 电子发烧友App
电子发烧友App


多Agent 深度强化学习综述
来源:《自动化学报》,作者梁星星等
摘 要 近年来,深度强化学习(Deep reinforcement learning,DRL) 在诸多复杂序贯决策问题中取得巨大突破.由于融合了深度学习强大的表征能力和强化学习有效的策略搜索能力,深度强化学习已经成为实现人工智能颇有前景的学习范式.然而,深度强化学习在多Agent 系统的研究与应用中,仍存在诸多困难和挑战,以StarCraft II 为代表的部分观测环境下的多Agent学习仍然很难达到理想效果.本文简要介绍了深度Q 网络、深度策略梯度算法等为代表的深度强化学习算法和相关技术.同时,从多Agent 深度强化学习中通信过程的角度对现有的多Agent 深度强化学习算法进行归纳,将其归纳为全通信集中决策、全通信自主决策、欠通信自主决策3 种主流形式.从训练架构、样本增强、鲁棒性以及对手建模等方面探讨了多Agent 深度强化学习中的一些关键问题,并分析了多Agent 深度强化学习的研究热点和发展前景.
关键词 多Agent 系统,深度学习,深度强化学习,通用人工智能
强化学习(Reinforcement learning,RL) 是机器学习的一个子领域,学习如何将场景(环境状态)映射到动作的策略,以获取能够反映任务目标的最大数值型奖赏信号,即在给定的环境状态下,决策选择何种动作去改变环境,使得获得的收益最大[1].同监督式的机器学习过程不同,在强化学习过程中Agent1不被告知应该采用哪个动作,而是通过不断与环境交互,从而试错学习到当前任务最优或较优的策略.这一学习范式能够有效地解决在自然科学、社会科学以及工程应用等领域中存在的序贯决策问题.在强化学习的发展历史中,强化学习和神经网络的结合已有较长的历史[2],但是在复杂序列决策问题中始终没有显著的突破.然而,随着深度学习(Deep learning,DL) 在复杂数据驱动任务中展现出的卓越性能[3-4],一种融合了深度学习强大的特征表示能力和强化学习高效策略搜索能力的学习范式-深度强化学习(Deep reinforcement learning,DRL) 逐渐引起学者的广泛关注,DRL 是将DL 引入到RL,将深度神经网络引入到RL 的值函数、策略函数或者环境模型的参数估计中.DRL 在游戏、机器人、自然语言处理等问题中,取得了令人瞩目的成果[5-12].AlphaGo 的主要贡献者David Silver 更是将现代人工智能定义为RL+DL[13],即DRL 才是人工智能的理想范式[14].赵冬斌等[7] 认为人工智能将会是各国竞相争夺的下一科技高地.
伴随着DRL 在一些复杂单Agent 任务中的有效应用,人们又将DRL 的研究成果转移到了多Agent 系统(Multi-agent system,MAS) 的应用中,以期获得同样的突破.MAS 由一组利用传感器感知共享环境的自治、交互的Agent 组成,每个Agent独立地感知环境,根据个人目标采取行动,进而改变环境[15].在现实世界中,存在许多MAS 的实例,例如资源调度管理[16]、拥塞处理[17-19]、通信传输[20]、自动驾驶[21]、集群规划[22-25] 等.
多Agent DRL (Multi-agent DRL,MADRL)是DRL 在MAS 中应用的研究分支,理论基础源于DRL.虽然将DRL 应用于MAS 中有着许多研究,但据我们所知,尚没有关于多Agent DRL 研究的综述性报告,赵冬斌等[7] 对DRL 以及围棋的发展进行了综述,但其出发点、综述角度以及内容安排与本文有较大不同,如表1 所示.本文在对近些年国内外的研究现状进行分析与研究后,从MADRL 设计与实践的角度出发,对这一领域进行归纳总结.
本文首先对DRL 进行基本的介绍,从策略表现的角度对当前DRL 的两个主要方向,即深度Q 网络和深度策略梯度的发展进行了描述.在第2 节,我们首先分析了DRL 与MAS 的关系,描述了DRL与MAS 结合的优势与挑战; 同时我们利用部分可观测的马尔科夫决策过程对MADRL 问题进行了模型设计,用以表达MAS 的数学过程; 之后,根据当前DRL 的实现结构以及多Agent 在DRL 实现中通信过程的发生阶段,将现有MADRL 划分为全通信集中决策、全通信自主决策以及欠通信自主决策等三类,对每类决策架构的当前研究现状进行讨论分析,对面向多Agent 学习的开放训练平台进行介绍; 在第3 节,针对现有MADRL 仍面临的一些关键问题,从MADRL 的学习训练框架、样本增强、鲁棒性研究以及对手建模等方面进行研究,提出了当前MADRL 可能发展的方向; 在第4 节,对全文进行总结.
1 深度强化学习简介
深度强化学习的学习框架是20 世纪90 年代提出的强化学习,由强化学习与深度学习结合发展而来,是机器学习的重要分支.在这一学习范式中,Agent 通过与环境的交互,不断调整策略,进而实现最大化累计奖赏值的目标.强化学习利用马尔科夫决策过程(Markov decision process,MDP) 对序贯决策问题进行数学定义.
定义1 (马尔科夫决策过程). MDP 由一个五元组〈S,A,R,T,γ〉 定义,其中,S 表示由有限状态集合组成的环境;A 表示可采取的一组有限动作集;状态转移函数T :S×A →Δ(S) 表示将某一状态-动作对映射到可能的后继状态的概率分布,Δ(S) 表示状态全集的概率分布,对于状态s,s′∈S 以及a∈A,函数T 确定了采取动作a 后,环境由状态s 转移到状态s′ 的概率; 奖赏函数R(s,a,s′) 定义了状态转移获得的立即奖赏;γ 是折扣因子,代表长期奖赏与立即奖赏之间的权衡.
表1 与已发表相关论文的研究异同
Table 1 Research′s similarities and differences

与一般的MDP 不同,面向强化学习的MDP中包含感知函数Z :s →z,如图1 所示.在完全观测环境下,Agent 获取完全真实的环境状态,即z=s (在对单Agent 讨论时,真实观测和真实状态通常不予区分).在学习过程中,RL 中的Agent在多个离散时间步同环境进行交互,在时间步t,Agent 从环境中接收状态空间S 中的状态st,根据策略π(at|st),从可选动作空间A 中选择动作at执行,作用于环境,环境根据自身动态性(奖赏函数R(s,a,s′) 和状态转移函数T=P(st+1|st,at)),转移到下一状态st+1,并返回一个标量的奖赏值rt+1(奖赏值是针对下一时刻的奖赏,因而下标是t+1).当环境所处的状态为终止状态或交互达到最大时间步,一次试验结束,进入下一次试验.返回值Rt=
是一个带折扣γ ∈(0,1]的累计奖赏值.Agent 的目标是最大化每个状态值的累积奖赏期望值,即
图1 MDP 示意图
Fig.1 Diagram of MDP
经典的强化学习策略学习方法包括了表格法(Tabular solution methods) 和近似法(Approximate solution methods).当求解问题的状态空间和动作空间规模较小时,往往采用基于表格法的强化学习.表格法将全部的状态值V(s) 或者状态-动作值Q(s,a) 存入到一个带索引的表格中,决策时按指定索引查询状态或状态-动作值,并根据贪婪原则选择动作.在更新过程中,依据一次试验的结果,按索引对参与的状态/状态-动作值以及相关的状态-动作值进行更新.在现实世界中,我们以期解决的问题的状态/动作空间是连续且庞大的[1].在这种情况下,表格法由于容量有限,很难对所有值进行存储,因而在实际操作中应用范围较窄,难以进行扩展.为了降低计算资源和存储资源的开销以及提高决策效率,我们需要通过近似的方法对状态/状态-动作值进行估计.这类算法的应用场景更为广泛,是当前强化学习研究的主要趋势.在近似法强化学习中,根据学习目的以及选择动作的依据,即是否利用状态值/状态-动作值函数的策略贪婪地选择动作,分为两类:函数近似方法和策略梯度方法.在文献[7] 中的第2 节中,对上述方法进行了概述,本文不再赘述.
与基本的强化学习方法相比,DRL 将深度神经网络作为函数近似和策略梯度的近似函数.虽然使用深度神经网络解决强化学习问题缺乏较好的理论保证,但深度神经网络的强大表现力使得DRL 的结果远超预期.在DRL 中,DL 同函数近似结合发展成为了深度Q 学习,而策略梯度则发展为深度策略梯度.
1.1 深度Q 学习及其发展
在深度Q 网络(Deep Q-network,DQN)[6,26]提出之前,强化学习与神经网络(Neural network,NN) 的结合遭受着不稳定和发散等问题的困扰.DQN 做了3 处改进,使用经历重放和目标网络稳定基于DL 的近似动作值函数; 使用端到端方法,利用卷积神经网络(Convolutional neural network,CNN) 将原始图片和游戏得分作为输入,使模型仅需较少的领域知识; 训练了可变的网络,其结果在多个任务中表现良好,超越人类专业玩家[14],如图2所示,利用最近的4 帧视频图片作为状态的描述,通过两层卷积层,一层全连接层输出Agent 可选动作的值估计,采用ε 贪婪选择执行动作.DQN 的网络参数更新方式为
其中,Q(st,at;θt) 表示t 时刻,状态-动作值估计;
rt+1+γmaxaQ(st+1,a;θ-) 是作为临时的目标Q 值,用于稳定神经网络的学习,θ- 表示目标网络的参数,γ 表示奖赏的折扣率;θt 表示正在同环境交互的网络的参数,α 表示神经网络的学习率.
标准Q 学习利用max 操作符使得目标值过高估计,Van Hasselt 等[27] 提出了Double DQN 用于平衡值估计.在利用时序差分(Temporal difference,TD) 算法对目标Q 值进行更新时,后继状态的动作选择来自于当前网络Q,而评估则来自于目标网络
将式(1) 中的
替换为
图2 DQN 架构
Fig.2 Framework of DQN
为了消除强化学习转移样本间的相关性,DQN使用经历重放机制,即在线存储和均匀采样早期交互的经历对神经网络进行训练.然而均匀采样方法忽略了经历的重要性,Schaul 等[28] 提出了优先经历重放,利用TD error 对经历的重要性进行衡量,对重要性靠前的经历重放多次,进而提高学习效率.
此外,在DQN 的模型结构方面,也有着较大的改进.Wang 等[29] 设计了竞争网络结构(Dueling network),在Q 网络输出层的前一隐藏层输出两个部分,一部分估计了状态值函数V(s),另一部分估计了相关动作的优势函数A(s,a),在输出层将二者相加进而估计动作值函数Q(s,a)=V(s)+A(s,a).这一结构使得Agent 在策略评估过程中能够更快地做出正确的动作.Hausknecht 等[30] 将循环神经网络(Recurrent neural network,RNN) 引入DQN中,提出了深度循环Q 网络(Deep recurrent Qnetwork,DRQN) 模型,在部分可观测的强化学习任务中,性能超越了标准DQN.Sorokin 等[31] 提出了基于软硬注意力机制的DQN,使用深度注意力RNN 对同任务相关的单元进行了重点关注.Hessel等[32] 对现有DRL 中的6 种扩展DQN 算法进行了比较,根据各改进对性能提升的贡献,提出了集成多种最优改进的组合版Rainbow 算法.Srouji 等[33]提出结构控制网络(Structured control net,SCN),将深度神经网络分解成为两部分:线性控制模块和非线性控制模块,然后分别对获得的编码进行处理,并将结果进行加和,非线性控制模块进行全局控制而线性模块对其进行补充.
1.2 深度策略梯度及其发展
策略是将状态空间映射到动作空间的函数或者分布,策略优化的目标是寻找最优的策略映射.DQN 算法主要应用于离散动作的空间任务,面对连续动作空间的任务,基于策略梯度的DRL 算法能获得更好的决策效果.
连续动作空间的策略梯度算法分为随机策略梯度算法(Stochastic policy gradient,SPG)[1] 和深度确定策略梯度算法(Deep deterministic policy gradient,DDPG)[34-35] .
SPG 假设在连续控制问题研究中,策略选择具有随机性,服从某种分布(如高斯分布),在策略执行过程中依概率进行动作选择.SPG 计算式为πθ(a|s)=P[a|s,θ],表示在状态为s 时,动作符合参数为θ 的概率分布,如高斯分布πθ(a|s)=
表示Agent 采取的动作服从均值为μ(s,θ)、方差为σ(s,θ)2 的正态分布.在SPG 算法中,即使在相同的状态,每次所采取的动作也可能是不同的.该算法的梯度计算为
其中,τ 表示试验过程,τ={s0,a0,r1,s1,a1,r2,···,sT-1,aT-1,rT,sT} 表示一次试验过程中每个时间步经历的状态、采取的动作以及获得的奖赏;R(τ)=
为试验过程中初始状态的累积奖赏.
DDPG 算法则假设策略生成的动作是确定的,策略梯度的求解不需要在动作空间采样积分.与SPG 的策略表现度量η(θ)=E[Rt] 不同,DDPG的策略表现度量为η(θ)=Q(s,a),如果策略是最优的,则状态-动作值是最大的.DDPG 计算式为a=μθ(s),表示在状态s 下动作的取值.在相同策略(即函数参数相同) 的情况下,同一状态下动作的选择是唯一的.DDPG 算法的梯度计算式为
通过Q 函数直接对策略进行调整,向着梯度上升的方向对策略进行更新.
广义上,DDPG 算法是SPG 的特例,当SPG算法中的方差σ →0 时,SPG 将会收敛到DDPG.SPG 算法的输入需要状态和动作,而DDPG 算法的输入仅依靠状态空间,且当动作空间维度较高时,DDPG 算法的学习效率优于SPG 算法.
与DQN 采用的经历重放机制不同,深度策略梯度采用异步优势Actor-critic (AC) 框架(Asynchronous advantage actor-critic,A3C)[36],如图3所示.利用CPU 多线程的功能异步执行多个仿真过程,这一并行训练方法打破了训练样本间的相关性.相比于传统AC 算法,基于多线程并行训练的A3C 算法,结合优势函数训练神经网络,大幅度提升AC 算法的学习效率.此外,A3C 使用经过tmax步的多步奖赏信号更新值函数网络-Critic 网络,并利用优势函数对Actor 网络进行更新,降低了值函数估计和策略梯度的方差.在A3C 的结构基础上,Babaeizadeh 等[37] 提出了CPU 和GPU 混合架构的GPU-A3C (GA3C),引入了队列系统和动态调度策略,有效利用了GPU 的计算能力,大幅提升了A3C 的训练速度.Jaderberg 等[38] 提出了无监督强化辅助学习(Unsupervised reinforcement and auxiliary learning,UNREAL) 算法,在训练A3C的过程中,兼顾训练两类辅助任务来对算法进行改进,一类是包括像素控制和隐藏层激活控制的控制任务,另一类是回馈预测任务.Wang 等[39] 结合长短时记忆网络(Long short-term memory,LSTM),提出了在不同任务间具有良好的泛化能力的堆栈LSTM-A3C 算法.
图3 A3C 框架
Fig.3 Framework of A3C
在非线性优化问题中,梯度的求解相对容易,但合适的优化步长困扰着函数优化的速率.早期强化学习研究设置步长退火因子,随着迭代次数的增加,逐步减小步长.在强化学习任务中,大多数的策略梯度算法难以选择合适的梯度更新步长,使得NN 训练处于振荡不稳定的状态.Schulman等[40] 提出了可信域策略优化(Trust region policy optimization,TRPO) 处理随机策略的训练过程,在训练中定义了新策略与旧策略的KL 散度,要求状态空间中的每个点的KL 散度有界限,即
KL[πθold(·|st),πθ(·|st)]]≤δ,得到了代理优化目标
利用非线性约束极值方法将代理优化目标转化为
进而保证策略优化过程稳定提升,同时证明了期望奖赏呈单调性增长.在此基础上,该团队继续提出了基于优势函数加权估计的广义优势估计方法(Generalized advantage estimation,GAE),用以减少策略梯度估计方差[18].ACKTR[41] 以Actorcritic 框架为基础,引入TRPO 使算法稳定性得到保证,然后加上Kronecker 因子分解以提升样本的利用效率并使模型的可扩展性得到加强,相比于TRPO 在数据利用率和训练鲁棒性上都有所提升,训练效率更高.Wang 等[42] 汲取其他DRL 算法的优势,提出了基于经验回放的Actor-critic 算法(Actor-critic with experience replay,ACER),采用n-step 的TD 估计,利用偏差修正的截断重要度权重,以及后验TRPO 对网络参数更新,提升了算法性能.TRPO 算法使用二阶优化算法获得海塞矩阵,计算较为复杂,Schulman 等[43] 进一步提出了仅使用一阶优化的近端策略优化(Proximal policy optimization,PPO) 算法,对代理目标函数简单限定了约束,简化了实现和调参过程,性能上优于现阶段其他策略梯度算法,表现出了同TRPO 算法相当的稳定性和可靠性.
2 MADRL 研究
本节首先对DRL 同MAS 间的关系进行讨论,分析DRL 与MAS 结合带来的优势以及挑战.之后,考虑到单Agent 强化学习算法中环境的马尔科夫属性在MAS 中并不适用,标准的强化学习模型及算法无法刻画出环境的动态性,我们对多Agent 的环境动态性以及学习过程进行描述与定义.在这一模型的描述基础上,我们根据DRL 中的神经网络内部各Agent 的信息交互发生阶段(对外则表现为决策架构形式),对当下的MADRL 进行分类,对每一个类型的现有研究进行分析.最后,为方便相关学者的研究,给出了现有公开可用的多Agent 实验平台介绍.
2.1 DRL 与MAS 的关系
多Agent 任务的复杂性使得预置的Agent 策略难以适应多变的环境,Agent 必须依靠自身学习去寻找解决方案,逐步提升Agent 或者整个多Agent系统的性能.RL 算法便于理解,操作简单,为Agent在线学习提供了一种便于接受的范式.在DRL 之前,将RL 应用于MAS 系统已有诸多研究综述.早在2005 年,Panait 等[44] 就对协作多Agent 学习算法进行了广泛的分析,并将其分为两类:单个学习者(团体学习) 和多个学习者(并发学习).Shoham等[45] 对多Agent 学习进行了一般性综述,提出了一些有趣的基础问题,并指出了该领域发展的5 个分支.Tuyls 等[46] 呈现了关于人工智能(Artificial intelligence,AI) 问题的多Agent 学习鸟瞰图,描述了领域内所取得的里程碑成就,并给出了当时的开放挑战.Matignon 等[47] 侧重于协作随机博弈的独立强化学习算法的发展.Bu¸soniu 等[48] 对多Agent强化学习进行了全面的调查,他们提出了多Agent强化学习的算法分类和相关属性.Crandall 等[49] 对两人重复博弈的算法进行了概述,指出了多Agent问题的3 个属性:安全性、合作性和折衷性,他们认为这些属性在各种不同的游戏中扮演着非常重要角色.M¨uller 等[50] 提出了一个面向应用的多Agent概述,重点研究了使用或基于MAS 的应用程序.Weiss[51] 在其关于多Agent 系统专著的第10 章对多Agent 学习算法进行了描述,并对这些算法进行了分类.Bloembergen 等[52] 对演化博弈论的相关研究进行了概述,分析了多Agent 学习与演化博弈论间的关系.Hernandez-Leal 等[53] 从处理MAS 非平稳性问题的角度出发,将现有方法分为忽略、遗忘、响应目标对手、学习对手模型以及心智理论等5类.但是这些研究难以处理高维连续状态空间与连续动作空间的环境,必须对环境特征进行抽取与人为定义,多个模块的联合进一步提升了MAS 的求解难度.而且上述综述都是从多Agent 研究的某一角度出发,研究较早,关注点停留在DRL 兴起前的研究算法,没有对DRL 崛起后的多Agent 系统进行研究.DRL 提供了一种端到端(End to end) 的学习方式,这一学习方式结合了深度神经网络的高容量特性,RL 决策高维连续空间的能力以及现有的硬件计算能力,克服了早期MAS 将任务分解的学习方式,降低了任务的求解复杂度,大幅提高了决策的稳定性,为解决MAS 提供了一种新的思路.
此外,DRL 和MAS 的特性在一些方面可以优势互补.DRL 训练往往需要大量样本进行训练,而MAS 系统的天生并发性,使得多个Agent 可以并发产生大量样本,大大提升了样本数量,加速学习过程以及达到更好的学习效果; MAS 的这一并发性,又使得多Agent 在分散架构下能够充分使用并行计算,提升了DRL 的学习效率; 在MAS 中,新来的Agent 能够接替早些时候的Agent,这使得MADRL 相对于single-agent DRL 具有更强的鲁棒性.现有的MAS 难以处理高维连续的环境,而DRL 能够处理高维度的输入,学习控制复杂的动作;神经网络的内部结构,又可以解决MAS 中的通信问题,克服人为定义通信方式的不足问题.MAS 同DRL 的结合,在带来上述好处的同时,也遭受着自身的以及结合带来的问题:随着Agent 数量的增加,决策输出的动作维度越来越大,动作空间呈现指数增长的趋势; 相对于单个Agent,多Agent 任务更加难以制定学习目标,单个Agent 学习的结果受全体Agent 的影响; 多Agent 的同步学习,使得环境产生了非平稳性,打破了DRL 学习的基本前提; 多Agent 中的探索,更容易使得策略的学习陷入恶性循环,难以获得良好的策略.
2.2 多Agent 学习模型
多Agent 集中决策过程获取全局观测并输出全局联合动作的方式满足MDP 属性,同单Agent 的强化学习方法决策过程类似,可以应用面向强化学习的MDP 对其进行建模,在本节对这一数学过程进行了描述,但这一方式在MAS 中应用有许多缺点,在第2.6 节中将进行讨论.多Agent 自主决策过程可以使用随机博弈理论进行描述,正则形式的博弈是MDP 在多Agent 的环境中的泛化形式,定义如下.
定义2 (正则形式的博弈,Normalform game). 有限参与者的正则形式的博弈由三元组〈N,A,u〉 组成,其中N 表示I 个Agent 的有限集合,i 表示Agent 的索引;A=A1×···×AI,其中,Ai 表示单个Agent 的有限动作集合,向量a=(a1,···,aI)∈A 表示所有Agent 的一次动作集合;u=(u1,···,uI),ui :
表示单个Agent 的真实效用或者收益函数.
正则形式的博弈描述了多Agent 的一次决策过程,但没有对环境状态进行明确定义,不能够描述多Agent 的环境特征以及动态变化特性,如StarCraft II,自动驾驶,多Agent 对抗等非平稳的、不完全的、部分可观测的环境特性.在现有强化学习以及随机博弈理论的启发下,自主决策的多Agent 决策过程可以建模为部分可观测的MDP,定义如下(过程如图4 所示).
定义3 (部分可观测马尔科夫决策过程,Partially observable MDP,POMDP). 面向多Agent 的POMDP 可由八元组G=〈N,S,A,R,T,γ,Z,O〉 定义.在POMDPG 中,N 表示参与决策Agent 的集合,i ∈N ≡{1,···,n} 表示单个Agent;s ∈S 表示环境的真实状态;aaa ∈AAA ≡An 表示参与决策的Agent 的动作集合,ai∈Ai 表示单个Agent 执行的动作;T :S×A×S →[0,1] 表示环境状态转移函数,在状态s 下,执行联合动作a,转移到状态s′ 的概率,即P(s′|s,a); 多Agent 奖赏函数R:S×A×S →R,在状态s 下,执行联合动作a,转移到状态s′ 获得的立即奖赏r(s,a,s′);z ∈Z≡Zn 表示Agent 对环境的部分带噪声(不完全信息) 观测,zi∈Zi 是单个Agent 对环境的观测;O :S × N →Z 表示环境状态s 下,单个Agent 的观测状态函数O(s,i)=zi;γ 是折扣因子,代表长期奖赏与立即奖赏之间的权衡.
在多Agent 环境中,Agent 利用自身的动作-观测历史τi∈Ti=(Zi×Ai)* 以及当前时间步的观测zi,决策Agent 采取动作ai 的概率πi(ai|τi,zi) :Ti×Ui→[0,1],执行后将该动作-观测添加到历史存储中τi←τi×(zi,ai).
在POMDP 中,单个Agent 的状态-动作值函数Q(zi,ai) 的贝尔曼方程表示为
a-i 表示状态s 下,除Agenti 外的Agent 动作集合;p(s|zi) 表示Agent 当前局部观测对应的全局状态的映射关系;π-i(a-i|τ-i,z-i))) 表示对手Agent 在该全局状态下的联合动作概率;P(s′|s,a)表示全局状态和联合动作到下一状态的转移函数;r(s,a,s′) 表示该全局转移下获得的全局奖赏;
表示该后继状态下对手Agent 的联合观测概率;
表示该后继状态与对手联合观测下,Agent 局部观测状态的概率.
图4 面向多Agent 的POMDP Fig.4 Multi-agent-oriented POMDP
2.3 MADRL 分类
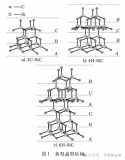
针对目前DRL 在多Agent 学习的最新研究进展,根据DRL 中的神经网络内部各Agent 的信息交互发生阶段,本文将现有MADRL 算法分为以下3 类:
1) 全通信集中决策架构.该决策架构中,多Agent 间的通信过程发生在神经网络内部,多Agent通过自我学习通信协议,决策单元接收各Agent 处理后的局部观测信息,对观测信息进行融合,获得全局信息表征,进而集中决策产生联合动作,以通信的方式指导单Agent 的动作,如图5(a) 所示.全通信集中决策架构通过信息融合,感知全局信息,降低了环境噪声带来的信息损失,此外,通过集中决策方式,有力地对单Agent 的动作进行了协调,使得多Agent 能够按照一致的目标开展行动.但这一架构对系统的时效性要求较高,并对通信系统有很大的依赖,适用于通信时效性要求较低的强化学习场景或一台PC 对多个Agent 控制的任务.
2) 全通信自主决策架构.该决策架构中,多Agent 间的通信过程发生在神经网络之前,单个Agent 利用自组网通信拓扑,接收对手2 Agent 的局部观测信息以及历史动作,采用嵌入式的方法对接收信息进行融合,并结合自身的观测信息(以及对对手的推断信息) 自主决策,进而协作的完成任务,如图5(b) 所示.全通信自主决策架构中各Agent 通过通信获得环境的全局信息,结合对对手行为的推断,自我学习协作的动作,涌现出协同能力.该架构对Agent 间通信时效性要求相对较低,适用于具备通信条件的RL 任务.相对于全通信集中决策架构,全通信自主决策架构在现实中应用更加广泛.
3) 欠通信自主决策架构.在该决策架构中,多采用循环神经网络进行学习,代表Agent 策略的神经网络之间没有信息交互,单Agent 依靠自我观测的能力,获得部分(不完全) 环境信息,结合对对手的观测与推断,进行自主决策,确定采取的行动,以期涌现出协同的联合行为,协调一致的完成任务要求,如图5(c) 所示.欠通信自主决策架构仅依靠自我观测能力,通过观测与推断对手行为,进行自主决策,进而涌现出协同能力.欠通信自主决策架构不依赖通信,适用任一多Agent 环境.由于缺乏通信,欠通信自主决策架构相对上述全通信决策结构,对环境的观测是部分的、不完全的.这种部分观测不仅包含观测的信息有限,也包含观测带来的环境噪声,受环境不确定因素的影响更大.此外,该结构也面临着对手策略变化带来的环境非平稳性问题.
2.4 全通信集中决策架构
图5 多Agent 决策示意图
Fig.5 Diagram of multi-agent decision-making
早期的多Agent 集中决策架构是关于多Agent的动作和观测的联合模型,将多Agent 的联合观测映射到联合行动,训练过程同单Agent 强化学习任务一致,如图6(a) 所示.这一决策架构将多Agent问题转换为单Agent 问题,有效解决了Agent 数量少且固定、动作空间小等MAS 任务中的多Agent间的协同问题.但是对于Agent 数量较多、动作空间巨大的强化学习任务,这一架构将导致联合观测空间s ∈S=|O1|×|O2|×···×|On| 和联合动作空间a ∈A=|A1|×|A2|×···×|An| 随Agent 数量增加呈指数级增长.此外,该架构限定了任务中的Agent 的数量,不能在交互过程中扩展Agent 的数量,即便是同样的环境,不同数量的Agent 也需要单独训练模型,泛化能力弱.
图6 集中决策架构输出动作分类
Fig.6 Output action classification of centralized decision architecture
在现有的多Agent DRL 研究问题中,人们通常将联合动作空间分解,联合动作可以看作是每个Agent 动作的组合,联合策略可以视作多个子策略的组合,这意味着神经网络的输出是单个Agent的动作分布,而不是联合动作分布,如图6(b) 所示.这一改变使得动作空间的大小由
降为
同样,采样类似的方式可以对观测空间进行分解.
在全通信集中决策架构中,现有研究方法主要集中在隐藏层信息池化共享通信和双向RNN 通信等两种手段,通过神经网络的隐藏层间信息传递保证全通信条件下Agent 间的协商.
在基于隐藏层信息池化共享的决策架构中,各Agent 通过内部隐藏层的交互,在决策过程中进行协商,进而输出协同的联合动作.Sukhbaatar 等[54]提出自主学习Agent 间通信协议的方法,采用包含模块fi 的多层架构,利用当前步的隐藏层输出h 和计算获得的通信输出c 迭代地获得下一决策所需的网络输入hK,并根据最终的网络输出q(hK) 选择执行动作.如图7 所示,sj 表示Agentj 的环境状态观测,将所有Agent 的联合观测sss={s1,···,sJ}的相关状态表征作为决策的输入,输出针对单个Agent 的联合动作的结果a={a1,···,aJ}.在中间的隐藏层中,设计出自身隐藏层信息和交互隐藏层信息融合的模块fi,每个Agent 的模块fi 接收两个输入向量:上一阶段传来的隐藏状态
以及通信向量
并输出下一隐藏层信息
其中通信信息为
隐藏层信息为
输出的隐藏层信息为
σ 为非线性的激活函数.该算法采用平均池化
可以克服Agent 数量不定,解决MAS 中算法难以扩展Agent 数量的问题.
图7 基于隐藏层信息池化共享的集中决策架构
Fig.7 Centralized decision architecture based on shared pooling of hidden layers information
基于隐藏层信息池化共享通信的决策架构人为设定通信协议,利用池化方法对信息进行整合,虽然解决了Agent 间的通信问题以及扩展问题,但针对缺乏先验知识的任务,难以设计有效的通信协议.基于双向RNN 通信的集中决策架构利用双向RNN 结构的信息存储特征,自学习Agent 间的通信协议,克服了通信协议设计对任务先验知识的刚性需求.Peng 等[55] 提出了基于AC 的多Agent 双向协作网络(Bidirectionally-coordinated network,BiCNet),Actor 和critic 网络均使用双向LSTM 架构将Agent 串联,在训练过程中,双向LSTM 自行学习通信协议,在输入端利用Attention 机制从全局态势信息中抽取每个Agent 的观测输入,输出行动集合,同样采用基于Attention 机制的双向LSTM对动作集合进行评价.
通信协议的自我学习解决了Agent 间的信息传递规则,但不合适的奖赏会带来虚假奖赏和产生懒惰Agent 等问题,Sunehag 等[56] 提出了全局奖赏下的值分解网络,采用DQN 网络结构,对每个Agent设立独立Q 值,进而求和获得联合行动的Q 值.他们尝试了RNN、Dueling Network 等多种组合,考虑了Agent 间多种通信程度,分别对全通信自主决策架构、全通信集中决策架构以及欠通信分自主决策架构进行了学习框架设计,如图8 所示.
Kong 等[57] 提出一种将集中决策同自主决策相结合的主-从多Agent RNN 学习架构,采用主-从架构,由中心Agent 指导多个真实执行的Agent,充分利用自主决策和集中决策的优势,其中主Agent融合分Agent 的观测信息并总结出指导信息,分Agent 根据指导信息并结合自身局部观测信息做出最终动作选择,类似于足球比赛中教练与球员间的关系.
2.5 全通信自主决策架构
全通信集中决策架构利用神经网络的隐藏层将各Agent 的信息进行融合,使得其必须将部分观测信息在单一的决策主体中进行融合,集中地进行决策,而全通信自主决策架构只需在输入端进行通信,将信息进行本地融合,自主的完成决策过程.
Foerster 等[58] 针对预定义通信协议在部分环境中不可用的问题,提出了自适应的端到端的通信协议学习算法,将通信定义为一组动作,Agent 利用自身观测以及对手Agent 传递的通信动作,采用时序RNN 架构输出通信和决策动作,从而达到协同行动的目的.根据通信动作的连续性,将决策网络的梯度更新方式分为增强和可微两类,如图9 所示,图9(a) 表示增强更新的应用架构,Agent 1 接受来自上一阶段Agent 2 的通信动作
并结合自身的观测
经过Action select 模块,产生传递给Agent 2 的通信动作
和对环境的动作
利用增强算法的梯度传播的思想对动作进行更新; 图9(b) 表示可微更新动作的应用框架,通信动作的产生不再通过动作选择模块,而是直接将神经网络的通信结果经过离散正规化单元(discretise/regularise unit,DRU) 后不经选择地传递给下一Agent,保证通信动作具有可微性,进而对决策网络进行更新.
通信动作的学习虽然有一定的研究意义,但通信动作的定义大多需要相关的领域知识,人们更关注在既定通信协议下或自学习通信协议下,通过本地的态势融合感知获得决策的结果.在既定通信协议下,Usunier 等[59] 定义了一种短期、低层次的微操强化学习任务,各Agent 将以通信的方式获得的局部观测进行联合编码,利用用于推断的贪婪MDP,通过多阶段的对手行动推理,自主产生协同行动,并利用零阶梯度估计的后向传播策略对行动策略进行更新.Mao 等[60] 提出了一般性的协作Actor-critic网络(Actor-coordinate-critic net,ACCNet),在部分观测的环境中从零学习Agent 间的通信协议,根据协作所处的阶段,提出了AC-Cnet 架构,如图10(b)所示.针对全通信的自主决策结构,他们设计了ACCNet 架构,对局部状态进行嵌入编码,之后利用预定义/自学习通信协议对所有局部状态编码进行联合编码,与待决策Agent 的局部状态结合一同作为决策输入,产生动作.
图8 多种架构下的值分解网络
Fig.8 Value decomposition network for multiple architecture
图9 通信流示意图
Fig.9 Diagram of communication flow
此外,针对个体奖赏带来的“囚徒困境”,自主决策也可采用联合动作评估方法,对行动网络进行更新.在策略执行过程中,Agent 依靠Actor 网络做出行动选择,因而在训练阶段采用联合动作的Critic函数对Actor 网络进行学习更新,不会破坏执行过程中的自主决策架构.Mao 等[60] 利用全局动作奖赏对策略进行评估,有效克服了个体奖赏带来的问题.Yang 等[61] 提出平均场强化学习,利用总体或邻近Agent 间的平均相互作用近似Agent 间的相互作用,个体的最优策略取决于全体动态,而全局动态则根据个体策略集合改变,设计了面向多Agent 的平均场Q 学习和平均场Actor-critic 算法,并分析了解的收敛性.
2.6 欠通信自主决策架构
图10 决策-协同-评估网络架构
Fig.10 Actor-coordinator-critic net framework
同单Agent 的强化学习不同,多Agent 自主决策强化学习任务面临着环境非平稳性的问题.对单个Agent 而言,对手Agent 策略的变化使得环境的状态转移函数随时间变化而变化,即
环境转移函数可表示为
其中o-i,a-i 表示Agenti 的对手联合观测和联合行动.在环境转移函数中,转移
ai,a-i) 是平稳的,不随时间改变; 然而,其他Agent 的策略学习,使得联合策略π(a-i|o-i) 发生变化,导致单个Agent 面临的环境转移
是非平稳的.针对欠通信自主决策面临的环境非平稳,Hernandez-Leal 等[53] 将早期强化学习中处理环境非平稳问题的方法分为忽略、遗忘、响应目标对手、学习对手模型以及心智理论等五类,在此不再赘述.本文结合当前DRL 的发展特性,从经历重放、协作中的“囚徒困境” 以及参数共享等方面对欠通信自主决策的MAS 进行研究.
Tampuu 等[62] 开展了将DRL 应用到多Agent环境中的开拓性研究,但没有考虑环境的非平稳性,通过设计不同的全局奖赏函数,采用两个独立自主的DQN 网络对合作、竞争和合竞等多Agent 强化学习任务进行训练,取得了较好的效果.由于环境的非平稳性,在自主Q 学习强化学习任务中,经历重放机制所存储的经历不能反映当前环境的动态性.Omidshafiei 等[63] 忽略环境非平稳问题,依旧利用经历重放机制,采用分散滞后深度RNN 的Q 网络(Dec-HDRQNs) 架构,克服环境非平稳带来的值估计偏差.他们根据单Agent 的TD error 有选择得对策略进行更新
当TD error 非负时,采用正常学习率α 更新,否则使用较小的学习率进行更新.此外,为了使得策略具有较好的泛化能力,他们采用多任务(Multi-task)对Dec-HDRQNs 的策略进行过滤.Palmer 等[64] 则将Lenient 应用到MADRL 中,随访问次数的增加而增大接受负TD error 的概率,并认为在实验中先进行普通Q 学习,再进行Double Q 学习的混合Q学习有更好的学习效果.Foerster 等[65] 则针对环境非平稳性的来源,提出了离环境下的重要性采用方法,对内存中的经历进行了重用,并使用指纹法记录环境中其余Agent 的动态变化信息,使得经历重放机制在多Agent 环境中依然适用,离环境下的重要度采样损失函数定义为
其中,
表示除Agenti 外,其他Agent 在当前策略下的联合动作产生概率;
表示除Agenti 外,其他Agent 联合动作在离环境下的产生概率;yl 采用Q 学习的方式获得.
受非全局奖赏的影响,多Agent 合作存在“囚徒困境” 的问题,Mao 等[60] 提出了A-CCNet 架构,如图10(a) 所示,针对欠通信的自主决策架构,设计了不依赖通信的A-CCNet 架构,各Agent 依据局部状态做出动作选择,将局部的状态-动作同对手Agent 的决策结果相结合,进行整体评价.Leibo等[66] 利用纯粹的自主Q 学习方法,为每个Agent单独训练一套参数,重点解决了社会困境中的“囚徒困境” 难题,揭示了社会困境如何影响Agent 间的合作.Facebook AI 研究室[67-68] 在DRL 中利用过往回报来调节自身行为,进而获得较好的合作策略.Menda 等[69] 提出事件驱动的MADRL 方法,将Agent 的动作分为宏观和一般两类动作,宏观动作由事件驱动,而一般动作则是自主决策,利用改进的GAE 算法对策略进行求解,允许Agent 在决策中异步执行,克服了固定时间步混淆事件发生顺序而带来的不利影响.Lowe 等[70] 将DDPG 方法扩展到多Agent 学习,通过观测对手过往行为对对手进行建模,同时构建全局Critic 函数对全局状态-自主动作进行评估,并训练一组Agent 策略提高算法的鲁棒性.
全局Critic 函数虽然克服了“囚徒困境” 问题,但对单个Agent 的Actor 网络改进指导不足,不能衡量单个Agent 策略对全局Q 值的影响程度,即信用分配问题.Foerster 等[71] 提出了基于Actorcritic 的反事实多Agent (Counterfactual multiagent,COMA) 策略梯度方法,采用集中的Critic函数对联合动作进行评估,各Agent 利用独自的Actor 策略网络进行决策.通过固定其他Agent 的行动,使用边际法确定反事实的基线,进而确定每个Agent 的信用分配
利用获得优势函数
(z,(ai,a-i) 对策略网络进行增强更新,获得的最好的实验效果超越了集中决策模型.
共享信息已被证明可以加速强化学习任务的优化[72],尤其是多Agent 强化学习任务.如果Agent是同质的,则可以利用参数共享(Parameter sharing,PS) 的方式,即多个Agent 共用一套网络参数.在PS 机制下,Agent 在训练中可以使用全体Agent 的仿真经历.此外,同样的策略网络,由于不同的Agent 接收不同的观测状态(也可以用相关的序号区分即便同观测的Agent),因而Agent 间可以产生不同的动作.Ellowitz[72] 用强化学习方法,模拟多Agent 优化同一任务的系统,研究了不同Agent 密度和策略共享的影响,发现PS 策略减少了达到渐近行为的时间,使得渐近行为获得较好改善.Gupta 等[73] 将策略梯度、TD error 以及AC等3 种深度强化学学习算法应用到部分可观测的协作多Agent 环境中,在一系列离散和连续的动作空间任务中,使用基于TRPO 的PS 并发训练模式加速了学习过程,并且验证了循环网络的效果优于前馈网络.Chu 等[74] 针对MADDPG 算法[73] 扩展性较差的问题,提出了参数共享的MADDPG 算法(PS-MADDPG),并针对不同的应用环境,提出了Actor-critic 网络均共享、Actor 网络共享而Critic网络不共享、Actor 共享而critic 部分共享(共享的部分为公有特征抽取网络,如CNN 层) 等3 种Actor-critic 共享组合架构.
2.7 多Agent 实验平台
强化学习过程需要不断同环境进行交互,环境对强化学习至关重要,相关单位与个人针对多Agent 强化学习研究开发了多种训练平台.
DeepMind 和暴雪公司合作,开发了一个基于星际争霸II 游戏的强化学习平台(StarCraft II learning environment,SC2LE)[75],描述了星际争霸II 中的观察、行动和奖励规范,并提供了一个基于Python 的开源的接口来与游戏引擎进行通信.除了主要的游戏地图之外,该平台还提供了一套专注于“星际争霸II” 游戏的不同元素的迷你游戏.对于主要的游戏地图,还提供了来自人类专业玩家的游戏数据的训练数据集.另外,还给出了从这个数据训练的神经网络的初始基线结果,以预测游戏结果和玩家动作(https://github.com/deepmind/pysc2).当前针对星际争霸游戏的DRL 研究主要集中在单元控制的微操(Micro-management) 层面,多采用状态间双方血线变化作为奖赏.不同的训练结构对状态有不同的表示方法,可分为单元附近状态的局部观测与所有单元的全局观测.Usunier 等[59] 利用全通信自主决策架构,通过参数共享的方式训练单个网络对多个同类Agent 进行控制,使用无梯度估计对策略网络进行更新,相对其他算法,该方法最多可以控制15 个单元.Peng 等[55] 利用双向LSTM 网络,搭建了全通信集中决策架构,集中的网络决策输出每个Agent 的动作,在不同尺度上具有较好的效果,学习的动作部分具有较好的可解释性.Kong等[57] 结合了集中决策和自主决策的优势,采用主-从架构的全通信集中决策架构,在十个以上单位的对抗中,超越了之前的所有算法.Foerster 等[65] 通过指纹法和重要性权重的方法,重用历史经历,采用欠通信的自主决策架构在较小的战斗场景中取得了不错的成绩.在之后的研究中,Foerster 等[71] 使用了集中的Critic 和分散的Actor 架构的Actorcritic 算法,采用反事实的基线获得动作优势函数,解决了多Agent 问题中的信用分配,在欠通信自主决策架构中取得了最好的效果,而且能够控制十个以上的单元.
上海交通大学开发了一种支持多Agent 强化学习研究和发展的MAgent 平台[76],该平台聚焦含成千上万Agent 的任务和应用.在Agent 间的相互作用中,该平台不仅能够开展Agent 最优策略学习的算法研究,而且能够观察和理解AI 社会中出现的个体行为和社会现象,包括沟通语言、领导力、利他主义.同时,MAgent 具有高度的可扩展性,可以在单个GPU 服务器上托管多达一百万个代理,还为AI 研究人员提供灵活的配置,以设计他们的定制环境和Agent,该平台给出了基于欠通信自主决策的独立Q 学习和A2C 的基线算法(https://github.com/geek-ai/MAgent).在MAgent 平台中,Yang 等[61] 构建了混合合作-竞争的战斗游戏,两支包含64 个Agent 的队伍进行对抗,每个Agent 的状态观测来自于全局状态观测,Q 值对自身动作和周围邻居平均动作的组合进行评估,有效的将多体问题转换为二体问题,并使用了平均场Q 学习和平均场AC 同平台的独立Q 学习和A2C 基线算法进行了对比,平均场算法在胜率和累积奖赏值中远超基线算法.Khan 等[77] 在MAgent 平台中构建了合作、竞争以及合竞等3 种多Agent 环境,采用全通信的自主决策架构的分布式多Agent 策略梯度算法,环境中的每个Agent 可以获得其他Agent 的相对位置与速度、静态障碍物的位置,在所有实验中使用包含100 个隐藏单元的两层全连接层对值网络和策略网络进行估计.所有算法同全通信集中决策的A3C 和TRPO 的基线算法进行比较,3 种环境下收敛速度明显优于基线算法.Chen 等[78] 提出了一种全通信自主决策下的多Agent 分散Q 学习架构,将全局观测与联合动作进行分解,利用分解的Agent 的值函数和剩余Agent 的联合值函数获得当前状态的值函数,采用Duling 架构的设计思想,采用分解Agent 的Q 值函数与当前状态值函数获得当前联合动作Q 值函数.在MAgent 平台下的战斗场景中,同基线算法以及平均场Q 学习算法进行了对比,从杀敌数量、单Agent 单步平均奖赏和全体累积奖赏等方面进行分析,该算法架构取得了很好的效果.
Brodeur 等[79] 提出了一个面向人工Agent 的家庭多模态环境(Household multimodal environment,HoME),在逼真的环境下,从视觉、音频、语义、物理以及与对象和其他Agent 的交互等方面进行学习.HoME 基于SUNCG 数据集,集合了超过45 000 种不同的3D 房屋布局,这个尺度可以促进学习,泛化和迁移.该环境是一个开放源代码,与OpenAI Gym 平台兼容,可扩展到强化学习、基于声音的导航、机器人以及多Agent 学习等任务(https://github.com/HoMEPlatform/home-platform).HoME 侧重于室内3D环境下的图像研究,利用该平台进行多Agent 研究的学者较少,但随着图像技术的发展,室内异质多Agent 协同也将是通用人工智能的热点之一.
此外,Facebook AI 研究室提出一个面向即时战略游戏(Real-time strategy game,RTS) 的广泛的、轻量级的和灵活得多的Agent 强化学习平台ELF (Extensive,lightweight and flexible research platform)[80],实现了具有3 种游戏环境(Mini-RTS、夺旗和塔防) 的高度可定制的RTS 引擎.该平台在Environment-agent 通信拓扑,强化学习方法选择游戏参数变化等方面灵活多样,并且可以托管现有基于C/C++的游戏环境,如ALF(Arcade learning environment).同样开发了相应的Python 接口,利用Python 接口可以返回经历样本,方便进行强化学习训练(https://github.com/facebookresearch/ELF).ELF 提供的为两人对抗的视频游戏场景,同Starcraft 相比,Agent 数量较少,不是多Agent 研究的主流,多为对抗游戏的测试环境.
3 MADRL 中的关键问题及其展望
MADRL 决策架构研究对当前MAS 的强化学习决策结构进行了分析与讨论,但MADRL 仍面临着多Agent 训练要素的研究,即构建何种训练结构可以使得Agent 能够不依赖人类知识而由弱到强的进行学习,如何构建合适的模型能够更加准确的描述MAS,针对特定的MAS 采用何种决策架构等;此外,PS 机制虽然使得单个Agent 拥有足量的训练样本,但当前MAS 系统仿真难度大,总体样本数量依然有限,数据效率低,因而,需要利用已有样本对整体样本进行增强,满足训练的样本量需求以及如何提高数据效率; 同时,DRL 训练通常面临着对环境过拟合的问题,而MADRL 则面临着对对手和环境的双重过拟合问题,需要采用对抗机制提高MADRL 算法的鲁棒性; 在自主决策架构中,受限于不完全环境信息,需要充分考虑对手模型,学习对手行为,进而产生协同行为; 另外,当前多Agent 逆强化学习的研究仍是一片空白.本节针对这些实用技术展开分析与研究.
3.1 多Agent 训练要素研究
单个Agent 的DRL 任务,只需要一个环境和部分环境参数,经过一定时间的训练就可以获得“令人满意” 的Agent.多Agent 任务相比单Agent 任务复杂许多,往往包含较多的因素,并且构建复杂的多Agent 环境往往是不切实际的,而真实环境又难以获得DRL 训练所需的大样本.
AlphaGo Zero[7-8] 利用自博弈的学习方式,不依赖人类知识,从零开始,训练出强大的围棋Agent.虽然AlphaGo Zero 是面向单Agent 的强化学习,但从训练过程分析,其采用了竞争环境的多Agent共享参数训练框架,自博弈的双方Agent 共用一套网络参数,增加了训练的样本量,并通过对抗式的训练架构,在19×19 的简单环境中获得了远远超越环境复杂度的强大Agent.在多Agent 学习中,可以使用类似的训练过程.Bansal 等[81] 针对Agent的行为容量受限于环境容量问题,即环境的复杂度限制了训练Agent 的复杂度上限,提出了一种同AlphaGo Zero 相似的对抗式的训练架构,该架构是无模型的强化学习方法,通过从零开始的课程学习,使得带自博弈的对抗多Agent 环境可以训练出远比环境本身更复杂的行为.尽管这种对抗训练方式在单个独立Agent 环境中取得很大成功,在多Agent也取得一些进展,但并没有类似AlphaGo Zero 的重大的突破.
除了对抗学习架构,博弈论方法为多Agent 研究提供了另外一种思路.Lanctot 等[82] 提出了基于近似最优响应的广义MARL 算法,该算法利用联合策略相关性评估策略的泛化能力,将DRL 策略和实证博弈论分析进行混合,计算策略选择的元策略,对自主强化学习、迭代最优响应、Double Oracle 以及虚构对抗等工作进行了泛化研究.
除了训练架构的研究外,对如何构建MADRL的模型也存在一定的讨论.在对序贯决策的任务建模中,MDP 是当前强化学习算法的主要模型,POMDP 则是多Agent 任务中的一种常见模型.但这一模型不是绝对的.演化博弈论同样可以针对MADRL 进行有效建模.在将博弈理论引入MAS的早期研究中,已经建立了一般强化学习和演化博弈论核心的模仿者动态(Replicator dynamics) 间的形式化联系,在Bloembergen 的综述[52] 中,他们对这一关系进行了讨论,采用无限学习率的极限,研究了由此产生的动力学系统,并深入了解了多Agent 系统的行为,如收敛性、稳定性和鲁棒性,对每个均衡的关注点和产生的回报给予额外的关注,同时对预期的联合交互结果进行评估.
在多Agent 任务的3 种决策架构中,集中决策利用集中方法对多Agent 进行协同,具有无法比拟的优势,在实际的问题研究中,业界人士多采用这种架构[16-19,22].但从理论研究上,研究者们更加关注多Agent 自主决策,希望通过学习、设定目标,使得Agent 在执行任务时能够自发形成期望的协同动作.即便在未能预先知晓对手的任务中,训练出自治的Agent 也能够有效、鲁棒的进行协作,对其他对手提供协同辅助.针对这种“点对点” 的协作已开展了部分研究[83-86],但仍留有很大的研究空间,而且在DRL 领域中还没展开该“点对点” 的协作模式.
3.2 样本增强技术研究
在真实系统上应用强化学习,数据采样速度有限,导致强化学习训练样本不足.Huang 等[87] 提出了增强生成对抗网络(Enhanced GAN,EGAN)初始化强化学习Agent,EGAN 利用状态-行为与后继状态-奖赏之间的关系提高由GAN 生成的样本的质量,以实现更快的学习.Kumar 等[88]为更好理解在线商务中顾客与产品间的关系,利用GAN 生成仿真交易订单,针对在线商务交易的特点,对在线订单构建了密集的低维表示,训练出ecGAN (e-Commerce GAN) 验证框架的合理性,并结合条件GAN 生成指定商品的订单.该方法对多Agent 环境中的数据样本生成提供了行之有效的架构.Andersen[89] 在其硕士毕业论文中研究了用于强化学习的人工训练样本生成模型,利用胶囊网络[90],结合条件GAN 对环境中的图片类状态进行了生成,展示了生成数据对DQN 训练的好处.Corneil 等[91] 介绍了变分状态表(Variational state tabulation,VaST),能够将具有高维状态空间(例如视觉输入空间) 的环境映射到抽象表格环境,使用高效的优先扫描规划方法更新状态操作值.Nishio等[92] 提出了结合神经情景控制(Neural episodic control)[93] 的NEC2DQN 架构,在学习的初始阶段,加速了样本匮乏任务的学习速度.这些方法使用现有的GAN 技术对样本进行生成,并不依赖环境的真实动态性,适用于经历重放机制下的强化学习算法.
上述方法关注于样本的真伪,虽然也有考虑生成样本间的相关性,但并没有考虑环境本身的转移关系.在DRL 研究中,无模型方法数据利用低效,仅仅使用了转移中的奖赏信号,忽视了样本的转移过程; 基于模型的方法有较高的数据效率,但所获得的策略往往不是最优解.Ha 等[94] 将无模型和基于模型的方法进行结合-“世界模型”,利用少数转移样本,通过混合高斯分布的RNN 学习了虚拟环境模型,在虚拟环境中利用进化算法求解策略取得很好的效果.在此基础上,相关学者[95-97] 将“世界模型” 概念推广到更广阔的环境中进行验证,这种梦境下的学习弥补了Agent 同环境的多频次交互.这一学习方式,为克服多Agent 环境中样本不足提供了一种解决思路,但是如何对多Agent 环境中的非平稳性进行刻画,还留有相当大的研究空间.
3.3 鲁棒性研究
在MAS 中,仿真环境同现实环境的差距巨大,这一困境导致在仿真环境中的策略学习的结果难以迁移; 另外,即使策略的学习样本来自于现实环境,学习数据的不足也使得强化学习难以收敛.Pinto等[98] 利用存在对抗对手的环境,对Agent 进行对抗训练操作,对手的对抗性随Agent 能力增强而增强以此提高Agent 的鲁棒性.Pattanaik 等[99] 发现即便很简单的干扰,都会使得DRL 算法性能大幅衰退,针对该问题他们提出了对抗攻击的强化学习算法,设计了简单扰动和基于梯度扰动的两种扰动方式,并对DQN 和DDPG 情况下的扰动以及对抗训练进行了研究,提高算法在参数不确定环境中的鲁棒性.Mhamdi 等[100] 认为在仿真中可能产生的中断是学习过程的一部分,Agent 要有能力在安全的中断中进行学习,并将这些影响它们奖励的干扰与特定的状态联系起来,从而有效避免中断,在联合行动学习者和自主学习者两个学习框架中研究这个概念,并对动态安全可中断性进行了定义,实验证明如果Agent 可以检测到中断,那么即使对于自主学习者,也可以修剪状态以确保动态安全中断.上述研究通过建立带有扰动的环境提高Agent 的鲁棒性.现有研究认为在有限的时间内,DRL 总能在单Agent 任务中寻找到较优的策略,这一学习过程的本质是对训练环境的过拟合,因而在DL 用于克服过拟合的方法在单Agent 的DRL 任务中仍旧适用.而在多Agent 研究中的过拟合问题更加严重,不仅存在对环境的过拟合,同样也存在着对对手的过拟合.双重过拟合问题是MADRL 中的一大难点,决定着MAS 能不能进行可靠的应用.
另外,从迁移学习派生出来的信息也可以推广到多Agent 情景来克服MADRL 的弱鲁棒性,如课程学习.迁移学习算法利用学习中获得的经历来对模型进行泛化,以改善Agent 在不同但相关的任务中的学习效果.迁移泛化能力在非平稳环境中的表现尤为重要,特别是多Agent 中对抗对手模型变化带来的环境的不可预知的变化(协同Agent 的策略变化处于一种可获知的变化).例如,如果对手经常发生变化,已有的先验信息(以模型、规则或策略等形式)将有助于快速制定Agent 的策略.在现有的多Agent 学习中,重复使用对手过去的策略也有体现,是当前克服模型过拟合的一种通用手段[63,81,101].现有技术适用于单个独立的Agent,重用迁移不同Agent 的信息仍是一个有待解决的问题,向Agent提供建议也是一个待发展的方向.
此外,在MAS 中,环境中的Agent 在交互中产生和消亡也是可能的(例如,星际争霸游戏中己方Agent 死亡),这将影响环境以及其他Agent 的策略.针对这类场景,是将每个可能消失/产生的Agent 单独建模,或者利用参数共享,搭建可扩展的训练架构[55,59-60,71,102-103].同时,在大多数多Agent 学习算法中通常假定Agent 间的交互在所有的Agent间同时发生.然而,在现实世界的情况下,情况并非总是如此,这种通信交互往往是异步的,而不同的Agent 具有不同的响应时间.目前的学习算法能否在这些条件下工作仍然是一个悬而未决的问题.
与数量较大的Agent 进行交互往往带来很大的问题,因而现有的大多数算法在环境中仅设置了较少的Agent 进行算法验证.然而,将这些算法应用到大规模Agent 环境中,往往面临着无法适应的问题.为了获得高效和可扩展的算法,人们需要牺牲某些细节,更加关注Agent 对整体最佳响应,而不是个体Agent 的最佳响应.想要克服这一问题,可以通过确定Agent 间交互的程度,考虑Agent 是否应该同某一Agent 进行交互、还是仅将其当作环境的一部分而不进行交互[63,104].
3.4 对手建模研究
在多Agent 任务中,存在着动作探索的风险.当多Agent 同时进行探索时,各Agent 都要面临这种噪声,往往造成全盘皆输的局面.同样的问题也出现在多Agent 深度强化学习设置中[59],在不能进行通信协调的任务中,该问题显得更加复杂.而且在MAS 中,Agent 是多种多样的,在多Agent 系统中可能包含着各种各样的Agent,它们的目标、感知以及奖赏都有可能是不同的.这种混杂的多Agent任务为最优行动的学习带来了极大的挑战.在多Agent 决策中,需要考虑对队友与对抗对手的理解.在全通信中,Agent 通过通信完成了对己方协同Agent 的行为推断,但对对抗Agent 仍需要进行观察与学习; 在欠通信中,Agent 不仅要对协同Agent的行为进行分析与判断,同时也要考虑对抗Agent的行为,对其进行分析与预测.Lowe 等[105] 利用对手的历史行为对对手的策略进行推断,通过最大化对手Agent 的动作概率来近似对手策略,定义损失函数为
其中oj 和aj 表示待近似的Agentj 的观测和实际执行动作,
表示对于决策Agenti 而言的对手Agent j 的近似策略,H 表示策略分布的熵.Rabinowitz等[106] 提出了一种使得机器可以学习他人心理状态的心智理论神经网络(Theory of mind network,ToMnet),通过观察Agent 的行为,使用元学习对它们进行建模,得到一个对Agent 行为具备强大先验知识的模型,该模型能够利用少量的行为观测,对Agent 特征和心理状态进行更丰富的预测.如图11所示,特征网络从POMDP 集合中解析Agent 过去的轨迹,从而形成嵌入表示echar.心理状态表示网络的心智网络解析当前片段中Agent 的轨迹,形成心理状态嵌入emental.然后,这些嵌入被输入至预测网络Prediction net,结合当前状态对Agent 未来行为进行预测,如下一步动作概率
、特定对象被消耗的概率
和预测后继者表示
图11 心智网络
Fig.11 Mind theory neural network
上述对手建模研究聚焦于建立概率模型和参数化策略,He 等[107] 提出了同步学习对手策略和模型的神经网络模型,将对手观测嵌入编码输入DQN中,而不是显式地预测对手动作.使用混合专家架构,无需额外的监督信息即可发现多种策略,并利用估计权重对多个策略Q 值进行加权求和,进而获得最优的行动.Foerster 等[108] 针对合作-竞争的多Agent 学习环境,提出与对手-学习意识(Learning with opponent-learning awareness,LOLA)的学习方法,该模型考虑对手策略的策略更新方式,推理其他Agent 的预期学习,通过对状态值V 1(θ1,θ2 +Δθ2)≈V 1(θ1,θ2)+(Δθ2)T∇θ2V 1(θ1,θ2) 进行一阶泰勒展开,获得决策Agent 的值函数梯度,针对合作对手和竞争对手采用两种不同的更新方式.Hong等[109] 根据预测对手动作的网络,从隐藏层中提取对手的行动意图作为决策依据,设计适应性的损失函数调整训练的关注点,并将RNN 架构引入Q网络的训练中,提出了深度循环策略推断Q 网络(Deep recurrent policy inference Q-network,DRPIQN).Raileanu 等[110] 提出自主对手建模(Self other-modeling,SOM),通过观测对手行动,根据已有的行动意图集以及单独的神经网络在线构建对手模型,判断对手的意图,最终结合当前状态以及自我意图进行决策.
在上述学习算法中往往假设知晓对手的相关域知识,如可正确描述对手观测的属性和特征,然而现实世界中,总有许多事情是不可预知的,总有些实体是不期而遇的.在这种情况下,可以构建一组已知的不确定对手特征表示,通过特定的概率分布来推断正确的对手行为.同样也可以采用多任务学习,构建多个可能的环境和对手对Agent 进行训练.然而在执行中,仍会存在一些之前没有遇到过的对手,不可能构建一个包含全体要素的环境,但现实的世界却有着种种不可预知的要素,如何克服这种不确定性为系统带来的风险,也是值得研究的一个方向.
4 结论
尽管DRL 在一些单Agent 复杂序列决策任务中取得了卓越的效果,但多Agent 环境下的学习任务中任然面临诸多挑战,另一方面,人类社会中很多问题都可以抽象为复杂MAS 问题,所以,在这个领域需要进一步地深入探索.现有多Agent 学习综述多同博弈论关联,但伴随着DRL 的产生与发展,国内外尚没有一份关于MADRL 的综述.我们通过总结近些年深度强化学习以及多Agent 深度强化学习方面的论文,从训练架构以及实现技巧方面着手,撰写此文.MADRL 是DRL 在多Agent 领域的扩展.本文首先对强化学习的基本方法以及DRL 的主要方法进行了介绍与分析; 在此基础上,从通信和决策架构方面对MADRL 进行分类,抽象为全通信集中决策、全通信自主决策、欠通信自主决策三类,并对一些开放的多Agent 训练环境进行了简要介绍; 然后,对多Agent 深度强化学习中需要用到的实用技术进行了分析与讨论,包含多Agent 训练框架、样本增强、鲁棒性以及对手建模等一些关键问题,并根据对这些关键问题的认识,给出MADRL 领域的发展展望,对仍待研究的问题进行了探讨.
随着深度强化学习的继续发展,在MAS 中的应用以及研究也将越来越广泛,但其训练和执行方式也将属于这3 种形式之一.我们的研究旨在对当前的MADRL 研究现状进行整理与归纳,为希望将DRL 应用于MAS 的学者或机构提供一份可供参考的概览.
审核编辑:符乾江















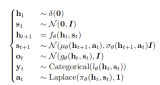






















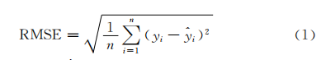





 工商网监
工商网监
评论