025-02-27 15:28:064 摘要 在能源资源日益紧缺和环境保护压力不断增大的背景下,如何高效利用能源、实现节能减排成为工业企业面临的重要课题。本文提出了一种基于物联网(IoT)与大数据分析的智慧化工业企业能耗监测与优化系统
2025-02-25 17:13:50887 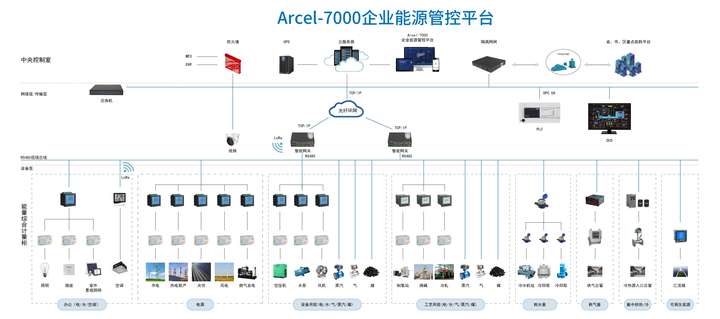
一、工业物联网平台的概念 工业物联网平台是工业物联网的核心,是在工业领域中,通过将物联网、大数据、云计算、人工智能等新一代信息技术与工业生产深度融合,实现工业设备、系统、人员以及产品之间的互联互通
2025-02-25 17:12:42758 大数据与云计算是支撑现代数字化技术的两大核心。大数据专注于海量数据的采集、存储、分析与价值挖掘;云计算通过虚拟化资源池提供弹性计算、存储及服务能力。两者结合,共同赋能企业决策、业务创新和效率提升。下面UU云小编将详细剖析大数据与云计算是干嘛的。
2025-02-20 14:48:231362 推动了大数据分析和AI应用的普及与创新。 公有云服务器以其大规模集群管理能力和资源利用效率最大化的特点,成为解决算力“供不上、用不起”问题的重要抓手。在大数据处理方面,公有云服务器提供了强大的存储和计算能力,支
2025-02-20 11:10:56762 本文总结了大模型领域常用的近100个名词解释,并按照模型架构与基础概念,训练方法与技术,模型优化与压缩,推理与应用,计算与性能优化,数据与标签,模型评估与调试,特征与数据处理,伦理与公平性、其他
2025-02-19 11:49:431379 大数据和云计算领域包含多种专业证书,其中大数据领域涵盖数据分析类证书、大数据工程类证书、数据治理类证书。云计算领域领域涵盖云计算技术类证书、云安全类证书。以下是UU云小编对每个领域的具体证书介绍:
2025-02-19 11:05:411249 本文介绍了集成电路设计中静态时序分析(Static Timing Analysis,STA)的基本原理、概念和作用,并分析了其优势和局限性。 静态时序分析(Static Timing
2025-02-19 09:46:351483 本文介绍了芯片失效分析的方法和流程,举例了典型失效案例流程,总结了芯片失效分析关键技术面临的挑战和对策,并总结了芯片失效分析的注意事项。 芯片失效分析是一个系统性工程,需要结合电学测试
2025-02-19 09:44:162908 产品别名: 电缆护层接地环流监测装置、电缆护层环流预警系统、智能电缆护层环流监测装置、电缆护层环流数据分析系统 产品型号: TLKS-PLGD 一、产品描述: 随着智能电网技术的不断进步,电力运维
2025-02-18 17:47:14763 
EtherNet/IP转Modbus TCP在新能源风力发电场远程监控与数据分析的配置案例 一、案例背景 在风力发电场的中控室安装 捷米特JM-EIPM-TCP 网关,连接
2025-02-10 15:54:38683 
功率分析仪的使用说明主要包括安装、设置、测量及数据分析等步骤,以下是详细的使用指南:
2025-01-28 14:55:002233 :对于年收益低于1亿的中小型企业来说采购成本较高,但可以考虑引入FineBI的Saas版本九数云
2. Tableau
优点:强大的数据可视化功能,支持多种数据源连接和大数据分析,拥有丰富的图表
2025-01-19 15:24:15
随着智能电网技术的发展和大数据时代的到来,电力系统数据分析技术已成为电力行业不可或缺的一部分。这些技术能够帮助电力公司更好地理解电网的运行状态,预测电力需求,优化电力资源分配,提高电网的稳定性
2025-01-18 09:46:011317 在上一篇文章中,罗克韦尔自动化为各位分享了使用制造执行系统 (MES) 优化生产的方法。承接上期,罗克韦尔将继续为您介绍数据分析工具等智能技术如何为优化生产赋能。
2025-01-17 11:02:12823 随着科技的不断进步,智能制造已经成为推动工业4.0发展的关键力量。在众多的智能制造技术中,智能焊接数据分析设备因其在提高生产效率和焊接质量方面的显著效果而受到广泛关注。本文将探讨智能焊接数据分析设备
2025-01-15 14:11:51727 不稳定、生产效率低等问题。而智能焊接数据分析设备的应用,则为解决这些问题提供了新的思路和技术手段。本文将探讨智能焊接数据分析设备如何通过数据采集、分析及应用,提升焊接制?
2025-01-14 09:36:56821 由于无人驾驶系统开发需要长期迭代优化,其过程需要大量的路试数据支撑,经纬恒润针对无人驾驶系统持续运营和持续迭代的需求,开发并在云端部署了车路云工程大数据平台,依托5G网络,具有远程数据采集、压缩、传输、解析、回放与算法无缝衔接等功能,可服务于客户从研发到商业化运营的不同阶段。
2025-01-10 17:00:00936 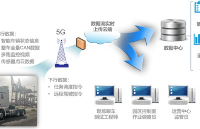
天拓四方通过集成工业智能网关、通信网络技术和数据分析平台,实现对自来水企业PLC系统的高效数据采集、远程监控与智能管理。不仅可以提高企业的生产效率和管理水平,还能降低运维成本,为企业的发展提供了有力支持。具体包括以下几
2025-01-09 17:47:541243 制备精细焊粉的方法有多种,以下介绍五种常用的方法:
2025-01-07 16:00:57738 
数字孪生工厂的构建方法与应用,以期为制造企业实现智能制造提供参考与指导。 1?数字孪生的概念及内涵 1.1 数字孪生的概念 数字孪生(Digital Twin,DT)是信息科学与物理工程学交叉领域中涌现的一个创新概念。其诞生可以追溯到
2025-01-06 10:41:26829
 电子发烧友App
电子发烧友App



 大数据分析包含那些方面
大数据分析包含那些方面





 工商网监
工商网监
评论