 电子发烧友App
电子发烧友App



基于元学习的红外弱小点状目标跟踪算法
关注微信公众号:人工智能技术与咨询。了解更多咨询!
人工智能技术与咨询 昨天
本文来自《激光技术》,作者热孜亚·艾沙等
引言
红外点状目标的跟踪是红外搜索和跟踪(infrared search and track, IRST)系统中的关键技术之一[1],在红外目标跟踪、遥感制图等多个方面占据主要的位置[2]。在红外背景的图像中,目标占据像素小、无具体的形状、缺少纹理呈点状[3-4], 在复杂的红外背景下,跟踪阶段常常存有如目标遮蔽、背景杂波、迅速移动等困难,这些因素增加了红外点状目标跟踪的难度。目前所使用的大多数都是常规的一些手工设计的特征提取方法,使得传统方法无法很好地用于红外点状目标跟踪。因此,在复杂背景下准确地跟踪红外点状目标成为一项具有挑战性的研究。
目前机器学习的算法被广泛应用于目标跟踪,通常需求大量的训练数据[5]。过度依赖于训练数据使得跟踪模型存在以下问题:(1)需要耗费大量人力进行数据标注,这给算法的计算带来很多困难;(2)这种依赖大量训练数据的模型在训练数据上可以取得较小的误差,但是在测试中遇到新状态下的视频序列时跟踪性能比较差,无法精确跟踪到目标。机器学习的算法需要足够的训练数据,但红外点状目标自身弱和小的特点,而且在点状目标的跟踪领域,公开的、大规模的点状小目标的视频数据十分有限,由于没有大数据的支撑,因而机器学习的算法不能直接用在红外点状目标的跟踪[6]。因此,如何根据红外弱小点状目标的特点,能够让模型尽量用少量的数据,建立具有代表性的、结合深度学习的红外点状目标跟踪算法是一个很大的难题。
将机器学习的方法运用在红外点状目标跟踪中,作者提出基于改进的元学习红外点状目标跟踪算法,该算法使用静态红外图像通过元学习的方法对卷积神经网络做离线训练,学习点状目标的通用特征表示,有效解决红外点状目标训练数据不足的问题。其次将静态红外图像传入预训练的卷积神经网络中提取特征[7],将红外点状目标跟踪问题转化为二元分类问题的判别模型,通过基于深度特征学习分类器来区分背景与前景信息。在跟踪阶段,依据点状目标的运动的特征,运用基于运动模型的目标位置预测的方法来除去后续的帧中非目标点和噪声点对跟踪结果的影响,定位精确的目标位置。结果表明,该实验方法能够稳定地、精确地跟踪到红外点状目标。
1. 相关工作
1.1 网络结构
牛津大学视觉几何组(visual geometry group, VGG) 提出分类任务预训练网络[8]。
如图 1所示,网络模型包含3个卷积层(convolutional)conv 1~conv 3,3个全连接层(fully connected, FC)FC 4~FC 6。输入图像的大小为C×W×H,其中C为图像的通道数,W为图像的宽度,H为图像的高度。卷积层1有96个卷积核,卷积层2有256个卷积核,卷积层3有512个卷积核,其中卷积核的大小为3×3。两个全连接层(FC 4,FC 5)分别有512个神经元节点。首先通过网络中的卷积层提取目标的特征,其次将得到的特征作为全连接层的输入,最后一层全连接层FC 6的输出是二分类分支,判别目标和背景。
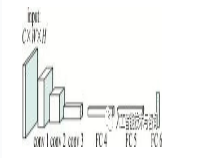
Figure 1. The architecture of VGG network
1.2 元学习
现存的大部分基于深度学习的方法都依赖于大规模的训练数据,这要求人工标注很多数据标签,这是极其浪费时间的,使得只有少量标注数据的任务难以进一步发展,如红外点状目标跟踪。元学习是解决训练数据不足的有效方法。元学习的主要目的是使模型能够用尽量少的训练数据获得尽量大的泛化能力。
尽管元学习在如图像分类等很多领域取得了不错的效果,但是基于元学习的单目标跟踪算法却很少见。运用元学习的离线训练和在线更新的方式,达到准确地跟踪点状目标。元学习又称为学会学习[9-10]。基于优化更新的元学习的主要思想是将跟踪问题当作二元分类问题。
使用初始帧数据(X1, Y1)和网络模型的参量θ,通过对损失函数Lθ经过一次或少量几次梯度下降得到模型f的参量θ*。采用随机梯度下降的方法对参量进行更新[11]:
|
θ∗=θ−α∂Lθ(X1,Y1)∂θθ∗=θ−α∂Lθ(X1,Y1)∂θ |
(1) |
式中,X1为初始帧图像,Y1为X1所对应的标签,θ为网络模型的参量,α为学习率。
更新后的参量θ*满足:
|
θ∗=argminθ∑i=1nLθ(Xn,Yn)θ∗=argminθ∑i=1nLθ(Xn,Yn) |
(2) |
式中,(Xn, Yn)为后续帧的数据,Xn为第n帧图像,Yn为对应的标签,Lθ(X, Y)为损失函数。
将红外点状目标跟踪问题看作为二元分类问题的判别模型,其常用的损失函数为交叉熵损失:
|
L=−[YilnPi+(1−Yi)ln(1−Pi)]L=−[YilnPi+(1−Yi)ln(1−Pi)] |
(3) |
式中,Yi表示样本i的标签,正样本为1,负样本为0,Pi表示样本i预测为目标的概率。
2. 本文中提出的算法
2.1 模型初始化
目前深度学习的算法被广泛应用于目标跟踪,通常需要大量的训练数据。由于红外点状小目标视频数据十分有限,因此运用预训练跟踪模型,将元学习运用到卷积神经网络中,在共享域中使用包含红外点状目标的静态图片对模型进行离线的预训练,充分的表示点状目标的外观特征,使得模型学习目标的通用属性,如时序性、空间特性等。本文中采用对VGG网络模型进行训练,来初始化跟踪模型。
首先,随机初始化网络模型参量θ并将Xn输入到VGG网络中提取目标特征f(Xn),利用网络模型参量θ在f(Xn)上做卷积操作,得到目标位置的响应图像,响应图像与真实标签Yn之间的差异来计算损失L,然后求得损失L对初始参量θ的导数并将其送到优化网络U(ϕ)中,获得更新后的参量θ*,训练过程如图 2所示。
|
L=l(θ∗f(Xn),Yn)L=l(θ∗f(Xn),Yn) |
(4) |
|
l(S,Y)=ln[1+exp(−SY)]l(S,Y)=ln[1+exp(−SY)] |
(5) |
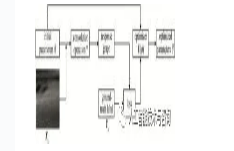
Figure 2. Meta-learning training process
式中,l为分类损失函数,*为卷积操作,S是响应图像,Y为训练数据的标签。
利用损失函数L来更新优化器参量ϕ与网络模型参量θ,如下式所示[12]:
|
{ϕ∗=ϕ−α∇Lϕθ∗=θ+U(∇Lθ,ϕ∗){ϕ∗=ϕ−α∇Lϕθ∗=θ+U(∇Lθ,ϕ∗) |
(6) |
通过随机梯度下降算法(stochastic gradient descent, SGD)[13]对网络参量θ和优化器参量ϕ进行优化,得到更新后的网路模型参量θ*和优化器参量ϕ*,学习率α=0.0001,∇Lθ∇Lθ表示损失梯度,更新网络U(·)为随机梯度下降算法。
图 3a为俯拍海面船舶的场景,受海面的反光,海面波浪等的影响。图 3b为田野背景模糊小目标红外图像序列,受到不同背景杂波的影响,如光照强度、树木遮挡、形状变化等。图 3c为海天背景红外图像序列。由于高亮的云层的影响,目标通常被淹没在杂波中。图像以“.jpg”格式存储,数据集获取场景涵盖了天空、海面等多种场景,背景相对复杂。
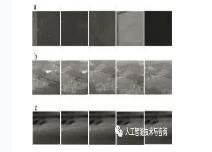
Figure 3. Some examples of static data and dynamic video data in the pre-training stage
通过网络的卷积层在离线训练阶段学习包含红外点状目标的静态图像中的通用属性,如时序性、空间特性等。特定属性是目标在不同的红外场景下所具有的明显差异目标特征的信息,通过初始帧中的目标来学习目标的特定表示,如尺度。
图 4a是原图,图 4b是卷积层1,图 4c是卷积层2,图 4d是卷积层3的卷积层的特征可视化显示的图。从图 4中可以看出,红外点状目标占较小的像素,因此浅层特征更多地偏向于对图像边缘的信息,包含较多的位置信息和丰富的运动信息,同时会保留图像更多的空间特性,这有利于目标定位。随着层数的加深,空间信息逐渐减少,从而影响分类器的定位精确度。

Figure 4. Features of different layers extracted using VGG network
2.2 模型更新
在长时目标跟踪过程中,跟踪目标的相关特性可能会发生变化,如目标的形状,目标被遮挡,以及背景变化等。如果没有根据目标最新状态进行采样来更新模型,会导致目标跟踪失败。因此,为了适应目标在跟踪过程中外观的变化,避免跟踪器产生漂移,更精确地跟踪目标,因而根据跟踪目标和背景的变化来更新样本和模型。
在后续帧中,当第t帧候选样本中前3帧的最大响应值的平均值大于设定的阈值Tth,认为当前帧跟踪结果可靠,则把R作为当前帧中目标的位置。若R小于阈值Tth(其中Tth=0.5为经验值)时,说明目标被遮挡,发生形变和光照变化,目标和背景产生较大的变化(如图 5所示),此时重新获取当前帧目标信息,这时启动重检测,使用多尺度局部梯度强度评估算法[14]来检测出当前帧的目标位置信息,当检测算法定位到目标在当前测试帧的位置时,会按照模型初始化时的方式将检测算法定位得到的目标区域的基础上采集样本。通过检测得到的目标位置作为正样本,其周围区域作为负样本来构成样本集合,将在线获得的样本作为训练数据来训练网络,对模型进行训练更新,直到成功预测目标位置。通过这种方式,使得模型能够及时适应目标的外观变化。

Figure 5. The target is occlusion, deformation, back-ground clutter
给定视频帧中第t帧的图像,以t-1帧图像中目标的预测位置为中心获得搜索区域图像Xt,利用网络获得响应图像St:
|
St=θ∗∗f(Xt)St=θ∗∗f(Xt) |
(7) |
从St中通过响应值最大的位置来估计出目标所在的位置。
2.3 跟踪模型
本文中算法以对卷积神经网络(convolutional neural networks, CNN)进行离线训练和在线模型更新相结合的方式对红外点状目标进行跟踪。跟踪过程的整体框架如图 6所示。
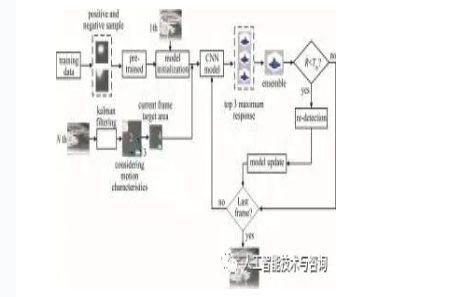
Figure 6. Flow chart of the entire algorithm
图 6中,紫色的实线框1为初始帧给定的目标区域,红色的虚线框2为前一帧目标区域,蓝色虚线框3为待搜索区域,绿色实线框4为当前帧目标区域,蓝色实线框5为最后一帧目标区域。
当前视频帧将前一帧的目标位置作为输入,根据前一帧的目标位置为中心,在它的周围用多维高斯分布的形式进行采样,将采集的样本输入到模型中获得输出结果,输出结果为输入图像块的响应值,取其中前3个具有最大响应值的平均值的图像块位置作为预测目标位置。如果将最大响应值作为目标位置,因测试和训练样本之间的差异,背景变化等这些原因,响应值最高的点不一定是最优的目标位置。因此,为了解决这个问题,本文中从多个响应值中选择前3个最高的响应值,然后对它求平均值作为目标的预测位置。
根据设定的阈值Tth来判断目标是否进行重检测。将取平均值后的响应值R与设定的阈值Tth进行比较,若R>Tth,认为跟踪准确,则把R作为当前帧中目标的位置; 若R < Tth,那么认为目标发生了遮挡,本文中检测方法使用多尺度局部梯度强度评估算法,再次检测到目标。通过检测得到的目标位置作为正样本,其周围区域作为负样本组成一个小批量数据,使用在线获得的样本作为训练数据,对模型进行更新。
在红外视频序列中,红外点状目标在前后两帧中的像素是相接近的,而且在相邻的多帧图像中,目标位置信息有相关性,而背景杂波没有这个特性。卡尔曼滤波根据前几帧目标状态来预测当前帧目标可能的运动方向和运动速度。
当目标运动速度过快或者过慢时,初步设定的以目标区域大小的3倍的搜索框就不合理,在搜索框内可能不存在目标,导致目标的丢失。根据卡尔曼滤波预测的目标运动速度自适应调节搜索框的大小,根据预测的目标运动方向把搜索框选择在目标可能存在的区域。因此在卡尔曼滤波预测的位置范围内,用模型来确定最终的目标位置。
在复杂的红外背景下,目标与背景的灰度差较小,当目标消失在杂波中或者重新出现时,跟踪算法会失去目标,采用重检测使跟踪算法发生跟踪失败时,能够让跟踪算法重新检测到目标是非常重要的。若逐帧都进行重检测,那么计算量较大,因此通过阈值来判断是否进行重检测。本文中检测方法使用多尺度局部梯度强度评估算法,达到再次检测到目标的目的。首先计算前3帧的最大响应值的平均值R。当前3帧的最大响应值的平均值R < Tth时,认为目标发生了遮挡,需要进行重检测; 当R≥Tth时,认为跟踪准确,作为新的目标位置。
|
R¯=Rt−1+Rt−2+Rt−33R¯=Rt−1+Rt−2+Rt−33 |
(8) |
式中,Tth=0.5为经验值,Rt-1, Rt-2, Rt-3为前3帧的最大响应值,R为平均响应值。
3. 实验结果和分析
3.1 实验环境和数据集
为了测试本文中所提出算法的跟踪性能,在不同的数据集上进行了对比实验。这5幅红外点状图像序列的详细信息如表 1所示。本文中通过对具有不同背景的5幅红外序列的数据集上对本文中提出的算法进行了跟踪对比实验。本文中所有的实验都是在一台具有一个3.6GHz Intel Core i7 CPU、8G内存的计算机上进行的,并使用MatConvNet工具箱。
Table 1. Data set for the test tracking
| databases | back-ground | image size | frame numbers | target size/pixel(n×n) |
|---|---|---|---|---|
| seq.1 | sunny-sky | 256×200 | 30 | 8×8 |
| seq.2 | missile | 504×396 | 381 | 9×9 |
| seq.3 | could-sky 1 | 250×250 | 170 | 7×7 |
| seq.4 | sea-sky | 250×250 | 342 | 8×8 |
| seq.5 | could-sky 2 | 250×250 | 270 | 7×7 |
| 显示表格
3.2 评价指标
在本文实验中采用3个评价指标来测试跟踪算法的性能。
(1) 重叠率(intersection-over-union, IOU),它主要度量通过跟踪算法估计的目标位置框与目标真实位置框之间的重叠部分[15]:
|
UIOU=A1∩A2A1∪A2UIOU=A1∩A2A1∪A2 |
(9) |
式中,A1为标注的目标框,A2为跟踪的跟踪框,∩为交集操作,∪为并集操作。
(2) 中心位置误差(center location error, CLE),通过计算跟踪框的中心位置之间的欧氏距离,ECLE的值越小,说明该方法更加有效[16]:
|
ECLE=(x0−x1)2+(y0−y1)2−−−−−−−−−−−−−−−−−−√ECLE=(x0−x1)2+(y0−y1)2 |
(10) |
式中,(x0, y0)为目标真实位置的中心坐标,(x1, y1)为跟踪到的目标位置中心坐标。
(3) 准确率(precision plots,PRE),它的定义为:
|
EPRE=rsEPRE=rs |
(11) |
式中,s为红外图像序列总的帧数,r为中心位置误差的值小于阈值的图像帧数[17]。比值越大,说明该算法的跟踪结果越准确。
3.3 实验结果和分析
为了检验本文中提出的算法跟踪红外点状目标的性能,选择了中值光流算法[18]、在线学习及检测(tracking learning detection, TLD)算法[19]、多实例学习(multiple instance learning, MIL)算法[20]等3种常规的跟踪算法作为本文中算法的对比实验。本文中的实验是计算机环境Windows10,3.6GHz Intel Core i7 CPU、8G内存,基于Python实现的。实验中采用的软件开发平台是Microsoft Visual Studio 2015,使用MatConvNet库的MATLAB2014软件。本文中的实验通过对具有不同背景的5幅红外序列的数据集上对4种跟踪算法进行了跟踪。
图 7~图 11中显示了4个跟踪算法在5个不同的红外视频序列上的跟踪结果。绿色框表示目标真实位置框(ground-truth, GT),红色框通过本文中算法得到的跟踪结果坐标框,深蓝色、橙色、紫色框依次分别是通过中值光流算法、TLD算法、MIL算法得到的跟踪结果坐标框。
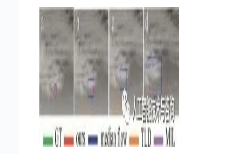
Figure 7. Representative visual results of four tracking algorithms on seq.1 dataset

Figure 8. Representative visual results of four tracking algorithms on seq.2 dataset

Figure 9. Representative visual results of four tracking algorithms on seq.3 dataset
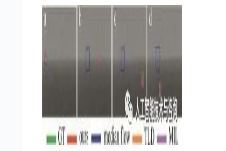
Figure 10. Representative visual results of four tracking algorithms on seq.4 dataset

Figure 11. Representative visual results of four tracking algorithms on seq.5 dataset
在红外视频序列1中(如图 7所示),在第1帧(如图 7a所示),目标与背景的灰度差较小,当点状目标最先从云层中出现时,TLD算法偏移较大,出现丢帧现象,失去了目标。中值光流算法、MIL算法偏移较小。在第10帧(如图 7b所示),中值光流算法偏移较大。从第20帧开始(如图 7c所示),TLD算法和中值光流算法在不同的阶段都失去了目标, 无法再次检测到目标。在信噪比较低的情况下,本文中算法能够准确跟踪到目标。
在红外视频序列2中(如图 8所示),在第180帧(如图 8b所示),中值光流算法、TLD算法和MIL算法偏移较大、失去了目标。在第280帧(如图 8c所示),MIL和中值光流算法都失去目标。在第381帧(如图 8d所示),中值光流算法、MIL算法、TLD算法失去了目标,无法恢复。本文中算法一直稳定地跟踪到目标,而其它3种算法跟踪失败,失去目标。
在红外视频序列3中(如图 9所示),在第1帧(如图 9a所示),MIL算法发生微小的偏移。在第60帧(如图 9b所示),MIL算法和TLD算法初始发生偏移,目标并不处于跟踪区域的中心。在第110帧(如图 9c所示),红外点状目标初步进去云层中,这时中值光流算法、MIL算法中,目标并不处于跟踪区域的中心。在第170帧(如图 9d所示), 目标消失在云层被遮挡时,背景与目标之间的灰度差比较小并且红外背景相对较复杂,中值光流算法失去了目标。尽管是在复杂背景下,本文中算法依然能够有效地准确跟踪到红外点状目标。
在红外视频序列4中(如图 10所示),在第140帧(如图 10b所示),中值光流算法偏移变大,失去目标,无法再次检测到目标,MIL算法偏移较小。在第240帧(如图 7c所示),TLD算法、MIL算法跟踪效果并不稳定,而本文中算法一直稳定地跟踪到目标。
在红外视频序列5中(如图 11所示),在第100帧(如图 11b所示),目标重现在云层中出来,目标区域发生了变化,中值光流算法失去了目标,无法恢复。在第170帧(如图 11c所示),目标开始重新进入云层中,TLD算法、MIL算法中的目标并不在跟踪区域的中心位置。在第270帧(如图 11d所示),目标消失在云层中被遮挡,MIL算法偏移较小,中值光流算法和TLD算法偏移较大,失去了目标,无法再次检测到目标。当目标从非云层区域移动到云层区域时,中值光流算法和TLD算法跟踪失败,MIL算法开始发生偏移,而本文中算法保持了较强的跟踪性能。
综上所述,通过对5幅图像序列的对比,本文中提出的算法在不同的红外场景下稳定地跟踪到目标的同时,还可以保证对整个视频序列的准确跟踪,抗干扰能力较强。中值光流算法和TLD算法的跟踪性能较差,对跟踪过程常存在的如目标遮挡、背景杂波和快速运动等问题解决较差。在突然变化的背景或背景杂波的环境中,本文中算法不仅准确跟踪到目标,而且跟踪结果坐标更加贴近真实目标框。
表 2显示,将本文中算法与中值光流算法、TLD算法、MIL算法的跟踪结果来评价算法的性能, 展现几种跟踪算法准确跟踪的帧数。其中occlusion表示目标被遮挡的总帧数。实验表明,中值光流算法和TLD算法对目标被局部遮挡的情况下跟踪效果比较差,MIL算法有部分未跟踪成功的情况,而本文中算法对整个视频序列准确跟踪。
Table 2. Number of successfully tracked frames(ours in comparison to medianflow, TLD, MIL results)
| sequence | frames | occlusion | medianflow | TLD | MIL | ours |
|---|---|---|---|---|---|---|
| sunny-sky | 30 | 10 | 10 | 1 | 25 | 30 |
| missile | 381 | 0 | 15 | 253 | 43 | 381 |
| could-sky 1 | 170 | 57 | 63 | 165 | 161 | 170 |
| sea-sky | 342 | 0 | 65 | 340 | 277 | 342 |
| could-sky 2 | 270 | 124 | 5 | 217 | 250 | 270 |
| 显示表格
图 12~图 16是本文中提出的算法、中值光流算法、TLD算法、MIL算法等4种跟踪算法在不同背景下的红外图像序列上的重叠率(IOU)、中心位置误差图(CLE)和基于中心位置误差的精确度图(PRE)。从图 12~图 16中清楚地看到,本文中算法的跟踪结果受到的背景杂波和非目标点的影响较小,表明该方法是比较有效的。还可以看出,与其它3种算法相比,本文中算法在不同背景下的性能都是较好的,这表明本文中算法具有更好的跟踪性能。

Figure 12. IOU, CLE, PRE plots of the four tracking algorithms on the seq. 1
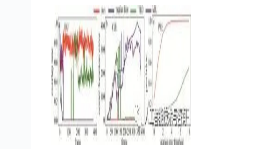
Figure 13. IOU, CLE, PRE plots of the four tracking algorithms on the seq.2
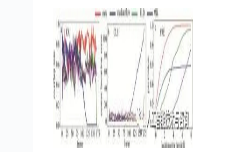
Figure 14. IOU, CLE, PRE plots of the four tracking algorithms on the seq. 3

Figure 15. IOU, CLE, PRE plots of the four tracking algorithms on the seq.4
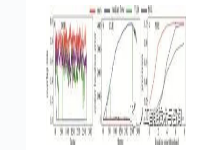
Figure 16. IOU, CLE, PRE plots of the four tracking algorithms on the seq.5
4. 结论
本文中把机器学习的方法运用在红外点状目标跟踪中,使用元学习的线下训练,使得模型可以学习到跟踪目标的通用特征,有效解决了红外点状目标训练数据不足的问题。此外,在长时跟踪过程中,目标可能存在被遮挡、跟踪可能会发生漂移等情况,从而丢失目标,因此,本文中提出重检测机制,重新跟踪到目标,实现稳定跟踪。与此同时,通过卡尔曼滤波算法预测目标运动模型,得到最优的搜索区域。为了验证本文中算法的有效性,对不同背景下的红外图像序列上进行测试,均表现出了良好的性能,实验结果表明了此方法的有效性。同时,与现有方法进行了比较,该算法优于其它几种红外点状目标跟踪算法。在后续的研究中,将在此基础上,结合使用优化算法来进一步提高算法的实时性。
【转载声明】转载目的在于传递更多信息。如涉及作品版权和其它问题,请在30日内与本号联系,我们将在第一时间删除!
关注微信公众号:人工智能技术与咨询。了解更多咨询!
编辑:fqj


















 工商网监
工商网监
评论