 电子发烧友App
电子发烧友App


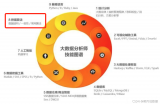
数据挖掘的定义
数据挖掘是指从大量的数据中通过算法搜索隐藏于其中信息的过程。
数据挖掘通常与计算机科学有关,并通过统计、在线分析处理、情报检索、机器学习、专家系统(依靠过去的经验法则)和模式识别等诸多方法来实现上述目标。
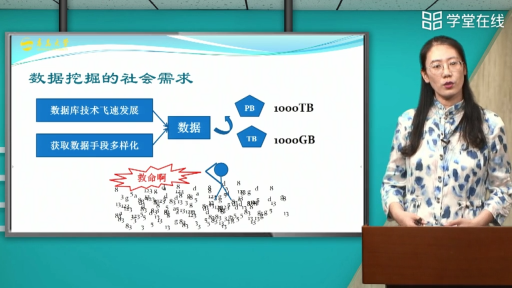
数据挖掘的对象
数据的类型可以是结构化的、半结构化的,甚至是异构型的。发现知识的方法可以是数学的、非数学的,也可以是归纳的。最终被发现了的知识可以用于信息管理、查询优化、决策支持及数据自身的维护等。
数据挖掘的对象可以是任何类型的数据源。可以是关系数据库,此类包含结构化数据的数据源;也可以是数据仓库、文本、多媒体数据、空间数据、时序数据、Web数据,此类包含半结构化数据甚至异构性数据的数据源。
发现知识的方法可以是数字的、非数字的,也可以是归纳的。最终被发现的知识可以用于信息管理、查询优化、决策支持及数据自身的维护等。
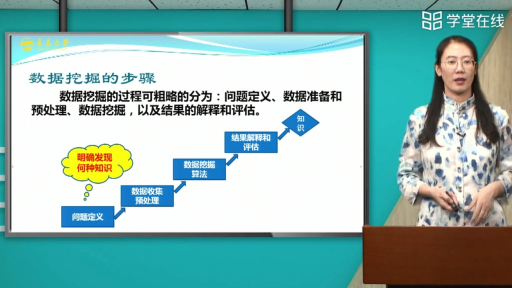
数据挖掘的步骤
1、定义问题。在开始知识发现之前最先的也是最重要的要求就是了解数据和业务问题。必须要对目标有一个清晰明确的定义,即决定到底想干什么。比如,想提高电子信箱的利用率时,想做的可能是“提高用户使用率”,也可能是“提高一次用户使用的价值”,要解决这两个问题而建立的模型几乎是完全不同的,必须做出决定。
2、建立数据挖掘库。建立数据挖掘库包括以下几个步骤:数据收集,数据描述,选择,数据质量评估和数据清理,合并与整合,构建元数据,加载数据挖掘库,维护数据挖掘库。
3、分析数据。分析的目的是找到对预测输出影响最大的数据字段,和决定是否需要定义导出字段。如果数据集包含成百上千的字段,那么浏览分析这些数据将是一件非常耗时和累人的事情,这时需要选择一个具有好的界面和功能强大的工具软件来协助你完成这些事情。
4、准备数据。这是建立模型之前的最后一步数据准备工作。可以把此步骤分为四个部分:选择变量,选择记录,创建新变量,转换变量。
5、建立模型。建立模型是一个反复的过程。需要仔细考察不同的模型以判断哪个模型对面对的商业问题最有用。先用一部分数据建立模型,然后再用剩下的数据来测试和验证这个得到的模型。有时还有第三个数据集,称为验证集,因为测试集可能受模型的特性的影响,这时需要一个独立的数据集来验证模型的准确性。训练和测试数据挖掘模型需要把数据至少分成两个部分,一个用于模型训练,另一个用于模型测试。
6、评价模型。模型建立好之后,必须评价得到的结果、解释模型的价值。从测试集中得到的准确率只对用于建立模型的数据有意义。在实际应用中,需要进一步了解错误的类型和由此带来的相关费用的多少。经验证明,有效的模型并不一定是正确的模型。造成这一点的直接原因就是模型建立中隐含的各种假定,因此,直接在现实世界中测试模型很重要。先在小范围内应用,取得测试数据,觉得满意之后再向大范围推广。
7、实施。模型建立并经验证之后,可以有两种主要的使用方法。第一种是提供给分析人员做参考;另一种是把此模型应用到不同的数据集上。
数据挖掘的方法
1、分类。它首先从数据中选出已经分好类的训练集,在该训练集上运用数据挖掘技术,建立一个分类模型,再将该模型用于对没有分类的数据进行分类。
2、估值。估值与分类类似,但估值最终的输出结果是连续型的数值,估值的量并非预先确定。估值可以作为分类的准备工作。
3、预测。它是通过分类或估值来进行,通过分类或估值的训练得出一个模型,如果对于检验样本组而言该模型具有较高的准确率,可将该模型用于对新样本的未知变量进行预测。
4、相关性分组或关联规则。其目的是发现哪些事情总是一起发生。
5、聚类。它是自动寻找并建立分组规则的方法,它通过判断样本之间的相似性,把相似样本划分在一个簇中。
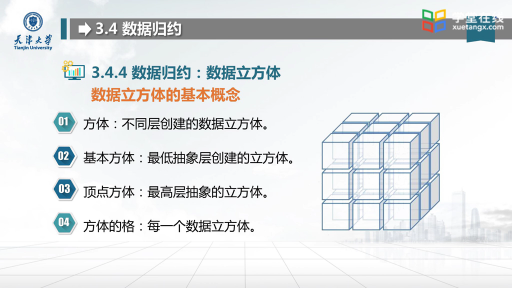
数据挖掘算法
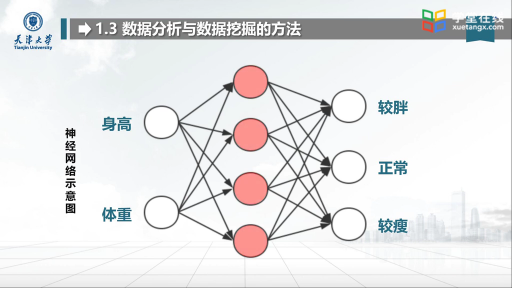
1、神经网络法
神经网络法是模拟生物神经系统的结构和功能,是一种通过训练来学习的非线性预测模型,它将每一个连接看作一个处理单元,试图模拟人脑神经元的功能,可完成分类、聚类、特征挖掘等多种数据挖掘任务。神经网络的学习方法主要表现在权值的修改上。其优点是具有抗干扰、非线性学习、联想记忆功能,对复杂情况能得到精确的预测结果;缺点首先是不适合处理高维变量,不能观察中间的学习过程,具有“黑箱”性,输出结果也难以解释;其次是需较长的学习时间。神经网络法主要应用于数据挖掘的聚类技术中。
2、决策树法
决策树是根据对目标变量产生效用的不同而建构分类的规则,通过一系列的规则对数据进行分类的过程,其表现形式是类似于树形结构的流程图。最典型的算法是J.R.Quinlan于1986年提出的ID3算法,之后在ID3算法的基础上又提出了极其流行的C4.5算法。采用决策树法的优点是决策制定的过程是可见的,不需要长时间构造过程、描述简单,易于理解,分类速度快;缺点是很难基于多个变量组合发现规则。决策树法擅长处理非数值型数据,而且特别适合大规模的数据处理。决策树提供了一种展示类似在什么条件下会得到什么值这类规则的方法。比如,在贷款申请中,要对申请的风险大小做出判断。
3、遗传算法
遗传算法模拟了自然选择和遗传中发生的繁殖、交配和基因突变现象,是一种采用遗传结合、遗传交叉变异及自然选择等操作来生成实现规则的、基于进化理论的机器学习方法。它的基本观点是“适者生存”原理,具有隐含并行性、易于和其他模型结合等性质。主要的优点是可以处理许多数据类型,同时可以并行处理各种数据;缺点是需要的参数太多,编码困难,一般计算量比较大。遗传算法常用于优化神经元网络,能够解决其他技术难以解决的问题。
4、粗糙集法
粗糙集法也称粗糙集理论,是由波兰数学家Z Pawlak在20世纪80年代初提出的,是一种新的处理含糊、不精确、不完备问题的数学工具,可以处理数据约简、数据相关性发现、数据意义的评估等问题。其优点是算法简单,在其处理过程中可以不需要关于数据的先验知识,可以自动找出问题的内在规律;缺点是难以直接处理连续的属性,须先进行属性的离散化。因此,连续属性的离散化问题是制约粗糙集理论实用化的难点。粗糙集理论主要应用于近似推理、数字逻辑分析和化简、建立预测模型等问题。
5、模糊集法
模糊集法是利用模糊集合理论对问题进行模糊评判、模糊决策、模糊模式识别和模糊聚类分析。模糊集合理论是用隶属度来描述模糊事物的属性。系统的复杂性越高,模糊性就越强。
6、关联规则法
关联规则反映了事物之间的相互依赖性或关联性。其最著名的算法是R.Agrawal等人提出的Apriori算法。其算法的思想是:首先找出频繁性至少和预定意义的最小支持度一样的所有频集,然后由频集产生强关联规则。最小支持度和最小可信度是为了发现有意义的关联规则给定的2个阈值。在这个意义上,数据挖掘的目的就是从源数据库中挖掘出满足最小支持度和最小可信度的关联规则。
编辑:jq






























































 工商网监
工商网监
评论