 电子发烧友App
电子发烧友App


深度学习已经成为我们这一代人最重要的计算工作量之一,推进从视觉识别到自动驾驶的跨行业应用。但这也是深刻的计算密集型。
为了训练当今最先进的神经网络,深度学习研发人员通常需要使用几十至数百个GPU的超大集群。这些集群的构建成本很高,而且很复杂。还需要几天到几周的时间来训练网络,从而拖累了创新的步伐。我们来看看Cerebras是怎么解决该问题的呢?
大多数深度学习工作都是在原型阶段开始的,研究人员希望快速、准确进行迭代。当一个实验处于初始阶段,并且使用有限的数据子集运行时,小规模的硬件设置(如单颗GPU工作站)就够了。
但随着研究规模的扩大或模型投产,其复杂数据集需要大量的计算。从而大规模、可扩展的液冷GPU工作站应运而生,甚至用液冷GPU服务器做数据集群。然而在庞大的计算集群中实现良好的利用率复杂且费时。它需要将工作负载分布在许多小型设备上,以解决这些内存大小和内存带宽限制,以及兼顾并管理通信及同步管理。因此研发人员经常发现需要引入其它软件如Nccl、Horovod、OpenMPI。
此外,对于大规模分布式训练,很少能从一开始就产生正确的结果。扩展效率依赖于使用大批量,影响模型的聚拢方式。
为了应对准确性下降的问题,调整学习速度及尝试不同的优化器,以找到最佳的训练配置,然后根据需要定制特定的硬件配置。
因此,虽然大量GPU集群有可能为神经网络训练带来更多的计算量,但对于整个组织来说,无论从ML研究人员到生产ML工程师以及基础架构和IT团队都是复杂、耗时且困难。
Cerebras最先进的深度学习是每个ML研发人员都可以轻松访问,无需集群或并行编程专业知识。以晶圆级技术为动力,Cerebras的计算和存储变得更加紧凑。将整个集群部署在单个设备的单个芯片上,因此ML研究人员和从业者可以通过单个机器的编程轻松实现集群规模的性能。
分布式GPU集群在深度学习方面最痛苦的步骤,在Cerebras CS-1和CS-2系统上更简单、更快的方法,以实现大规模的深度学习。
1传统方法:使用GPU集群进行分布式训练
模型分发和集群编排
像PyTorch和TensorFlow这样的ML框架使得在单颗GPU上构建和运行模型变得非常简单。但最终遇到性能瓶颈,需要使用大量数据来扩展。如何解决跨多个GPU分发模型成为挑战。多GPU工作负载分配不仅仅需考虑单个神经网络模型范围及设备之间的并行处理。通常从更改模型代码开始训练。数据在一台或多台GPU机器上并行,并使用分布式TensorFlow或PyTorch等框架扩展进行软件配置。
与手动实现数据或模拟相比,这些框架使向外扩展变得不那么痛苦,但调整设置和学习仍然需要时间。并且得到模型运行只是第一步。
设备和群集编排
想要在较高的设备使用率下运行分布式深度学习工作负变得更加复杂。从多个小型处理器实现性能最大化是一项的挑战,每个处理器都有具体的设备限制,需要统一管理和协调。
需要弄清楚如何在设备之间分配计算,如何考虑设备内存大小以及内存限制,以及如何处理它们之间的通信和同步。这就是为什么许多用户会引入更多框架(如Horovod)和库(如OpenMPI)用于工作负载分配、进程间通信以及内外节点通信。
但模型并行化不是深入学习的研究或工程;它是超级计算机集群工程,是个非常复杂的并行编程问题。即使有最好的工具,也会非常耗时,通常需要IT支持、HPC和ML工程的专业团队。
聚拢与调优
成功地跨集群分发模型需要不仅仅是调整集群设置和同步开发软件,还需要研究人员改变他们的实际模型部署。随着GPU集群扩展到10、100甚至1000,研究人员往往被迫使用超大规模集群,减少大量通信开销以实现设备利用率。
但大规模批量训练往往对模型聚拢有很大影响。需要显著增加epoch总数,甚至可能导致模型精度下降。实现聚拢到精准的快速分布式模型可能需要几天、几周甚至更长。研究人员通常需要进行几十次实验才能找到合适的组合 - 优化超参数(例如批量大小、学习速度和动量)、优化器等聚拢性和精准度。
同时,挂钟训练时间也呈亚线性变化。例如MLPerf最近研究结果显示, 需要32个NVIDIA DGX-A100 系统(256个A100 GPU)的集群才能实现仅比单个DGX-A100高14.6倍的挂钟加速。随着对计算机需求的增长,运行分布式GPU的研究人员必须应对日益增加的软件和模型聚拢复杂性,同时在性能上带来的回报不断减少。
最后,通过分布式集群实现深度学习模式是脆弱的。如果研究人员需要更改其数据维度、数据集、模型架构或神经网络层操作及优化器,需重新调整功能超参数、解码及性能调试实验。
2 Cerebras解决方案
Cerebras系统可以消除跨GPU集群扩展深度学习模型带来的挑战。
由世界上最大的芯片驱动,CS-2系统单个芯片上集成85万个AI优化内核,从而大大增强了计算能力。将所有都集成在硅上意味着CS-2不仅能提供巨大的计算和芯片内存,而且比GPU提供了更大数量的内存和互连带宽。加速深度学习模型的训练。
单个CS-2可提供整个GPU集群的挂钟计算性能:数十到数百个独立处理器,节约空间和功耗。
这意味着以更低的成本获得更快的洞察力。对于ML研究人员来说,通过单个设备的编程实现集群规模的性能。有了CS-2,研究人员可以加速最先进的模型,而无需花费数天到数周的时间对大型集群运行分布式培训而带来的设置和调整。
3 Programming the CS-2
由于CS-2在单个设备中加速集群扩展,显著缩短运行时间且保持编程模型的简单性。数据 科学家和ML研究人员可以专注于处理他们的数据、模型和应用程序,无需花时间协调解决备群集的并行处理及优化。
研究人员可以使用熟悉的ML框架(如TensorFlow和PyTorch)对CS-2进行编程。之后,Cerebras图形编译器(CGC)自动将用户的神经网络图转换为CS-2的850000个内核的优化可执行文件。
在CS-2上实现应用程序非常简单。添加几行代码,如使用TensorFlow。
CerebrasEstimator是专为TensorFlow开发的包装类浮点。用户只需导入CerebrasEstimator,然后跟平常一样定义其模型函数,输入功能、相关参数、培训脚本,使用标准的TensorFlow语义。
CerebrasEstimator是官方TensorFlowEstimator的子分类,以保持工作流程简单和熟悉。用户只需实例化CerebrasEstimator,为Cerebras系统提供IP地址,并设置一个标志use_cs=True以指导CS-2的训练或推理。运行时CerebrasEstimator train将自动调用CGC并处理为CS-2准备一个模型的剩余的内容。
由于CS-2是如此强大的单一系统,因此不需要额外的工作来扩展网络。用户只需更改几行代码。
使用CS-2端到端模型开发任务,如模型设置、超参数优化、扩展和性能优化可以在数小时或数天内完成,而非采用传统GPU集群所需数周时间。
4CS-2的优势
CS-2独特的性能与单节点简单结合不仅避免了并行编程的复杂性,也解锁了更快的时间问题,从研究理念可以直通生产建模。
在典型的GPU集群设置中,ML工程师可能会花费数天或数周的时间来选择和调整超参数,以实现可接受的设备利用率,同时还要保持大规模扩展带来的的模型精度。
CS-2是单一的功能强大的设备,所以没有这样的批量规模要求。在CS-2上,研究人员可以在任何批量下对模型进行高可用训练。用户不仅可以实现巨大的即时加速,也可以提高模型聚拢及到目标精度。
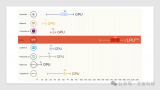
5 GPU与Cerebras的实例对比
在与一生命科学客户的合作中,下图展示使用GPU集群和系统从概念到生产特定领域的BERT NLP模型开发项目对比。显而易见Cerebras的性能与编程的易用性相结合,使研究人员节省了14周的时间。
我们考虑了相同的模型和数据集,并包括软件设置步骤:模型定义、功能调试、性能优化、初始模型培训和后续实验开发生产部署。
这项工作表明,Cerebras解决方案缩短了生产解决方案的端到端时间。在GPU集群上运行18周,在Cerebras系统上只需运行四周。编程和计算时间都缩短至少三个多月,为客户节省了大量工程成本,使其加速新的人工智能创新。
深度学习将继续是我们这个时代最重要的计算工作量之一。今天的传统系统正在拖累传统行业的创新步伐。Cerebras先进的深度学习推崇的是简单易行。Cerebras已将整个集群的计算和内存加密整合到单个设备中的单个芯片。Cerebras创造更简单、更快的方法,实现大规模的深度学习。
责任编辑:tzh










































 工商网监
工商网监
评论