 电子发烧友App
电子发烧友App


基于改进SSD的车辆小目标检测方法
来源:《应用光学》,作者李小宁等
摘 要:地面车辆目标检测问题中由于目标尺寸较小,目标外观信息较少,且易受背景干扰等的原因,较难精确检测到目标。围绕地面小尺寸目标精准检测的问题,从目标特征提取的角度提出了一种特征融合的子网络。该子网络引入了重要的局部细节信息,有效地提升了小目标检测效果。针对尺度、角度等的变换问题,设计了基于融合层的扩展层预测子网络,在扩展层的多个尺度空间内匹配目标,生成目标预测框对目标定位。在车辆小目标VEDAI(vehicle detection in aerial imagery)数据集上的实验表明,算法保留传统SSD(single-shot multibox detector)检测速度优势的同时,在精度方面有了明显提升,大幅提升了算法的实用性。
关键词:计算机视觉;目标检测;深度学习;车辆小目标;特征融合
引言
地面目标检测任务[1]中,由于目标外观信息较少[2-3],易受复杂背景干扰等原因,较难精确检测到目标[4]。目前,基于深度学习的目标检测算法[5-6]包括基于候选区域方法及基于回归的方法[7]。Girshick等人最先提出R-CNN(Region-CNN)[8]检测方法,但其存在对同一区域多次重复提取的问题。之后的Fast-RCNN[9]算法仅对原图像进行一次特征提取操作,由于生成候选框的Selective Search 算法[10]耗时较多,检测速度较慢。基于区域推荐方法的另一个主流框架是Ren 等人提出的Faster R-CNN[11]。2016年,Liu Wei 等人提出了基于回归的检测方法SSD[12](single-shot multibox detector),去掉了区域推荐和重采样等步骤,仅在单个步骤完成预测,显著提升了检测速度。
为解决小目标检测难点,本文提出了一种基于扩展融合层的目标检测框架,引入了重要的局部细节信息。此外,本文设计了基于融合层的扩展层预测子网络,在扩展层多个尺度空间内匹配目标,生成目标预测框。为解决过拟合问题,文章采用了数据集增广,BN(batch normalization)[13]层归一化处理的方法。最后,将本文方法与几种主流目标检测算法在VEDAI[14]车辆小目标数据集上进行了对比实验。
1 相关工作
1.1 传统SSD 算法
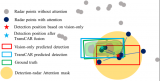
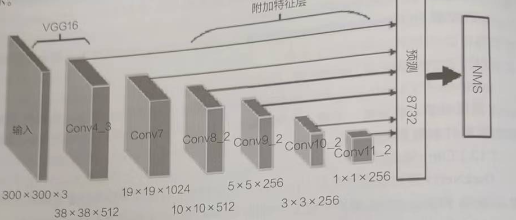
2016 年Wei Liu 提出的SSD 模型结构包括基础网络,附加提取层和预测层3 个部分。传统SSD模型网络结构如图1 所示。基础网络部分提取的特征图将作为附加提取层的输入。

图1 传统SSD 模型网络结构图
Fig.1 Network structure of conventional SSD model
此外,增加了conv6_1、conv6_2、conv7_1、conv7_2、conv8_1、conv8_2、conv9_1、conv9_2 共8 层附加层。附加层对基础网络层提取的特征图做进一步的卷积运算。选取其中6 层特征层作为预测层,分别在预测层的每个位置上生成固定宽高比的边界框预测结果。
1.2 传统FPN 方法
Tsung-Yi Lin 等人提出FPN(feature pyramid networks)[15],用于目标检测包含2 个关键步骤:1) 在每个尺寸特征图的基础上,分别保留了一个包含最强语义信息的特征层。由这些特征层构建出具有层级的特征金字塔结构[16-18]。2) 采用自上而下的结构,对金字塔高层特征层逐层上采样;再分别与下一层的特征图横向连接得到增强后的高层特征层。最后,对横向连接金字塔的每个特征层分别计算目标类别得分和边框回归。
1.3 传统方法检测小目标存在的问题
传统SSD 直接在不同特征层预测结果,忽略了不同层之间的联系,丢失了部分重要信息,缺乏同时获取局部细节信息和全局语义信息的能力。FPN 模型虽然通过横向连接得到融合特征层,但其采用逐层融合的方法,大大增加了计算量,从而降低了模型的检测速度。对小目标识别与检测问题而言,模型忽略了不同特征层对目标预测贡献的差异。
2 基于扩展融合特征的小目标检测算法
为解决车辆小目标识别与精确定位的问题,本文提出了基于扩展融合特征的小目标检测算法,基于融合浅层特征高边缘信息和深层特征的高语义信息的思想,设计了一种轻量化的特征融合模块。将融合特征层经额外的6 层卷积层扩展得到预测子网络,以此作为依据预测目标。本文网络结构中引入BN(batch normalization)层,以加速算法收敛,提升模型的泛化能力。本文算法的整体结构如图2 所示。
图2 基于扩展融合特征的目标检测模型结构
Fig.2 Structure of object detection model based on extension of fused feature
2.1 特征层选择
由于浅层特征图具有更小的感受野,其对应产生的默认边界框大小更适宜小目标检测。但其缺乏目标分类重要的语义信息。深层特征虽包含更多语义信息,但感受野过大,对小目标定位不够精确。因此,考虑在高层特征中引入浅层局部细节信息。本文采用VGG-16 卷积神经网络作为特征提取网络,表1 为部分特征层结构参数。
表1 部分特征层结构参数
Table 1 Structure parameters of partial feature layer
Conv4_3 层之前的特征层,虽然具有更高的分辨率,但包含较少的语义信息,考虑将Conv4_3 层作为浅层特征融合层。更深层的特征中,结合航拍数据集中车辆小目标特点,选取Conv7_2 层作为高层特征融合层。
2.2 特征融合子网络设计
输入图像映射为相同尺寸(300×300)后,经卷积和池化等的计算,特征层尺寸逐层递减。Conv4_3层特征层特征图大小为38×38,维度为512 维,Conv7_2 层特征图大小为19×19。将2 层特征图变换为相同维度再进行连接,得到融合特征层。特征融合子网络示意图如图3 所示。
图3 融合子网络示意图
Fig.3 Schematic diagram of feature fusion sub-network
分别对Conv4_3 和Conv7_2 层采用1×1 卷积层变换通道,降低原特征层维度。再对Conv7_2_new 层采用双线性插值方法,映射为同Conv4_3 相同维度,插值后的特征层Conv7_2_inter 维度为38×38×256。将两层特征层连接得到融合层(维度为38×38×512)。结合浅层局部细节信息和深层高语义信息的融合层作为依据,预测小目标的位置及类别。
2.3 扩展预测子网络设计
本文方法在融合层后增加BN 层以加速网络收敛速度。BN 层前向传导公式为
引入BN 层对输入数据进行归一化操作,消除了权值放缩带来的影响,从而避免了梯度弥散现象,同时进一步提升了模型的泛化能力。传统的SSD 及FPN 方法预测流程示意图对比,如图4所示。
图4 SSD 及FPN 方法预测流程示意图
Fig.4 Schematic diagram of prediction process of SSD and FPN
本文方法延续了特征金字塔的思想,在融合特征层后增加6 层卷积层,每层卷积层后紧跟一层ReLU 层。分别在扩展层的不同尺度空间内匹配目标,预测目标类别得分和边框位置。本文方法的预测流程示意图如图5 所示。
图5 本文方法的预测流程示意图
Fig.5 Schematic diagram of prediction process of our method
在扩展预测子网络中的6 层特征层做预测,对第k 层而言,默认边界框的缩放比例计算公式如下:
式中:Smin=0.3,表示最低层的缩放比例为0.3,Smax=0.9,则最高层的缩放比例为0.9。假设原图像大小M×N,a 为宽高比,则每个特征层对应默认边界框的宽和高的计算公式如下:
3 实验结果与分析
为验证改进后算法在小目标检测问题的效果,实验在车辆小目标数据集VEDAI(vehicle detection in aerial imgery)进行实验测试,并与当前主流的几种深度学习目标检测方法对比结果。
3.1 VEDAI 数据集
Sebastien Razakarivony 等于2016年提出的数据集VEDAI 为卫星航拍图像,共包含1 210 张1 024×1 024 像素的图像。平均每张图像中车辆数量为5.5 个,且目标像素占图像总像素的0.7%。图像目标车辆尺寸小(约40×20 像素),方向随机且光照变化大,是小目标检测标准数据集之一。
3.2 模型训练
模型训练采用基于动量的SGD(stochastic gradient descent)算法(随机梯度下降算法)。匹配策略中,最小jaccard overlap 值为0.5。硬件平台为:NVIDAI Titan X GPU(12 GB 显存),PC 机操作系统为Ubuntu 14.04,模型训练框架为Caffe 框架,mini batch 尺寸为32。
初始学习率为0.000 5,20 000 次迭代后,学习率调整为5e-05,60 000 次循环后训练终止。权值衰减系数为0.000 5,动量因子为0.9。
3.3 测试结果
测试阶段选取数据集中248 张图片作为测试集验证检测效果。召回率和mAP 是目标检测2 个重要指标。召回率和准确率的计算公式分别如下:
式中:TP 代表分类正确的正样例;FP 为分类错误的正样例;FN 为分类错误的负样例。准确率随召回率变化构成PRC(precision-recall curve)曲线,平均精度mAP(mean average precision)则为曲线与坐标围成的面积,计算公式如下:
将主流目标检测方法与本文方法在VEDAI 数据集上进行实验对比,结果如表2 所示。
表2 不同检测模型在VEDAI 数据集上的检测结果对比
Table 2 Comparison of detection results on VEDAI of different models
由表2 可知,对于VEDAI 数据集中像素为1 024×1 024 的图像检测,改进后模型达到最高的召回率和平均检测精度(mAP),分别为74.6%和56.2%,其较传统SSD 算法在车辆目标检测精度上有了显著提升(约10%)。表3 为不同检测模型检测速度对比结果,基于区域推荐的方法Fast R-CNN检测速度最慢,为0.4 fps,而Faster R-CNN 较其略快,检测速度为5.4 fps。基于回归方法SSD(VGG-16)检测速度为19.2 fps。图6(a)为不同检测模型检测精度和速度分布图。
表3 不同检测模型检测速度对比
Table 3 Comparison of detection speed of different models
图6 不同检测模型检测结果对比
Fig.6 Comparison of detection results of different detection models
图6(b)为改进SSD 算法与传统SSD 算法随迭代次数增加,检测精度的变化趋势。约在25 000次迭代后,检测精度值保持平稳上升,由图6 可知,改进后算法精度较传统SSD 有了显著的提升。图7 展示了改进算法在VEDAI 数据集上的部分检测结果。
图7 VEDAI 数据集部分检测效果
Fig.7 Partial detection results on VEDAI dataset
测试结果表明,本文提出的算法较传统SSD等主流目标检测算法,对VEDAI 数据集的平均检测精度显著提升,算法采用单个步骤内预测目标,保留了传统SSD 算法检测速度快的优势。融合子网络有效地利用了浅层特征层中丰富的局部细节信息及深层特征层的高语义信息,因此模型的泛化能力得到提升。
4 结论
为提高车辆小目标检测效果,本文提出了基于扩展融合特征的小目标检测方法。该方法结合小目标尺寸较小、依赖局部细节信息等特点设计了融合子网络,融合了高局部信息的浅层特征信息与高语义信息的深层特征。此外,本文设计了基于扩展金字塔的预测网络,在多个尺度空间匹配目标,提升了目标检测效果。为解决模型过拟合问题,本文引入BN 层提高了模型的泛化能力。改进算法有效地提升了车辆小目标检测精度,同时,具有更高稳定性和鲁棒性。下一步,将对模型中权值进行研究,以提升算法在复杂背景下的检测性能。
审核编辑:符乾江

































 工商网监
工商网监
评论