 电子发烧友App
电子发烧友App


人工智能技术与咨询
来源:《图学学报》。作者翟进有等
摘要:传统目标识别算法中,经典的区域建议网络(RPN)在提取目标候选区域时计算量大,时间复杂度较高,因此提出一种级联区域建议网络(CRPN)的搜索模式对其进行改善。此外,深层次的卷积神经网络训练中易产生退化现象,而引入残差学习的深度残差网络(ResNet),能够有效抑制该现象。对多种不同深度以及不同参数的网络模型进行研究,将两层残差学习模块与三层残差学习模块结合使用,设计出一种占用内存更小、时间复杂度更低的新型多捷联式残差网络模型(Mu-ResNet)。采用Mu-ResNet与CRPN结合的网络模型在无人机目标数据集以及PASCAL VOC数据集上进行多目标识别测试,较使用ResNet与RPN结合的网络模型,识别准确率提升了近2个百分点。
关键词:无人机;残差网络;级联区域建议网络;目标识别
卷积神经网络属于人工神经网络的一个分支,目前国际上有关卷积神经网络的学术研究进行的如火如荼,且该技术在计算机视觉、模式识别等领域成功得到应用[1-2]。卷积神经网络的优点非常明显,其是一种多层神经网络,通过卷积运算和降采样对输入图像进行处理,其网络权值共享,可以有效减少权值数目,降低模型复杂度,且该网络结构具有高度的尺度不变性、旋转不变性等多种仿射不变性。
近两年的ILSVRC (imagenet large scale visual recognition challenge)竞赛中,在目标检测、分类、定位等项目上前3名的获奖者均使用了神经网络的算法,如文献[3]。在自主目标识别领域,基于机器学习的方法越来越展现出其强大的生命力,学习能力是智能化行为的一个非常重要的特征。随着人工智能的发展,机器学习的方法以其强大的泛化能力,不断在目标识别领域创造突破,也日渐成为计算机视觉各领域的研究主流。
深度卷积神经网络[4-5]为图像分类带来了许多突破[6-7]。深层神经网络以端到端的方式自然地集成了低、中、高级功能和类别[8],功能的“级别”可以通过堆叠层数(深度)来丰富。近年来,在十分具有挑战性的ImageNet数据集上进行图像分类取得领先的结果都是采用了较深的网络。当更深的网络能够开始收敛时,就会暴露出退化的问题,随着网络深度的增加,精度达到饱和(这并不奇怪),然后迅速退化[9-11]。这种降级不是由过度设置引起的,是因在适当深度的模型中添加更多的层而导致了更高的训练误差。
1 深度残差网络搭建
1.1 深度卷积神经网络
在2012年的ILSVRC图像分类大赛上,KRIZHEVSKY等[4]提出了AlexNet这一经典的深度卷积神经网络模型。AlexNet相较于浅层的卷积神经网络模型,在性能上有了巨大的提升,而深层的网络模型较浅层的网络模型具有更大的优势。VGG16网络以及GoogleNet网络不断刷新着ILSVRC竞赛的准确率。从LeNet,AlexNet至VGG16和GoogleNet,卷积神经网络的层数在不断加深。伴随着网络层数的加深,数据量以及运算量也在剧增。卷积模块的数学表达为
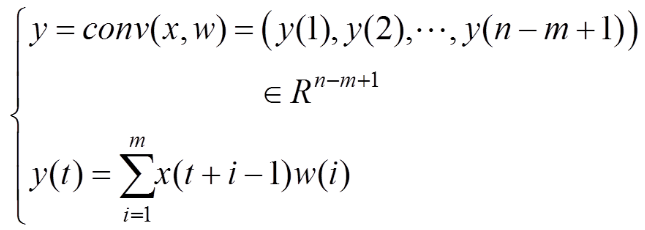
(1)
其中,x为输入信号;w为卷积核尺寸大小且Rs×k,Rn×m,,且n>m。卷积操作的核心是:可以减少不必要的权值连接,引入稀疏或局部连接,带来的权值共享策略大大地减少参数量,相对地提升了数据量,从而可以避免过拟合现象的出现;另外,因为卷积操作具有平移不变性,使得学习到的特征具有拓扑对应性和鲁棒性。
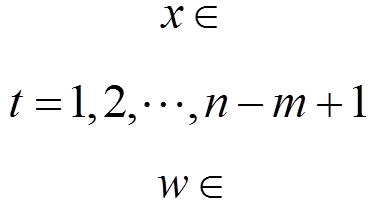
1.2 深度残差学习机制
当卷积神经网络层数过深,容易出现准确率下降的现象。通过引入深度残差学习可以有效解决退化问题。残差学习并不是每几个堆叠层直接映射到所需的底层映射,而是明确地让其映射到残差层中[12]。训练深层次的神经网络是十分困难的,而使用深度残差模块搭建网络可以很好地减轻深层网络训练的负担(数据量)并且实现对更深层网络的训练[13]。残差网络的学习机制如图1所示。
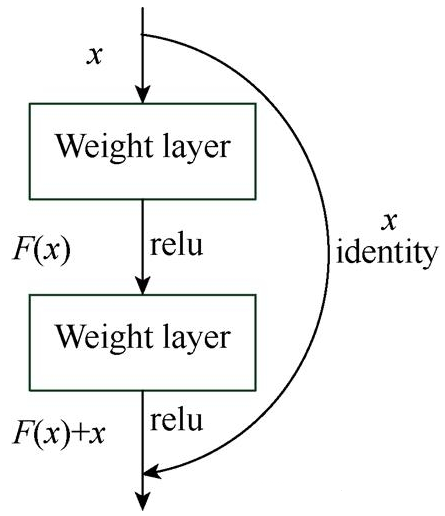
图1 残差网络学习模块
残差学习模块也是深度卷积神经网络的一部分[12]。现假设残差学习模块的输入为x,要拟合的函数映射即输出为H(x),那么可以定义另一个残差映射为F(x),且F(x)=H(x)–x,则原始的函数映射H(x)=F(x)+x。文献[12]通过实验证明,优化残差映射F(x)比优化原始函数映射H(x)容易的多。F(x)+x可以理解为在前馈网络中,主网络的输出F(x)与直接映射x的和。直接映射只是将输入x原封不动地映射到输出端,并未加入任何其他参数,不影响整体网络的复杂度与计算量。残差学习模块的卷积层使用2个3×3卷积模块,进行卷积运算[13-14]。引入了残差学习机制的网络依然可以使用现有的深度学习反馈训练模式求解。
另一种3层残差学习模块,与2层不同的是第一个卷积层采用了1×1的卷积核,对数据进行降维,再经过一个3×3的卷积核,最后在经过一个1×1的卷积核还原。这样做既保存了精度,又能够有效地减少计算量,对于越深层次的网络效果往往更好。图2为3层残差学习模块,由于其是先降维再卷积再还原,这种计算模式对于越深层次的网络训练效果越好。
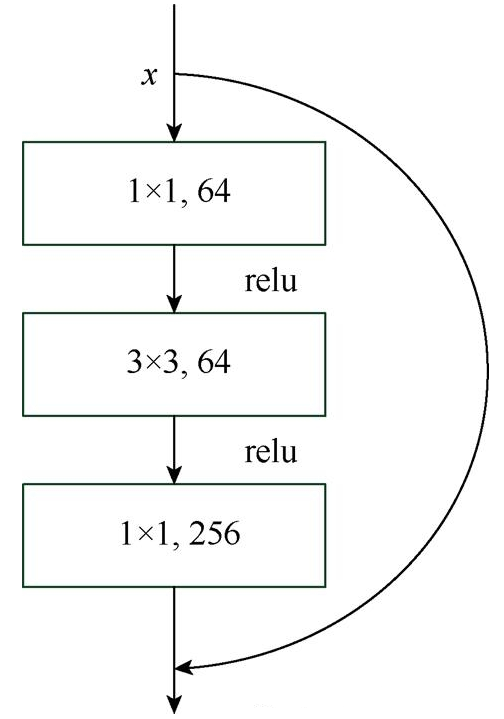
图2 3层残差学习模块
1.3 搭建深度残差网络模型
本文设计出一种包含多条捷径通道的多捷联式残差学习模块,结合文献[10]中2种残差模块的优势,多捷联式残差模块使用了5层的堆栈,由1个1×1的卷积层进行降维,再经过3个3×3的卷积层,最后经过一个1×1的卷积层还原。在第一个1×1的卷积层之前和第二个3×3的卷积层之后使用一条捷径,第三个3×3的卷积层之前和最后一个1×1的卷积层之后使用一条捷径,再将第一个1×1的卷积层之前和最后一个1×1的卷积层之后使用一条捷径。通过设置多条捷径减轻网络的训练难度,采用降维以卷积的方式减少训练的时间复杂度。多捷联式残差模块如图3所示。
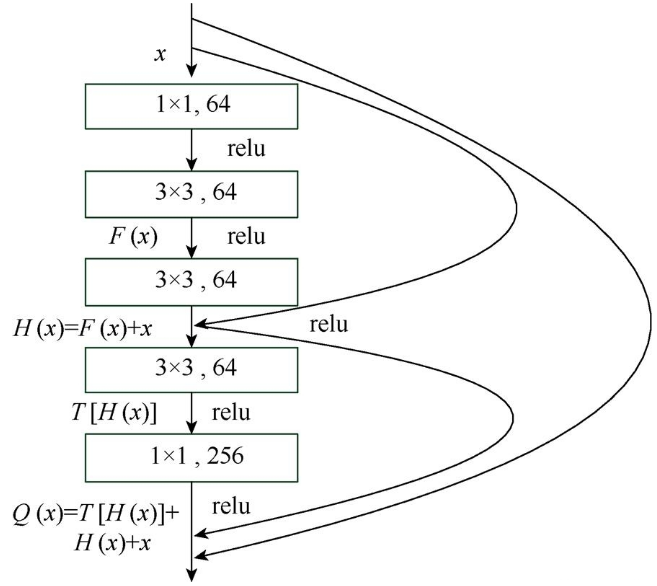
图3 捷联式残差模块
前三层卷积层定义为多捷联式残差模块的第一级,后两层网络定义为第二级。现假设多捷联式残差模块的输入为x,第一级的残差映射为F(x),要拟合的函数映射即第一级的输出为H(x),则
F(x)=H(x)–x (2)
第二级输入函数为H(x)=F(x)+x。第二级残差映射为T[H(x)],第二级的输出Q(x),即
Q(x)=T[H(x)]+H(x)+x (3)
Q(x)为多捷联式残差学习模块的最终输出,该模块设置了多条捷径,在深层的网络中训练更易收敛。
针对输入为任意大小的多类别目标图像,无人机(unmanned aerial vehicle,UAV)目标识别系统采用卷积神经网络和残差学习机制结合。采用五层残差学习模块搭建了多种不同深度的残差网络(multi-strapdown ResNet,Mu-ResNet)。
2 无人机目标识别算法
2.1 级联区域搜素网络
在Faster-RCNN算法出现之前,最先进的目标检测网络都需要先用区域选择建议算法推测目标位置,例如SPPnet和Fast-RCNN虽然都已经做出来相应的改进,减少了网络运行的时间,但是计算区域建议依然需要消耗大量时间。所以,REN 等[15]提出了区域建议网络(region proposal network,RPN)用来提取检测区域,其能和整个检测网络共享所有的卷积特征,使得区域建议的时间大大减少。
简而言之,Faster-RCNN的核心思想就是RPN,而RPN的核心思想是使用CNN卷积神经网络直接产生region proposal,使用的方法就是滑动窗口(只在最后的卷积层和最后一层特征图上滑动),即anchor机制[15]。RPN网络需要确定每个滑窗中心对应视野内是否存在目标。由于目标的大小和长宽比不一,使得需要多种尺度和大小的滑窗。Anchor给出一个基准窗的大小,按照不同的倍数和长宽比得到不同大小的窗[15]。例如,文献[15]给出了3种面积{1282,2562,5122}以及3种比例{1∶1,1∶2,2∶1}共9种尺度的anchor,如图4所示。
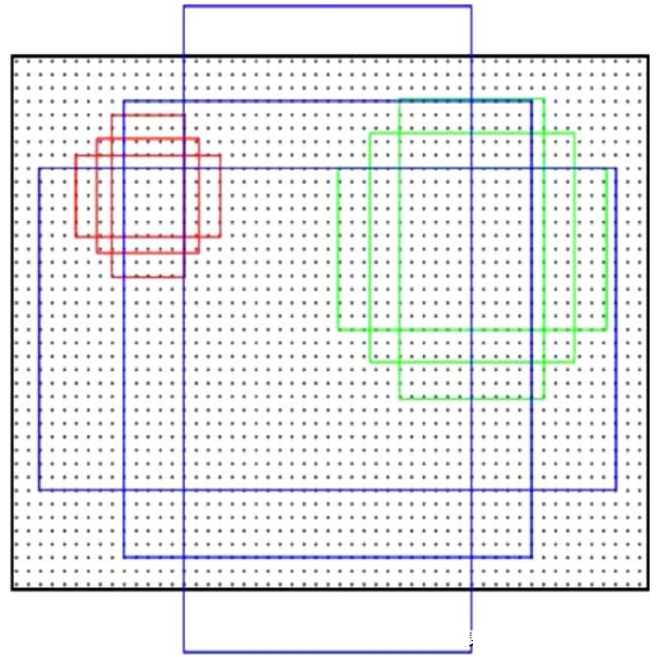
图4 anchor示意图
考虑到经典的RPN网络搜索区域过多,提取目标候选区域时计算量大,导致时间复杂度较高。本文提出一种级联区域建议网络(cascade region proposal network,CRPN)的搜索模式,第一级CNN采用32×32的卷积核,步长为4,在W×H的特征图上进行滑窗,得到检测窗口。由于搜索区域尺度较小,通过第一级CRPN可以过滤掉90%以上的区域窗口,最后在采用非极大值抑制(non-maximum suppression,NMS)消除高重合率的候选区域,可大大减少下级网络的计算量以及时间复杂度。
将32×32网络最后得到的目标候选区域调整为64×64,输入第二级CRPN,再滤掉90%的候选区域窗口,留下的窗口再经过NMS消除高重合率的候选区域。
最后将第二级CRPN输出的候选区域调整为128×128,经过同样的操作滤掉背景区域。最后通过NMS去除高度重合区域,最终得到300个矩形候选区域。CRPN模型如图5所示。
图5 级联区域搜索网络
经过级联区域搜索网络输出的每一个位置上对应3种面积{1282,2562,5122}以及3种比例{1∶1,1∶2,2∶1}共9种尺度的anchor属于目标前景和背景的概率以及每个窗口的候选区域进行平移缩放的参数。最后的候选区域分类层和窗口回归层可采用尺寸为1×1的卷积层实现。
2.2 目标识别网络数学模型
目标识别网络的第一部分是以ResNet为模型提取特征图作为RPN输入。经过ResNet共享卷积层厚的特征为
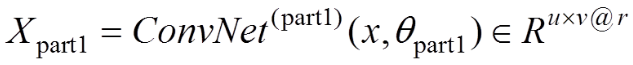
(4)
其中,输入图像为,通过残差网络的共享卷积层实现特征提取,提取的特征(输出)为,即有r个特征图,其尺寸为u×v;待学习的参数(权重和偏置)记为。
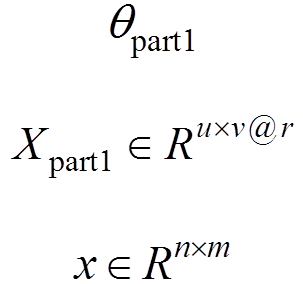
通过共享卷积层提取特征图之后,利用区域生成网络实现候选目标区域的提取。对于区域生成网络的训练,是将一幅任意大小的图像作为输入,输出则是候选目标(矩形)区域的集合,并且对每个(矩形)区域给出是否为目标的得分,即
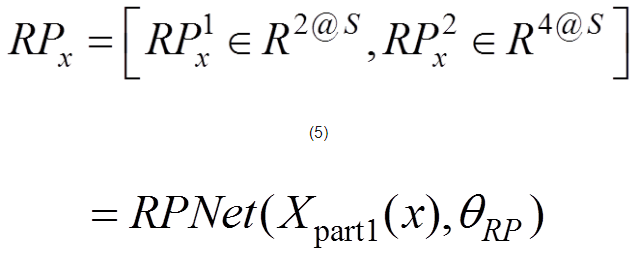
(5)
其中,x为输入的图像信息;RPx为输出;S为候选目标区域(矩形)个数;为判断每个目标候选区域的得分,即
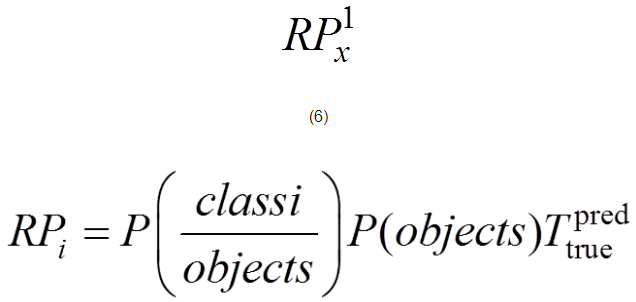
(6)
其中,P(objects)为该矩形框中是否有目标;P(classi/objects)为在有目标的情况下目标属于第i类的概率;为该预测矩形框与真实目标边框之间的交集与并集的比值。对于每一幅特征提取图,选取得分大于0.7的kn个候选区域(矩形)作为正样本,小于0.3的作为负样本,其余的全部舍弃。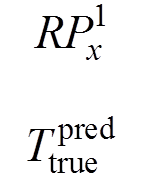
将区域生成网络的输出结合特征提取图作为输入,得到目标识别网络的第二部分,即Fast-RCNN网络。在共享卷积层后得到
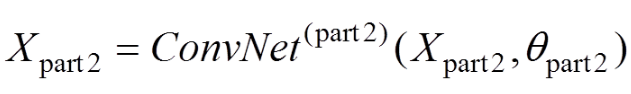
(7)
这一层卷积网络是利用特征图Xpart1来生成更深一层特征Xpart2,其中待学习的网络参数为θpart2。感兴趣区域(region of interest,ROI)的池化层输出为
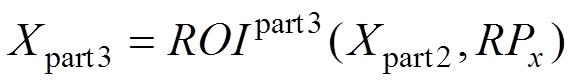
(8)
其中,输入为区域生成网络得到的候选区域RPx和式(8)中的Xpart2,但是因为目标候选区域的尺寸大小不同,为了减少裁剪和缩放对信息造成的损失,引入单层空域塔式池化(spatial pyramid pooling,SPP)来实现对不同尺寸图像的输出。最后经过全连接层输出为
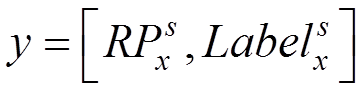
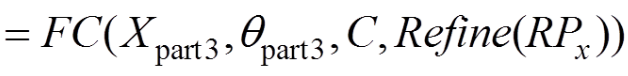
(9)
输出y包含目标区域位置和目标区域类别2部分。其中输入为式(9)中的Xpart3和目标的总类别个数C以及对每一类所对应的目标区域进行精修的参数Refine(RPx),即目标矩形区域中左上标与长宽高等滑动窗的位移,其中c=1,2,···,C。对于每一幅输入图像,可能存在的目标区域个数为s=1,2,···,S。
3 目标检测实验
3.1 Cifar10
Cifar10数据集共有60 000张彩色图像,每张图像大小为32×32,分为10个类,每类6 000张图。数据集中有50 000张图像用于训练,构成了5个训练集,每一批包含10 000张图;另外10 000张用于测试,单独构成一批测试集。数据集和训练集图像的选取方法是从数据集10类图像中的每一类中随机取1 000张组成测试集,剩下的图像就随机排列组成了训练集。训练集中各类图像数量可不同,但每一类都有5 000张图。
本文以文献[10]中的残差网络形式搭建多种不同深度的经典残差网络模型,而后又以本文提出的5层残差模块为基础,搭建了22层、37层和57层的残差网络模型,最后将本文的不同ResNet模型网络的分类效果与经典残差网络模型进行对比。
图6是文献[10]与本文设计的网络性能对比图。图中ResNet网络表示文献[10]中的网络,Mu-ResNet表示本文设计的网络。随着网络深度的增加,训练误差均不断减小,网络性能变的更优。Mu-ResNet在22层时误差高于ResNet,到37层时误差低于ResNet,当继续加深网络至57层式,误差下降近一个百分点。实验结果表明,残差网络的收敛速度在迭代2 k以前较快,随后减慢,在迭代3 k左右准确率快速下降,当到32 k时则开始收敛。
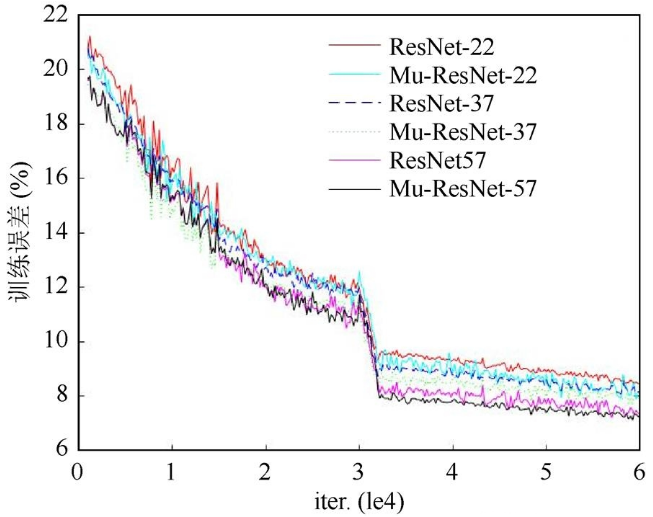
图6 残差网络性能对比图
图7为本文搭建的3种不同深度的残差网络训练cifar10的准确率,由图可知深层次的Mu-ResNet-57准确率比Mu-ResNet-22高出了3个百分点。本文设计的网络模型减少了内存、时间复杂度和模型大小,使得同样深度的网络具有更好的性能,且网络性能在更深层的优化越明显。
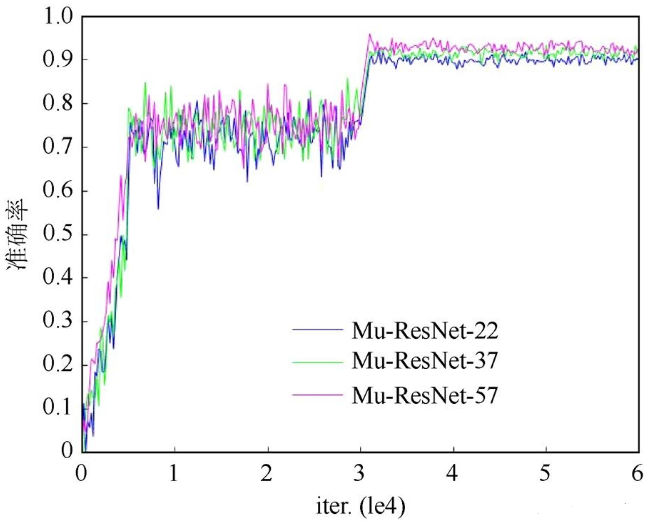

图7 Mu-ResNet准确率曲线
通过cifar10实验结果表明,本文提出的Mu-ResNet在目标分类上具有较好的效果。相比于经典残差网络不仅减少了内存、时间复杂度,在准确率上也有了一定的提升。从22、37、57层的Mu-ResNet准确率在不断提升(图6),且在训练的过程中未观察到退化现象,因此可从增加深度上显著提高准确度。所有评估指标都体现了深度的好处。更深层的网络能够更好地提升Mu-ResNet的性能。
3.2 无人机目标识别
UAV执行目标识别任务主要包含飞机、行人、小汽车、大型公交车、船以及飞行的鸟等10类常见目标。数据源主要来源于ImageNet,各大开源数据库以及通过UAV航拍的图像共100 000张。其中将70 000张图像作为训练集,30 000张作为测试集。
为了研究不同性能参数的特征提取网络对识别效果的影响,共搭建了3种不同深度的网络进行性能测试。22、37、57层的ResNet分别为Mu-ResNet-22,Mu-ResNet-37以及Mu-ResNet-57。
为了进行横向对比,将以上网络与VGG16,ZF和经典残差网络结合经典区域搜索网络进行性能比较。通过在UAV目标数据集上进行训练,测试得到各网络模型在测试集上的识别准确率以及检测每张图片的时间。
Mu-ResNet-57的识别准确率略高于ResNet-57,但检测时间更少;Mu-ResNet-22和Mu-ResNet-37的整体性能也优于VGG16和ZF网络。采用本文提出的5层残差学习模块搭建网络模型能够更有效地提高算法的性能,在计算时间和识别精度上都有所提升。
将ZF,VGG16,ResNet-57和Mu-ResNet-57结合CRPN,得到在UAV目标数据集上的召回率曲线。
当目标候选区域更少时,IOU更大,ResNet-57和Mu-ResNet-57的召回率较慢,当IOU在0.70~0.75区间内Mu-ResNet-57效果最好。在IOU过小(<0.60)时,提取候选区域过多,严重影响网络的速度,在IOU过大(>0.80)时,提取候选区域过少,导致召回率较低。
在十万张图像的UAV数据集上,VGG16,ResNet-57和Mu-ResNet-57与经典区域搜索网络和级联区域搜素网络相结合,对每一类目标的检测准确率。RPN的proposal参数采用文献[15]中效果最好的2 000。本文提出的CRPN中proposal参数取1 000。由表2可知,Mu-ResNet对airplane,human,automobile,truck的分类效果要优于VGG16和ResNet,对ship,bird,horse的分类效果要差于ResNet。而采用CRPN的性能整体要优于RPN。
通过以上实验,综合考虑检测每幅图像的时间以及检测的准确率,采用5层残差学习模块搭建的57层Mu-ResNet结合CRPN在数据集上能达到90.40%的识别率且检测每张图像只需要0.093 s,故该网络模型较适合用于UAV目标识别。
3.3 PASCAL VOC
PASCAL VOC 2007数据集作为经典的开源数据集,包含5 k训练集样本图像和5 k测试机样本图像,共有21个不同对象类别。PASCAL VOC 2012数据集包含16 k训练样本和10 k测试样本。本文使用VOC 2007的5 k和VOC 2012的16 k作为网络的训练集,使用VOC 2007的5 k和VOC 2012的10 k作为网络的测试集。采用ZF,VGG16,文献[10]中提出的ResNet和本文中搭建的Mu-ResNet-57模型分别与文献[15]中的RPN和本文提出的CRPN结合,来评估网络的平均检测精度,在VOC 2007+2012数据集上检测结果见表3。
将Mu-ResNet-57与CRPN结合在VOC2007+2012数据集上测试,准确率达到76.20%。采用较深层网络ResNet-57和Mu-ResNet-57模型提取特征时,CRPN效果较RPN有所提升。而采用浅层网络ZF和VGG16模型时,CRPN与RPN对结果影响基本无区别。
以New-ResNet-57结合CRPN进行测试的结果图。对于飞机、汽车、行人、鸟类等目标的识别具有良好的效果,该网络模型对大小不同的物体识别效果均较好,具有良好的适应性。
4 结束语
针对UAV目标识别的实时性与准确性要求,以卷积神经网络为基础,搭建了多种框架的ResNet模型进行训练,并且通过比较各网络的性能优劣,最终找到最适用于UAV目标识别的网络。基于ResNet的目标识别算法,相较于传统的目标识别算法可以避免人为提取目标特征而带来的误差,在识别精度上有了巨大的提升。对于复杂背景下的目标,ResNet的捷径反馈机制能够有效地降低网络训练的难度,使得更深层次的网络依然能够有效地训练使用。使用ResNet的目标检测应用于UAV目标识别中,通过准确率与检测时间的综合性能考虑要更优于传统的深度卷积神经网络。
然而本文所研究的目标数据集依然较少,在以后的研究中需要获取更大、更多的UAV目标数据集,并且搭建更深层次、性能更优的网络以及更高效的特征提取来提高目标检测的准确率与检测时间。
关注微信公众号:人工智能技术与咨询。了解更多咨询!
编辑:fqj



























 工商网监
工商网监
评论