 电子发烧友App
电子发烧友App


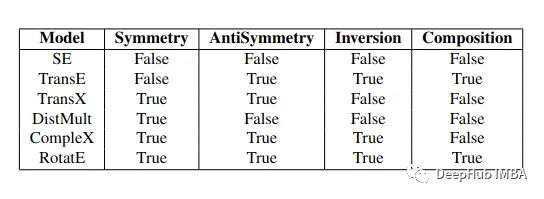
规则引导的知识图谱联合嵌入方法
人工智能技术与咨询
本文来自《计算机研究与发展》 ,作者姚思雨等
摘 要 近年来,大量研究工作致力于知识图谱的嵌入学习,旨在将知识图谱中的实体与关系映射到低维连续的向量空间中.且所学习到的嵌入表示已被成功用于缓解大规模知识图谱的计算效率低下问题.然而,大多数现有嵌入学习模型仅考虑知识图谱的结构信息.知识图谱中还包含有丰富的上下文信息和文本信息,它们也可被用于学习更准确的嵌入表示.针对这一问题,提出了一种规则引导的知识图谱联合嵌入学习模型,基于图卷积网络,将上下文信息与文本信息融合到实体与关系的嵌入表示中.特别是针对上下文信息的卷积编码,通过计算单条上下文信息的置信度与关联度来度量其重要程度.对于置信度,定义了一个简单有效的规则并依据该规则进行计算.对于关联度,提出了一种基于文本表示的计算方法.最后,在2个基准数据集上进行的实验结果证明了模型的有效性.
关键词 知识图谱;表示学习;图卷积网络;上下文信息;文本信息
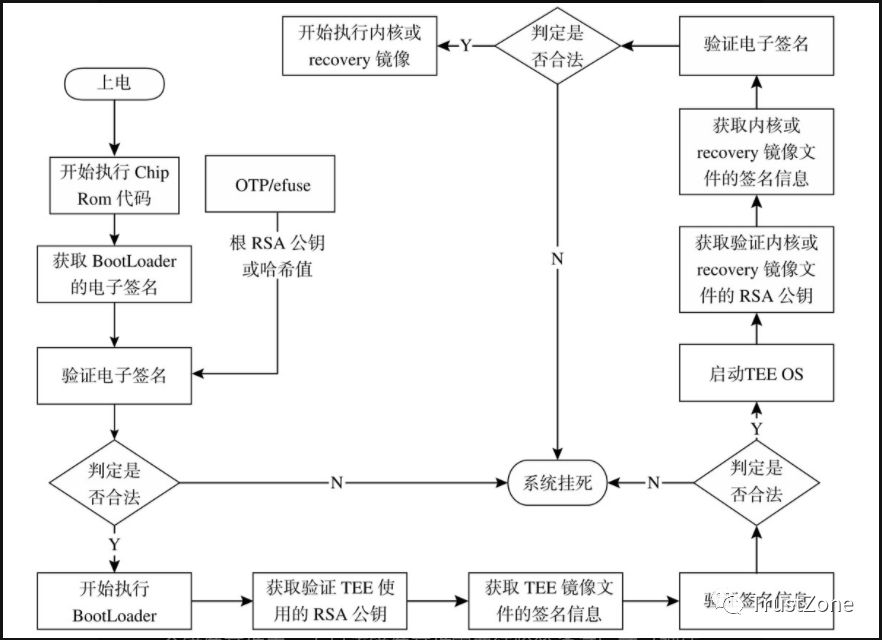
近年来,由于具有表达能力强、歧义性低、模式统一、且支持推理等优点,知识图谱已被广泛用于组织和发布各领域的结构化数据.通常,知识图谱由实体、实体所具有的属性以及实体间的关系所组成.例如,其中可能包含有实体中国、关系首都以及实体属性“China”. 如图1所示,知识图谱的基础构成则是描述2个实体之间的关系或实体及其属性之间关系的三元组,如(中国,首都,北京)、(中国,英语标签,“China”).
Fig. 1 Several triples which contain the entity Beijing and the related literals
图1 包含实体“北京”的若干三元组及文本信息
目前,知识图谱已被广泛应用在智能问答[1]、推荐系统[2]和信息检索[3]等任务中,其突出表现在学术与工业界均获得了广泛关注[4].但是,受益于知识图谱所包含丰富信息的同时,其庞大的规模与数据稀疏性问题也给知识图谱的应用带来了挑战.例如,Freebase[5], Yago[6]和Dbpedia[7]等开放领域知识图谱中通常包含有数百万个实体,以及上亿条描述实体关系的三元组.将子图匹配等传统图算法应用在这些大规模知识图谱上往往存在计算低效性问题.为此,研究人员提出了知识图谱嵌入学习模型(knowledge graph embedding learning model),将知识图谱映射到低维、连续的向量空间中,学习实体与关系的嵌入表示[8].
通过设计特定的表示学习机制,知识图谱的结构和语义等信息可被编码在所学习到的嵌入表示中.一方面,原本需要对大规模知识图谱进行频繁访问的操作,例如结构化查询构建(structured query construction)[9]、逻辑查询执行(logical query pro-cessing)[10]和查询放缩(query relaxation)[11],均可在所学习到的嵌入表示空间中通过数值计算完成,极大地提高了效率.另一方面,知识图谱的嵌入学习提供了一种抽取并高效表示知识图谱特征信息的方法,类似于自然语言处理领域中被广泛应用的词嵌入(word embedding),知识图谱的嵌入表示也为基于知识图谱的深度学习工作提供了极大的便利.
现有知识图谱嵌入学习模型大多仅关注知识图谱中以三元组表示的结构信息.例如,Bordes等人提出了基于翻译机制(translation mechanism)的TransE模型[12],其目标任务为链接预测(link prediction)与三元组分类(triple classification),概括而言就是判断知识图谱中给定的2个实体之间是否存在某个关系.因此TransE模型仅关注所学习到的嵌入表示对单条三元组结构信息的编码,其在嵌入学习过程中将知识图谱简化为互不相关的三元组的有限集合.因此,TransE及其后续改进模型[13-16]对知识图谱中上下文信息的编码能力非常弱,很难应用于语义相关的任务.针对这一问题,相继有一些基于上下文信息的嵌入表示模型被提出,如GAKE[17], RDF2Vec[18].但是它们仍然仅关注知识图谱中由子图、路径等结构所表示的上下文信息.例如,在学习图1中实体北京的嵌入表示时,上述方法仅关注(中国,首都,北京)与(北京,位于,华北)等描述实体间关系的三元组,而忽略了北京的简介、英文标签等文本信息.显然,文本信息的缺失限制了所学到嵌入表示对语义信息的表达.
为解决这一问题,本文提出了一种规则引导的知识图谱联合嵌入学习模型.受Vashishth等人[19]所提出的图卷积网络启发,模型首先通过多关系型图卷积将实体在知识图谱中的上下文信息编码到实体的嵌入表示中.与Vashishth等人的工作所不同的是,本文认为实体的多条上下文信息应该具有不同的重要程度,并且某条上下文信息的重要程度取决于2个因素:该条上下文信息的置信度,以及其相对于实体的关联度.为此,本文提出了一条简单有效的规则引导上下文信息置信度的计算,并基于知识图谱中的文本信息表示提出了实体与其上下文信息之间关联度的计算方法.最后,模型将图卷积网络所编码的嵌入表示与文本信息的向量表示整合,以链接预测任务的结果作为训练目标,学习知识图谱中实体与关系的嵌入表示.
本文贡献主要体现在3个方面:
1) 基于图卷积网络,创新地提出了一种联合考虑知识图谱中上下文信息与文本信息,由规则引导的嵌入表示学习模型.
2) 针对上下文信息在图卷积中的重要程度,提出了应用规则以及知识图谱中文本信息来计算单条上下文信息置信度与关联度的新方法.
3) 在基准数据集上进行了充分的实验,并与相关的知识图谱嵌入学习方法进行了对比,实验结果验证了本文模型的有效性.
1 相关工作
本节对与本文工作较相关的知识图谱嵌入学习模型进行介绍,由于本文所提出的模型是基于图神经网络的,因此分别介绍基于图神经网络的知识图谱嵌入学习模型和其他非图神经网络的嵌入学习模型.
1.1 基于图神经网络的模型
基于图神经网络的模型主要包括R-GCN[20], W-GCN[21], CompGCN[19]等.该类模型通常将图卷积网络作为编码器,对图结构数据进行编码,并结合对应的解码器进行知识图谱上的链接预测、节点分类等任务.在R-GCN中,每层网络中节点与关系的特征利用权重矩阵进行计算,并通过领域聚合的方式传递至后续网络层.具体而言,R-GCN利用基分解和块对角分解构造特定关系的权重矩阵,以处理不同类型的邻居关系,将其与邻居节点信息进行融合,并传递到目标实体上进行更新.W-GCN在图卷积网络聚合过程中为每个权重矩阵分配可学习的权重参数,使模型获得更优的实体嵌入表示.CompGCN则提出了针对中心节点的领域信息聚合方法,在理论上使用多种“实体-关系”组合算法对当前主流的基于多关系的图卷积网络模型进行了概括.
1.2 非图神经网络的模型
非图神经网络的嵌入学习模型类别较多,主要包括基于翻译机制的模型,如TransE[12]及其后续改进模型,包括TransH[13],TransR[14],TransD[15],TransAH[16],基于上下文信息的模型,如GAKE[17],RDF2Vec[18],基于张量分解的模型,如ComplEx[22],RESCAL[23].
其中,基于翻译机制的模型应用较为广泛.该类模型通常仅关注知识图谱的结构信息,将实体之间的关系表示为嵌入向量空间中的某种翻译操作(translation operation).以TransE为例,其将知识图谱中的实体与关系都表示在同一个低维欧几里得空间中,以向量表示一个实体或关系.具体而言,对于知识图谱中的一条三元组(h,r,t),TransE 将其中的关系r看作在欧几里得空间中从头实体h到尾实体t的平移操作,即其期望头实体所对应的向量h经过关系所对应的向量r的平移操作后可以非常逼近尾实体所对应的向量t,即h+r≈t.
TransE的翻译机制较为简单,因此可以高效地应用于大规模知识图谱,但同时又限制了其模型的表达能力,使其难以处理一对多、多对一以及多对多类型的复杂关系[14].为解决这一问题,TransE之后相继有一些翻译机制更加复杂的模型被提出.例如,TransH[15]相对于所给定三元组中关系的超平面空间设计翻译机制,TransR[16]则针对知识图谱中的每一个关系额外学习一个矩阵,借助该矩阵将头、尾实体通过线性变换映射到相应的关系向量空间中,然后再计算其翻译机制的损失值.
2 联合嵌入表示学习
本节首先对知识图谱嵌入学习问题进行形式化定义,介绍相关概念的符号表示,然后详细介绍所提出的规则引导的联合嵌入学习模型.
2.1 问题定义
本文将知识图谱表示为
其中
分别代表知识图谱中的实体与关系集合.对于某个三元组
其中头尾实体均属于实体集合,即
其中关系属于关系集合,即
知识图谱的嵌入学习问题在于学习给定知识图谱
中任意实体
与任意关系
的向量表示e,r∈
d,其中为d嵌入表示的维度.本文通过链接预测任务评价所学习到的嵌入表示,该任务可能包括2种情形:给定实体
与关系
基于它们的嵌入表示e,r∈
d,预测另外一个实体
使得存在三元组
或
或者给定2个实体
基于它们的嵌入表示e,e′∈
d,预测一个关系
使得存在三元组
或
对于任意实体
与关系
本文将它们所对应的文本信息表示为le与lr.对于实体
本文将其所有邻居三元组的集合
视为e的上下文,具体而言
为集合
与集合
的并集,且对于
中任意邻居三元组,本文认为其表达了节点e的一条上下文信息.
与Vashishth等人[19]的做法类似,本文也对知识图谱的关系集合进行扩充:
其中
为逆关系集合.具体而言,对于任意三元组
本文在关系集合中增加一条逆关系r-1,并相应地将三元组(et,r-1,eh)添加到知识图谱
中,即
代表自环关系集合,即对于任意实体
在知识图谱
中添加自环三元组,即
此外,本文使用
代表实体e周围邻居实体的集合,
代表实体e周围邻居关系的集合,例如对于图1中的实体北京,其邻居实体集合为{华北,中国,…},邻居关系集合为{位于,首都,简介,英文标签,…}.
2.2 模型整体架构
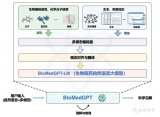
本文基于知识图谱的上下文信息与文本信息联合学习实体与关系的嵌入表示.图2展示了模型的整体架构,针对节点eh,其上下文信息
由包括三元组(eh,ri,eti)在内的所有邻居三元组表达.本文模型利用图卷积网络,基于
将eh的上下文信息编码到其嵌入表示中.并且,本文认为eh的不同邻居三元组所各自表达的上下文信息具有不同的重要程度,通过计算单条上下文信息的置信度与关联度对其重要程度进行度量.
对于置信度计算,本文针对上下文信息中所包含的关系提出一条简单有效的规则,并基于该规则在嵌入学习之前预先计算特定于一对关系的置信度矩阵C,并在图卷积过程中利用该矩阵计算某条上下文信息的置信度,如图2中标有置信度计算的虚线所示.
Fig. 2 An overview of the core part of the model
图2 模型核心部分框架图
对于关联度计算,本文首先利用预训练语言模型对知识图谱中实体与关系的文本信息进行编码.如图2所示,对于实体eh与关系ri的文本leh与lri,它们的文本向量分别记为Leh与Lri.本文基于实体与关系的文本向量表示计算单条上下文信息与其对应实体之间的关联度,如图2中标有关联度计算的虚线所示.
值得一提的是,本文所提出的模型采用“编码器-解码器”框架(encoder-decoder).上述基于图卷积网络的上下文信息编码即为编码器的主要内容.除此之外,编码器还将上述过程学习到的实体与关系的嵌入表示与它们的文本表示相结合.本文模型的解码器则主要基于ConvE模型[24]实现.下面对模型的细节进行详细的介绍.
2.3 编码器
规则引导的置信度计算. 知识图谱中的关系并非相互独立.对于一个实体
当e拥有一条邻居关系
时,这可能暗示其还同时拥有另一条邻居关系
例如,当某个实体的一条邻居关系为首都时,其很可能拥有另外一个邻居关系市长.因为显然只有城市才可能是“首都”,并且其往往拥有“市长”这一上下文信息.本文认为这种关系间的联系可用于对上下文信息的置信度进行估算.因此,本文提出以下规则:对于实体
当其某条上下文信息中包含有关系
并且
中同时存在关系r2,r1≠r2.此时,对于知识图谱中任意实体
出现
的概率越高,相对于e而言包含r1的上下文信息置信度越高.例如,当某个实体拥有一条包含有关系市长的上下文信息时,如果该实体同时拥有关系首都,那么包含有市长的上下文信息置信度较高,因为首都与市长通常同时出现在实体的上下文中.
基于上述规则,本文在进行图卷积网络的训练前首先计算置信度矩阵C∈
表示集合的大小.对于矩阵中的任意参数Ci,j,0≤i,j≤
其计算如下:
(1)
其中,分母表示知识图谱中拥有邻居关系ri的实体的个数,分子表示同时拥有邻居关系ri与rj的实体的个数,i与j在此表示关系ri与rj在关系集合
中的索引.
对于图2中实体eh,当利用其邻居三元组
通过图卷积编码其向量表示eh时,模型会首先基于置信度矩阵C评价eh的各个邻居三元组.例如,图2中邻居三元组(eh,ri,eti)的置信度可以通过式(2)来计算:
(2)
其中,
代表实体eti邻居关系集合,id(·)表示关系在
中的索引.值得一提的是,在本文模型的实现中,置信度计算被整合到了关联度计算中对其进行详细介绍.
基于文本信息的关联度计算.考虑到知识图谱中实体与其不同上下文信息之间关联度的差异,在进行实体嵌入表示的卷积编码时,关联度高的上下文信息应该获得更多的关注.为此,本文借助实体和关系的文本描述作为辅助信息计算实体与其单条上下文信息之间的关联度,用于后续图卷积网络中实体嵌入表示的更新.本文首先将知识图谱中实体和关系的文本描述输入到预训练的BERT[25]语言模型中,得到它们所对应的初始文本表示,然后再分别利用实体文本转换矩阵与关系文本转换矩阵计算它们的最终文本表示.具体而言,对于任意实体
与关系
其对应文本分别为le与lr,它们通过BERT得到的初始文本表示为
与
转换后的最终文本表示为Le与Lr,其中
本文利用实体与关系的文本表示计算对于某一实体而言,其单条上下文信息的关联度.如图2所示,实体eh的一条邻居三元组为(eh,ri,eti),本文计算参数βi与γi来度量该条邻居三元组所表示的上下文信息与eh之间的关联度,具体公式为:
(3)
其中,Lej与Leh分别为实体ej与eh的文本表示,
为实体eti的邻居实体集合.
(4)
其中,Lrj与Lri分别为关系rj与ri的文本表示,
为实体eti的邻居关系集合,Cid(ri),id(rj)如式(2)所定义.
基于图卷积网络的嵌入更新.本文采用Vashishth等人所提出的CompGCN[19]模型作为图卷积网络的架构,对知识图谱上下文信息进行编码.
初始状态下,对于任意实体
与关系
其嵌入表示为随机向量e0与r0,且e0,r0∈
d.以图2中的实体eh为例,其嵌入表示通过以下图卷积过程进行更新:
(5)
其中,
表示实体eh的邻居三元组集合,
或
针对包含有邻居关系ri与邻居节点eti的一条上下文信息,αi基于置信度计算与关联度计算度量该条上下文信息的重要程度,具体如下:
αi=λ1βi+λ2γi,
(6)
其中,βi由式(3)计算得到,γi则由式(4)计算得到;Wt(ri)为CompGCN[19]中定义的关系类别矩阵,由于知识图谱中被加入了逆关系与自环关系,Wt(ri)∈
d′×d可能为3种不同的表示,具体为:
(7)
其中函数f(·)表示循环关联操作(circular correla-tion)[26],可以将2个向量x,y∈
d进行融合,得到x∘y∈
d,每个维度的数值计算为
(8)
遵循CompGCN框架,在对实体进行图卷积编码的同时,本文通过转换矩阵Wr∈
d′×d更新关系的嵌入表示:
(9)
最后,本文将任意实体
与关系
的文本表示加入到其嵌入表示中,具体为:
e=e+Le,
(10)
r=r+Lr.
(11)
2.4 解码器
本文采用ConvE[24]模型作为解码器,基于所学习到的嵌入表示进行链接预测,通过提高链接预测的表现更新模型参数.当知识图谱经过编码器编码后,对于某个任意构成的三元组(eh,r,et),可知其头尾实体eh与et的嵌入表示为eh与et,关系r的嵌入表示为r.ConvE模型首先将eh与r转换成二维形式,即
与
然后计算该三元组的分数值:
sc(eh,r,et)=
(12)
其中,[·]表示相连接,ω表示卷积过滤器,vec(·)为ConvE所定义的维度变换,Wcov为参数矩阵,f′(·)为非线性函数.当式(12)计算得到的分数值越高,(eh,r,et)越有可能是正确的三元组.
3 实 验
本节首先对实验所使用的数据集、对比模型和评价指标等进行说明,然后介绍本文所提模型的实验结果,并与其他基准模型进行比较与分析.
3.1 数据集及对比模型介绍
本文在2个广泛使用的数据集上进行试验,分别是FB15K-237[27]和WN18[12],其统计数据如表1所示:
Table 1 Summary Statistics of Knowledge Graphs
表1 数据集的统计信息
为验证所提模型的有效性,本文广泛选取了当前被应用较多的知识图谱嵌入学习模型作为对比方法,具体包括TransE[11],DistMult[28],ComplEx[22],R-GCN[20],KBGAN[29],ConvE[24],ConvKB[30],SACN[21],HypER[31],RotatE[32],ConvR[33],VR-GCN[34],CompGCN[19].其中,TransE[11]为基于翻译机制的嵌入学习模型,上文已对其进行了详细介绍.DistMult[28]将实体表示为通过神经网络学习到的低维向量,将关系表示为双线性或线性映射函数.ComplEx[22]与RESCAL[23]模型类似,属于基于矩阵/张量分解进行链接预测的模型.R-GCN[20],VR-GCN[34]与CompGCN[19]属于基于图卷积网络的嵌入表示模型,以R-GCN[20]为例,其将知识图谱中的关系编码为矩阵,通过关系矩阵传递相邻实体的嵌入信息,并采用了多层图卷积网络.KBGAN则应用了对抗生成网络(generative adversarial network, GAN),在训练过程中生成更具迷惑性的负例来提高嵌入表示的训练效果.本文应用了ConvE[24]模型作为解码器,在第2节中对其进行了详细介绍.ConvKB[30],ConvR[33],SACN[21]与HypER[31]均是基于卷积神经网络的方法.以HypER[31]为例,其可以生成简化的与关系相关的卷积过滤器,且可被构造为张量分解.RotatE[32]与TransE[11]等基于翻译机制的模型类似,其将实体之间的关系表示为向量空间中从头实体到尾实体的旋转.
3.2 评价方法说明
本文通过链接预测任务来对模型的有效性进行评价.在实验中,针对被事先去掉头实体或尾实体的测试三元组,本文基于学习到的嵌入表示推测其被去掉的头实体或尾实体.具体对于每个测试三元组,本文选取知识图谱中的任意实体作为可能的预测结果,并计算利用该实体补全测试三元组后的分数值,如式(12)所示,最后对分数值进行排序.在此以缺失头实体的预测为例,对于测试集中每个三元组(eh,r,et),事先删除其头实体eh,然后试图使用G中的任意实体
补齐该测试三元组,从而产生候选三元组集合
最后,基于所学习到的嵌入表示计算候选三元组的分数值并进行排序,分数值越高表明学习到的模型,即嵌入表示,认为该结果更可靠,通过与真实结果进行比较从而判段所学习嵌入表示的优劣.
最后采用MR(mean rank),MRR(mean reciprocal rank)和Hit@k作为评价指标[12].其中,MR与MRR均为预测结果平均排名的指标,Hit@k则指预测结果排在前k名中的比例,本文具体采用Hit@10,Hit@3和Hit@1.总之,越好的预测结果,其MR值越低、MRR值越高、Hit@k也越高.
3.3 实验设置
本文实验代码使用Python实现,在配置Ubuntu 16.04.6 LTS操作系统的服务器上完成,其CPU配置为16核Intel Core i7-6900K 3.20 GHz, 内存128 GB,GPU配置为4张GeForce GTX 1080 GPU卡.
对于实体和关系文本表示向量的编码,本文借助pretrained-bert-base-uncased预训练模型(1)https://github.com/google-research/bert,文本向量初始维度为768,转换后的维度为200.在图卷积网络中,实体和关系的初始化向量维度为100,即d=100,GCN的维度为200,即d′=200.解码器中维度转换的高度和宽度分别为10和20,卷积过滤器的大小为7×7,数量为200.利用Adam优化器对整体模型进行训练,批大小(batch size)为256,学习率(learning rate)为0.001.
本文对TransE模型进行了复现,其余模型则引用对比模型论文中所报告的结果.
3.4 实验结果分析
表2报告了本文模型与对比模型在链接预测任务中的实验结果.
通过表2可观察到如下结果:
1) 本文模型在各个评价指标上显著优于TransE,DistMult和ComplEx等基准模型,与SACN,HypER和CompGCN等最新提出的模型十分接近,由此可证明本文模型的有效性.对于FB15K-237数据集,本文在Hit@10指标上排名第一.
2) 在Hit@1和Hit@3指标上也与CompGCN,ConvR,SACN相差极小.具体在Hit@1指标上仅比最高的CompGCN低1.51%,在MRR指标上与CompGCN相比仅低0.8%.而对于WN18数据集,本文模型在MR指标上排名第一,在Hit@10和Hit@3指标上也与第一名差距微小.具体在Hit@10指标上比RotatE低0.2%,在Hit@3指标上比ConvR和HypER仅低0.9%.
3) 基于图神经网络的嵌入学习方法的表现普遍优于TransE等仅关注结构化信息的模型.就本文模型而言,由于其基于图卷积网络对知识图谱的上下文信息与文本信息进行了联合嵌入表示,显著提高了在链接预测任务中的表现.
Table 2 Link Prediction Results on FB15K-237 and WN18
表2 链接预测在FB15K-237和WN18上的结果
Note: The best performance is in bold.
4 总 结
现有多数知识图谱嵌入学习方法仅考虑由三元组表示的知识图谱结构信息,而忽视了知识图谱中丰富的上下文信息与文本信息,限制了嵌入表示在链接预测等任务中的表现.针对现有方法的这一局限性,本文提出一种利用图卷积神经网络,结合知识图谱的上下文信息与文本信息学习嵌入表示的方法.为了对上下文信息的重要程度进行细粒度分析,本文提出一条简单有效的规则来计算上下文信息的置信度,并基于文本信息的向量表示提出计算上下文信息关联度的方法,加强了对上下文信息的约束和引导.最后,通过在2个广泛使用的基准数据集上进行对比实验,验证了本文模型的有效性.
关注微信公众号:人工智能技术与咨询。了解更多咨询!
审核编辑:符乾江



























 工商网监
工商网监
评论