 电子发烧友App
电子发烧友App


AI虚拟人|冬奥会|图像转换|自监督学习
随着模拟仿真、人工智能、深度学习的快速发展,GAN技术的脱颖而出给图神经网络的发展带来了巨大保障。
冬奥会天气预报人是假的?
2022
满满的黑科技,绝对是本届冬奥会的一大亮点。
无论是惊艳的开幕式,还是场馆内外的建设,无不因为科技,一次次引起舆论的惊叹。
然而,万万没想到的是,就连给选手和观众的天气实时播报,竟然也达到了一个新的高度:

看到这张图片,你可能会想,这不是《中国天气》的主持人冯殊吗?但事实并非如此。图中在声情并茂播放天气的,并不是他本人,而是一个纯粹的AI虚拟人——冯小殊。
那么冯小殊是怎样炼成的呢?
从效果上看很明显,人类主持人冯殊是他的训练目标。冯小殊背后的“杀手锏”是数字孪生虚拟人技术。他之所以能分清面部、表情、肢体动作的整体自然度和本尊真假难辨,主要结合GAN和深度神经网络渲染技术。
而且训练周期只有一周。值得一提的是,在语音专家模型、嘴巴专家模型和人脸渲染专家模型的训练下,“冯小殊”准确地学习冯殊的嘴部动作、眼部和面部肌肉之间的协调性。
北京冬奥会期间,冯小殊将继续播报“冬奥公众观赛气象指数“,涵盖户外观赛的人体感受和健康提示,包括体感寒凉指数、穿衣指数、感冒指数、冻伤指数、防晒指数、护目镜指数等气象指标,为观赛人群及时传递户外场馆精细化气象指数服务信息,为公众健康、安全观赛提供气象条件参考依据。
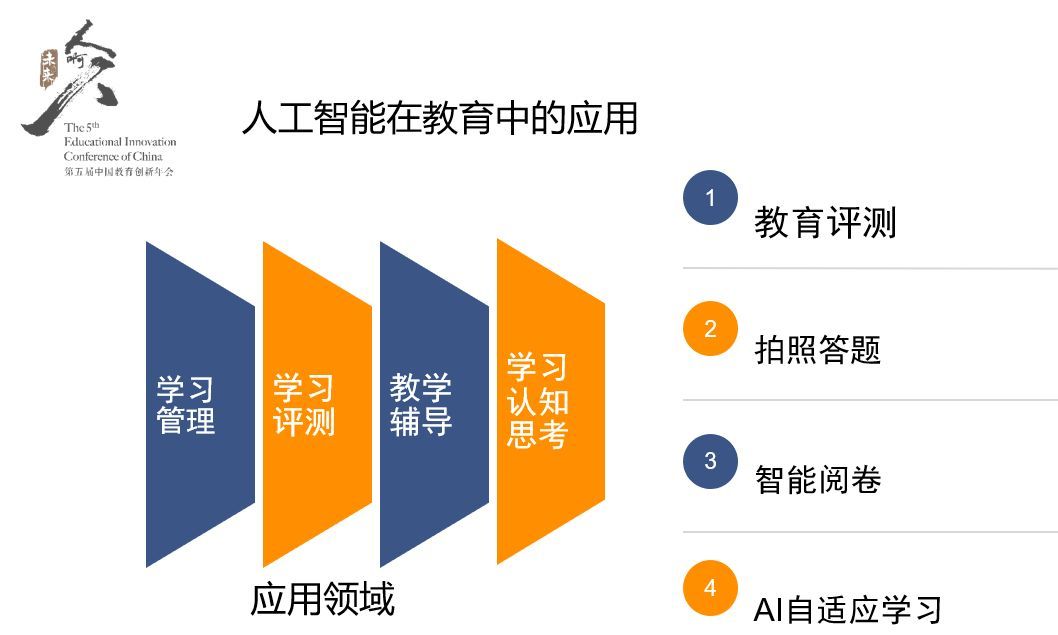
GAN生成图像综述
2022
根据不同GAN所拥有的生成器和判别器的数量,可以将GAN图像生成的方法概括为三类:直接方法,迭代方法和分层方法。
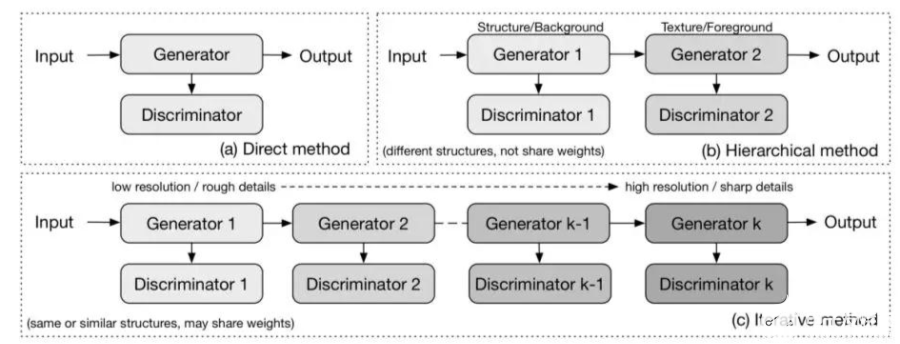
GAN在图像生成中的三类方法
直接法
早期GANs都遵循在模型中使用一个生成器和一个判别器的原理,并且生成器和判别器的结构是直接的,没有分支。如GAN 、DCGAN 、ImprovedGAN,InfoGAN ,f-GAN 和GANINT-CLS 。这类方法在设计和实现上比较容易,通常也能得到良好的效果。
分层法
分层法的主要思想是将图像分成两部分,如“样式和结构”和“前景和背景”,在其模型中使用两个生成器和两个鉴别器,其中不同的生成器生成图像的不同部分,然后再结合起来。两个生成器之间的关系可以是并联或串联。
以SS-GAN为例,其使用两个GAN,一个Structure-GAN用于生成表面结构,然后再由Style-GAN补充图片细节,最后生成图片,整体结构如下所示:
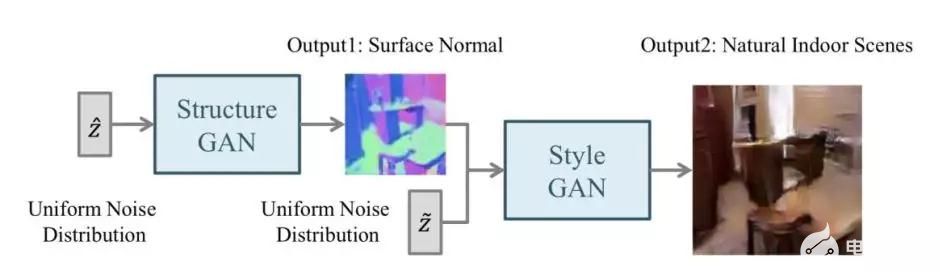
SS-GAN的分层结构
迭代法
迭代法使用具有相似甚至相同结构的多个生成器,经过迭代生成从粗到细的图像。
以LAPGAN为例:LAPGAN中的多个生成器执行相同的任务:最低级别的生成器仅将噪声向量作为输入并输出图像,而其他生成器都从前一个生成器获取图像并将噪声矢量作为输入,这些生成器结构的唯一区别在于输入/输出尺寸的大小,每一次迭代后的图像都拥有更多清晰的细节。
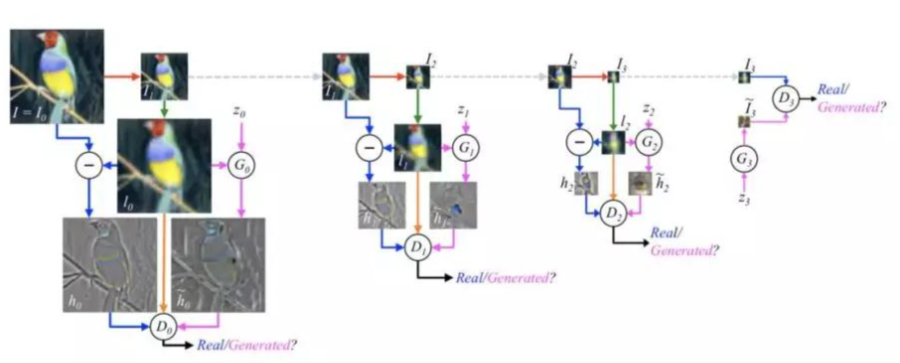
LAPGAN的迭代结构
GAN-图像转换
2022
图像到图像的转换被定义为将一个场景的可能表示转换成另一个场景的问题,例如图像结构图映射到RGB图像,或者反过来。该问题与风格迁移有关,其采用内容图像和样式图像并输出具有内容图像的内容和样式图像的样式的图像。图像到图像转换可以被视为风格迁移的概括,因为它不仅限于转移图像的风格,还可以操纵对象的属性。
图像到图像的转换可分为有监督和无监督两大类,根据生成结果的多样性又可分为一对一生成和一对多生成两类:
有监督下图像到图像转换
在原始GAN中,因为输出仅依赖于随机噪声,所以无法控制生成的内容。但cGAN的提出使得我们可以将条件输入y添加到随机噪声z,以便生成的图像由G(z,y)定义。条件y可以是任何信息,如图像标注,对象的属性、文本描述,甚至是图片。
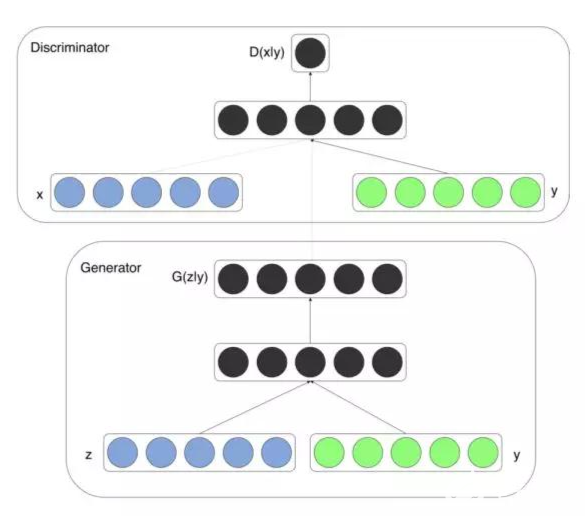
CGAN的结构
如果引入图片作为监督信息,cGAN就可以完成一些paired data才能完成的任务,如把轮廓图转化成真实图片,把mask转化成真实图,把黑白图转化成真实图等。其中最具代表性的工作为pix2pix:
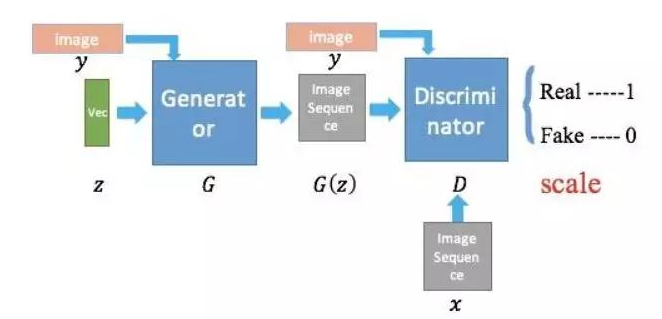
pix2pix结构图
无监督图像到图像转换
虽然有监督下图像转换可以得到很好的效果,但需要的条件信息以及paired image成为其很大的限制。但如果用无监督学习,学习到的网络可能会把相同的输入映射成不同的输出,这就意味着,我们输入任意xi并不能得到想要的输出yi。
CycleGAN 、DualGAN 和DiscoGAN突破了这个限制,这几项工作都提出了一致/重构损失(consistent loss),采取了一个直观的思想:即生成的图像再用逆映射生成回去应该与输入的图像尽可能接近。在转换中使用两个生成器和两个判别器,两个生成器进行相反的转换,试图在转换周期后保留输入图像。
以CycleGAN为例,在CycleGAN中,有两个生成器,Gxy用于将图像从域X传输到Y,Gxy用于执行相反的转换。此外,还有两个判别器Dx和Dy判断图像是否属于该域。

CycleGAN的生成效果
一对一生成到一对多生成
从pix2pix到CycleGAN系列,再到UNIT,这些方法实现的image-to-image translation不管是有监督的还是无监督的,都是一对一的,也就是说输入一张图片只能产生一种风格,缺乏多样性。但其实大多数情况下,image translation是多对多的,也就是一张图片对应不同风格的转换图片。比如我们设计衣服时,一张轮廓图其实可以设计成不同风格的衣服。再比如同一个场景,不同的光照条件就是一个模式,不一定只有白天和黑夜,还可能有傍晚清晨等。
BicycleGAN首先对此进行了尝试,其在模型中添加随机噪声,通过随机采样使噪声得到不同的表达,并在输出与潜在空间上添加双向映射。双向映射指的是:不仅可以由潜在编码映射得到输出也可以由输出反过来生成对应的潜在编码,这可以防止两个不同的潜在编码生成同样的输出,避免输出的单一性。
但直接用不同的随机噪声来产生多样化的结果,由于mode collapse的存在,很容易训练失败。MUNIT和DRITUNIT的基础上,将latent code进一步细化为内容编码 C和风格编码 S。不同domain的图像共享内容编码空间 C 而独享风格编码空间 S ,将内容编码C与不同的风格编码S结合起来就能得到更棒的多样性的结果。

MUNIT将latent code分为内容c和风格c
如下所示,BicycleGAN、MUNIT和DRIT都取得了不错的生成结果:



GAN模型分析
2022
稳定性差
稳定性差指的是GAN在训练的过程中很难把握好梯度消失和梯度错误之间的平衡。我们先看看为什么会出现梯度消失的问题。先关注判别网络,若 和 已知,令式(2)的导数为零,可解得最优的判别为:
也就是说,当判别网络最优的时候,生成网络的目标是最小化分布 和 之间的 散度。当两个分布相同时 散度为零,即生成网络的最优值 对应的损失为 。
然而实际情况是,当用诸如梯度下降等方式去最小化目标函数 的时候,生成网络的目标函数关于参数的梯度为零,无法更新。为什么会出现这种情况呢?原因是 散度本身的特性:当两个分布没有重叠的时候,它们之间的 散度恒为 。容易发现此时目标函数为0,意味着最优判别器的判别全部正确,对所有生成数据的输出均为0,因此对目标参数求导仍为0,带来了梯度消失的难题。
因此在实际中,我们往往不将判别网络训练到最优,只进行 次梯度下降,以保证生成网络的梯度仍然存在。但是如果因为训练次数太少导致判别网络判别能力太差,则生成网络的梯度为错误的梯度。如何确定 这个超参数,平衡好梯度消失和梯度错误之间的平衡是个难题,这也是为什么说GAN在训练时稳定性差的原因。
模型坍塌
除了稳定性差,GAN在训练的时候还容易出现模型坍塌的问题。模型坍塌指生成网络倾向于生成更“安全”的样本,即生成数据的分布聚集在原始数据分布的局部。下面我们看看为什么会出现这个问题。
将最优判别网络 代入式(4),得到生成网络的目标函数为:
此时, 。其中 属于有界函数,因此生成网络的最优值更多受逆向KL散度 的影响。
什么是前向和逆向KL散度?以它们为目标进行优化会带来什么结果?我们先看看第一个问题:
KL散度是一种非对称的散度,在计算真实分布 和生成分布 之间的KL散度的时候,按照顺序不同,分为前向KL散度和逆向KL散度:
在前向KL散度中:
当 而 时, 。意味着 的时候, 无论怎么取值都可以,都不会对前向KL散度的计算产生影响,因此拟合的时候不用回避 的点;
当 而 时, 。意味着要减小前向KL散度, 必须尽可能覆盖 的点。
因此,当以前向KL散度为目标函数进行优化的时候,模型分布 会尽可能覆盖所有真实分布 的点,而不用回避 的点。
在逆向KL散度中:
当 而 时, 。意味着要减小逆向KL散度, 必须回避所有 的点;
当 时,无论 取什么值, 。意味着 不需要考虑考虑是否需要尽可能覆盖所有真实分布 的点。
因此,当以逆向KL散度为目标函数进行优化的时候,模型分布 会尽可能避开所有真实分布 的点,而不需要考虑是否覆盖所有真实分布 的点。
下图给出了当真实分布为高斯混合分布,模型分布为单高斯分布的时候,用前向KL散度和逆向KL散度进行模型优化的结果,可以发现使用逆向KL散度进行优化会带来模型坍缩的问题。
因此,基于上述两个问题,GAN难训练的问题是出了名的。为了解决这些问题,后续又有人提出了各式各样的GAN,例如W-GAN,通过用Wasserstein距离代替JS散度,改善了GAN稳定性差的问题,同时一定程度上缓解了模型坍缩的问题。
GAN复原:伟大诗人泰戈尔
2022
当近百年前的黑白影像披上了色彩,它的历史意义会不会多一层呢?
近日,一段泰戈尔1930年演讲珍贵影像被AI修复还原。
那么是运用了什么技术将泰戈尔影像还原的呢?
RIFE,Deep-Exemplar-based-Video-Colorization,GPEN等一系列人工智能项目为泰戈尔影像的还原做出了巨大贡献。
其中RIFE是一个实时视频插帧方案,能实现老旧影像对高帧率的需求。
另外,在此另一个补帧项目是DAIN。
Deep-Exemplar-based-Video-Colorization是来自一种结合了图像检索与图像着色的模型。该模型首先会从大量参照图像中检索和灰度图相似的图像,然后再将该参照图像的配色方案迁移到灰度图中,实现了非常好的着色效果。
GPEN(GAN prior embedded network,GAN先验嵌入网络)是新晋开源项目,由国人打造,对亚洲人像还原效果更为出色。
结果表明,其效果明显优于最先进的严重损坏的人脸图像复原(Blind face restoration)方法。
还有DeOldify:DeOldify 使用了NoGAN 进行训练,NoGAN对于获得稳定和丰富多彩的图像是至关重要的。
NoGAN 训练结合了 GAN (美妙的着色)的好处,同时消除了副作用(如视频中闪烁对象)。
除了利用这些开源的AI模型,还结合了高超的后期技巧,百年前的老北京生活、上海时装秀才能栩栩如生地出现在人们面前。
蓝海大脑液冷GPU工作站(可搭建于 NVIDIA 4 × A100 / 3090 / P6000 / RTX6000;使用 NVLink + NVSwitch的最高GPU通信;4个用于 GPU Direct RDMA的NIC(1:1 GPU比率);最高4 x NVMe用于GPU系统盘,带有 AIOM双电源冗余供电系统、防雷击、防浪涌保护)是提供 GPU 算力的高性能计算,服务于深度学习、科学计算、图形可视化、视频处理多种应用场景。蓝海大脑液冷GPU工作站为GAN技术的发展提供硬件保障。
审核编辑:符乾江



































 工商网监
工商网监
评论